
🚩 Seq2Seq Model (Attention)
- RNN 구조에서 many to many와 같음
- 입력, 출력 둘 다 sequence (입력 sequence를 받은 후, 출력 시퀀스 생성)
- 입력 문장을 받는 encoder, 출력 단어를 하나씩 생성하는 decoder
- Start of Sentence <SoS>, End of Sentence <EoS>
- Decoder에서
SoS를 받으면 문장 단어 생성을 시작하고EoS를 받으면 더이상 생성하지 않는다. - Encoder에서 나오는 hidden vector들을 decoder에게 넘겨주어 각 time step에서 필요한 encoder hidden state 벡터를 선별적으로 가져가서 예측한다. (
Attention)
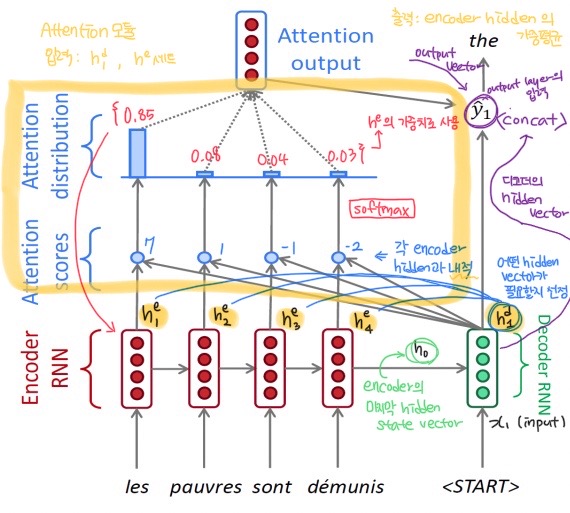
