
🚩 Convolution
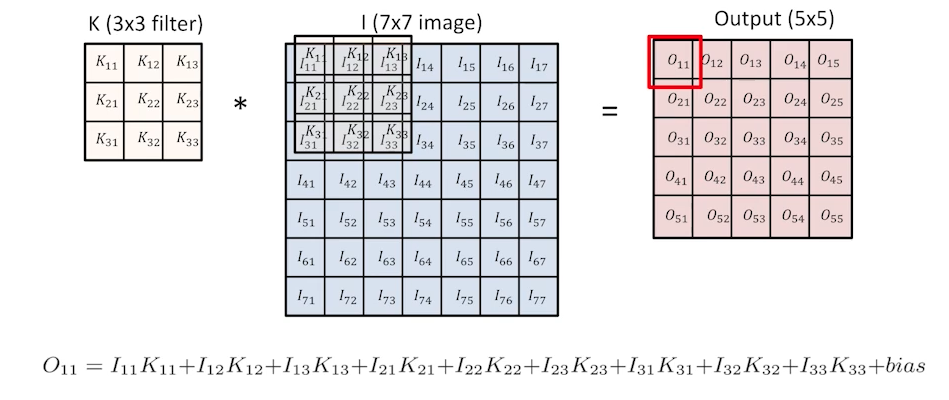
RGB (3 channel) Image Convolution
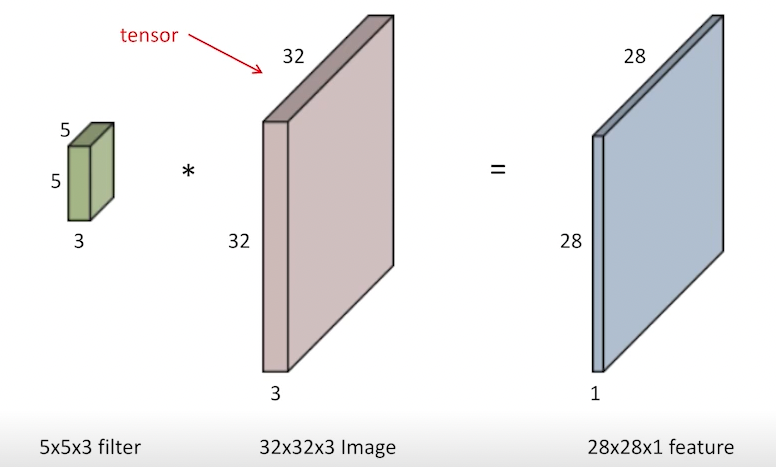
5x5 크기의 3채널을 가진 1개의 filter와 곱하게 되면, 28x28x1 피처가 나온다.
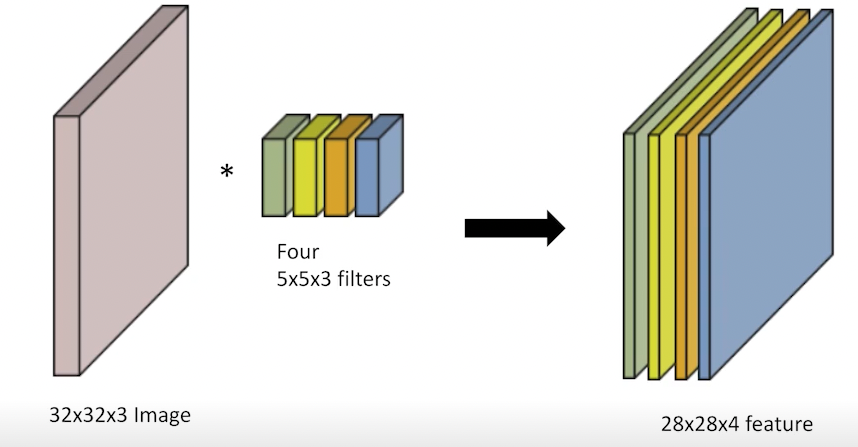
4개의 필터를 곱하게 되면, 동일하게 4개의 피처가 출력된다.
(size size input_channel * output_channel <필터 갯수>) ---> 5x5x3x4
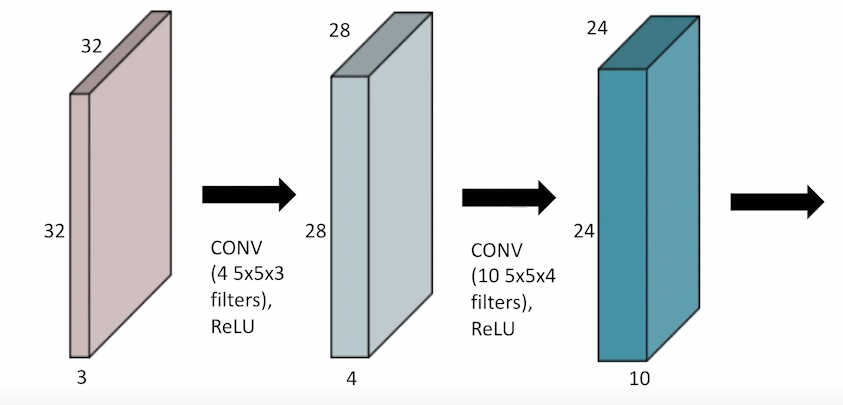
5x5x3 짜리 4개의 필터를 곱하면, 28x28x4 feature map이 나온다.
그 다음 feature map이 24x24x10면, 5x5x4 크기인 10개의 필터를 통과하면 된다. 이때 4는 내가 convolution을 하는 filter의 dimension이다.
