
🚩 딥러닝 기본
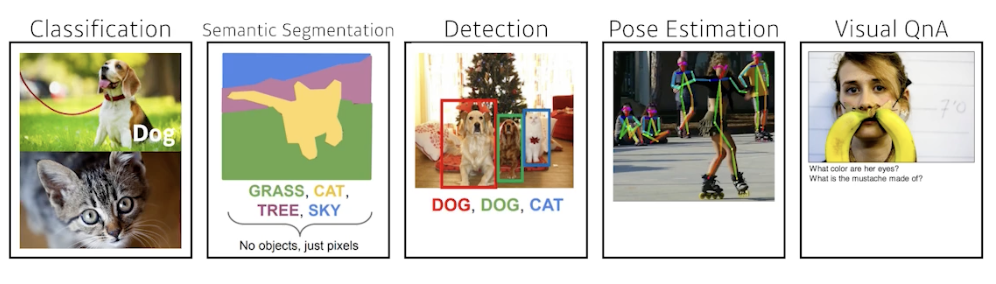
- loss function
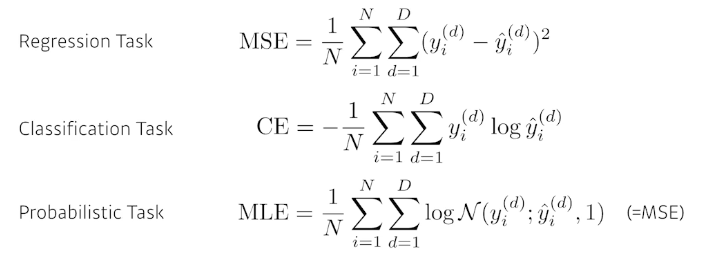
- Classification Task
출력값 y는 원-핫 벡터로 표현된다. 내가 찾고 싶은 label이 10개면 10차원의 벡터로 나오게 된다. 만약 출력값이 강아지를 뜻하는데 강아지의 차원이 2라면 0,1,0,0,0... 강아지의 차원 index만 1이고 나머지는 0이 된다. ( = 클래스에 해당하는 값만 높이겠다!)
- Classification Task
🍏 Linear Neural Networks
- activation functions (활성함수)
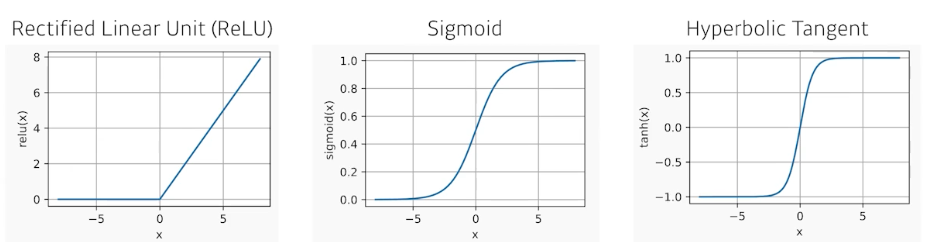
- ReLU: 출력값이 0보다 크다면 그대로 쓰고, 0보다 작다면 0으로 변환
- Sigmoid: 출력값을 항상 0~1 사이로 제한
- Hyperbolic Tangent: 출력값을 항상 0~1 사이로 제한
🍏 Optimization (최적화)
-
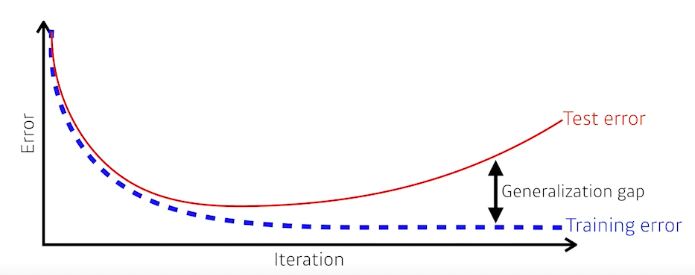
Generalization 일반화
This network has good gerneralization performance
= 이 네트워크의 성능이 학습 데이터와 비슷하게 나올 것이다.