- Encoder에서 나온 hidden state vector들 중 마지막 인코더의 hidden vector 을 decoder의 input으로 넣어준다.
decoder의 input: , ---> () 디코더의 hidden vector 출력
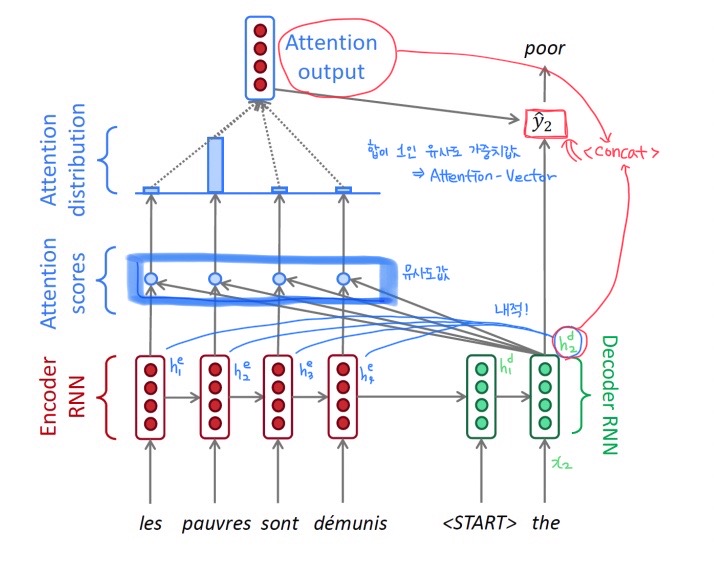
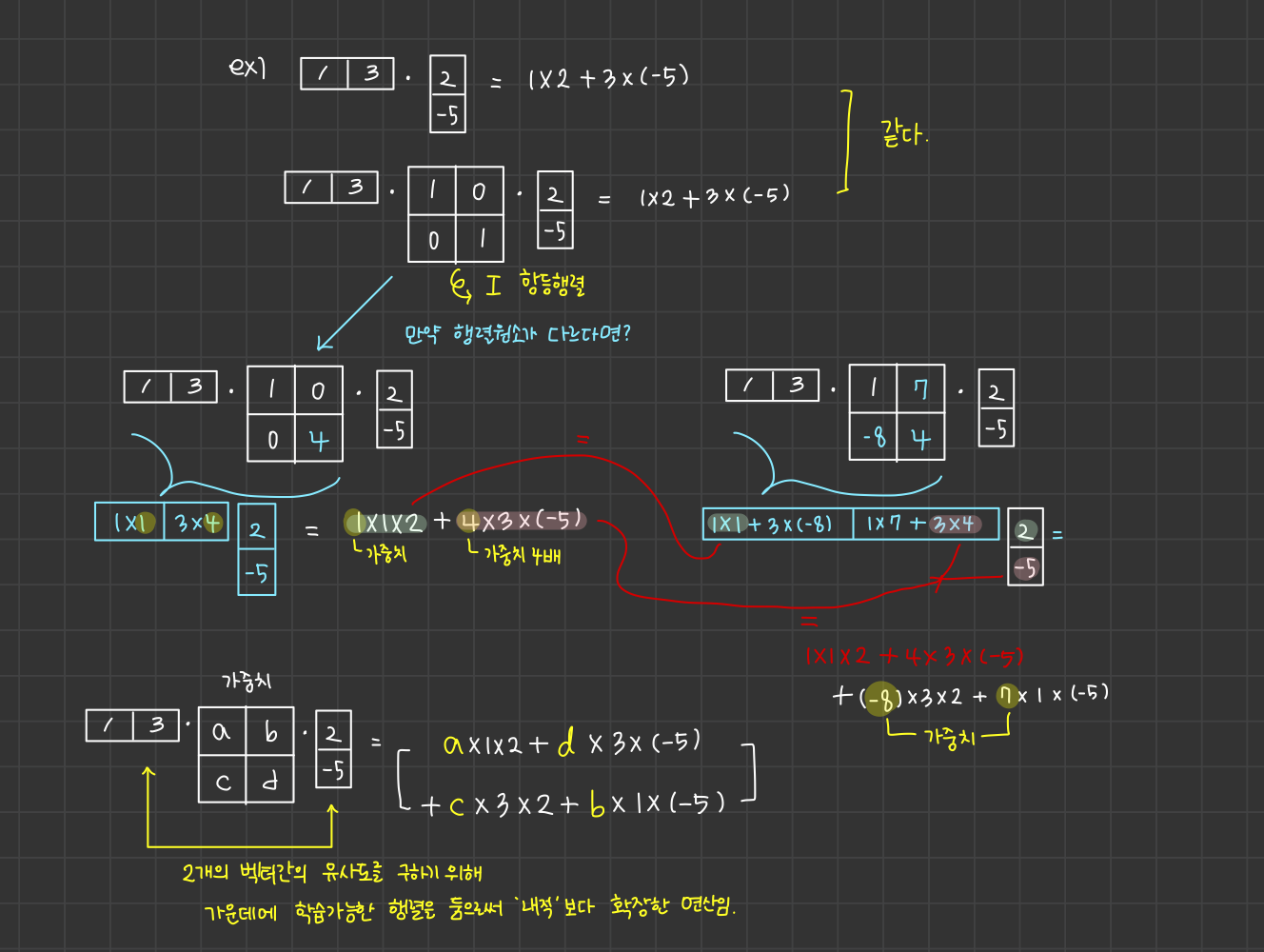
- 와 encoder의 모든 hidden state vector들을 내적해
유사도값(Attention scores) 계산 → 단어 예측을 위해 어떤 hidden vector가 필요할지 선정하는 작업
softmax를 통해 합이 1인유사도 가중치값Attention-Vector 생성
위의 2, 3번을 통합해Attention Module이라고 부른다.
