
1. GRDP와 사회조사지표, 인구통계자료 분석
- 지역내 총생산(Gross Regional Domestic Product : GRDP)
- 연도별 지역내 총생산이 낮은지역, 높은 지역을 알아보자.
- 2020년 대비 2023년 증감율을 기준으로 어느지역이 증가하고 감소했는지 알아보자.
- 2023년 GRDP와 사회조사지표, 인구통계자료를 통합하여 분석하여 보자.
- 삶의 만족도와 다른 사회조사 지표, GRDP, 인구밀도와의 상관관계
- 인구통계와 사회조사지표간의 상관관계
- Datasets
import pandas as pd
import numpy as np
# csv 파일읽기
import chardet
def read_csv_file(file_path, index_col=0):
try:
with open(file_path, 'rb') as f:
result = chardet.detect(f.read())
df = pd.read_csv(file_path,
encoding=result['encoding'],
index_col=index_col)
except Exception as e:
print(f"Error: {e}")
return df
# 인당 GRDP 파일읽기
grdp = pd.read_csv('/content/drive/MyDrive/LikeLion/!수업자료/1인당_GRDP_시도_15_23.csv',
encoding='EUC-KR', index_col=0)
grdp.head()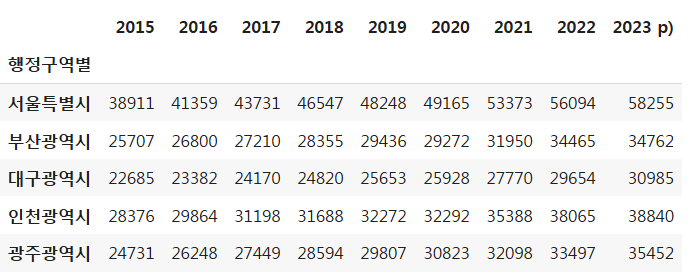
# 2023 p) 컬럼 이름 변경
grdp = grdp.rename(columns={'2023 p)':'2023'})
grdp.head()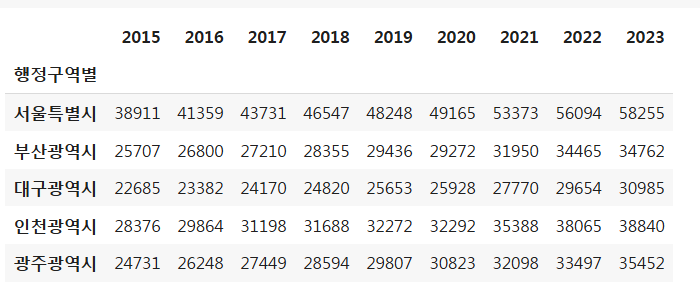
# 연도별 GRDP가 높은 지역
highest = grdp.index[np.argmax(grdp, axis=0)]
lowest = grdp.index[np.argmin(grdp, axis=0)]
highest, lowest
# grdp.idxmax(axis=0), grdp['2023'].idxmin(axis=0)
# 2020년 대비 2023년 증감율
grdp['증감율'] = (grdp['2023']-grdp['2020'])/grdp['2020']
grdp['증감율'].sort_values(ascending=False)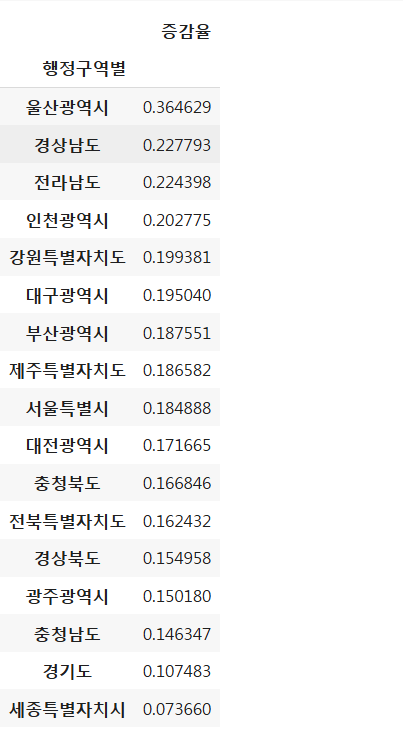
# 사회조사 지표 파일 읽기
social_path = '/content/drive/MyDrive/LikeLion/!수업자료/사회조사지표_시도_2023.csv'
social = read_csv_file(social_path)
social.head(2)