🚩 Stride & Padding
-
stride
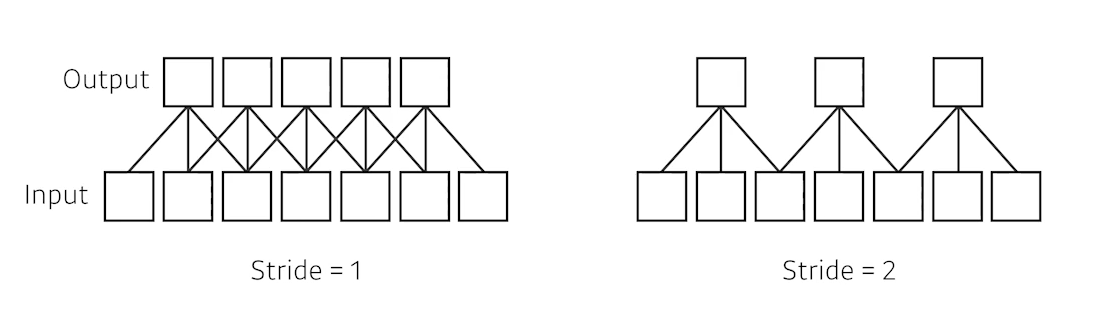
-
padding
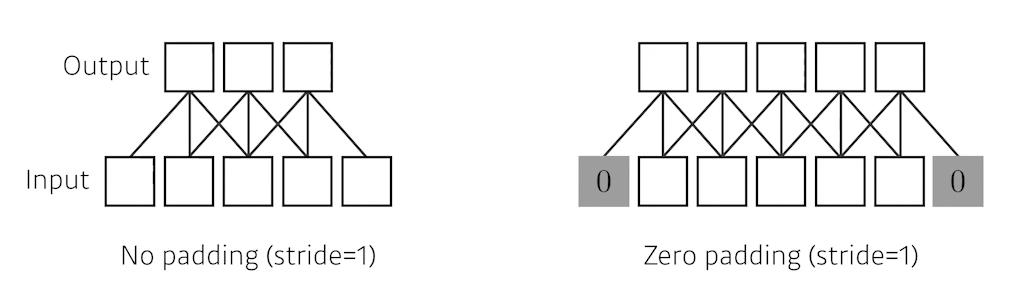
zero padding을 해주게 되면, Input과 output의 dimension이 같게 나온다.
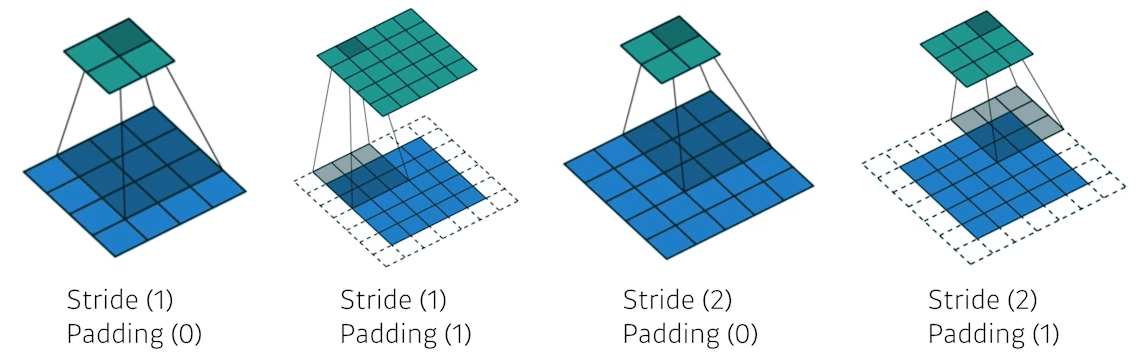
🍏 What is the number of parameters of this model?
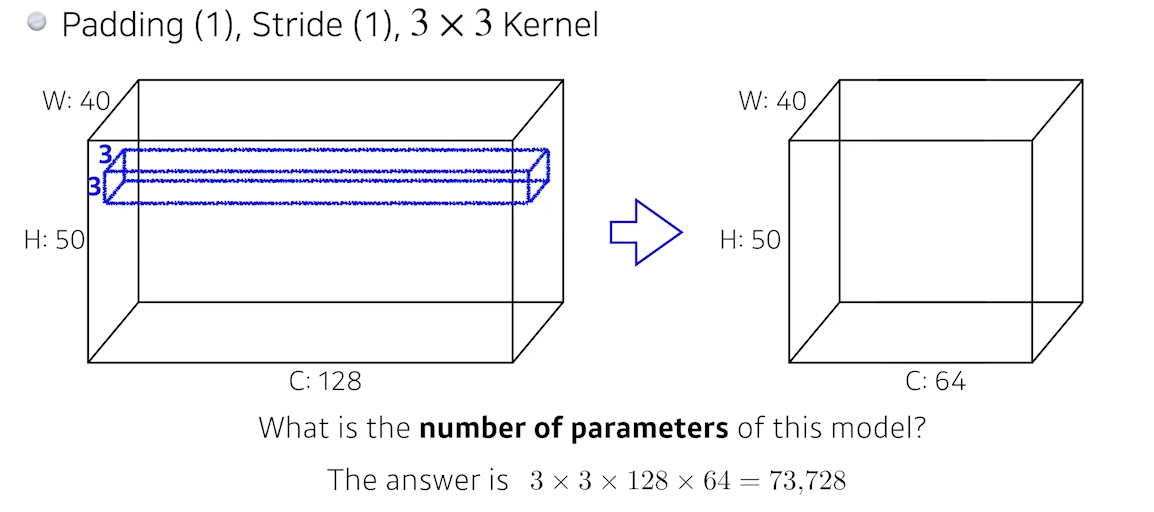
padding으로 3x3 커널을 적용해도 output은 input과 같은 크기 (w, h)
3x3x128 convolution filter를 적용하면 1개의 채널이 나온다.
