
1. Pandas
- 관계형, 혹은 레이블로 된 데이터를 쉽고 직관적으로 작업할 수 있도록 설계된 빠르고 유연한 데이터 구조를 제공하는 Python 패키지
- 주요 특징
- 데이터 조작을 위한 DataFrame 객체 지원
- 인메모리 데이터 구조와 csv, txt, excel. sql과 같은 다양한 형태 지원
- 시계열과 비시계열 데이터를 같이 다룰 수 있는 데이터 구조 제공
- Finace, Neuroscience, Economics, Statics, Advertising, Web Analytics와 같은 다양한 분야에서 사용
(1) Pandas 자료 구조
- Series(1차원)와 DataFrame(2차원) 자료 구조(Object)가 존재
- Numpy Array를 기반으로 함
- 다차원 배열(ndarray)을 위해 설계된 Numpy와 다르게 2차원 데이터 구조에 특화
- Numpy 1차원 배열의 경우 행 우선이지만 Panda 시리즈의 경우 열 우선
- Numpy 배열은 Index로 위치만 오지만, Pandas의 경우 이름(문자)도 올 수 있음
- DataFrame은 여러 개의 Series를 Key(칼럼명)로 접근하는 구조로 Dictionary와 유사
(1)-1 Series
- Pandas의 기본객체이며 1차원 배열
- Series() 함수를 사용
pandas.Series(values=[], index=[])- Series 생성시 index 매개변수를 이용하여 이름 지정 가능
- index 매개변수를 이용할 때 데이터의 개수와 인덱스의 개수는 동일해야 함
- 다양한 데이터 타입을 섞어서 사용하는 경우
- 범위가 더 큰 타입의 숫자로
- Series에 다양한 데이터 타입의 데이터로 생성시 object타입으로 생성
(1)-2 DataFrame 생성
- 표와 같은 스프레드시트형식의 2차원 자료 구조(row, column으로 구성)
- DataFrame() 함수를 사용
pandas.DataFrame(values=[], index=[], columns=[])- 각 column은 서로 다른 데이터타입을 가질 수 있음
(1)-3 Series와 DataFrame 생성 시 사용되는 데이터는 리스트, 배열뿐만 아니라 딕셔너리도 올 수 있음
- Series의 경우 key가 행 인덱스로 지정 (index)
- DataFrame의 경우 key로 열 인덱스로 지정 (columns)
(2) Pandas 입출력
- 다양한 데이터 파일 유형을 읽어오거나 해당 유형으로 저장할 수 있음
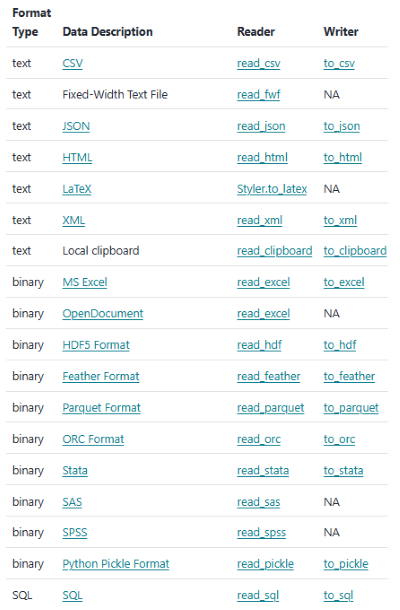
- csv파일 읽기/저장 : read_csv / to_csv 함수 이용
- excel파일 읽기/저장 : read_excel / to_excel 함수 이용
(2)-1 CSV 파일 저장
- index를 False로 지정하면 index를 저장하지 않음
- 인코딩형식을 지정할 수 있음 (기본값은 'utf-8')
data = [['A',3,1,'X'], ['A',1,2,'X'], ['A',0,5,'Y'],
['B',1,6,'X'], ['B',7,2,'Y'], ['B',3,3,'X'],
['C',2,4,'X'], ['C',1,1,'Y'], ['C',0,2,'X']]
df = pd.DataFrame(data, columns=['A','B','C','D'])
df.to_csv('data1.csv')
df.to_csv('data2.csv', index=False)(2)-2 csv 파일 읽기
- 파일의 형식이 'utf-8'이 아닌 경우 인코딩(
encoding) 형식을 지정해야 함 - 열과 열을 구분하는 구분자가 콤마(,)가 아닌 경우 구분자(
sep)을 지정해야 함 - 데이터가 너무 커 분할해서 데이터 로드 시
chunksize매개변수를 활용항여 설정 가능
pd.read_csv('data1.csv')
chunk = pd.read_csv('data2.csv', chunksize=3, skiprows=0)
chunk.get_chunk()(2)-3 Excel 파일 저장
- index를 False로 지정하면 index를 저장하지 않음
- sheet_name을 통해 시트명 지정 가능
- 여러개의 시트를 저장하리 위해서는