# 인구통계 파일읽기
population_path = '/content/drive/MyDrive/LikeLion/!수업자료/인구통계_시도_2023.csv'
population = read_csv_file(population_path)
population.head(2)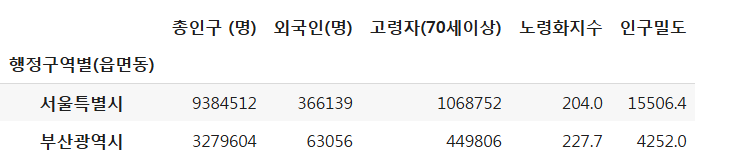
# 인구통계의 컬럼명 변경
population = population.rename_axis('행정구역별')
# 인구통계의 인덱스명 변경
population = population.rename(index={'전라북도':'전북특별자치도'})
population
# 2023년 GRDP의 컬럼명 변경
df.rename(columns={'2023':'인당GRDP'}, inplace=True)
# df의 결측치 및 데이터 타입 확인
df.info()
# 변수간 상관분석
df_corr_matrix = df.corr()
df_corr_matrix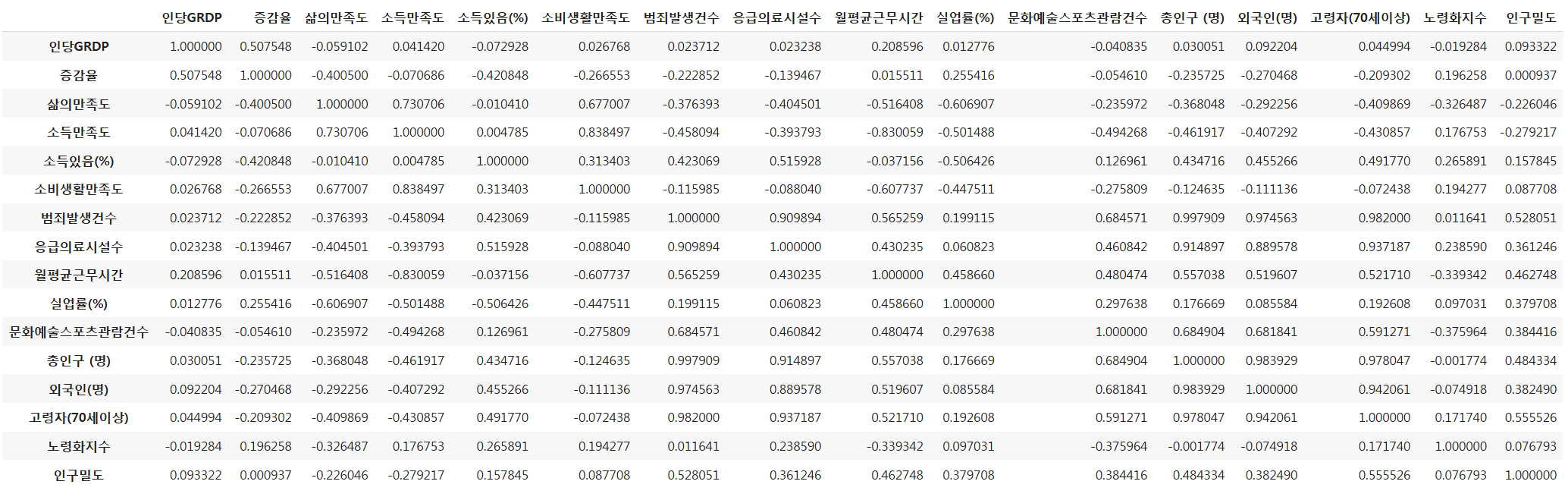
2. 데이터 산업 현황
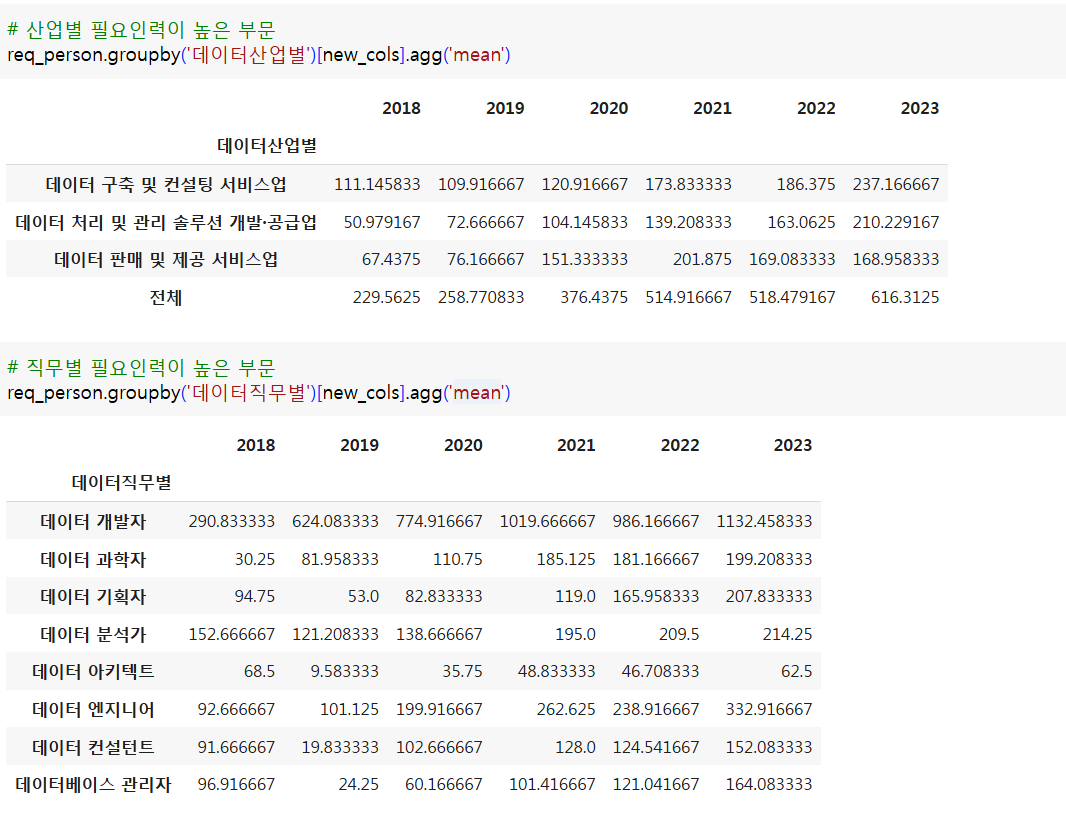
- 데이터 산업별 직무별 필요 인력현황
- 산업별 필요 인력현황이 높은 직무는?
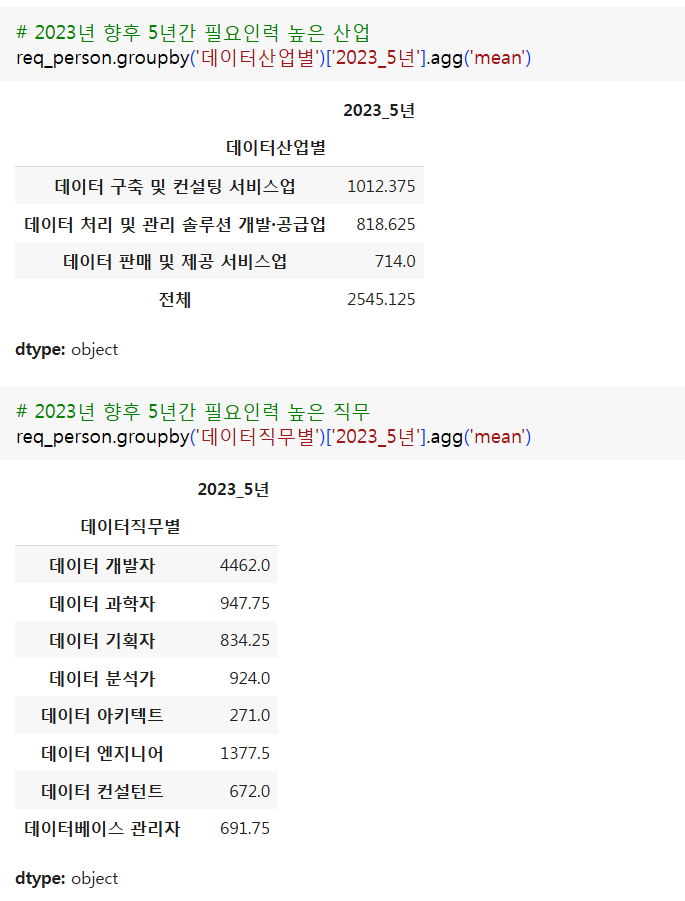
- 2023년 기준 향후 5년간 필요인력현황이 높은 산업, 직무는?
- 데이터 산업 시장규모
- 어떤 산업의 시장규모가 높은가?