(식빵 썰듯이 w:40,h:50인 채널 1개의 얇은 직사각형만 나온다는 뜻)
우리가 필요한 채널은 64개이므로 x64 !
🟨 예제 (AlexNet)
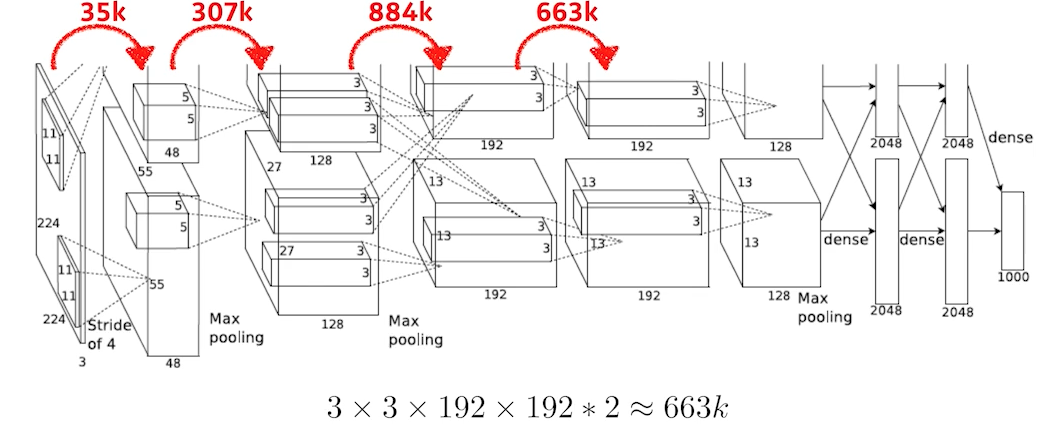
1. 224x224 크기의 3 채널 레이어에 11x11x3(채널) 커널을 stride 4로 적용한다.
위의 예제는 옛날 네트워크라 메모리 문제 때문에 2개로 쪼갰다. (2번째 layer 참조)
---> 11x11x3x48*2 = 35k
3번째 ~ 4번째 레이어는 각각 1커널 1레이어 적용이 아니라 쪼개진 레이어 두 개에 2커널을 적용하므로
3x3x128*2x192*2 = 884k
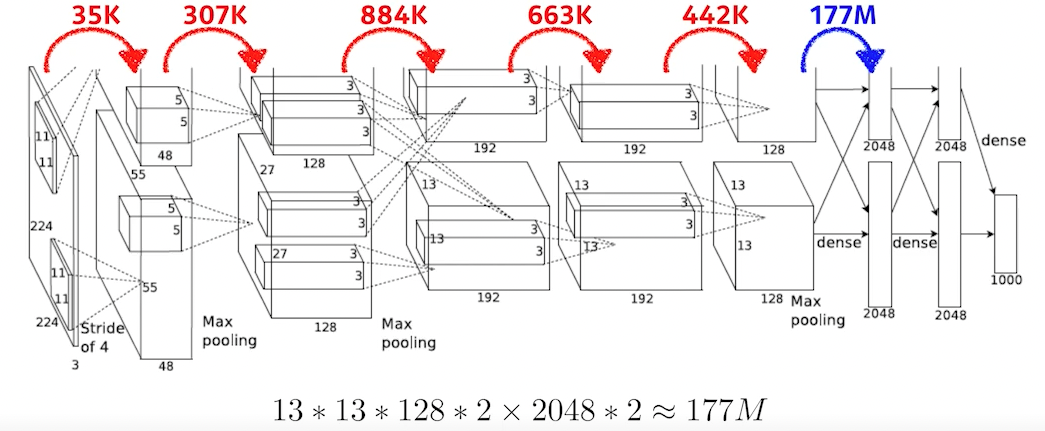
뒤에 dense 레이어는 fully connect layer
이 레이어의 차원 계산은 input parameter 갯수 * output parameter 갯수다.