ExcelWriter를 이용
(2)-4 Excel 파일 읽기
- sheet_name을 통해 읽어올 시트를 지정가능
- sheet_name을 통해 특정 시트의 데이터만 가지고 올 수 있음
- sheet_name=None으로 지정되면, 모든 시트를 가지고 오며, 시트명을 key로 시트데이터를 values로 가지는 사전 형태로 읽어 옴
(3) Pandas 자료 구조 속성
- Series와 DataFrame에서도 속성을 통해 편리하게 조회할 수 있음
- ndim : 데이터의 차원
- shape : 각 차원의 크기
- values : 해당 oject의 값
- index : 해당 oject의 행 인덱스
- columns : 해당 object의 열 인덱스
- index와 columns 속성은 값을 조회하는 것 뿐만 아니라 값을 수정하는 것도 가능함
- 수정하고자 하는 데이터 개수와 대입하는 데이터 개수가 동일해야 함
- T : 해당 object를 전치시킨 결과
- dtype : 특정 컬럼의 데이터 타입 조회
- dtyps : 데이터프레임의 모든 컬럼의 데이터 타입 조회
(4) Pandas 연산
- Pandas에서의 연산은 Numpy와 동일하게 elemnet wise 연산
- [row][col]이 동일한 (인덱스가 동일한) 요소끼리 연산
- element wise 연산 시 위치가 기준이 아닌 인덱스를 기준으로 함
- 중첩되는 인덱스가 없는 경우 결과 값이 NaN으로 설정됨
- DataFrame의 경우 행 인덱스뿐만 아니라 열인덱스도 일치해야 계산이 가능함
2. 인덱싱과 슬라이싱
(1) Pandas Series 인덱싱과 슬라이싱
- Numpy Array에서 사용한것과 동일하게 대괄호([])를 사용하여 특정 요소에 접근할 수 있음
- 단, 위치가 아니라 행 인덱스를 사용한다는 점을 유의
- -1로 가장 마지막 요소에 접근 불가
(2) 문자열인덱스 활용
- Series의 경우 문자열 인덱스를 가질 수 있기 떄문에 이름(문자열)을 통해서도 개별 데이터에 접근 가능
- 인덱스가 문자로 지정된 경우에는 위치(숫자)를 동시에 사용가능
- 문자인덱스를 이용하여 슬라이싱하는 경우 마지막 값을 포함
(3) DataFrame 인덱싱과 슬라이싱
- DataFrame에서 인덱싱과 슬라이싱은 다르게 동작함
- 인덱싱의 경우 열 단위 선택을, 슬라이싱의 경우 행 단위 선택
- 조건인덱싱 : 여러개의 행을 가지고 오고 싶은 경우
- Boolean Series인 경우 True값을 가지는 인덱스를 기반으로 행 선택
- Boolean DataFrame인 경우 True값을 가지는 행인덱스와 열인덱스를 기반으로 선택하며, False값을 가지는 위치는 NaN으로 설정됨
- 팬시인덱싱 : 여러개의 열을 가지고 오고 싶은 경우 (원하는 컬럼을 list로 묶어서 인덱싱)
(4) Indexer
- Pandas에서 데이터 선택은 기본적인 인덱싱과 슬라이싱보다는 Indexer(인덱서)를 이용하는 방법을 주로 권장함
- 기본 인덱싱, 슬라이싱으로 선택된 데이터는 값을 추가/수정 시 오류 발생 가능
- Pandas Indexer : loc, iloc, at, iat
- loc, at : 이름을 기반으로 인덱싱
- iloc, iat : 위치를 기반으로 인덱싱 (i는 integer)
- at, iat : 한개의 값만 반환
dataframe.인덱서[행인덱스, 열인덱스]
(4)-1 loc 인덱서
- 인덱싱 :
dataframe.loc[행, 열] - 슬라이싱 :
dataframe.loc[시작:끝, 시작:끝](끝이 포함됨) - 이름(문자열)의 리스트나 슬라이싱
- boolean리스트, 1차원배열, 시리즈 (데이터프레임은 불가)
# A와 C행, X1과 X2열 선택
df.loc[['A','C'], ['X1','X2']](4)-2 iloc 인덱서
- iloc인덱서를 사용하는 경우에는 행 또는 열 인덱스는 다음과 같은 형식
- 위치(정수)
- 위치(정수)의 리스트나 슬라이싱
- boolean리스트나, 1차원 배열 (시리즈 불가)
dataframe.iloc[행인덱스, 열인덱스]
# X1열의 항목이 짝수인 행의 X1과 X3열 선택
df.iloc[list(df['X1']%2==0), [0,2]](4)-3 at, iat 인덱서