- 최근 3개년 시장데이터를 평균하여 2024년 시장 규모를 예측해보자
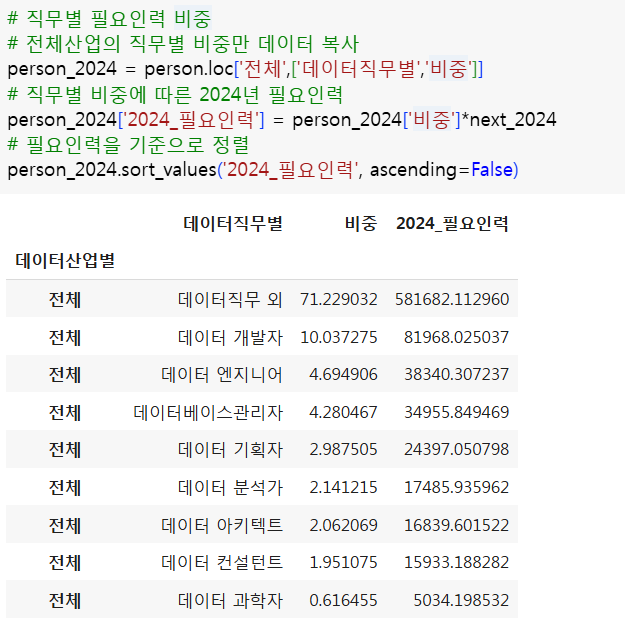
- 데이터산업별 직무별 인력현황
- 어떤 산업의 총 인력이 많은가?
- 산업별 각 직무의 비중은?
- 데이터산업별 우대기술
- 산업별 어떤 우대기술이 유효한가?
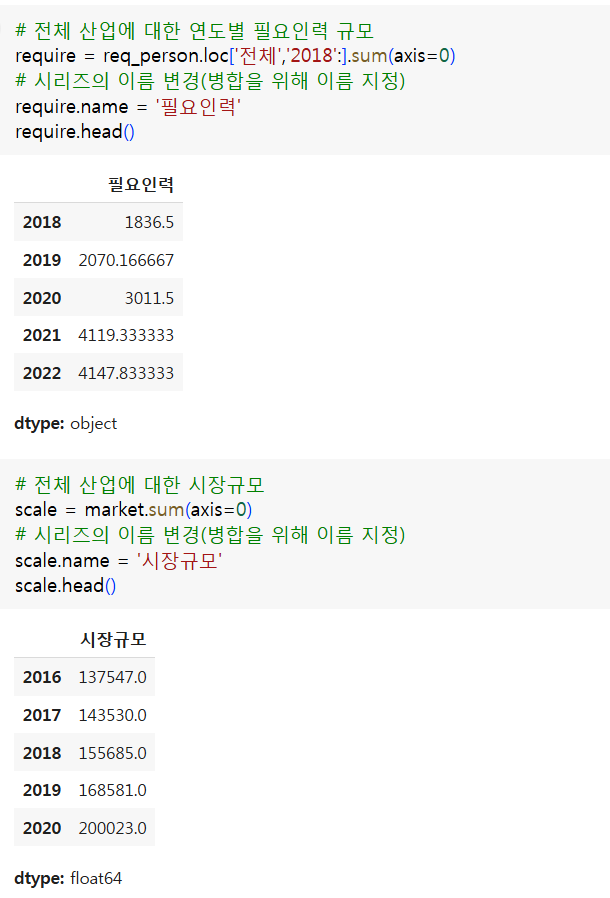
- 시장규모와 보유인력, 필요인력(차년도, 5개년)현황의 상관관계
- 상관관계가 높다면, 예측된 시장규모를 기준으로 2024년의 차년도 필요인력 규모는?
- 직무별 비중에 따라 차년도 직무별 필요인력의 규모는?
