Paper Review
1.트랜스포머 기반 다변량 시계열 회귀

1. Transformer 자세한 구조는 https://velog.io/@hyeda/transformerbert 에 정리 2. Transformer의 시계열 데이터 적용 Transformer를 다변량 시계열 데이터에 최초로 적용한 논문 [A Transformer
2.[논문 리뷰] LoRA: Low-Rank Adaptation of Large Language Models
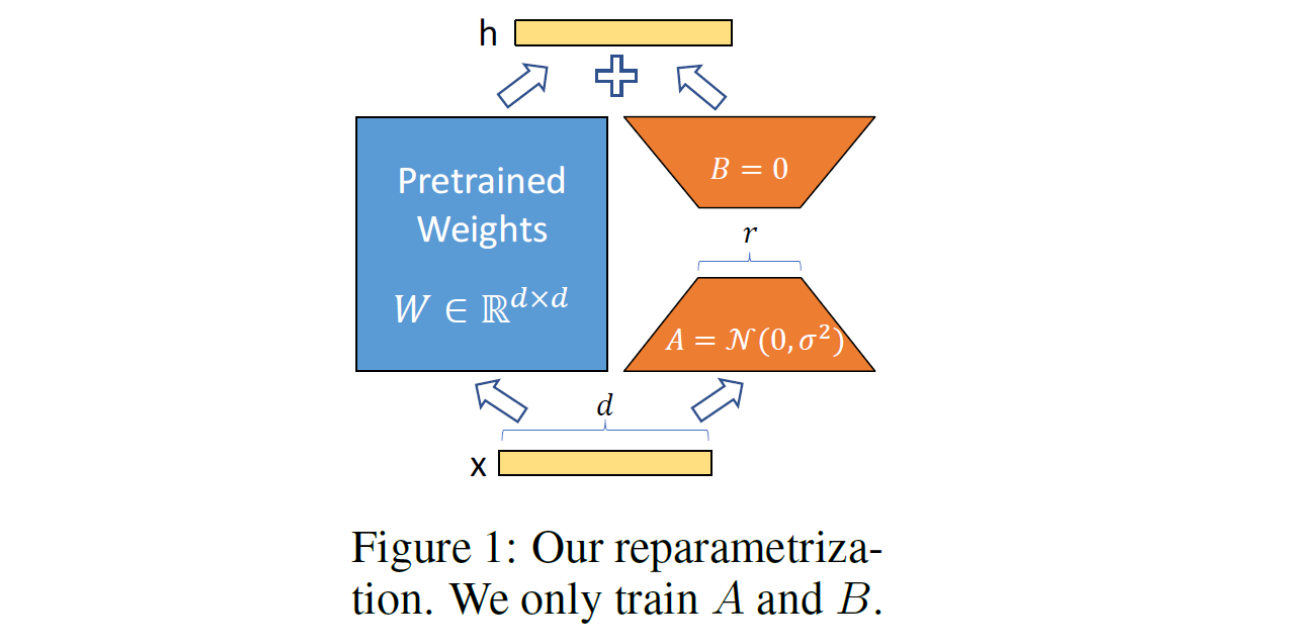
Prompt-based learning을 알아보다가, prompt-based learning의 한계점을 극복할 Parameter-Efficient Learning methods를 알아보았고, 그 중 LoRA라는 논문을 중점적으로 정리해보았다.reference : htt
3.Prompt-based Learning_soft prompt를 중심으로

PPT: Pre-trained Prompt Tuning for Few-shot Learning 논문 리뷰를 통해1) soft prompt에 해당하는 방법론을 간단히 정리하고, 2) 논문에서 제시한 prompt-tuning과 Clipcap의 아이디어인 prefix-tun


