
🍏 model.save()
- 학습의 결과를 저장하기 위한 함수
- 구글 colab에서 모델을 학습하다보면 8시간 뒤에 런타임 연결이 끊겨 학습 결과가 날아간다.
이를 방지하기 위해, pytorch는 학습 결과를 저장하는 함수를 지원한다. - 모델 형태(architecture)와 파라미터를 저장한다.
- 모델 학습 중간 과정의 저장을 통해 최선의 결과 모델을 선택
🟨 state_dict()
- 모델의 파라미터를 표시
torch.save(model.state_dict(), # save model's parameters
os.path.join(MODEL_PATH, "model.pt")
new model = TheModelClass()
# 같은 모델의 형태에서 파라미터만 load
new_model.load_state_dict(torch.load(os.path.join(MODEL_PATH, "model.pt")))
torch.save(model, os.path.join(MODEL_PATH, "model.pt")) # model의 architecture도 함께 저장
model = torch.load(os.path.join(MODEL_PATH, "model.pt")) # model의 architecture도 함께 load- 모델의 크기를 깔끔하게 보려면
torchsummary추천
🍏 checkpoints
- earlystopping 기법 사용시 이전 학습의 결과물을 저장
- loss와 metric 값을 지속적으로 확인 저장 (epoch도 함께)
torch.save({
'epoch': e,
'model_state_dict': model.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
'loss': epoch_loss,
}, f"saved/checkpoint_model_{e}_{epoch_loss/len(dataloader)}_{epoch_acc/len(dataloader)}.pt")🚩 Pretrained-Model
transfer learning
- 다른 데이터셋으로 이미 만들어진 모델을 현재 데이터에 적용
- 대용량 데이터셋으로 만들어진 모델의 성능이 좋다.
- backbone architecture가 잘 학습된 모델에서 일부분만 변경하여 학습 수행
HuggingFace를 주로 이용한다.
🍏 Freezing
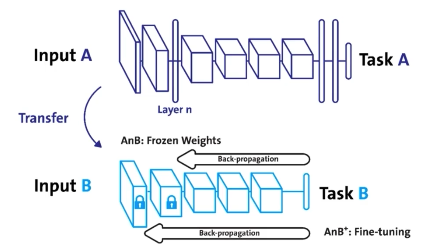
- 어느정도까지는 parameter 변경없이 학습(= frozen 시키다)하다가 뒷부분은 parameter를 변경하여 새롭게 학습하겠다!
→ Back-propagation이 일부 layer에서만 일어난다.

🚩 Monitoring
🟨 Tensorboard - tensorflow의 프로젝트로 만들어진 시각화 도구
- 학습 그래프, metric, 학습 결과의 시각화 지원
scalar: metric (Accurate, Loss, recall) 등 상수 값의 연속(epoch) 표시graph: 모델의 computational graph 표시histogram: weight 등 값의 분포를 표현image: 예측값과 실제값의 비교 표시mesh: 3d 형태의 데이터를 표현하는 도구

🟨 Weight & biases (Wandb)
-
머신러닝 실험을 원활히 지원하기 위한 상용 도구
-
협업, code versioning, 실험 결과 기록 등 제공
🚩 Multi-GPU
-
SinglevsMulti -
GPUvsNode
1 gpu vs Node(1대의 system이라 지칭) 컴퓨터 1대 gpu -
Single Node Single GPU
1대 1 gpu -
Single Node Multi GPU
1대 여러 개 gpu -
Multi Node Multi GPU
여러 대 여러 gpu
🍏 Model parallel
- 다중 gpu에 학습을 분산하는 2가지 방법