(학습 데이터와 테스트 데이터의 성능 차이가 나는지에 대한
-
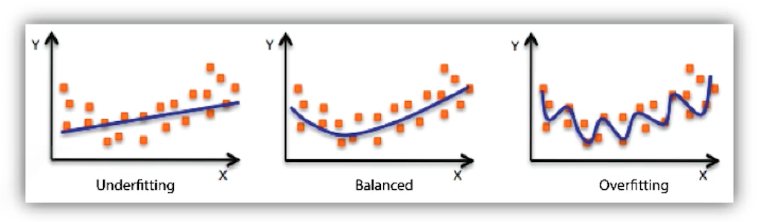
Under-fitting
네트워크가 너무 간단하거나, 학습이 부족해서 학습 데이터조차 잘 맞추지 못하는 현상 -
Over-fitting
학습 데이터에서는 잘 나오지만, 테스트 데이터에서는 잘 안되는 현상
-
Cross validation
대부분 train data / test data로 나누는데, train data 내에서 validation data를 따로 또 나누어 학습에 사용되지 않은 validation data을 기준으로 테스트하여 얼마나 잘 나오고 있는지 확인.validation data는 얼만큼 나누어야 할까?
- 반으로 나누자니, 학습 데이터가 적어 학습이 잘 안될 것
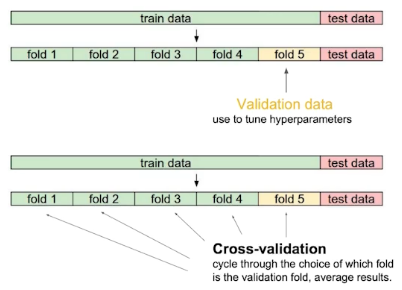
Cross-validation 사용!
학습 데이터를 k개로 나누어 k-1개로 학습시키고, 나머지 1개로 테스트 - 반으로 나누자니, 학습 데이터가 적어 학습이 잘 안될 것
-
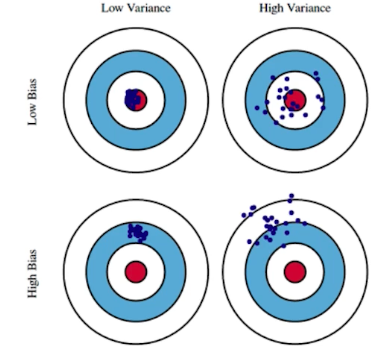
Bias-variance tradeoff
Low Bias: 평균적으로 true target에 가까이 찍히는 경우
Low Variance: 입력을 넣었을 때 출력이 일관되게 나오는 경우
High Bias: 내가 원하는 true target과는 거리가 먼 경우
High Variance: 입력을 넣었을 때 출력이 분산되어 나오는 경우
bias와 variance, noise를 줄이는게 cost를 줄이는 방법이다.
하지만 bias를 줄이게 되면 variance가 높아지는 반비례 관계이기 때문에 noise가 껴있는 경우에는 둘 다 줄이기가 어렵다.
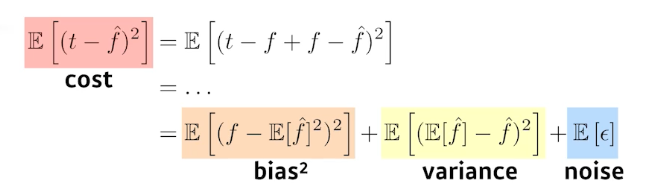
-
Bootstrapping
주어진 학습데이터를 다 쓰지 않고 몇 개씩 뽑아서 여러 모델을 만들고 그 모델간의 상관관계를 파악하는 실험을 하는 등, 여러가지를 하겠다는 뜻 -
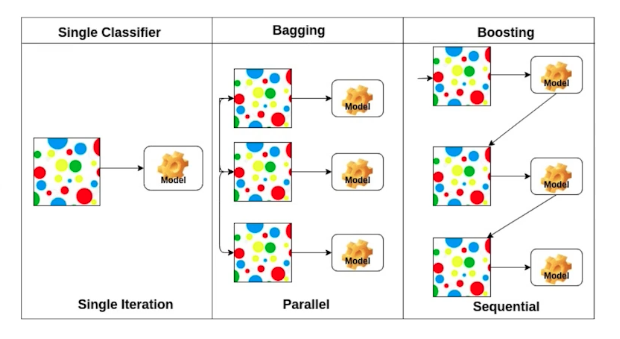
Bagging and boosting
<Bagging>
여러 독립적인 모델들을 subsampling들을 통해 만들고 그 모델의 output들을 평균을 내겠다 (앙상블)
<boosting>
여러 모델들을 독립적으로 합치는게 아닌, sequential하게 합쳐서 하나의 출력을 갖는다.