- Datasets
(1) 필요인력
# 필요인력 현황 파일읽기
req_path = '/content/drive/MyDrive/LikeLion/!수업자료/데이터산업별_데이터직무별_필요인력현황.csv'
req_person = read_csv_file(req_path)
req_person.head(2)
# 컬럼명 변경
req_person.columns=['데이터직무별', '2018_차년', '2018_5년',
'2019_차년', '2019_5년', '2020_차년', '2021_5년',
'2021_차년', '2021_5년', '2022_차년', '2022_5년',
'2023_차년', '2023_5년']
req_person = req_person.rename_axis('데이터산업별')
req_person.head(2)
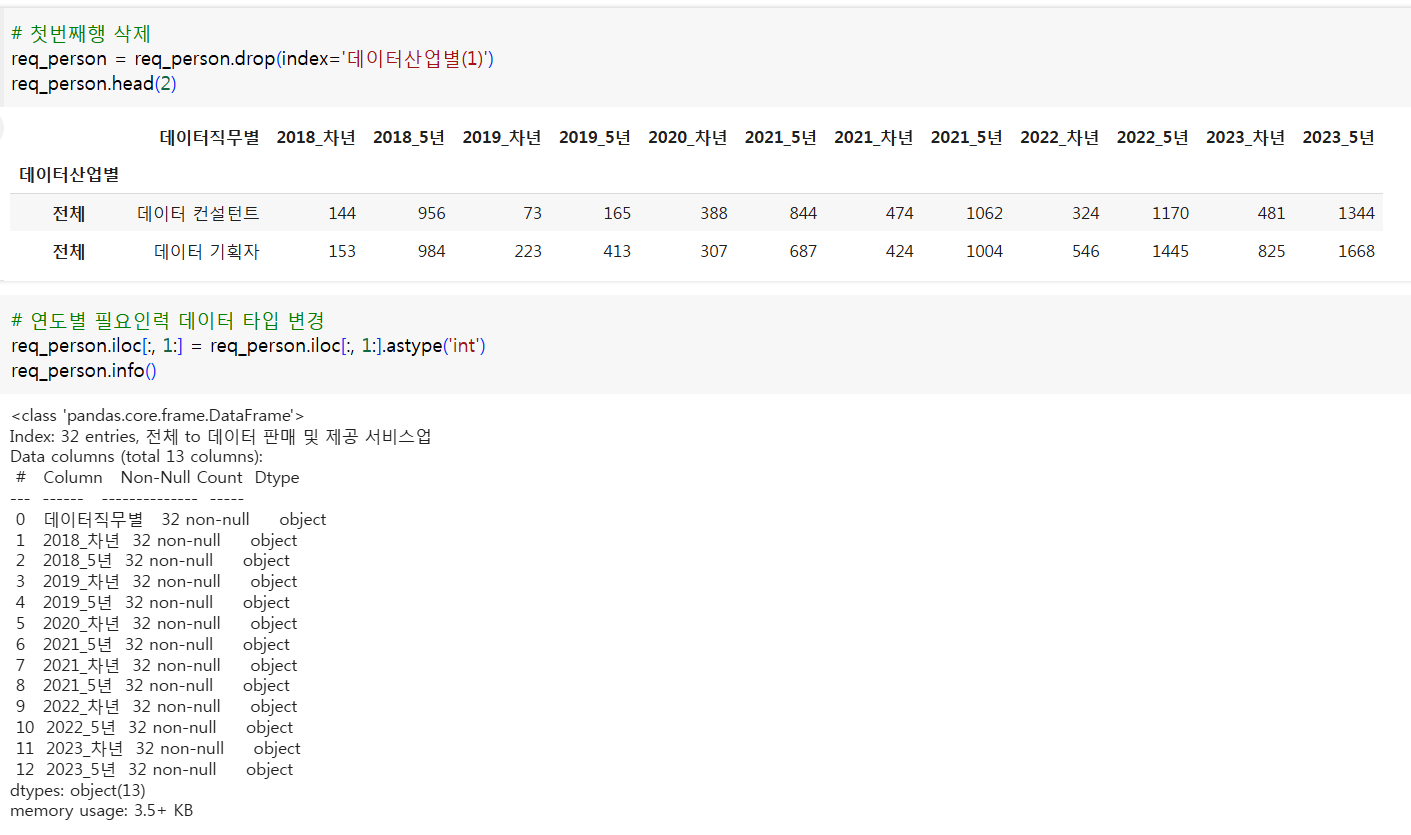
# 첫번째행 삭제
req_person = req_person.drop(index='데이터산업별(1)')
req_person.head(2)
# 연도별 필요인력 데이터 타입 변경
req_person.iloc[:, 1:] = req_person.iloc[:, 1:].astype('int')
req_person.info()
(2) 시장규모
# 시장규모 파일 읽기
market_path = '/content/drive/MyDrive/LikeLion/!수업자료/데이터산업별_시장규모.csv'
market = read_csv_file(market_path)
market.info()
# 컬럼명 변경
market = market.rename(columns={'2023 e)' :'2023'})