- 모델 나누기
- 데이터 나누기 (여러 gpu에 할당 후 결과의 평균을 취하는 방법)
- gpu 사용 불균형 문제 발생
- batch 사이즈 감소 (한 gpu가 병목)
train_sampler = torch.utils.data.distributed.DistributedSampler(train_data)
shuffle = False
pin_memory = True
trainloader = torch.utils.data.DataLoader(train_data, batch_size=20, shuffle=False,
pin_memory=pin_memory, num_workers=3, shuffle=shuffle, sampler = train_sampler)
# num_workers = gpu 갯수- 모델의 병목, 파이프라인의 어려움으로 인해 모델 병렬화는 고난이도 과제
🚩 Hyperparameter Tuning
- 모델 스스로 학습하지 않는 값(learning rate, model size, optimizer ..)은 사람이 지정
- 하이퍼 파라미터에 의해서 값이 크게 좌우 될 때가 있음
- 기본적인 방법
- grid search
log를 취해서 값을 변화, 일정한 범위를 정해서 값을 자른다 (lr = 0.1 0.01, 0.001 ...) - random search
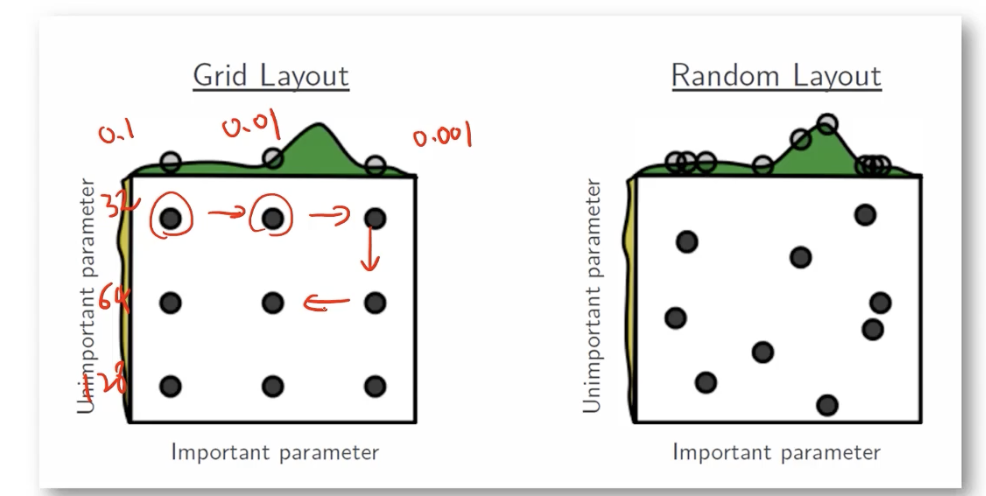
가로: learning rate (0.1 0.01, 0.001 ...)
세로: batch size (32, 64, 128 ...)
- grid search
🍏 Ray
- multi-node multi processing 지원 모듈
- Hyperparameter Search를 위한 다양한 모듈 제공
data_dir = os.path.abspath("./data")
load_data(data_dir)
# config에 search space 지정
config = {
"l1": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"l2": tune.sample_from(lambda _: 2 ** np.random.randint(2, 9)),
"lr": tune.loguniform(1e-4, 1e-1),
"batch_size": tune.choice([2, 4, 8, 16])
}위의 코드 예제는 grid search 관련
🚩 Troubleshooting
GPU , cuda 에러와 관련된 트러블 슈팅이 가능한 도구들과 해결방법을 위한 내용
🟨 OOM (Out of Memory)
- 왜 / 어디서 발생했는지 알기 어렵고 에러 백트래킹이 이상한 데로 간다.
- Batch Size를 줄이고 → GPU → clean Run
- 학습시 OOM이 발생했다면 배치 사이즈를 1로 설정해보기
- GPUUtil 사용하기
- nvidia-smi 처럼 GPU 상태를 보여주는 모듈

- torch.cuda.empty_cache() 써보기
- 사용되지 않은 gpu상 캐시들을 정리
- 가용 메모리를 확보
- del과는 구분이 필요
(del은 메모리와의 관계를 끊어줘서 메모리 free 시키는 작업)- reset 대신 쓰기 좋은 함수
- del 하자마자 메모리를 더 사용할 수 있는 것이 아니다.
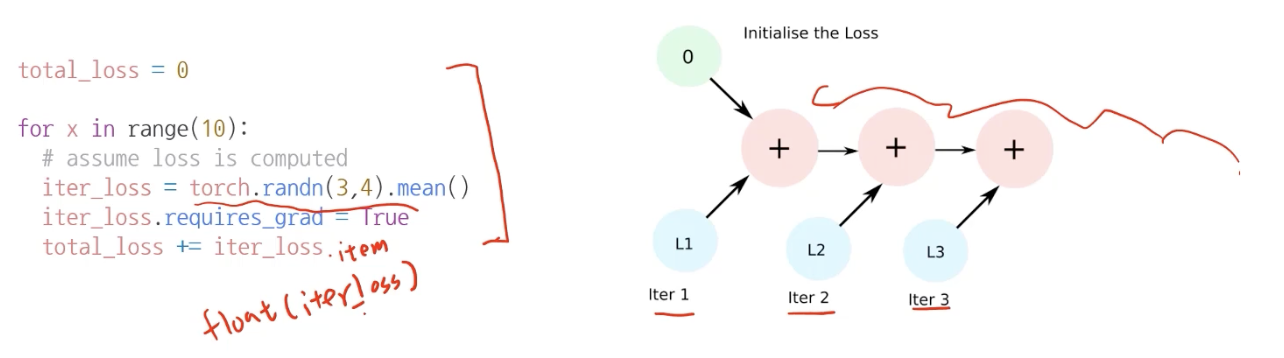
캐시들을 삭제하는 garbage collector 가 작동하는 그 시점부터 메모리를 사용할 수 있다.- training loop에 tensor로 축적되는 변수는 확인할 것
- tensor로 처리된 변수는 GPU 상에 메모리 사용 (메모리 많이 잡아먹는다)
- 해당 변수 loop 안에 연산이 있다면, GPU에 computational graph 생성 (메모리 잠식)
ex. backward() 를 하려면 이전 값들을 계속 알고 있어야 하니까..
