PIVOT
행을 열로 바꾸기!
샘플 데이터
이름과 직업으로 구성된 데이터를 사용했다.
-- 테이블 생성 CREATE TABLE occupations(name varchar(20), occupation varchar(20)); -- 데이터 삽입 INSERT INTO occupations VALUES ('Samantha', 'Doctor'), ('Julia', 'Actor'), ('Maria', 'Actor'), ('Meera', 'Singer'), ('Ashely', 'Professor'), ('ketty', 'Professor'), ('Christeen', 'Professor'), ('Jane', 'Actor'), ('Jenny', 'Doctor'), ('Priya', 'Singer'); -- 테이블 확인 SELECT * FROM occupations;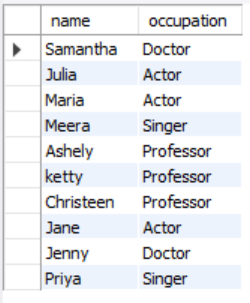
CASE 문을 사용한 PIVOT
Input 테이블을 살펴보았을 때, Occupation 종류에 따라 각각에 속하는 Name들을 정리해보면 다음과 같다.(Name은 알파벳 순으로 정렬했다.)
- Doctor : Jenny, Samantha
- Professor : Ashely, Christeen, Ketty
- Singer : Meera, Priya
- Actor : Jane, Julia, Maria
이 때, 각 직업에 속하는 첫 번째 이름들끼리 한 행에 출력하게 하고자 한다. 그런데 만약 그 index에 해당하는 직업의 이름이 없다면 NULL을 출력하라는 것이다. 그래서 Sample Output을 Pivot 형태로 정리하면 다음과 같다.
쿼리
1. 먼저 나눌 기준이 될 것으로 서브쿼리를 만들기
occupation을 기준으로 partition을 만들어서 rank를 row_number 방식으로 달아준다.
이때, 알파벳 순서로 해주기 위해 정렬은 name 순으로 한다
(이렇게 하면 기준이 같은 것끼리 1,2,3,4,5의 순서가 생긴다)
SELECT *, ROW_NUMBER() OVER (PARTITION BY occupation ORDER BY name) rnk -- 알파벳 순서로 정렬하기 위해 name으로 ORDER BY 했음 FROM occupations;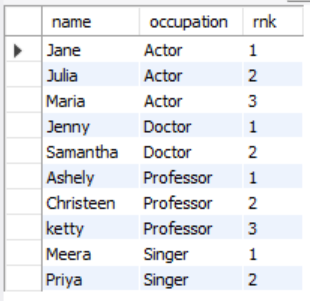
2. CASE 문을 활용해 직업별로 이름 나누기
1번 결과를 sub-query로 해서 CASE 문을 활용해 각 직업별로 name을 뽑아준다.
이때, 알파벳 순서로 해주기 위해 집계함수 중 MIN을 사용한다.
- 알파벳의 최소값(a)부터 가져오게 하기 위해 MIN을 사용했다
- 순서가 필요 없으면 아무 집계함수나 넣어도 된다
- name의 값이 숫자가 아니기 때문에 사실상 집계되는 건 없음
- 피벗은 반드시 집계함수를 함께 써야한다! (값이 2개일 수도 있기 때문!)
-- MIN()과 GROUP BY를 하지 않았을 때 출력값 SELECT (CASE WHEN occupation = 'Doctor' THEN name END) doctor, (CASE WHEN occupation = 'Professor' THEN name END) professor, (CASE WHEN occupation = 'Singer' THEN name END) singer, (CASE WHEN occupation = 'Actor' THEN name END) actor FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY occupation ORDER BY name) rnk FROM occupations) A;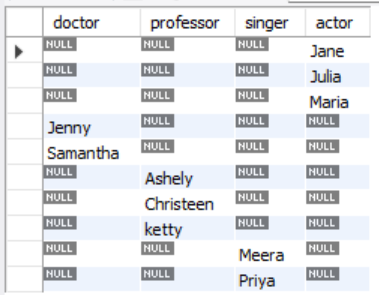
-- GROUP BY를 하지 않았을 때 출력값 SELECT MIN(CASE WHEN occupation = 'Doctor' THEN name END) doctor, MIN(CASE WHEN occupation = 'Professor' THEN name END) professor, MIN(CASE WHEN occupation = 'Singer' THEN name END) singer, MIN(CASE WHEN occupation = 'Actor' THEN name END) actor FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY occupation ORDER BY name) rnk FROM occupations) A;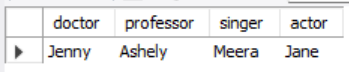
3. GROUP BY 하기
NULL을 없애고 같은 rank마다 한 행으로 만들어주기 위해 GROUP BY를 해준다.
- GROUP BY와 집계를 하면, 랭킹이 같은 것끼리 한 행이 된다.
SELECT MIN(CASE WHEN occupation = 'Doctor' THEN name END) doctor, MIN(CASE WHEN occupation = 'Professor' THEN name END) professor, MIN(CASE WHEN occupation = 'Singer' THEN name END) singer, MIN(CASE WHEN occupation = 'Actor' THEN name END) actor FROM (SELECT *, ROW_NUMBER() OVER (PARTITION BY occupation ORDER BY name) rnk -- 알파벳 순서로 나오기 하기 위해 ORDER BY를 name으로 하고 rnk을 매겼다 FROM occupations) A GROUP BY rnk -- 여기 집계를 해주지 않으면 NULL 값이 한 행으로 처리되지 않는다 ORDER BY rnk; -- 서브쿼리에서 ORDER BY를 해줬기 때문에 이 부분이 없어도 같은 값이 출력된다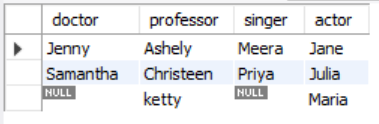
이렇게 풀면 안돼!
SELECT MIN(CASE WHEN occupation = 'Doctor' THEN name END) doctor, MIN(CASE WHEN occupation = 'Professor' THEN name END) professor, MIN(CASE WHEN occupation = 'Singer' THEN name END) singer, MIN(CASE WHEN occupation = 'Actor' THEN name END) actor FROM occupations GROUP BY occupation ORDER BY name;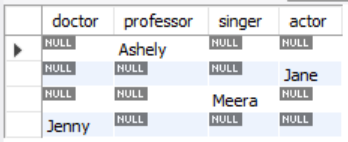

좌충우돌 천방지축 룰루랄라 데이터 공부