Attention Module의 input: ( , )
- Attention의
output vector와Decoder의 hidden vector를concat하여 output layer의 input으로 준다. ()
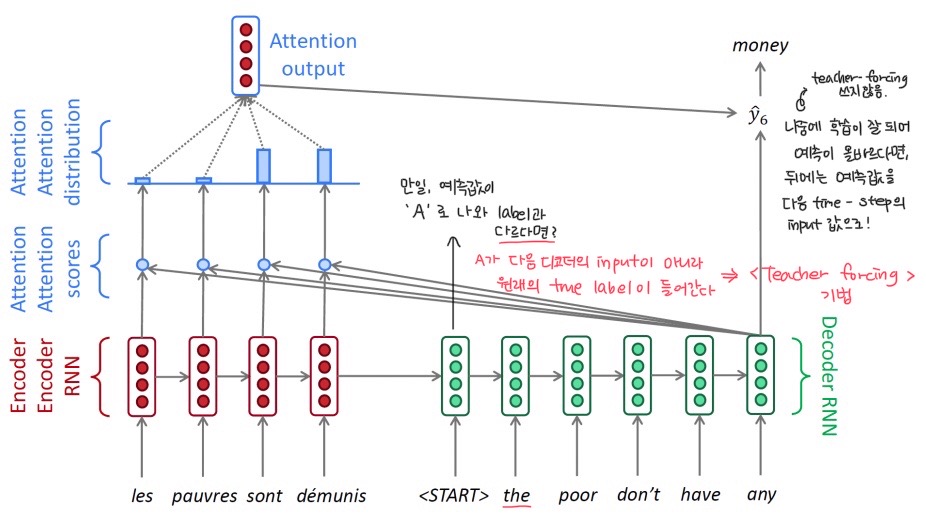
- Teacher-forcing 기법
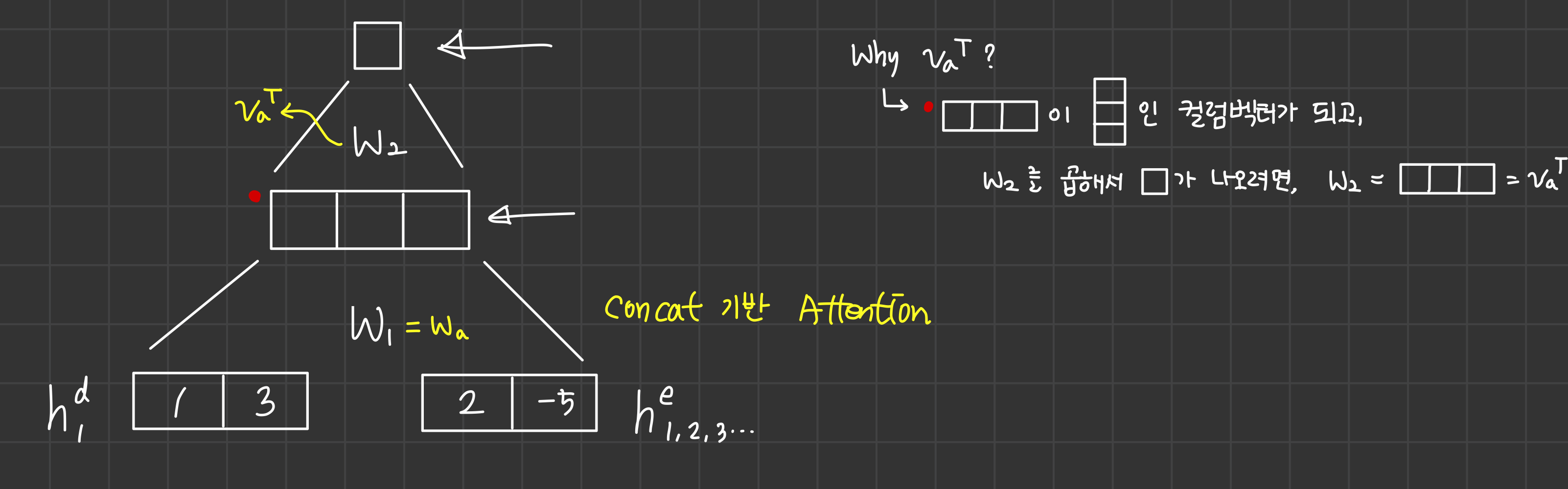
🍏 유사도를 구하는 다양한 방법 (Attention Mechanisms)

🚩 Beam Search
- 자연어 생성 모델에서 보다 더 좋은 단어 생성 결과를 얻기 위한 기법
🟨 Greedy Decoding
시퀀스의 전체적인 문장 확률 값을 보는게 아니라 근시안적으로 현재 time step에서 가장 확률이 높은 단어 후보를 선택하는 디코딩 방법
Problem
me with을 생성하지 못하고 다음 단어인 a라고 생성해버린다면?
🙌🏻 Solution = Beam Search
- 디코더의 매 time step마다 확률이 높은 빔의 개수(k)를 골라서 진행한다.