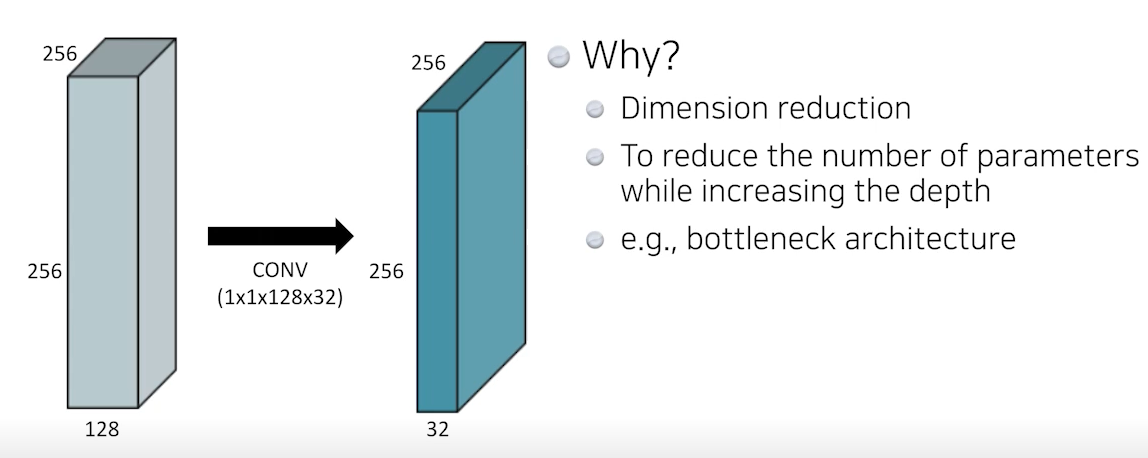
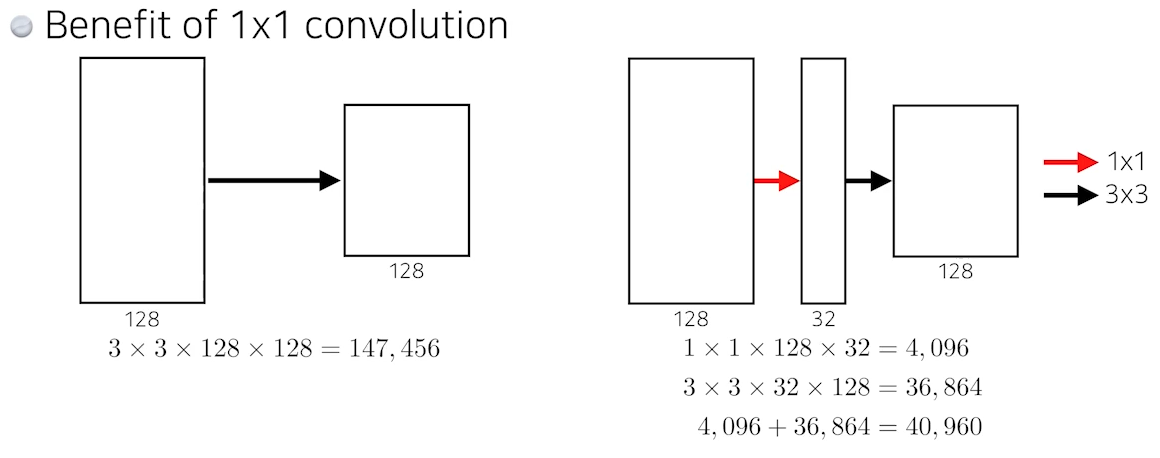
🍏 1x1 Convolution (Dimension reduction)
🚩 Modern Convolutional Neural Networks
🍏 AlexNet
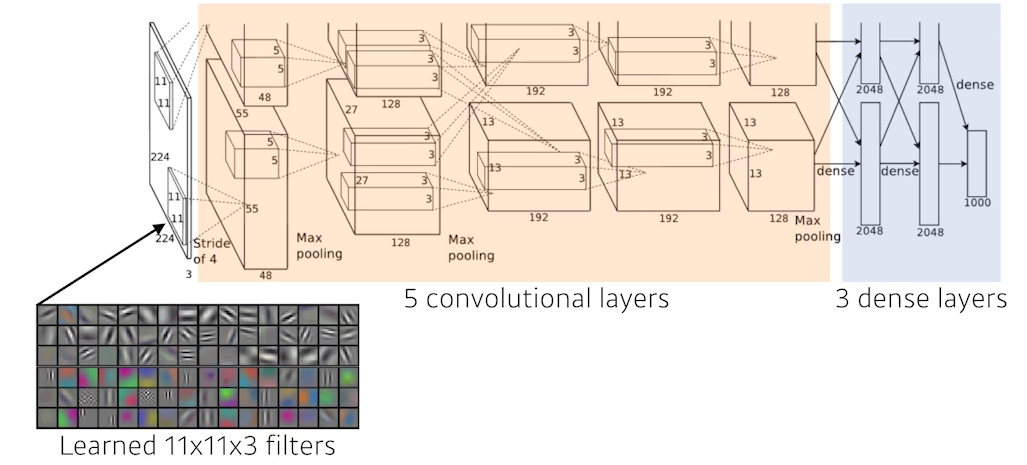
✍🏻 Key ideas
- ReLU activation
-->sigmoid, tanh와 다르게vanishing gradient문제를 극복- 2 GPU
