사례와 변수
사례 case: 데이터 수집의 단위 ex) 고객, 제품 등변수 variable: 사례에 따라 달라지는 값 ex) 나이, 가격 등
데이터는 표
데이터는 표로 정리한다. 이것은 모두의 약속이다.
행 row- 표에서
가로방향 한 줄 - 하나의
사례
- 표에서
열 column- 표에서
세로방향 한 줄 - 하나의
변수
- 표에서
| 열 | column | 변수 | |
|---|---|---|---|
| 행 | |||
| row | |||
| 사례 |
데이터의 변수
데이터의 변수는 크게 2개로 나뉜다. 변수의 종류에 따라서 할 수 있는 분석의 종류가 달라지기 때문에 변수의 종류를 파악하는 게 중요하다.
1. 범주형 범주 categorical variable
- 종류, 이름 등이 해당 ex) 주거 형태(월세, 전세), 소유 차(없다, SUV)
- 숫자로 표시하더라도 양적인 개념이 아님(기호에 불가)
- 덧셈 등 대부분의 연산이 의미가 없다(애초에 양이 아니기 때문! 평균을 내는 실수를 하기 쉽다!) ex) 지역 번호
- 순서가 있을 수도 있으나 간격이 일정하지 않음 ex) 학력
2. 연속형 변수 continuous variable
- 연속적인 형태
- 정수나 실수로 표시할 수 있음
- 간격이 일정하고 덧셈, 뺄셈 등의 계산이 의미가 있음
- ex) 무게, 나이, 시간, 거리, 자녀의 수, 시험 점수
통계의 종류
통계의 종류는 크게 2개로 나눌 수 있다. 통계학의 핵심과 목적은 추론 통계인데, 일상적으로 쓰이는 통계는 기술 통계에 가깝다. 그러나 회사에서는 추론 통계를 잘 쓰지 않는다.
기술 통계descriptive statistics : 기록하고 서술한다는 의미의기술, 데이터를 묘사, 설명추론 통계inferential statistics : 데이터를 바탕으로 추론, 예측
1. 기술 통계
- 데이터를 묘사, 요약, 설명하는 통계적 방법과 절차들
- 기술 통계치
- 중심 경향치
- 분위수
- 변산성 측정치
1.1 중심 경향치 - 데이터가 어디에 몰려 있는가?
1) 평균 mean
- N개의 값이 있을 때
합계를 N으로 나눈 것 - 평균은 극단값에 따라 영향을 크게 받기 때문에 평균으로만 판단하면 잘못된 판단을 할 수 있다
- ex) 대졸 초봉의 예 - 소득은 과장될 수 있음!
.mean()
2) 중간값 median
- 값들을 크기 순으로 정렬했을 때
중간에 위치한 값 중위수라는 표현도 많이 사용 (중위소득, 중위가격 등)- 값이 짝수 개 있을 경우에는 가운데 두 값의 평균
.median()
3) 최빈값 mode
가장 많은 사례에서 관찰된 값- 영어 mode에는 상태, 유행,
가장 많은 것등의 뜻이 있음 - 연속 변수보다 범주형 변수에서 유용함 ex) 구성원 중 김씨가 30%로 가장 많음
- 연속 변수의 경우 구간을 나누어 최빈값을 구하는 경우가 많음, 구간을 나누는 방법에 따라 최빈값이 달라질 수 있다.
.mode()
4) 범주별 빈도
.value_counts()
1.2 분위수 quantile
- 크기순으로 정렬된 데이터를
q개로 나누는(분) 위치의 값 - 쉽게 말하면
등수를 매기는 것!- 4명 중 1등(1/4)은 0.25, 10명 중 1등은 (0.1)로, 같은 1등이지만 값이 다르다
- 1등은 모두 같은
값(0)으로 만들기 위해1을 빼줬다 등수-1/N-1그래서 모든 값은0과1사이로 표현되게 하는 것
- 대표적으로
사분위수,백분위수가 있다
1) 사분위수 quartile
- 데이터를 크기순으로 정렬했을 때 4토막으로 나누는 것
- 데이터를 4등분하는 위치 - 자르기는 3번만 하면 되므로 분위수는 3개가 나온다
- 제1사분위수 : 1/4지점- 제1사분위수 : 2/4지점
- 제3사분위수 : 3/4지점
- 영어 철자 주의! 분위수(qua
ntile), 사분위수(quartile) - ex) 국가장학금은 10분위로 나누니까 분위수는 9개가 나온다
2) 백분위수 percentile
- 데이터에서 순위를 퍼센트로 표현
- 최소값 = 0퍼센타일
- 제1사분위수 = 25퍼센타일 = 0.25퀀타일
- 제2사분위수 = 중간값 = 50퍼센타일
- 제3사분위수 75 퍼센타일
- 최대값 = 100퍼센타일
생활 팁!