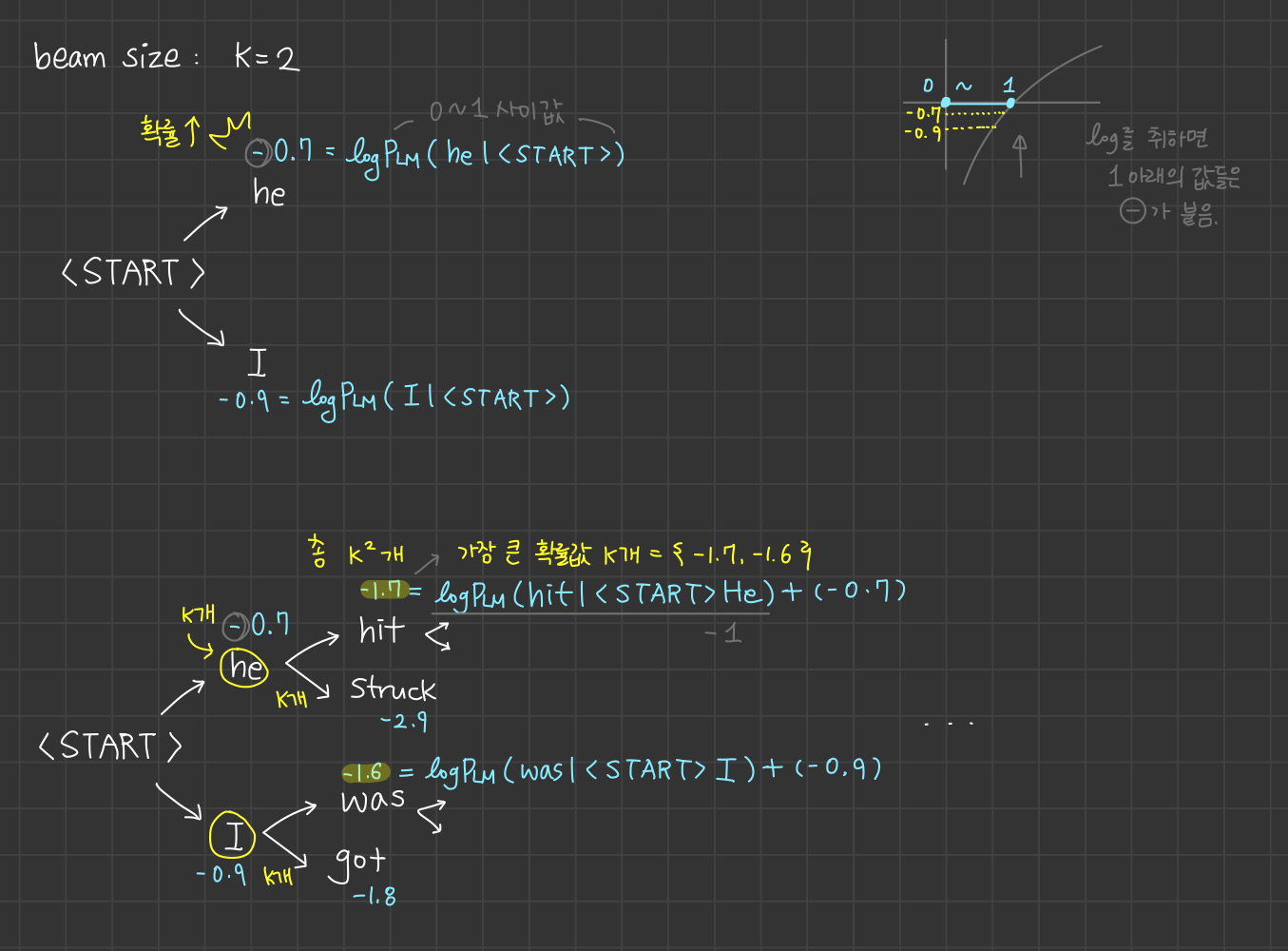
- greedy decoding은 현재 시점에서 다음 예측 단어로 <END> 토큰을 예측했을 때 단어 생성을 끝낸다.
- Beam search는 다른 hypotheses를 갖고 다른 시점에서 <END> 토큰을 생성할 수 있다.
- 어떤 hypothesis가 <END> 토큰을 만나면 그 경로는 완료 처리
- 임시 메모리 공간에 완료된 경로를 저장해둔다.
남은 경로들은 <END> 토큰을 만날 때까지 decoding 수행
Beam search는 임의의 시점 T에 도달할 때까지 디코딩 수행하거나,
완료된 hypotheses가 메모리 공간에 임의의 n개 이상 찼을 때 디코딩을 종료한다.
- 빔 서치가 끝나면, 메모리 공간에 있던 completed hypotheses 를 얻는다.
- 그 중에 가장 큰 확률을 갖는 score 1개를 뽑는다.
