RocksDB의 데이터 저장방식
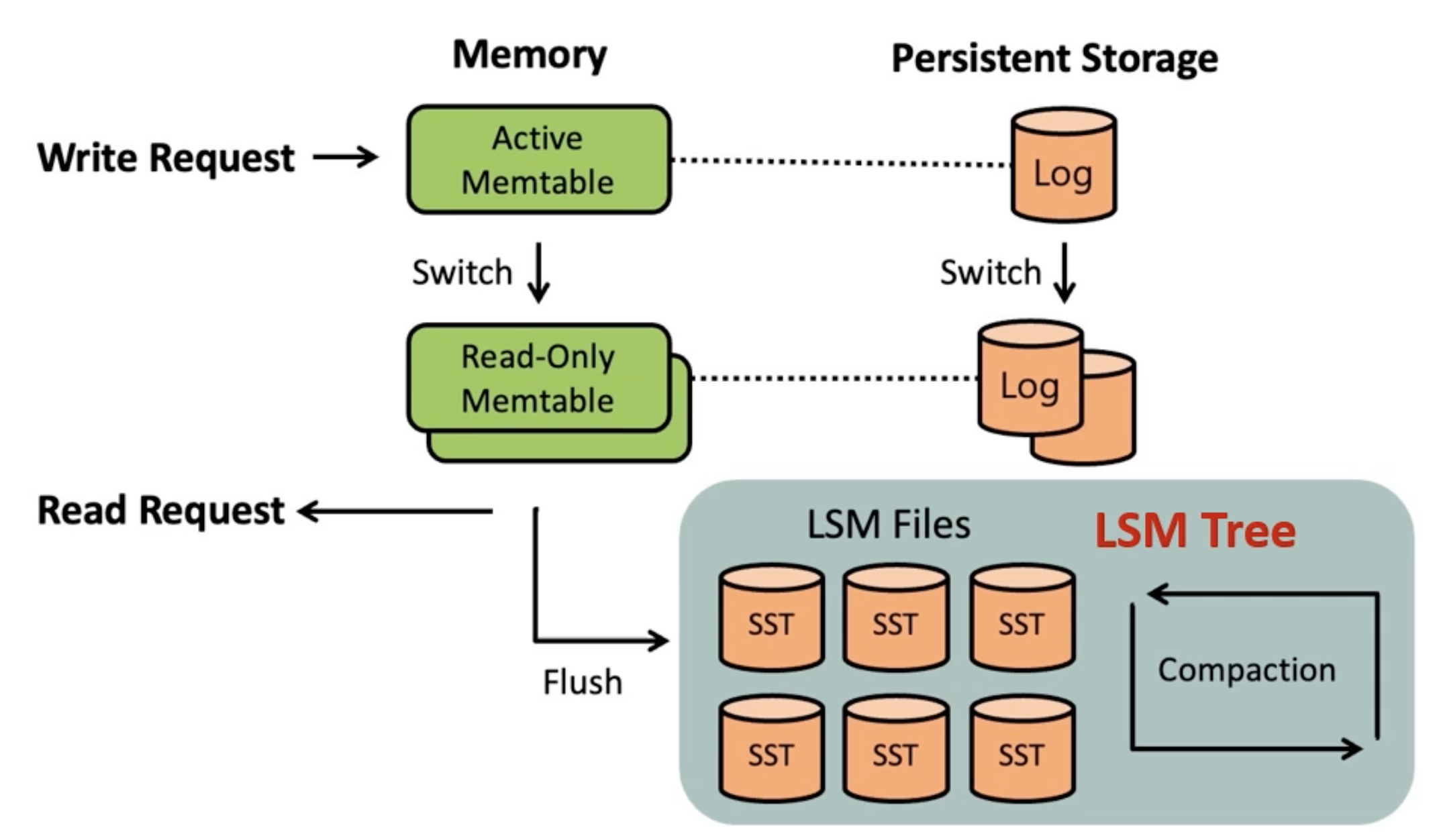
RocksDB는 데이터를 Key-value 쌍의 형태로 저장 및 관리한다. 이는 다른 관계형 데이터베이스와 달리 비정형 데이터 처리에 도움을 준다. 다른 RDBMS는 정형적인 데이터, 즉 각 속성(Attribute)가 정확히 정해져 있는 데이터들을 차곡차곡 테이블에 넣고 각 관계를 이용해 저장 및 관리하는 형태이므로, 속성들이 명확히 정해지지 않은 비정형 데이터 관리가 힘들기 때문.
그리고 이 구조에서 높은 데이터 처리 성능을 위해 Log Structured Merge-Tree(LSM-Tree)라는 구조를 사용한다. 이것은 순차 쓰기를 유도해서 쓰기 성능이 우수하지만, 데이터 관리를 위해 수행되는 Compaction 과정 중에 부가적인 쓰기와 공간 사용을 필요로 한다.
당연히 쓰기가 늘어나면 데이터베이스 처리 성능이 저하된다. 이에 더하여 실제로 저정한 데이터보다 많은 양의 데이터를 저장해야 하기 때문에 데이터베이스 운영 측면에서 부담이 가중된다.