퍼센타일같은 용어 어려워 하지 말자! 다른 사람들을 설득하기 위해전문성과멋짐을 뽐내기 위해서라고 생각하자!보그체처럼!
1.3 변산성 측정치
- 데이터가 퍼져 있는 정도를 나타내는 수치
- 예를 들어 주식을 할 때
평균수익률 = 번 돈/투자한 돈내가 10 종목에 투자를 하고 10, 10, 10...의수익률 10%, 100, -100, 200, -100...의수익률 10%은 같지만 다르다는 것을변산성으로 알 수 있다! - 데이터가
안정적인지,들쭉날쭉한지 알 수 있기 때문에변산성은 중요하다! - 종류(변산성을 지표화시키는 방법)
- 범위
- 사분위수
- 분산
- 표준편차
1) 범위 range
- 최대값
.max()- 최소값`.min() - 극단값이 있으면 커짐
- 보통 최대값과 최소값에는 극단값이 들어가 있을 경우가 있다 ex) 마이클 조던의 연봉
2) 사분위간 범위 InterQuartile Range
- 범위의 극단값을 해결하기 위해 사용
- 줄여서 IQR
- 제3사분위수
.quantile(0.75)- 제1사분위수.quantile(0.25) - 극단값은 최소값 또는 최대값 근처에 있으므로 극단값의 영향이 적음
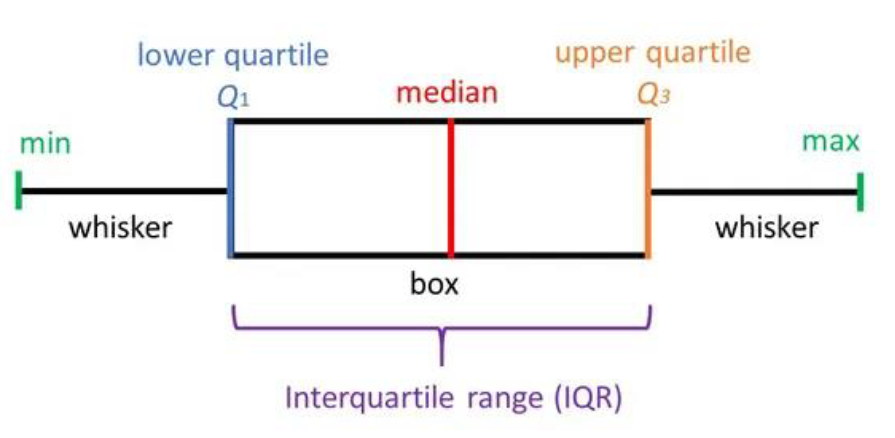
3) 상자 수염 그림 box whisker plot
- 제1사분위수 ~ 제3사분위수를
상자로 표현 - 사분위간 범위
IQR을 표시 중간값은 상자의가운데 굵은 선으로 표시최소값과최대값은수염(whisker)으로 표시 - 그리고 최소값과 최대값을 표시하는 데에는 규칙이 있다!- 바로 수염의 최대 길이는
IQR의1.5배까지만 표시 - 이를 넘어가는 경우(튀는 값) 점으로 표시 - 경험적으로 대부분의 데이터가
1.5배사이에 있기 때문
4) 편차 deviation
값-평균- ex) 원 데이터가 30, 40, 50인 경우 평균은 40, 편차는 10, 0,0,+10
- ex) 내 나이대의 평균 연봉은 4000만원인데, 내가 5000만원을 받으면 편차는 1000만원인 것
표준편차 이해하기
- 데이터에서 편차가 전반적으로 큰지 작은지 알려면 편차의 평균을 구하면 된다!
