Amplification Factors
세 가지 type가 있다.
Space Amplification= the size of the database on thefile system/ the size of theuser datain the database- 실제로 DB에 10MB의 데이터를 삽입했는데, DB가 storage에서는 100MB를 점유하고 있다면, space amplification = 10
Write Amplification= the number of bytes written to the disk / the number of bytes written of the database- 실제로 DB에는 10MB의 write 요청을 보냈지만 storage에는 30MB의 disk write rate가 일어나면, write amplification = 3
Read Amplification= the number ofdisk reads/ the number ofqueries- 만약 한 query를 완수하기 위해 disk read가 5회 필요하다면, read amplification = 5
이 세 가지 amplification factor는 서로 TRADE OFF관계이다.
Implications of Space Amplification
- Cost efficiency
- 사용하는 space를 줄이면, 당연히 Storage Device의 수를 줄일 수 있다.
- HDD -> SSD로 변하면서 price per GB가 매우 커졌다.
- 앞서 확인했듯, Amplifications들끼리는 Trade Off 관계라서, 싼 HDD를 주로 쓰던 과거에는 Space Amplification을 늘리는 것이 Acceptable했다고 한다. 하지만 이렇게 SSD로 넘어오면서는 Wasteful한 방법이 된 것.
- 특히 Space Amplification이 늘어나면 Data center나 Cloud Service Providers에게 큰 타격이 됐다
=> 최적화를 해야하는 것.
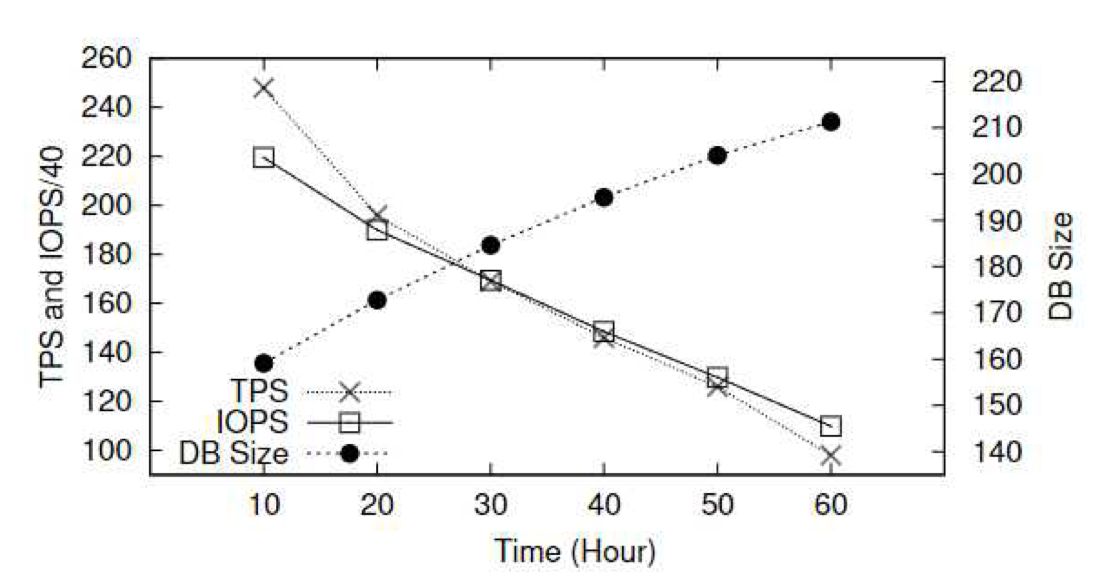
- Effect on flash SSDs
- SSD의 특징 중 하나로 DB 사이즈가 커지면
- TPS(Transaction Throughput per Second)이 줄어들고,
- Read & Write IOPS(Input/Output Operations per Second)가 떨어지며,
- SSD의 기대 수명(Life expectancy)도 떨어진다.
Space Amplification in LSM-Tree
여기서 Space Amplification이란, How much stale data is yet to be garbage-collected인지로 결정된다.
Victim SST와 Overlapped SST가 merge되면서 내려갈 때, 이들은 Merge Sort를 통해 새로운 파일(Newly generated SST)로 생성된다는 것은 알 것이다. 이때 Compaction에서 선택된 파일(Victim & Overlapped)은 더 이상 쓸 일이 없는, Invalid SST로 관리되는데, 이들은 시스템의 Grabage Collection이 삭제해 줄 때까지 남아있다.
이로 인해 Space amplification이 나타난다고 이해할 수 있을 것이다.