- Overlapping pooling, Local response normalization
- Data augmentation
- Dropout
🍏 VGGNet
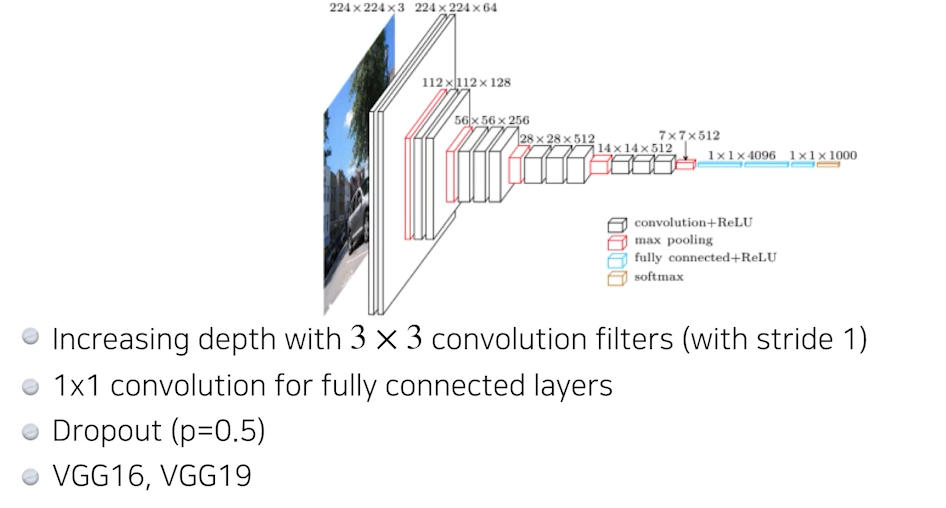
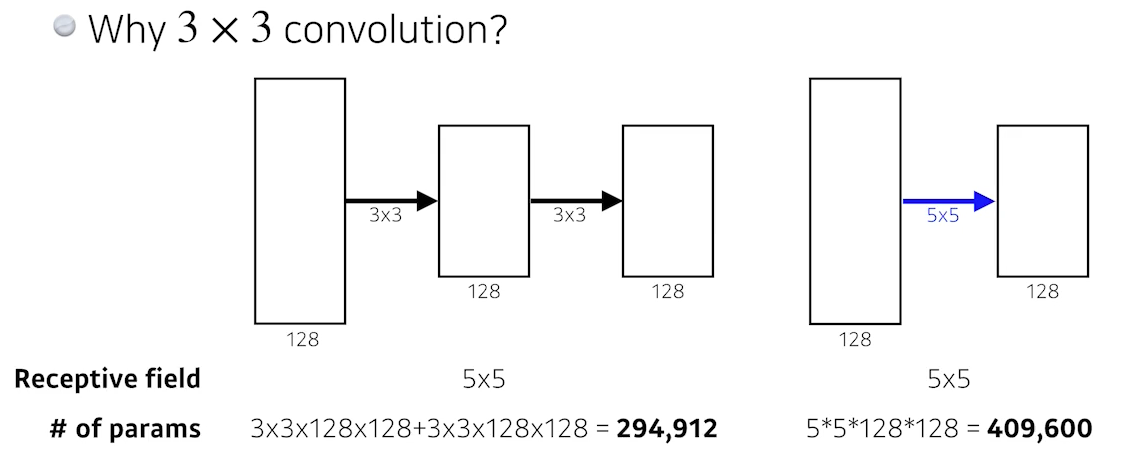
✍🏻 Why 3x3 convolution?
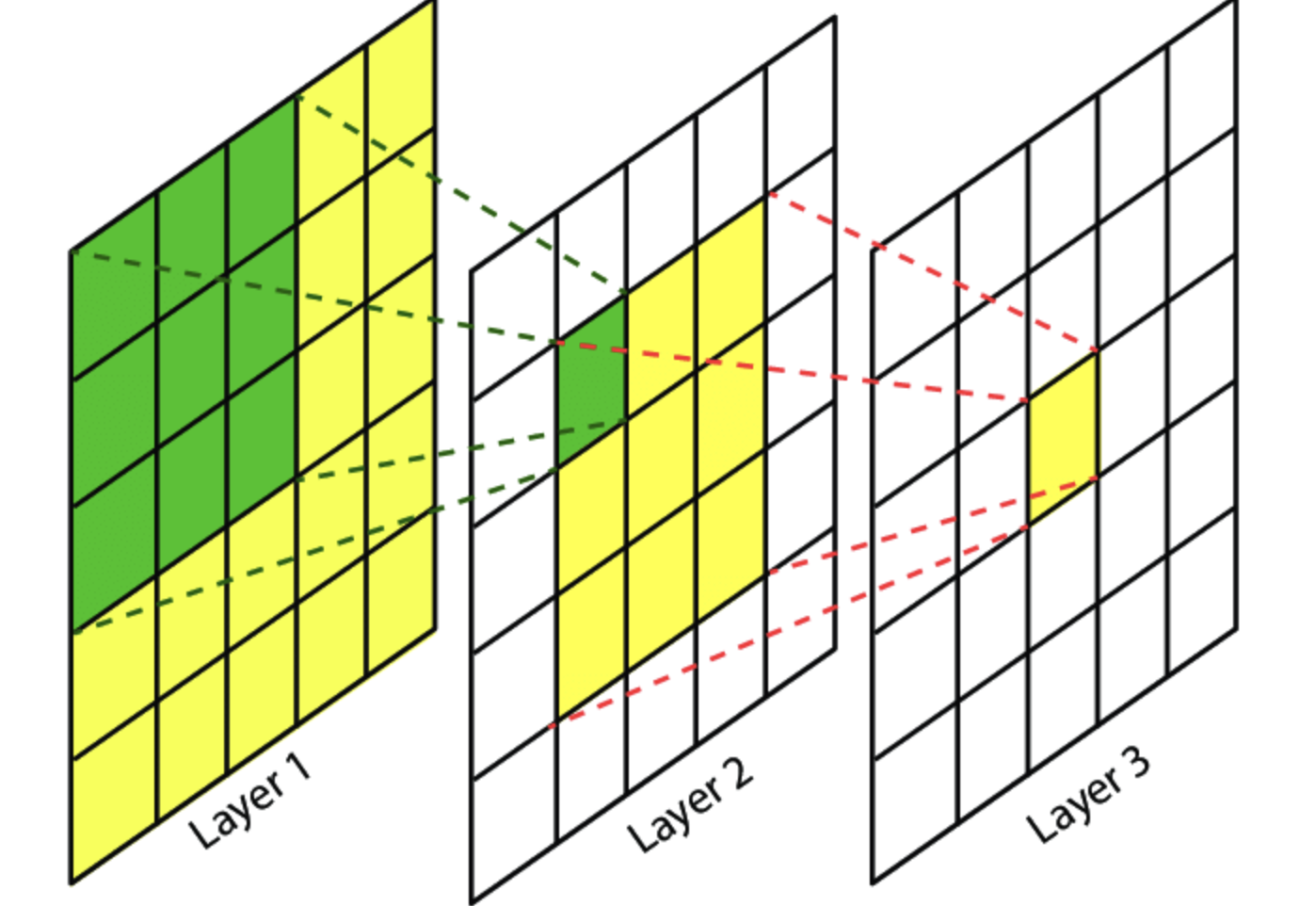
3x3 2번과 5x5는 Receptive field 차원에서 똑같다.Receptive field란?