- 그런데 평균보다 큰 것도 있고 작은 것도 있으니(
+,-) 편차의 평균을 구하면0이 된다! (제로섬!!) - 편차에
+,-부호를 떼고 평균을 내보자!
- 방법 1)절대값을 취한다 - 평균절대편차(MAD) => 잘 사용 안 한다!!!
- 방법 2) 값에제곱을 한다
5) 분산 variance
- 편차 제곱의 평균 (편차는 -, + 둘 다 나올 수 있기 때문에 - 부호를 없애려고 제곱을 해줬다)
- 직관적으로 이해하기는 어려우나
수학적으로 중요한 여러 성질이 있음 - 편차를 제곱하여 크기가 커지므로 표준편차(
분산에루트씌운 것 =분산의 제곱근)를 많이 사용 - 파이썬의 분산과 표준편차
- 분산 :
.var() - 표준편차 :
.std()
- 분산 :
생활팁! 제곱을 하고 다시 루트를 씌우고, 이런 걸 너무 깊게 이해하려고 하기 보다 진리처럼 받아들이는 것도 좋은 방법이다! 모든 것을
이해한다는 환상을 버리자!
- 표준편차도 계산 과정이 중요한 게 아니라
표준편차를 이용해서 무엇을 하려고 하는지를 아는 게 중요하다!!- 표준편차는 데이터의 변산성(크고 작은 정도)을 지표로 만들기 위해서!
- 지표마다 보여주는 것이 다르고 지표를 통해 데이터를 파악하는 것
- 지표는 맞고 틀린 게 없다!
정답이 존재한다는 환상도 내려놓기
중요한 건 <표준편차는 데이터의 변산성(크고 작은 정도)을 지표로 만들기 위해서 사용한다>는 것이다!!
지금까지는 지표로 데이터를 봤다! 이제는 그래프로 알아보자!
히스토그램 histogram
- 데이터를 구간별로 나눠 각 구간의 사례 수를 막대그래프로 그린 것
데이터 분석의 목적은
의사결정이다. 그렇기 때문에 bins의 갯수 같은 것도 정답이 있는 게 아니라의사결정에 필요한 만큼 - 경험과 감으로 오는 것...
커널 밀도 추정 kernel density estimation
- 데이터의 밀도를 추정하여 그린 곡선
- 히스토그램의 보조장치 같은 것!
모집단과 표본
용어일 뿐이다! 어려워도 외우자!
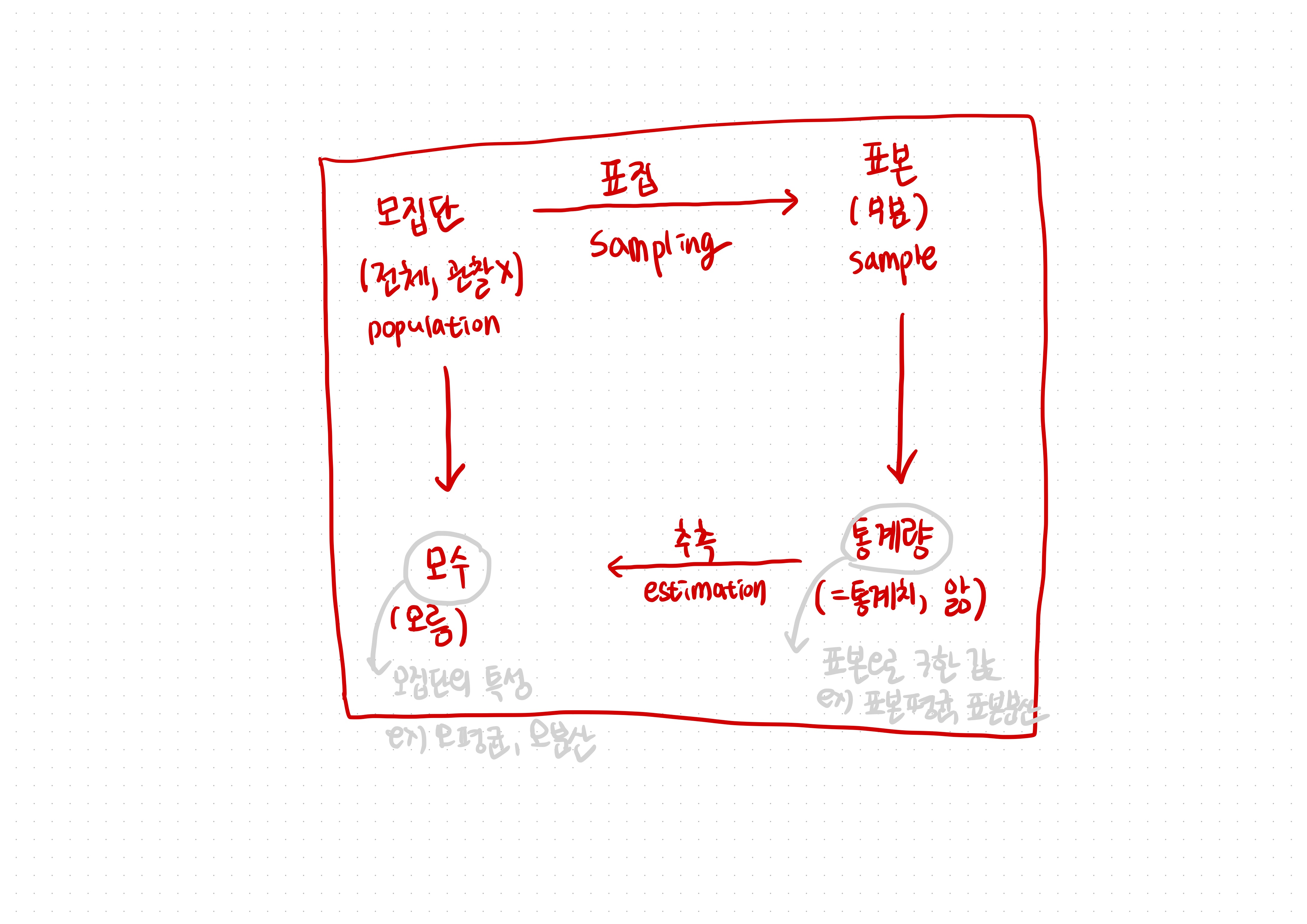
모집단 population : 연구의 관심이 되는집단 전체- 거의 신의 뜻과 같아서 직접 쉽게 보거나 들을 수 있는 게 아니다!
표본 sample: 특정 연구에서 선택된 모집단의부분 집합표집 sampling: 모집단에서 표본을 추출하는 절차,표본 추출이라고도 함- 대부분의 경우 집단 전체를 전수조사하기는 어려우므로 무작위로 표본을 추출하여 모집단에 대해 추론