Params of RocksDB
Memtable
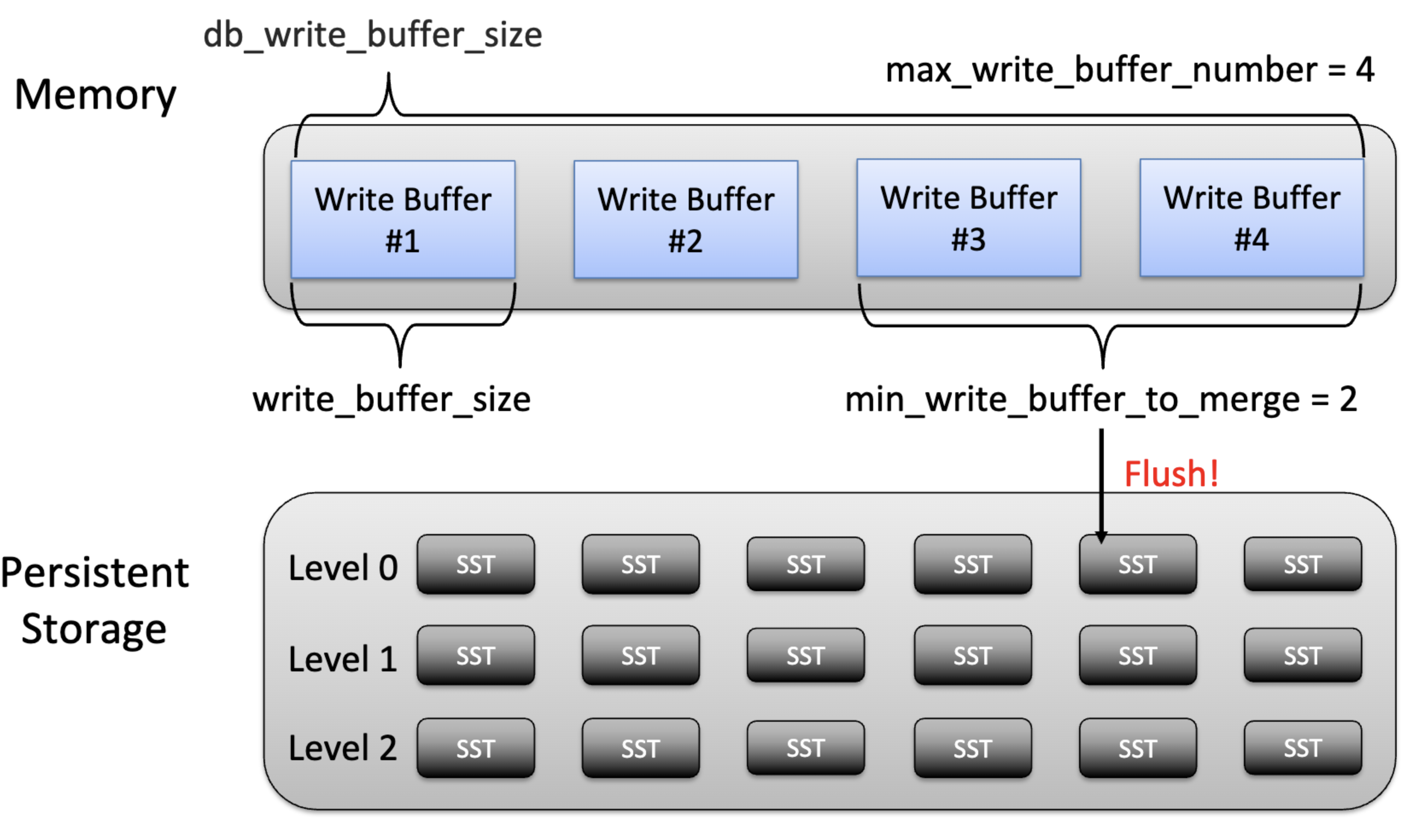
write_buffer_size: Compaction이 되기 전인, memtable에 존재하는 single buffer의 크기(number of bytes) 결정.- 이것이 초과되면 immutable이라는 mark가 붙고 새로운 buffer가 생긴다.
max_write_buffer_number: 메모리 상에 존재하는 memtable의 최대 개수. Active memtable과 immutable memtable의 개수를 합산했을 때의 최댓값으로, 이 둘의 값이 max_write_buffer_number보다 커지면 밑으로의 write가 시작된다. (buffer 개수임. byte아님)- 검색해 보니 여기까지 커져버리면 모든 write를 다 정지시키고 flush가 끝날 때까지 기다리는 듯.
min_write_buffer_to_merge: storage에 저장(L0으로 flush)되기 위해 채워야 하는 memtable의 최소 개수.- 여러 memtable이 함께 merge되면 write를 줄일 수는 있으나, read 과정에서 아직 메모리에 있는 많은 immutable memtable에 순차접근해야 하므로 read amplification이 늘어난다. read performance 줄이는 것.
db_write_buffer_size: set total memory size(역시 byte단위)
LSM tree에는 두 가지 background process가 있다. 하나는 Flush이고, 다른 하나는 Compaction이다. 여기서 flush가 더 high priority를 갖는다.
flush는 가득 찬 activate memtable이 immutable memtable로 변화한 후에 이 immutable들을 storage로 write하는 과정이다.
compaction은 이전에 본 것처럼
1. Merge SSTable files.
2. Remove deleted key from the file.
3. new SSTable file is created and put into the same(overlapped SST 기준인듯) or different level(victim SST 기준인듯)
- max_background_jobs: 그래서 이러한 background job을 돌리는 (thread인듯) 놈 개수가 몇 개인지 결정.