필터가 한 번에 보게 되는 이미지의 면적이라는 개념으로 이해할 수 O
초록색 면적 (3x3)으로 이해하면 된다.
필터를 통해 어떤 사진의 전체적인 특징을 잡아내기 위해서는 receptive field가 높을수록 좋다. 그렇다고 필터의 크기를 크게 하면 연산량이 늘어나고, overfitting 가능성이 크다.결국 필터링되어 줄어진 출력 field 면적은 같다.
면적은 같지만, 파라미터 수를 계산해보면 3x3 convolution을 2번 적용했을 때의 파라미터 수가 훨씬 적다.
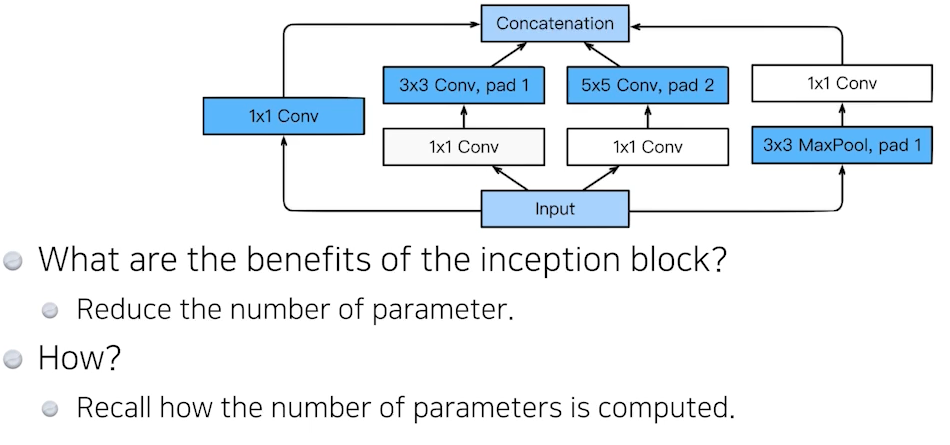
🍏 GoogleNet
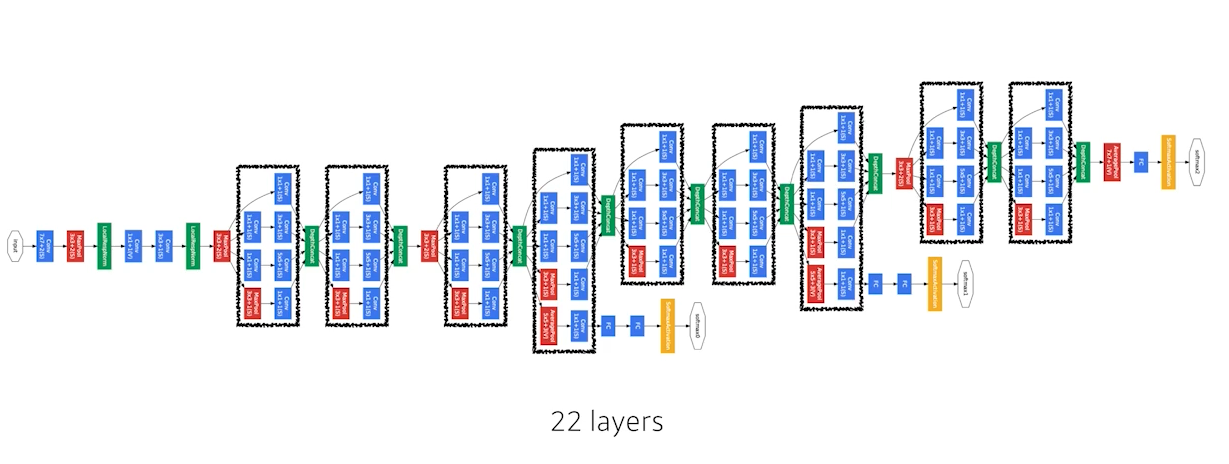
비슷한 네트워크가 여러번 반복된다 = 네트워킹 네트워크 구조
✍🏻 Key ideas
- Inception blocks
한 input이 여러 개의 네트워크로 넘어갔다가 합쳐진다 (concatenation)
GoogleNet은 1x1 convolution 을 통해 파라미터 수를 줄였다.
AlexNet, VGGNet과 달리 네트워크는 깊어지고 파라미터 수는 줄어들고 성능은 높아지게 된다!
🍏 ResNet
parameter 수가 많아지게 되면 overfitting이 일어나기 쉽다.