1. 모집단의 특성, 모수 population parameter
모수는 통계에서 아주 중요한 용어!파라미터 parameter: 어떤 시스템의특성을 나타내는 값- para : 옆 / meter 자로 쟀다!
모수: 모집단 population의 파라미터, 즉모집단의 특성을 나타내는 값- 예시
- 모집단의 평균(모평균)
- 모집단의 분산(모분산)
- 주의! 표본의 크기를 모수라고 하는 경우도 있으나 잘못된 표현
- 모수를 구하기 위해서는 전수조사가 필요(사실상 어려움)
2. 통계량(또는 통계치) sample statistic
- 표본으로 계산한 값(뭐가 나오든 표본에서 구하면
통계량,통계치인 것) - 예시
- 표본의 평균(표본평균)
- 표본의 분산(표본분산)
- 주의
모집단의 통계량이라는 표현은 없음(통계량은 표본에서 구한 값이기 때문!)표본의 모수같은 말도 없음(모수는 모집단에서 구한 값)
추론 통계 inferential statistics: 표본 통계량을 일반화하여 모집단에 대해 추론 하는 것
numpy와 pandas에서의 분산 계산 : https://hooni-playground.com/1422/
3. 모평균 vs. 표본평균
- 표본의 평균은 모집단의 평균보다 조금 크거나 작다
4. 표집 분포 sampling distribution
- 기억을 해두는 게 좋다! (모수는 별 4개 용어, 표집분포는 별 2개 용어)
동일한 모집단에서동일한 크기의 표본을동일한 방법으로 뽑더라도통계량이 조금씩 다른 것을 확인할 수 있음표집 분포: 통계량의 확률 분포- 모집단에 대한 추론의 바탕이 되는 이론적 분포
- 주의 : 표본의 분포가 아님
4.1 표집 분포의 특성
- 각 표본의 분포는 모집단의 분포와 비슷
- 주사위에서 1~6이 대체로 고르게 나옴 - 표집 분포는 모수를 중심으로 모수와 가까운 값이 더 많이 나옴
- 평균의 표집 분포는 주사위값 3.5 근처에서 많이 나옴 - 어떤 통계량(ex: 평균)은 표집 분포의 형태를 이론적으로 알 수 있음
표집 분포를 통해 무엇을 확인할 수 있을까? 표본을 뽑을 때 결과가 극단적으로 나올 수 있는데, 어느 정도 극단적으로 나올 수 있는지 그 확률을 알수 있다. 우리 데이터에서
±(뿔마)어느 정도까지오차가 있을 수 있겠구나 예측할 수 있다!