- max_background_compactions, max_background_flushes가 있는데, 말 그대로 각 job을 돌리는 백그라운드 Thread가 몇 개인지 결정해 주는 것.
Storage(Leveled Compaction)
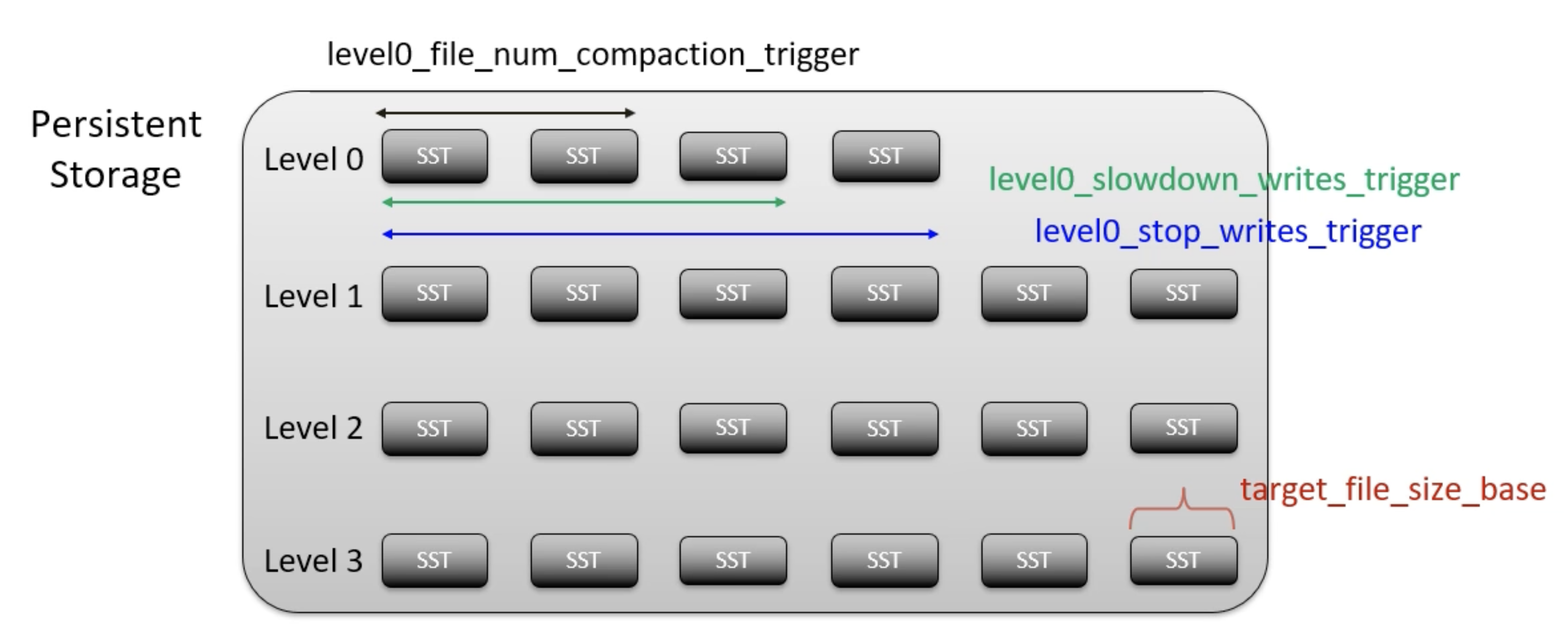
- level0_file_num_compaction_trigger: L0에서 Compaction이 일어나기 위한 file의 개수를 지정하는 것.
- 이 값을 늘리면 Compaction이 '덜'일어난다는 것이고, single compaction이 한 번에 더 많은 데이터들을 merge해야 한다는 것.
- level0_slowdown_writes_trigger: default로 Compaction이 더 low priority인 것은 앞서 설명했는데, 그래서 언제까지 그렇게 낮은 우선순위를 유지할 것인지를 나타내는 파라미터라고 한다.
- 검색해 보니 L0 SST file 개수가 level0_slowdown_writes_trigger에 도달하면 모든 write를 정지하고 L0에 있는 SST를 어느 정도(어느 정도인지는 모르겠네) Compaction할 때까지 기다리는듯.
- level0_stop_writes_trigger: slowdown이랑 비슷하긴 한데 file 개수가 여기에 도달하면 RocksDB가 모든 write process를 멈춰버리고 이걸 1순위로 처리해서 L0을 Compaction.
- target_file_size_base: Single SSTable file 크기를 결정하는 것.
- 검색해 보니 이는 Level-1에 적용된다고 함. 그러니까 level 1 ~ level max까지는 적용되겠지. L0에는 안 되는 거 같음.
