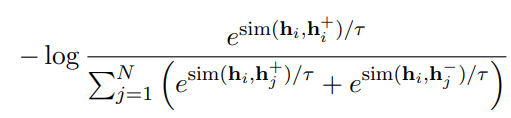0812
해당 논문은 Contrastive Learning을 활용한 Sentence Embedding framework인 SimCSE를 제안한다.
Introduction
- Universal 한 sentence embedding을 위한 방법론 계속 연구되고 있음 (in NLP)
- 해당 논문은 Contrastive Learning을 PLM과 결합했을 때 더 나은 성능을 보이는 것을 확인
- 또한 Unsupervised approach, Supervised approach를 모두 제안하여 unlabeled / labeled data 에 모두 적용되는 방법론이다.
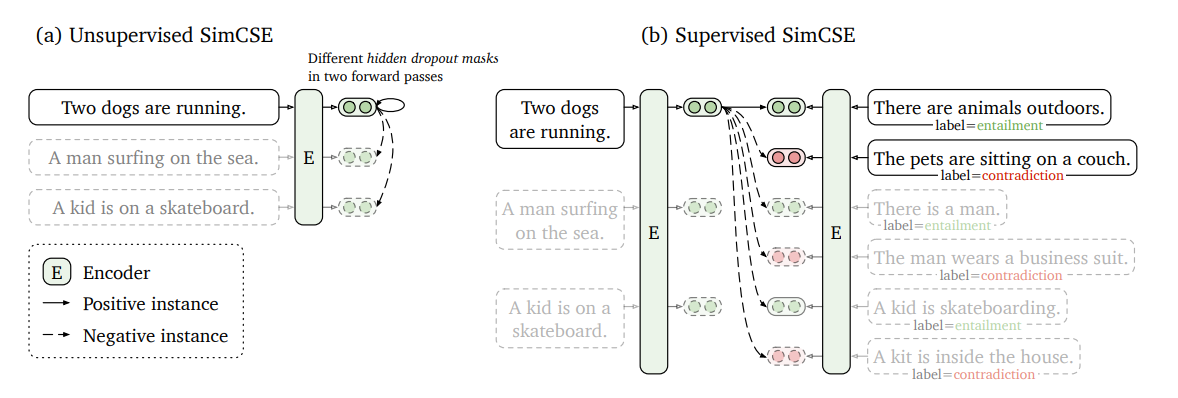
(a) Unsupervised SimCSE
"drop out"을 노이즈로 활용
- pt 된 인코더에 같은 문장을 두 번 넣음, 대신 drop out을 다르게 적용
-> 같은 문장에 대해 두 가지 다른 임베딩 값을 얻을 수 있다. (=positive pairs) - 같은 배치 내 다른 문장들을 통해 얻은 임베딩 값 = negative pairs
--> 모델은 (-)들 사이에서 (+)를 예측하는 방식으로 학습됨!
간단하면서도 NSP, discrete augmentation의 성능을 능가함
(b) Supervised SimCSE
"NLI datasets" 활용
- entailment pairs가 positive 로 활용될 수 있다는 점에서 착안
- 마찬가지로 contradiction pairs는 negative로 활용 --> hard negatives 로써 더 좋은 성능 달성
- 나머지 in batch 문장들에서 나온 임베딩 값도 negative로 활용
--> NLI datasets 이 sentence embedding에 효과적임을 확인
어째든 제안하는 방법은
1) Sentence Embedding에 Contrastive Learning을 적용했다는 점,
2) unsupervised 한 pair 생성 방법을 제안했다는 점인 것 같다.
Background : Contrastive Learning
Contrastive learning을 활용했을 때의 contribution ?
- Anisotropic
: 이방성, embedding space가 좁다. 고르게 분포되어있지 않음
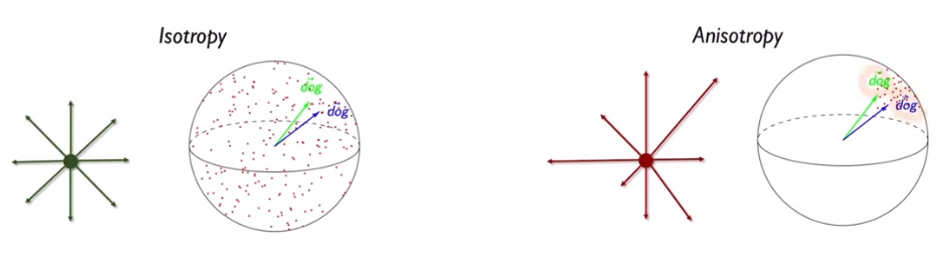
- dog, dogs 가 가까이 위치하더라도 스페이스 자체가 좁아서 좋은 representation 이 아님
- 동일한 단어가 다른 문맥에 등장했을 경우, context에 따라 거리가 가깝지만 다른 의미를 지니는 것은 좋음 → 이러려면 embedding space 가 넓고 고르게 분포되어야 함
-> embedding space 가 hypersphere에서 넓고, 고르게 분포하여 각 단어가 고유한 의미를 보존하는 것은 중요함 --> uniformity의 중요성!
따라서, CL을 통해 학습하면
-> (-)을 (+)와 멀게 하는 과정에서 embedding space를 균일하게 분포하도록 만들 수 있음
-> Alignment and Uniformity
[참고]
Unsupervised SimCSE
- Transformer 구조에서 drop out mask는 fc layer, attention 계산 시 적용됨
- x와 x+에 독립적인 dropout mask를 적용한다.
- Training objective는 다음과 같다.
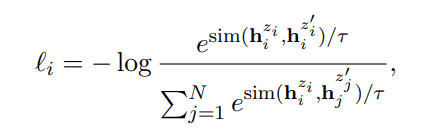
- 분자 = 같은 sentence에 다른 drop out 적용한 두 임베딩의 유사도
- 분모 = 다른 sentence에서 얻은 두 임베딩의 유사도
- 분자는 클 수록, 분모는 작을 수록 전체 loss 값은 작아짐
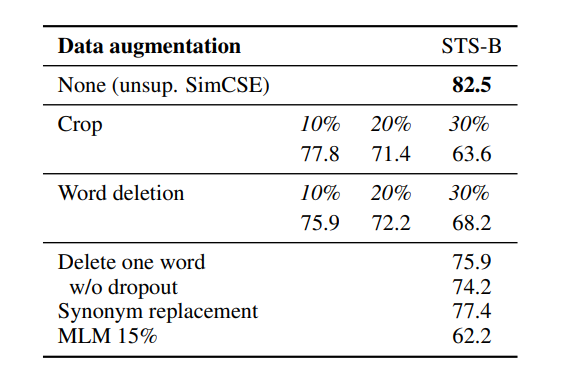
- 비교 실험 1 : Data augmentation
다른 Data augmentation vs drop out 방법
- 비교 실험 2 : Training objectives
다른 Training objectives vs SimCSE의 Contrastive loss 방법
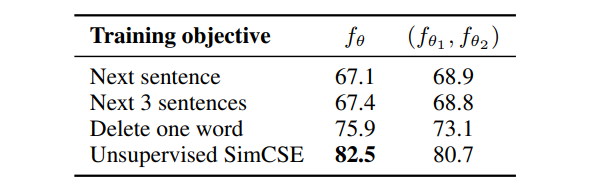
- 하나의 인코더를 사용했을 때의 성능이 더 좋음
- 하나의 인코더를 사용했을 때의 성능이 더 좋음
Supervised SimCSE