즉, 표집 분포를 이론적으로 알고 있으면 역으로 모수를 추론할 수 있다!!!!
4.2 평균의 표집 분포
표준 오차 standard error: 표집 분포의 표준 편차- 시뮬레이션에서 관찰된 표준오차 :
np.std(ms) - 이론적으로 예측된 표준오차(모집단의 표준오차?) :
np.std([1,2,3,4,5,6])/np.sqrt(size)
4.3 데이터를 많이 모아야 하는 이유
- 데이터가 많을수록 표준 오차가 작아짐
- 데이터가 많을수록 표본의 통계량이 모수에 더 가깝게 나옴
- 표준 오차는 1/√n(
루트씌운n)으로 줄어들기 때문에 데이터를4배늘리면2배더 정확- 예를 들어 1000명으로 선거 출구조사를 할때
2배더 정확한 데이터를 구하려면, 4000명을 조사해야 한다!
- 예를 들어 1000명으로 선거 출구조사를 할때
통계량은 모수와 조금 다르게 나올 수 있다!
그런데 어느 정도 다르게 나올지 이론적으로 알 수 있다!
그리고 데이터를 많이 모으면 더 정확한 통계량을 얻을 수 있다!
그렇지만 데이터를 무한정 많이 모으기는 어렵다 (비용이 많이 든다)
5. 추정 estimation
통계량으로부터 모수를 추측하는 절차를 추정이라고 하며, 추정은 크게 2가지 방법이 있다.
1) 점 추정 point estimate : 하나의 수치로 추정
2) 구간 추정 interval estimate : 구간으로 추정 - 어느 정도만 정확하면 되는 거야!
5.1 신뢰구간 confidence interval
대표적인 구간 추정 방법이다.
이름이 신뢰구간인 하나의 추정 방법임으로, 이것을 100% 신뢰할 수 있다는 것은 아니다
- 신뢰구간 = 통계량±오차범위
통계량은 데이터(표본)에서 직접 구한 값 (예를 들어 표본평균)
5.2 신뢰수준 confidence level
신뢰구간에는 신뢰수준이라고 하는 속성이 있다.
- 신뢰구간에 모수가 존재하는 표본의 비율을
신뢰수준이라고 한다- 신뢰수준이 높음 > 많은 표본을 포함(더 많은 예외들을 포함) > 더 넓은 오차범위 > 정보가 적음 => 이 정보를 토대로 의사결정을 하기 어려움!!!
- 신뢰수준이 낮음 > 적은 표본을 포함(극단적인 예외들을 제외) > 더 좁은 오차범위 > 정보가 많음 => 의사결정을 위한 유의미한 정보!!
- 신뢰구간이 좁으면 신뢰수준이 낮으므로 타협이 필요
- 교과서적으로는
95%, 99% 등을 추천하나 절대적 기준은 없음 - 감수할 수 있는 수준에서 결정
- 신뢰수준은 100%면 안된다!
- 교과서적으로는
100% 신뢰구간 : 단 하나의 예외도 제외하지 않겠다!!! => 절대 틀리지 않는 일본의 프로파일러
희박한 확률을 고려하면, 예외적인 케이스를 더 많이 포함하기 때문에 신뢰구간이 넓어질 수밖에 없다
신뢰수준 95% 신뢰구간 (예외 5%는 쳐냄) => 신뢰구간이 좁음
신뢰수준 99% 신뢰구간 (예외 1%는 쳐냄)
- 신뢰수준이 높다는 얘기는 더 정확하다는 얘기가 아니다.