- 문제점: 누적 확률 계산이므로 계속해서 log를 취해 누적하여 계산할수록 누적 확률 값이 점점 작아진다. (= 문장 길이가 길수록 누적 확률 값 ↓)
🚩 BLUE score
- 예측 결과의 정확도를 평가하는 평가 지표
- 각 시점의 본 단어와 예측 단어의 정답 유무를 보는 것이 아니라 전체적인 관점에서 문장 간의 유사함을 따질 수 있는 평가 지표를 사용해야 한다.
- precision (정밀도)
검색 시스템에서 내가 무언가를 검색했을 때 (우리에게 노출되는 경우) 얼마나 내가 원하는 문서들이 추출되었는가?- recall (재현율)
검색 시스템에서 해당 키워드에 관련된 문서가 10개가 존재하는데, 검색 결과로 7개밖에 나오지 않았을 때 (우리에게 노출되지 않음)다른 기준에 의해 나온 2개의 평가를 종합해서 하나의 결과로 나타내고 싶다!
→ 산술 평균
→ 기하 평균 (2개의 값을 곱하여 루트)
→ 조화 평균 (2개의 값을 역수를 취한 뒤 산술 평균을 구한 값의 역수)
- F-measure (조화 평균) : 작은 값으로 나오게끔 평균 내겠다
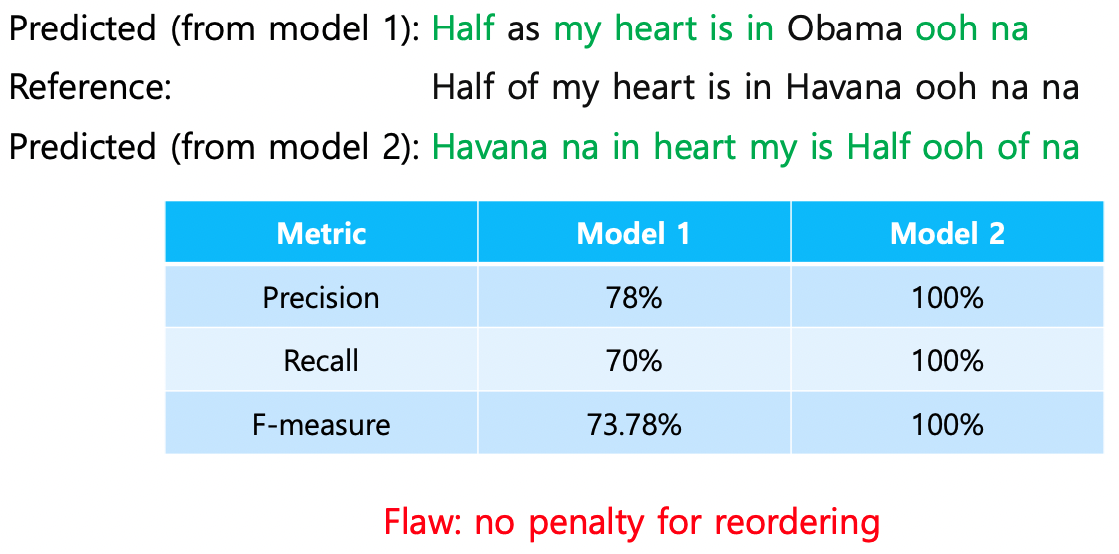
🟨 예제
- Model 2는 단어의 순서가 다르지만, Ground truth 단어들이 전부 존재하기에 100%의 평가값이 나온다.
→ 문법적으로 말이 되지 않는 문장이 예측된다. <문제점>
→ 🙌🏻 Solution: BLEU score
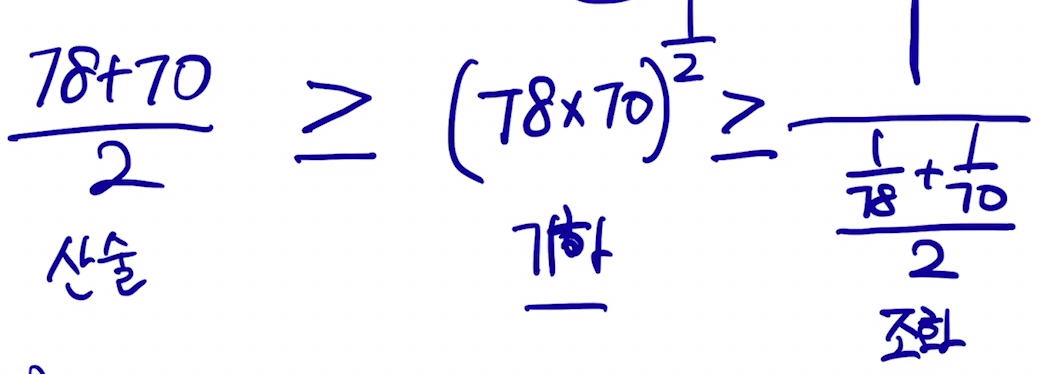

🟨 BLEU score
- 단어 요소 하나하나 다 완벽하게 번역되었는가? 가 아닌,
(N-gram) 연속된 N개의 요소가 연속적으로 얼마나 같은가 (연속적으로) - Precision 평가 방식으로 계산한다.