- at, iat 인덱서는 하나의 값만 가져옴
- 빠른 인덱싱 속도가 요구되는 경우 사용
- loc, iloc보다 at, iat이 소모시간이 적음
dataframe.at[행인덱스, 열인덱스]
dataframe.iat[행인덱스, 열인덱스]3. Pandas 함수
(1) 데이터 조회
(1)-1 info()
- DataFrame의 기본정보
- 주로 데이터 개수, 데이터 타입을 동시에 확인할 때 사용
- 인덱스,컬럼, 각 컬럼의 데이터 타입, 메모리사용, 누락 데이터 개수 등의 정보 제공
(1)-2 head(n)/tail(n)
- 첫행(head) 혹은 끝행(tail)부터 n(기본값 5)개의 데이터를 조회
(1)-3 value_counts(sort=Ture, ascending=False, normalize=False)
- Series에서 자주 쓰임
- 값의 개수를 계산하여 내림차순으로 정렬 후 결과 반환
sort=False: 정렬하지 않고 반환ascending: 정렬기준, True=오름차순, False=내림차순으로 정렬normalize=True값의 비율로 반환
(1)-4 sort_values(by, ascending=True, inplace=False)
by<컬럼명>: 특정컬럼을 기준으로 데이터 정렬ascendng: True=오름차순, False=내림차순으로 정렬inplace: 원본데이터 변경 여부, True=원본데이터를 변경
(1)-5 sort_index(axis=0 or 1, ascending=True, inplace=False)
- 행(axis=0) 또는 열(axis=1) 인덱스를 오름차순 또는 내림차순으로 정렬
- 열(axis=1) 지정은 DataFrame에서만 가능
(2) 데이터 컬럼명 변경
(2)-1 전체 컬럼의 이름을 변경할 경우
dataframe.columns = <변경하고자 하는 컬럼 정보>- DataFrame에서만 가능
- 변경하고자 하는 컬럼정보의 개수는 반드시 기존 컬럼의 개수와 동일해야 함
(2)-2 특정컬럼의 이름만 변경할 경우
dataframe.rename(columns={'변경전':'변경후'}, inplace)
series.rename('변경후', inplace)(3) 데이터 타입 변경
(3)-1 astype(str or dict)
- DataFrame의 전체 데이터 유형을 변환하거나 특정컬럼만 변경 가능
- 전체 데이터 유형을 변환하고자 할 경우 변환하고자 하는 데이터 유형을 문자열로 지정
- 특정 컬럼의 데이터 유형만 변경하고 싶은 경우 딕셔너리 형태로 지정
(3)-2 데이터타입을 숫자로 변환
- astype을 이용하여 숫자형으로 변경하고자 하는 경우 에러가 발생할 수 있음
- 숫자형으로 변경이 불가능한 데이터가 존재하는 경우 발생
pandas.to_numeric()을 이용하면 에러유형에 따라 변환방법을 지정 가능errors='ignore': 에러가 발생하지 않고 변경이 안됨errors='raise': 에러를 발생시킴 (기본값)errors='coerce': 에러가 발생한 데이터를 NaN으로 변환
(3)-3 날짜형식의 데이터 타입 변경
panda.to_datetime(dataframe, format)- DataFrame의 컬럼명이 'year', 'month', 'day', 'hour', 'minute', 'second', 'ms', 'us', 'ns'와 같다면 날짜 형식 데이터를 반환
- 자동으로 합쳐져 datetime형식을 반환
(3)-4 날짜 범위 생성
pandas.date_range(start, end, periods, freq)- 특정 날짜/시간 범위의 데이터를 생성가능
- periods : 데이터의 개수
- freq : 주기 ('YS', 'YE', 'MS', 'ME', 'd', 'min', 's')
(4) 데이터 삭제
dataframe.drop(labels, axis, inplace)- labels로 지정된 행(axis=0)또는 열(axis=1)이 삭제된 결과 반환
- 삭제대상이 여러 개인 경우 행 또는 열 인덱스를 []로 묶어서 지정
(5) 데이터 구간별 범주화
pandas.cut(x, bins, right, labels,..)- 연속 데이터를 구간별 범주화