🍏 Gradient Descent Methods
- Stochastic gradient descent
Update with the gradient computed from a single sample - Mini-batch gradient descent (⭐️)
Update with the gradient computed from a subset of data - Batch gradient descent
Update with the gradient computed from the whole data
Batch size를 작게 잡는 것이 일반적으로 성능이 좋게 나온다.
(sharp minimum)
🍏 Regularization (좋은 일반화를 위해 조정) // ex. Early Stopping...
🟨 Early Stopping
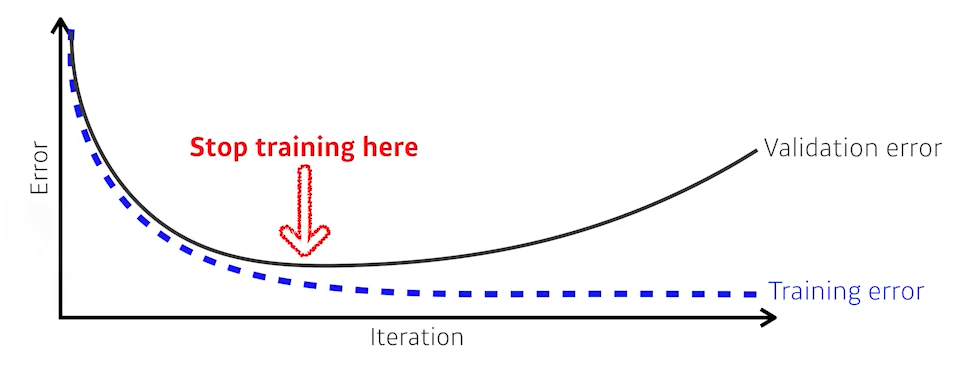
Note that we need additional validation data to do early stopping. (Not using test data)
🟨 Parameter norm penalty
파라미터 값이 작을수록 일반화가 잘 되더라 (가정)
파라미터가 커지지 않도록 제한하는 것. (smooth하게)
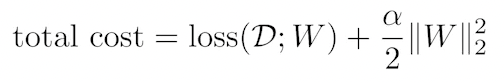
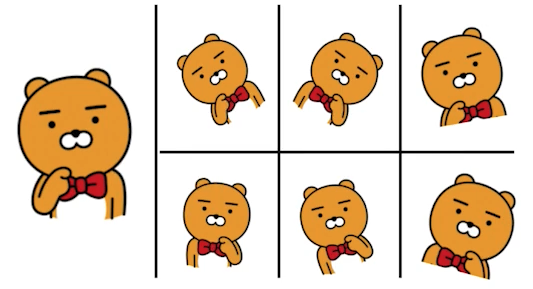
🟨 Data augmentation
데이터가 무한히 많을 때가 더 잘된다.
주어진 데이터는 한정적이기 때문에 갖고 있는 데이터들을 변환해서라도 데이터 갯수를 많이 만들어낸다.
🟨 Noise robustness
noise를 줌으로써 더 견고하게 만들 수 있다. 테스트 데이터에서도 성능이 좋도록 (일반화)

🟨 Label smoothing
학습 데이터 중에서 2개를 뽑아서 섞어주는 것 (<분류 문제>에서 성능이 많이 올라간다!)

🟨 Dropout
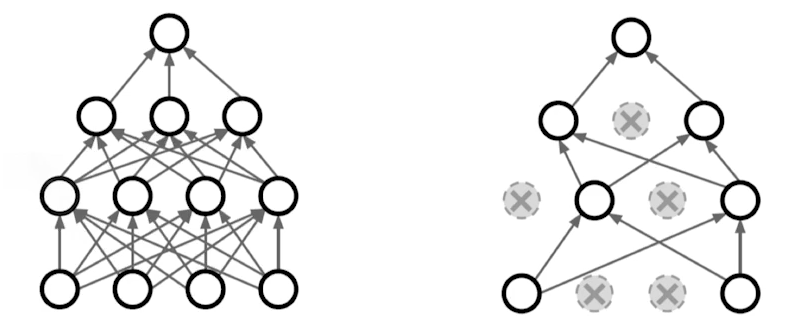
In each forward pass, 뉴럴 네트워크의 뉴런들 몇가지를( 등..) 0으로 바꾸는 것 (초기화)
🟨 Batch normalization
layer가 많이 쌓일수록 Batch normalization을 하게 되면 성능이 잘 올라간다.
<분류 문제>에서 성능이 많이 올라간다!