market.head()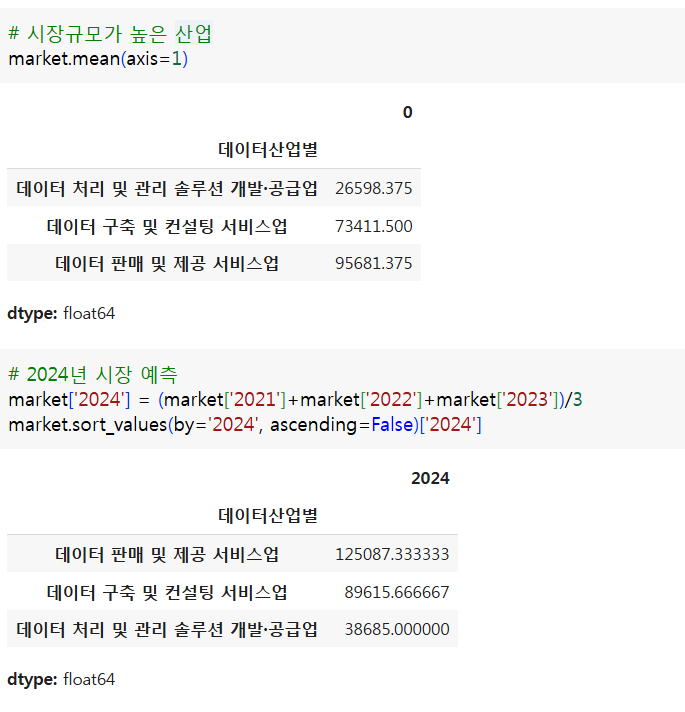
(3) 인력현황
# 인력현황
person_path = '/content/drive/MyDrive/LikeLion/!수업자료/데이터산업별_데이터직무별_인력현황.csv'
person = read_csv_file(person_path)
person.info()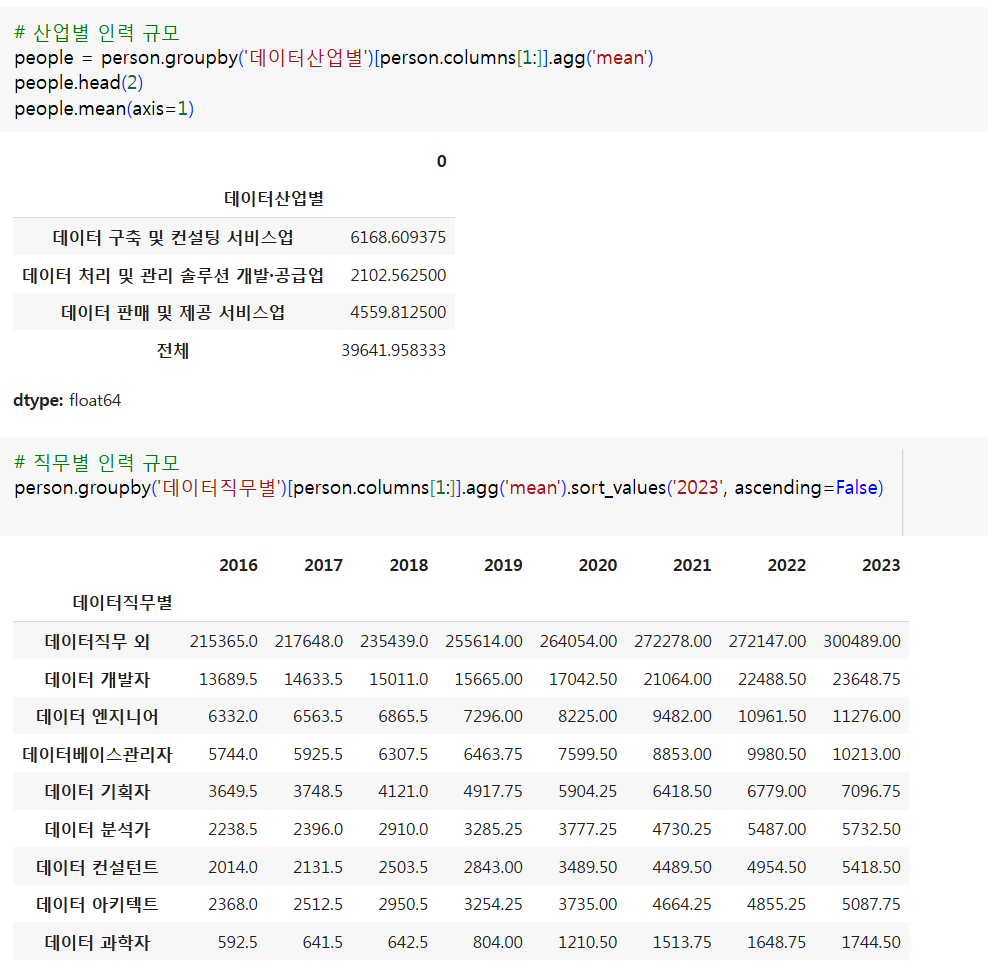
(4) 우대기술
# 산업별 우대기술 파일 읽기
skill = read_csv_file('/content/drive/MyDrive/LikeLion/!수업자료/데이터산업별_우대기술.csv')
skill.info()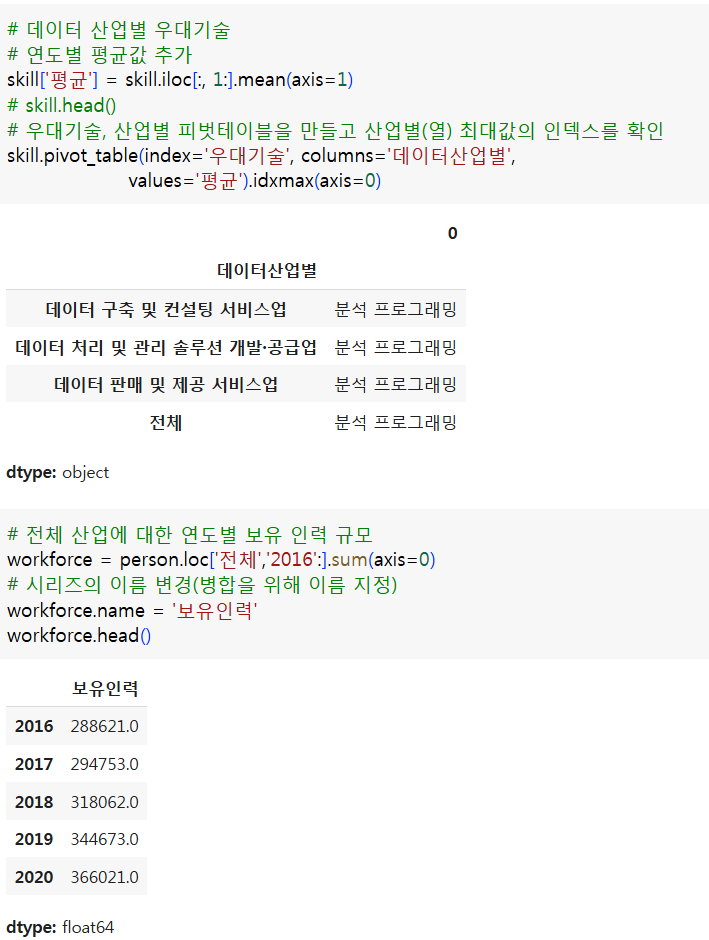