x: 데이터bins: 구간을 나누는 기준right: 구간의 오른쪽 값 포함 여부labels: 구간의 이름
3. Pandas 통계함수
- 데이터에 대한 통계 계산을 Pandas 통계함수를 사용하여 통계값 산출 가능
- Pandas는 배열의 주어진 요소로 부터 최소, 최대, 평균, 분산, 표준편차 등을 찾는데 유용한 통계함수가 존재
- 통계함수는 배열에서 요소별로 작동하며 axis옵션을 통해 연산 방향을 지정할 수 있음
- axis=0 : 행과 행의 연산결과를 반환(기본값)
- axis=1 : 열과 열의 연산결과를 반환
- describe, sum, min, max, mean, count, std, var, prod, corr, argmin, argmax, cumsum, cumprod 등
(1) describe() 요약통계
- 전반적인 기술통계 정보를 확인할 수 있음
- 기본값으로 수치형(Numeric) 컬럼에 대한 통계표를 보여줌
- count:데이터개수, mean:평균, std:표준편차,
min:최소값, 25%:1분위수(하위25%값), 50%:2분위수(중앙값), 75%:3분위수(상위25%값), max:최대값
- count:데이터개수, mean:평균, std:표준편차,
(2) count() 데이터의 개수
- NaN을 제외한 데이터의 개수 계산
# 전체 데이터
dataframe.count()
# 단일 컬럼의 데이터
dataframe['<컬럼명>'].count()(3) mean() 평균
- NaN을 제외한 데이터의 평균 계산
- 조건별 평균도 계산 가능
# 전체 데이터의 평균
dataframe.mean()
# 컬럼의 평균
dataframe['<컬럼명>'].mean()
# 조건별 평균(조건식에 맞는 컬럼 데이터의 평균)
dataframe.loc[<조건식>, '<컬럼명>'].mean()(4) skipna=True 옵션
- NaN의 값을 제외하고 기술통계함수를 실행
skipna=False로 설정하면 NaN값이 있는 컬럼은 NaN으로 출력
(5) median() 중앙값
- 데이터의 중앙값을 출력
- 이상치(outlier)가 존재하는 경우, 평균보다 중앙값을 대표값으로 선호
(6) sum() 합계
- NaN을 제외한 데이터의 합계
- 문자열 컬럼은 모든 데이터가 붙어서 출력될 수 있음
(7) cumsum() 누적합과 cumprod() 누적곱
- 누적되는 합계
dataframe.cumsum()
dataframe['<컬럼명>'].cumsum()- 누적곱을 구할 수 있으나, 일반적으로 값이 너무 커지므로 잘 활용하지 않음
dataframe.cumprod()
dataframe['<컬럼명>'].cumprod()(8) var() 분산과 std() 표준편차
- 분산 : 어떤 대상의 흩어진 정보나 상태로 편차의 제곱의 평균값
- 표준편차 : 자료의 산포도를 나타내는 수치로, 분산의 제곱근
(9) min() 최소값과 max() 최대값
(10) unique() 고유값과 nunique() 고유값 개수
- 고유값과 고유값읠 개수를 구하고자 할 때 사용
- 일반적으로 문자열 컬럼에 사용
(11) quantile(r) 분위수
- 분위수는 주어진 데이터를 동등한 크기로 분할하는 지점
- r은 0부터 1의 값을 가지며, 하위 r%의 값을 계산
- 10%의 경우 0.1, 80%의 경우 0.8
(12) mode() 최빈값
- 가장 많이 출현한 데이터
- 카테고리형 데이터에도 적용 가능
(13) corr() 상관계수
- 데이터프레임의 컬럼별 상관관계를 확인할 수 있음
df_corr = pd.read_csv('/content/drive/MyDrive/LikeLion/!수업자료/swiss.csv',
encoding='EUC-KR', index_col=0)
# 전체 데이터 상관계수
df_corr.corr()
# Edu와 Exam의 상관관계
df_corr['Edu'].corr(df_corr['Exam'])
### Edu의 상관관계
df_corr.corr()['Edu'](14) 연습문제 [구별교통사고현황]
car = pd.read_csv('/content/drive/MyDrive/LikeLion/!수업자료/교통사고현황(구별).csv',
index_col=0)
car.head(3)
# 데이터 정보
car.info()