- 신뢰수준이 높다는 데 정보가 적다는 게 이상하게 느껴지지만, 이는 아직 이게 낯설기 때문.
통계적 관점과 논리에 익숙해져야 한다.- 이것은
시간이 해결해준다!!!!
이 신뢰수준을 어떻게 활용할 수 있을까?
- 사업을 하려고 하는데 평균 850만원은 팔아야해, 그런데 시장조사를 해보니까 신뢰수준 95% 신뢰구간은 814~893만원까지야! 이때 (1) 딴 일을 하자! (2) 시장조사를 더 해보자! 등으로 의사결정을 할 수 있는 것!
신뢰수준
- 통계에서 어떠한 값이 알맞은 추정값이라고 믿을 수 있는 정도이다.
- 보통은 95%의 신뢰수준을 사용한다.
- 예를 들어, ‘정치인 지지율 조사에서 A후보는 40%, B후보는 25%의 지지율을 얻었다. 신뢰수준 95%에서 표본오차는 3.1%포인트이다’란 말의 의미는 다음과 같다. 동일한 형태의 여론조사를 100번 실시했을 경우에 95번은 A후보가 40%에서 ±3.1% 인 36.9% ~ 43.1%, B후보는 25%에서 ±3.1% 인 21.9% ~ 28.1% 사이의 지지율을 얻을 것으로 기대된다는 의미이다.
- 출처 : 통계청 사전식보기 - 신뢰수준
5.3 신뢰구간 구하기
1) 정규분포 t분포 : pingouin 사용
pip install pingouin
import pingouin as pg
pg.ttest(df.price , 0, confidence=0.95)모집단에 대해 정확하게 알면, 표집 분포를 이론적으로 유도할 수 있다
그러나 모집단에 대해서는 모른다(그걸 알면 통계를 할 필요가 없지...)
우리에게는 표본 밖에 없다
(우리 표본이 모집단이랑 똑같지는 않지만 아주 다르지도 않지! 표집분포는 모집단의 성질로부터 유도되는 것!)
우리 표본을 가지고 > 표본을 뽑는 것을 매우 많이 반복 > 표집 분포와 비슷한 분포를 얻어서 신뢰구간을 계산한다
2) 부트스트래핑 bootstrapping
- 평균과 달리 중간값 최빈값 등의 통계량은 표집분포의 형태를 간단히 알기 어려움
- 표본이 충분히 크면 부트스트래핑이라는 시뮬레이션 기법을 사용해서 신뢰구간을 추정할 수 있음
- 즉, 표본의 시뮬레이션으로 모집단을 추정!
- 파이썬
scipy의.bootstrap()함수 사용 중간값의 신뢰구간을 구할 때 유용하다
import scipy
scipy.stats.bootstrap([df.price ], np.median, confidence_level=0.99)
# 중간값의 99% 신뢰구간생활팁! 데이터 분석을 할 때는
신뢰성이라는 말은 가능하면 안 쓰는 게 좋다! 일상적으로는 써도 되지만... 데이터 분석에서신뢰성이라는 말은 없다!!
5.4 신뢰구간에 영향을 주는 요소
- 신뢰구간이 좁을 수록 예측된 모수의 범위가 좁으므로 유용
- 신뢰수준 낮추기 : 큰 의미는 없음
- 표본의 변산성 낮추기
- 실험과 측정을 정확히 해서 변산성을 낮춤
- 데이터에 내재한 변산성은 없앨 수 없음
- 표본의 크기를 키우기
- 가장 쉬운 방법이나 시간과 비용이 증가
6. 통계적 가설 검정 statistical hypothesis testing
통계를 배울 때 가장 헷갈리는 것중 하나!
- Karl Pearson, Ronald Fisher 등 통계학의 초기 인물들이 개발한 절차
반증주의 철학에 기반하고 있어 일반적인 과학적 가설 검정(실증주의)과 다름실증주의: 내가 하고 싶은 주장을 입증반증주의: 내가 '까고 싶은' 주장을 깐다!