-> overfitting: 학습이 잘 되다가 갑자기 test error가 높아지는 상황
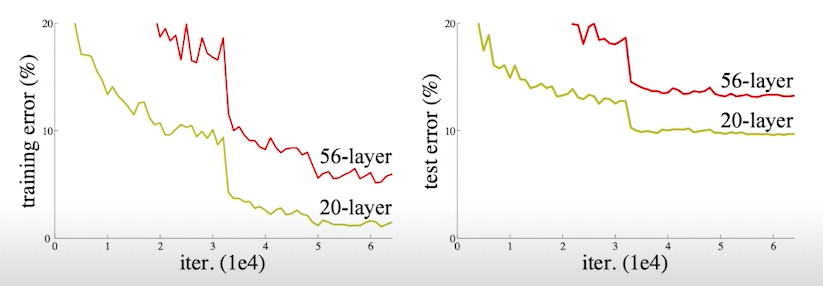
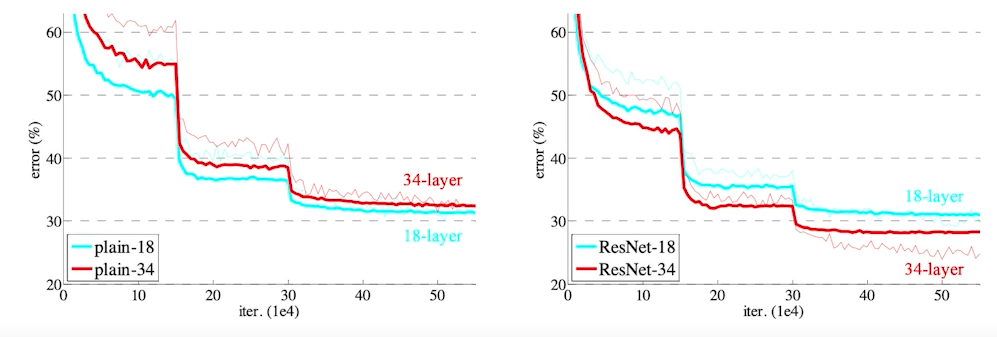
하지만 이런 케이스는 overfitting은 아니지만, 네트워크가 깊어질수록 학습이 잘 안되는 것을 확인할 수 있다.
✍🏻 Key ideas
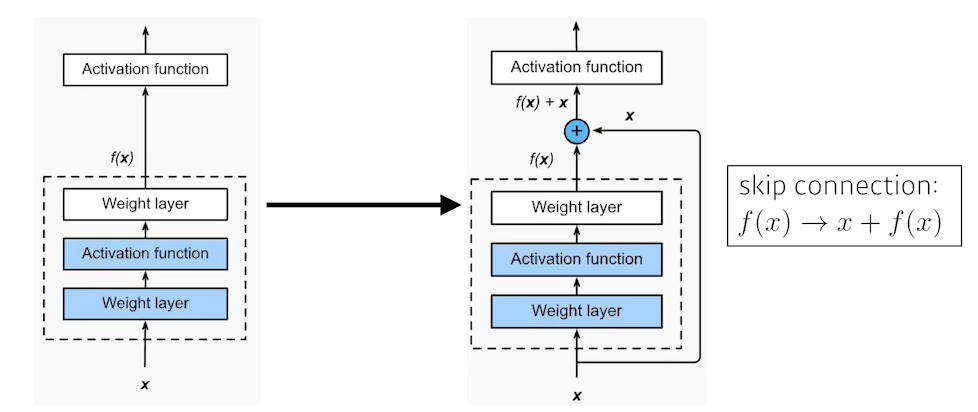
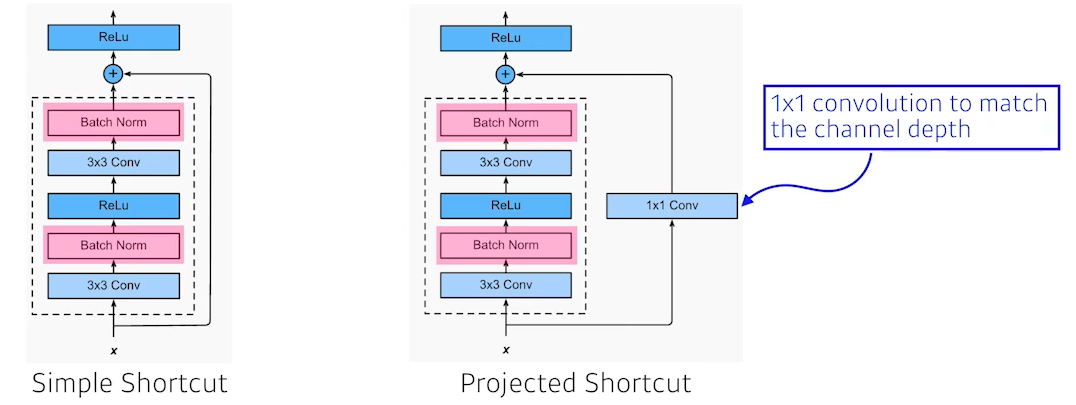
- identity map (skip connection)
layer들을 거친 f(x)에 원래 입력값 x를 더해주는 Identity map
이때, 더해주려면 f(x)와 x의 차원이 같아야 한다.
차원이 다르다면?
projected shortcut처럼 1x1 convolution을 통해 차원을 맞춰주자
(하지만 이것은 잘 안 쓴다.)