6.[논문 리뷰] VL-LTR_ Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition

.
7.[논문 리뷰] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
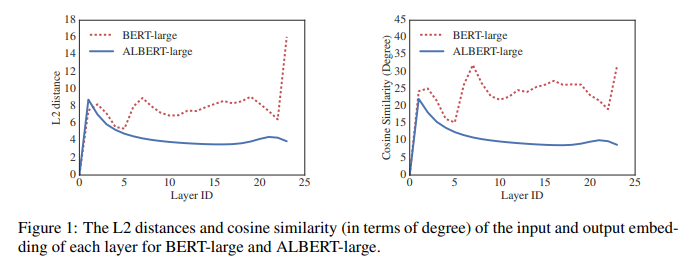
Paper : ALBERT: A Lite BERT for Self-supervised Learning of Language Representations ALBERT 핵심 요약
8.[논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach
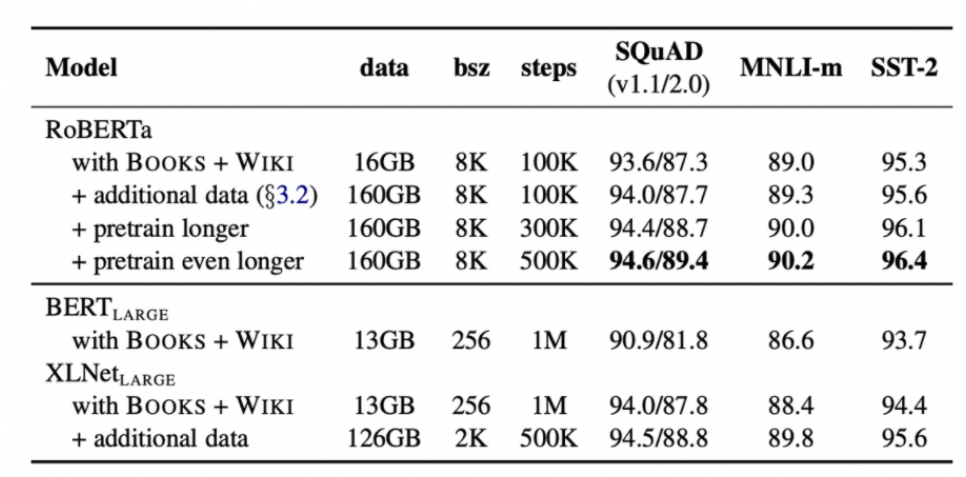
bert의 replication study인 RoBERTa 논문을 리뷰, 정리 해보았다.
9.QA 논문 리뷰, 실습
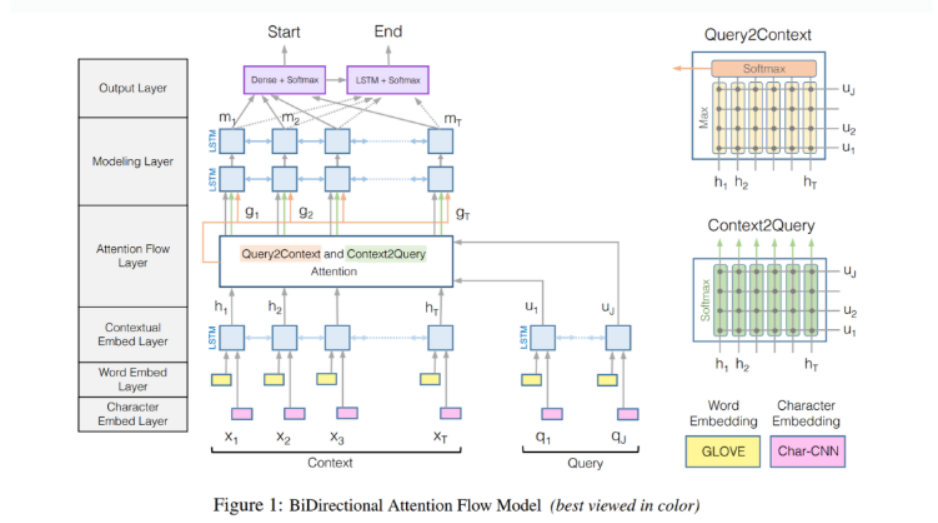
_해당 포스팅은 QA와 관련된 논문 스터디를 진행 중에 공부했던 'Question Answering on SQuAD 2.0' 이라는 논문을 정리해보면서, 1) 기존 'BIDAF'모델과 ' non-PCE Question Answering model'을 비교 분석 해보고,
10.[이론, 코드] Transformer~BERT 리뷰
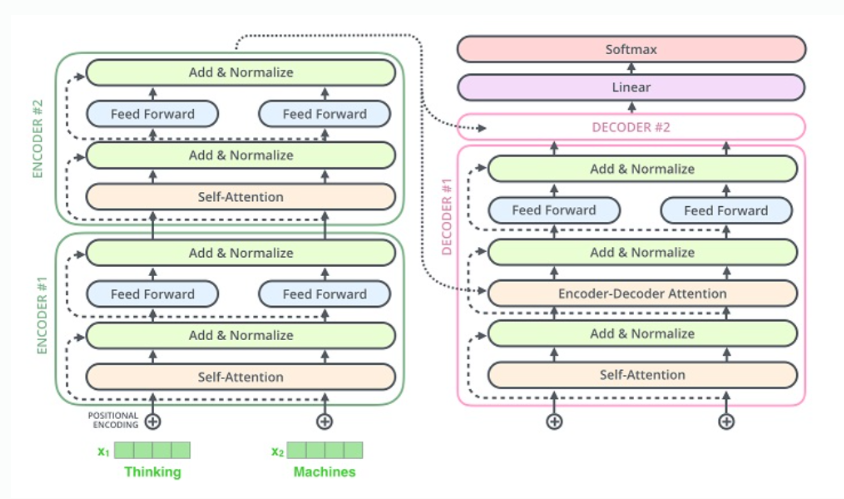
BERT 모델을 복습하고자 해당 페이지에 정리해보았다! BERT를 이해하기 위해 우선 Transformer 구조부터 알아야한다. Transformer Paper: Attention is all you need 인코더, 디코더 구조를 지닌 딥러닝 모델. 기존의 seq
11.SimCSE: Simple Contrastive Learning of Sentence Embeddings
0812 해당 논문은 Contrastive Learning을 활용한 Sentence Embedding framework인 SimCSE를 제안한다. [논문] Introduction Universal 한 sentence embedding을 위한 방법론 계속 연구되고