-
는 기하 평균을 적용 → 평균 중 낮은 것에 치중하겠다
- 위의 식에는 4가 들어가있지만, 인 n-gram을 사용하기 때문이다. (n-gram precision의 기하평균을 위한 것)
-
이 1이 넘어가면 (예측 문장의 길이가 길어진다면) 값 = 1
-
Brevity penalty : reference의 길이 대비 예측된 문장 길이가 짧아짐에 따라 penalty를 부여하는 것.
length of prediction / length of reference비율이 1보다 작을 경우, BLEU score에 1보다 작은 값이 곱해지면서 패널티 부여
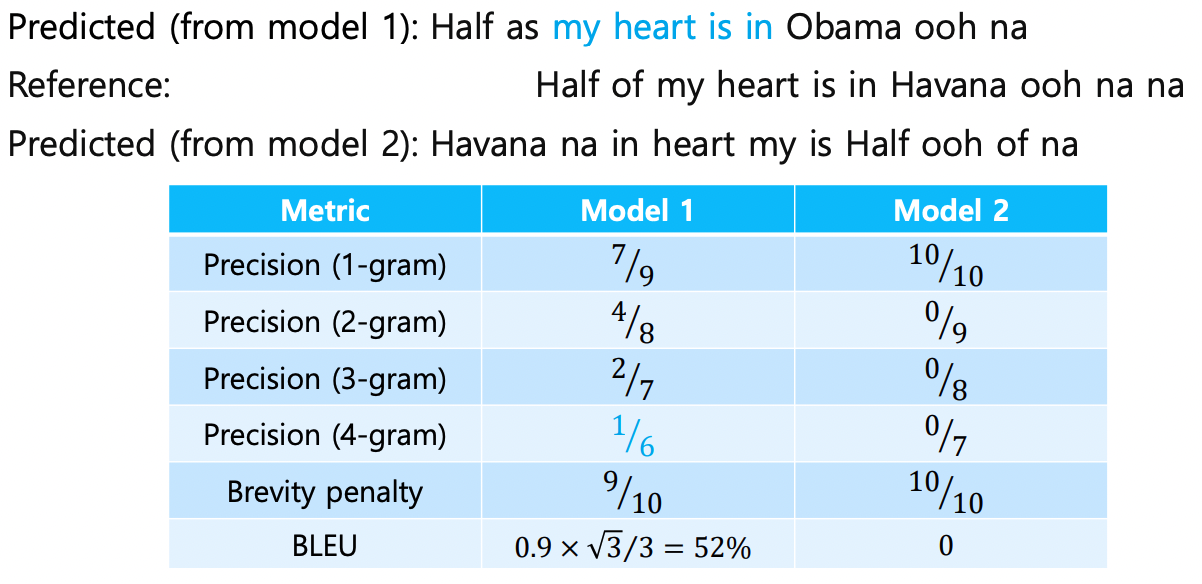
- Precision (1-gram) : 개별 단어씩
- Model 1: Reference 문장에 비해 9개의 단어 중 7개 예측 성공
- Precision (2-gram) : 단어 2개씩 묶어서 (Half as, as my ...)
- Model 1: 2개의 연속된 단어 묶음이 8개 중 4개의 연속 묶음이 같음
- Brevity penalty : 생성된 단어 개수와 본 문장의 단어 개수 비교
- Model 1: 단어 10개가 아닌 9개를 생성했으므로 (정답 유무 중요 X)
- BLEU : Brevity penalty * 모든 Precision을 곱하고 4제곱근

배우고 싶은게 많은 개발자📚