1-d tensor의 경우 python 기본 객체로 변환하여 처리할 것!
- del 명령어를 적절히 사용하기
- 필요가 없어진 변수는 적절한 삭제가 필요
- python 메모리 배치 특성상 loop가 끝나고 메모리를 차지하고 있다.
- torch.no_grad() 사용하기
- Inference 시점에서는 torch.no_grad() 구문 사용
- backward()가 일어나지 않기 때문에 backward() 메모리 사용에서 자유로움
그 외...
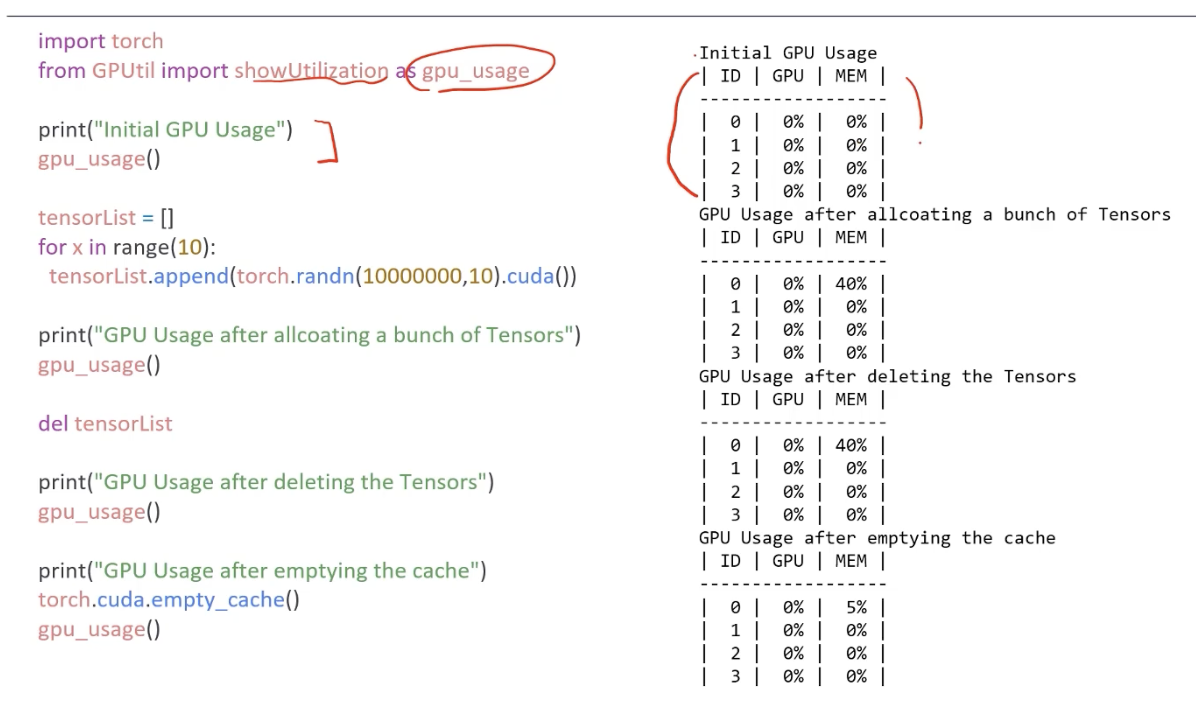

참고: https://brstar96.github.io/devlog/shoveling/2020-01-03-device_error_summary/
🟨 Tip !
- UserWarning이 많이 뜰 때
import warnings
warnings.filterwarnings("ignore")
배우고 싶은게 많은 개발자📚