# 서울시는 어느 연도에 교통사고가 가장 많이 일어났나?
car.sum(axis=0).sort_values(ascending=False).head(1)
# 2020년, 어느 구에 교통사고가 가장 많이 일어났나?
car.sort_values(by='2020', ascending=False).head(1)
car['2020'].sort_values(ascending=False).head(1)
# 연도별 평균값을 기준으로 교통사고 top3구는?
car['평균값'] = car.mean(axis=1)
car['평균값'].sort_values(ascending=False).head(3)
# '최근증가율' 컬럼을 추가하여 2023년 교통사고수와 2022년 사고수의 증가율을 계산
car['최근증가율'] = (car['2023'] - car['2022'])/car['2022']
car
# 어느구의 최근증가율이 가장 높나?
car['최근증가율'].sort_values(ascending=False).head(1)
# 2024년의 교통사고수 구별 예측은? (이동평균법을 사용, 전체, 최근 5개, 최근3개..)
# 최근 5년의 평균을 기준으로 예측
car['2024(e)'] = car.loc[:,'2019':'2023'].mean(axis=1)
car['2024(e)'].sort_values(ascending=False)+ 이동평균법이란?
- 이동평균법은 시계열 데이터에서 이전 일정 기간 동안의 평균값을 이용해 미래의 값을 예측하는 방법
- 이 방법은 시간에 따라 변화하는 데이터의 경향성(추세)을 부드럽게 하거나 노이즈를 제거하는 데 자주 사용
(1) 이동평균법의 원리
- 특정 기간 동안의 평균을 계산하여 미래의 값을 예측합니다.
- 평균을 구하는 기간이 짧으면 단기적 변동에 민감하고, 길면 장기적인 추세를 반영합니다.
- 보통 주식, 날씨, 교통량, 수요예측 등에서 사용됩니다.
(2) 이동평균의 종류
(2)-1 단순 이동평균(Simple Moving Average, SMA)
- 과거 일정 기간의 데이터에 동일한 가중치를 주고 평균을 계산합니다.
- 예제: 최근 3년의 데이터를 기준으로 하면,
- 예측값 =
(2)-2 가중 이동평균(Weighted Moving Average, WMA)
- 과거의 데이터에 \가중치를 다르게 부여하여 최근 데이터를 더 중요하게 다룹니다.
- 예제: 최근 데이터일수록 높은 가중치를 부여하여 미래의 예측값에 더 큰 영향을 미침.
예측값 =
여기서 가중치 합
(2)-3 지수 이동평균(Exponential Moving Average, EMA)
- 가장 최근의 데이터에 지수적으로 더 큰 가중치를 부여합니다.
- 과거의 데이터가 시간이 지나면서 빠르게 가중치가 감소합니다.
- 주로 금융 데이터에서 단기 추세를 반영하는 데 사용됩니다.
(3) 예시
(3)-1 단순 이동평균법 예시
- 2019년부터 2023년까지의 교통사고 수를 기준으로 2024년의 교통사고 수를 예측한다고 가정
(3)-2 가중 이동평균법 예시
가중치가 각각 0.1, 0.15, 0.2, 0.25, 0.3으로 부여된 경우:
(4) 이동평균법의 특징과 장단점
-
장점
- 계산이 간단하고 직관적이다.
- 단기적인 노이즈를 제거하고 데이터의 추세를 파악하는 데 유용하다.
-
단점
- 갑작스러운 변화에 민감하지 않음.
- 예측이 과거 데이터에만 의존하기 때문에 미래의 돌발적인 사건을 반영하기 어렵다.

hyeeun-techlog