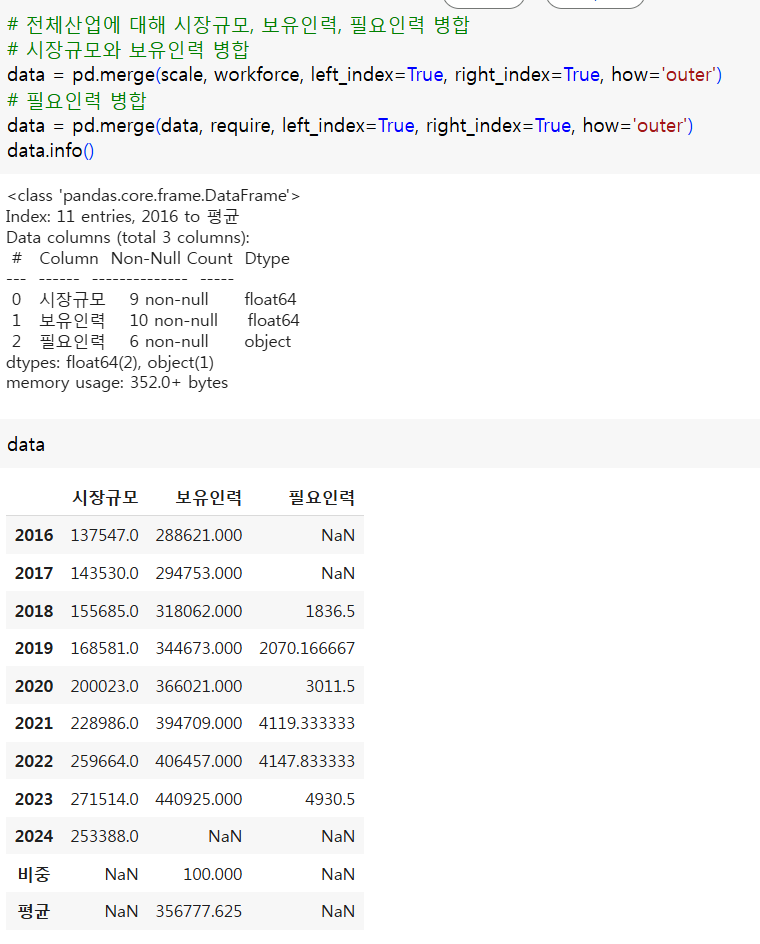
(5) 최소제곱 추정량에 따른 기울기와 절편 구하기
- 절편
- 기울기
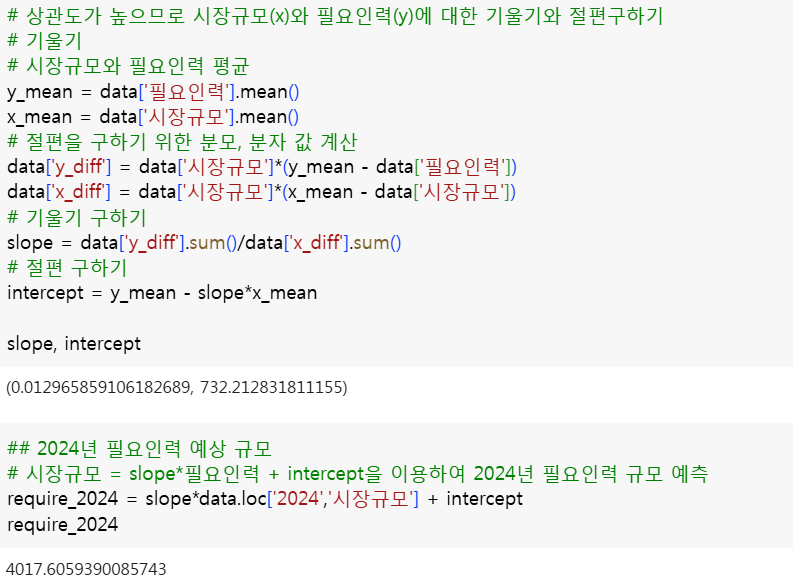
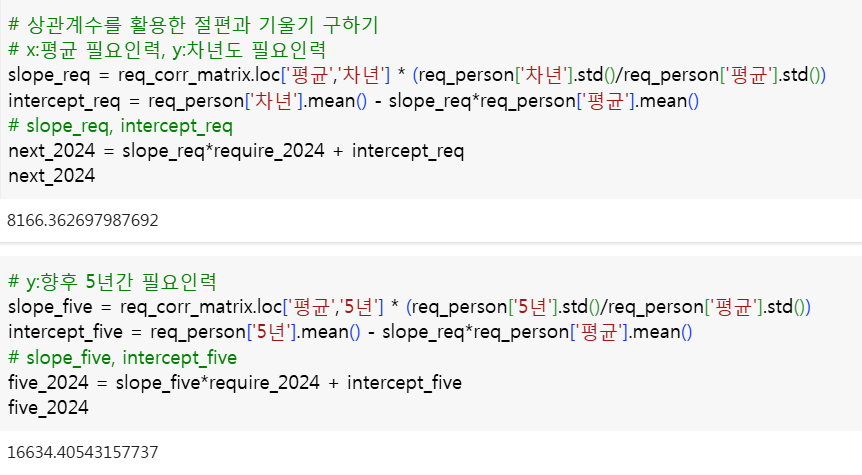
(6) 상관계수를 활용한 기울기와 절편 구하기
- 절편
- 기울기
3. 음주운전교통사고
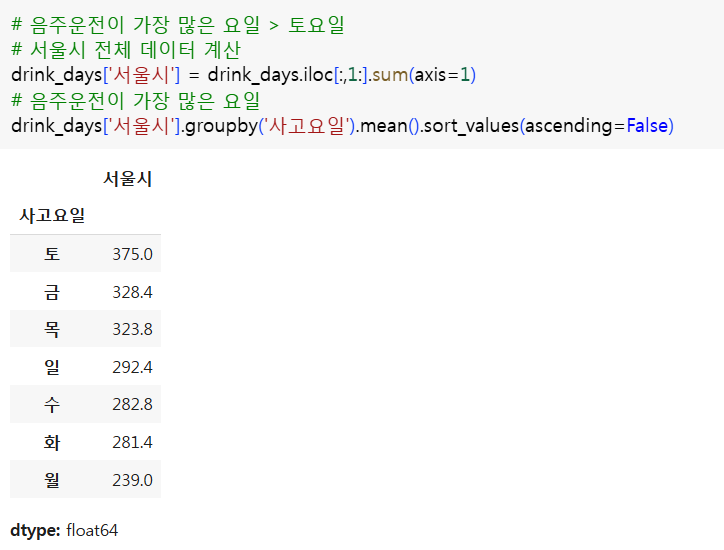
- 음주운전교통사고가 가장 많은 요일은?
- 음주운전교통사고가 가장 많은 시간대는?
- 교통사고와 음주운전간의 상관관계
- 교통사고가 가장 많은 구는?
- 음주운전 교통사고가 가장 많은 구는?
- Datasets




hyeeun-techlog