ResNet을 거치게 되면 깊은 네트워크여도 학습이 잘 되는 것을 확인 가능
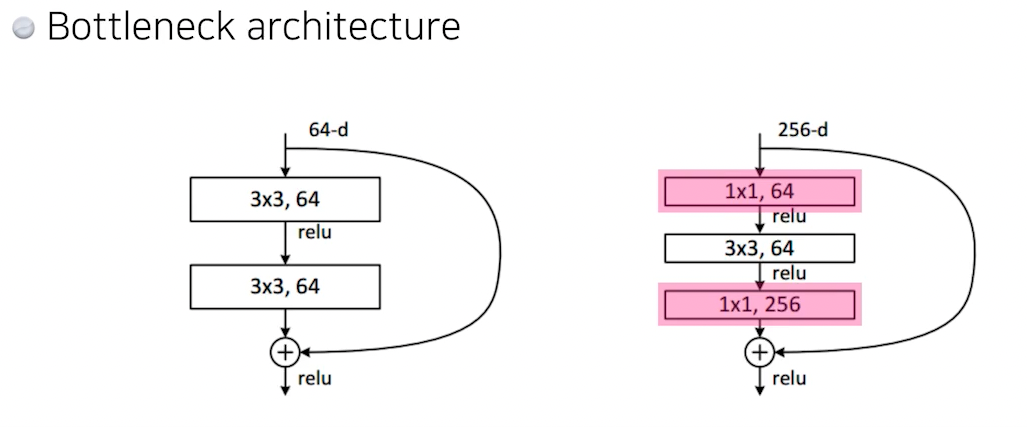
GoogleNet처럼1x1, 64를 통해 차원을 줄여줬다가 다시1x1 256을 통해 차원 원상복구를 해주어 파라미터 수를 줄이기도 한다.
🍏 DenseNet
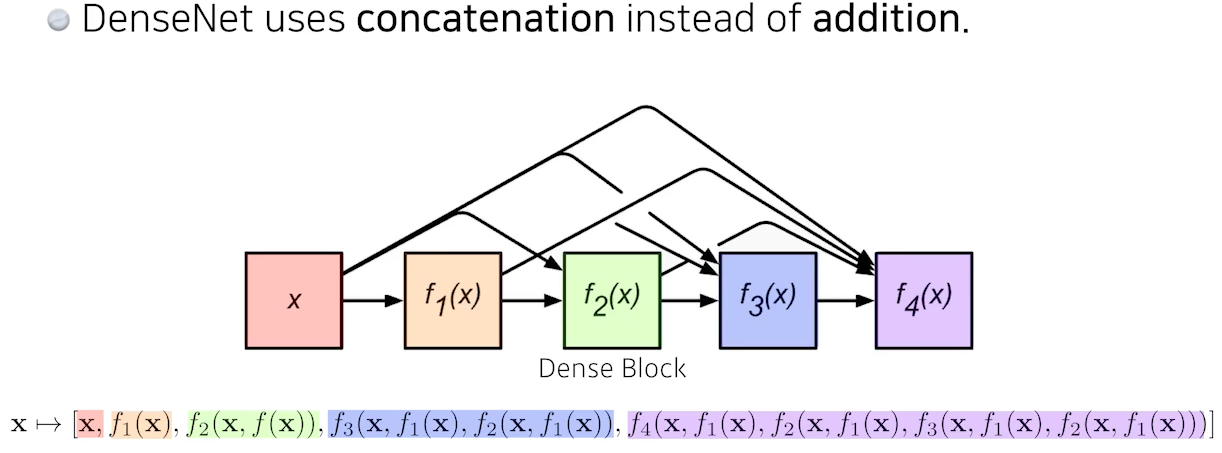
이렇게 계속 합치기만 한다면, 파라미터 수도 차원 수도 증가하기에 우리가 원하는 이상향이 아니다. 그러므로, 아래 그림처럼 convolution으로 줄였다 dense로 늘렸다하는 네트워크 구조를 쌓게 된다.
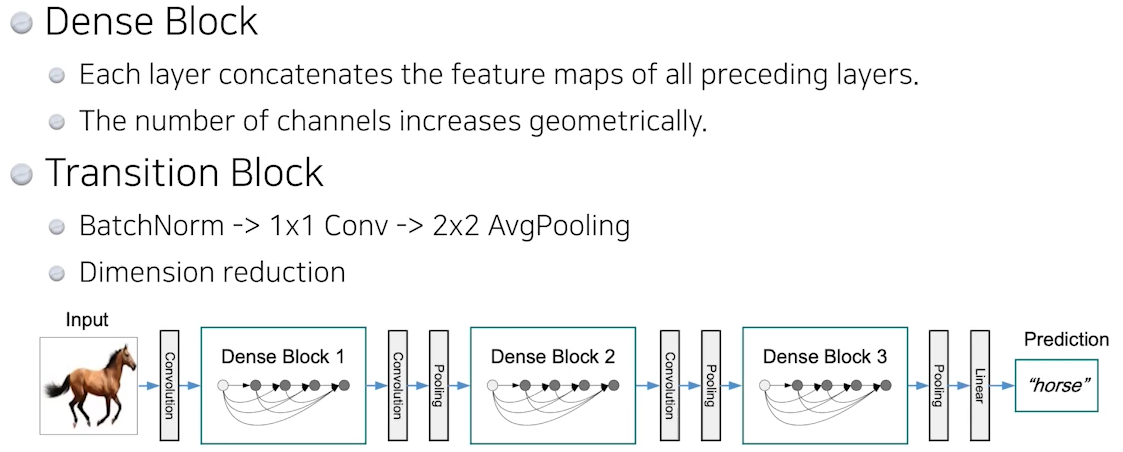
🥕 Summary
- VGG: 반복되는 3x3 blocks
- GoogleNet: 1x1 convolution
- ResNet: skip-connection (깊은 네트워크)
- DenseNet: concatenation (네트워크 쌓기 o // feature map add (x))