Compaction
이는 서로 다른 크기를 갖는 각 계층(level)의 임계점을 초과할 때 동작하는 것이다. 임계점을 초과한 계층에 있는 파일(victim SST)를 선택하고, 해당 level의 하위 level에서, 선택된 파일의 키 범위와 중복된 키 범위를 갖는 파일들(overlapped SST)를 선택해서, 이들을 병합하고 새로운 파일(Newly generated SST)로 만든다. 이렇게 만들어진 파일은 하위 level에 저장된다.
정리하자면
- Remove multiple copies of the same key
- Process deletion of keys
- Merge SST files to a bigger SST file
즉, 임계점을 초과한 계층에 존재하는 파일을 하위 계층으로 내려, 공간을 확보하는 작업이다.
Leveled Compaction
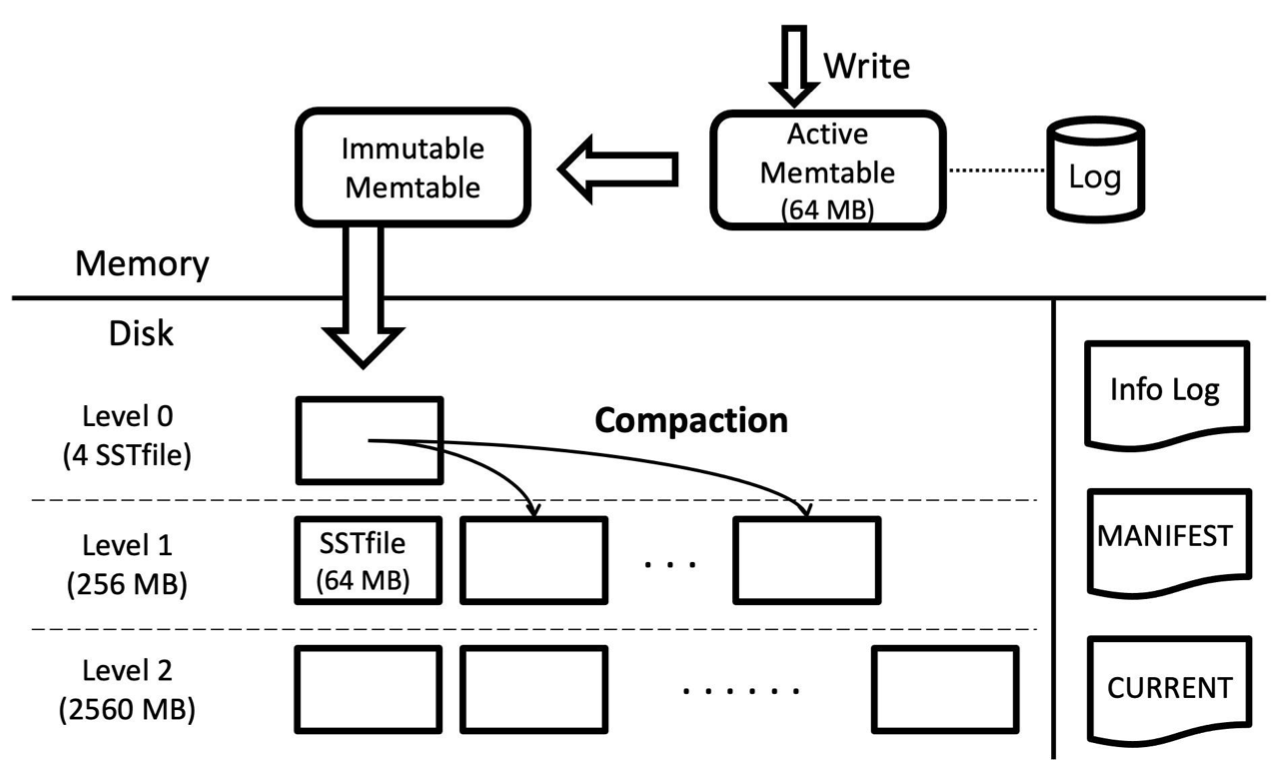
이게 RocksDB의 기본적인 과정이며, 가장 최근에 수정된 데이터가 L0에, 그리고 가장 오래된 데이터가 Lmax에 존재하는 방식으로 계층을 구분한다. L0의 SST 개수가 임계점을 넘어가면 해당 파일이 중복된 key를 갖는 파일과 병합됨과 동시에 정렬되면서 한 단계 내려가는 방식이다.
- L0은 Memtable에서 방금 flush된 파일들이 저장되는 장소이다. 따라서 Overlapping keys가 존재하고, flush time에 따라 정렬되어 있다. 그냥 들어온 순서대로 저장해뒀다는 것이다.
반면 L1~Lmax에는 Non-overlapping key가 존재하며, key에 의해 정렬된 상태로 데이터를 보관한다.
http://delab.yonsei.ac.kr/assets/files/publication/domestic/conference/KIPS_C2020B0294.pdf
(데이터베이스 성능 향상을 위한 기계학습 기반의 RocksDB 파라미터 분석 연구, 김휘군, 2020 온라인 추계학술발표대회 논문집 제27권 제2호)

이해가 쏙쏙 !