- 많은 비판이 있으나 오랫동안 쓰여왔기 때문에 여전히 널리 쓰임
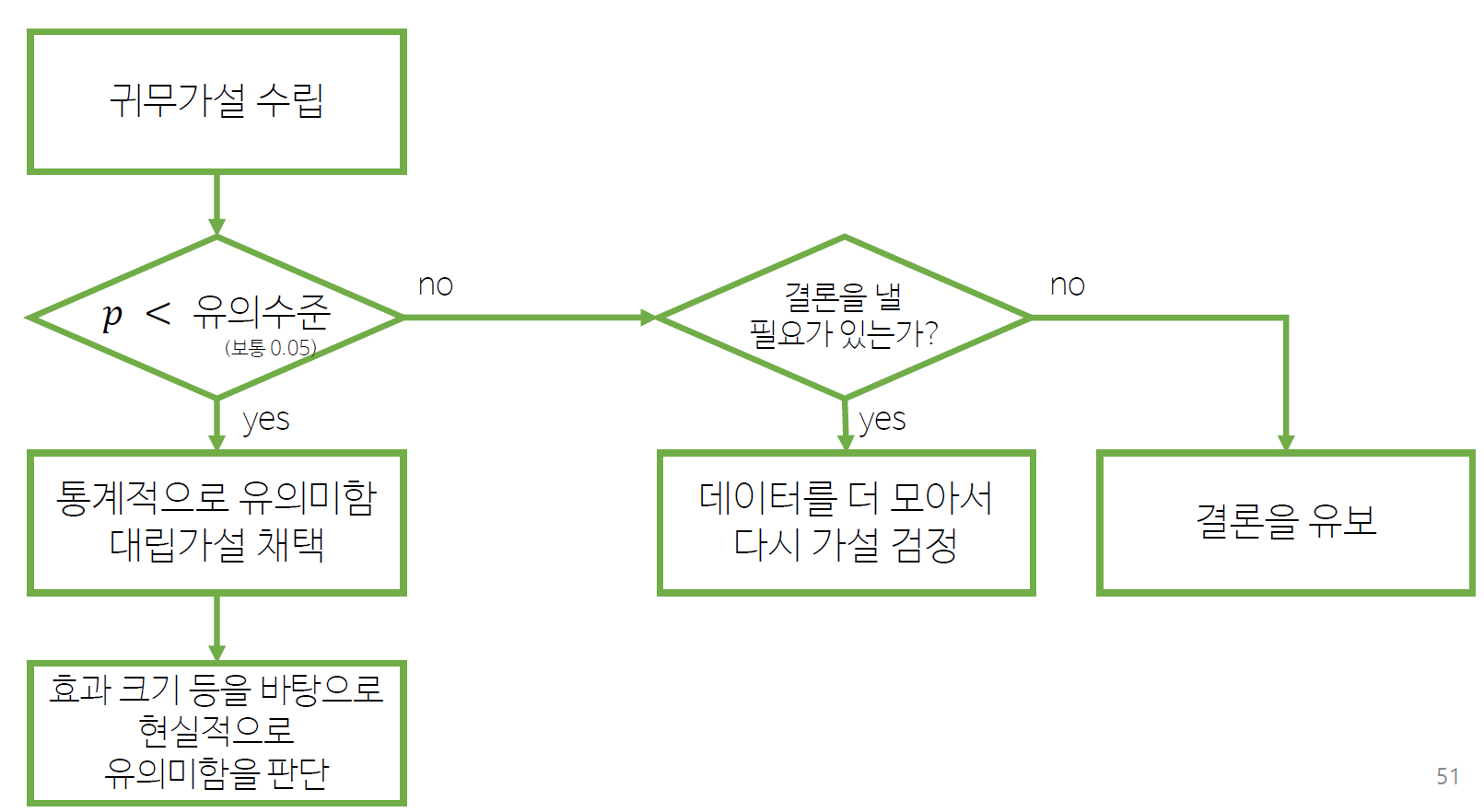
6.1 통계적 가설 검정의 절차
1) 귀무가설을 수립한다
귀무가설null hypothesis : 기각하고자 하는 가설 (내가 까려고 하는 가설 ㅎㅎ)대립가설alternative hypothesis : 주장하고자 하는 가설 (귀무가설을 설정하면 대립가설이 등장한다)
ttest할 때
0으로 넣었던 속성이귀무가설에 해당하는 것!
2) 유의수준을 결정한다
유의수준significance level : 100% - 신뢰수준 (예를 들어 신뢰수준이 95%라면 유의수준은 5%다)- 보통 5%(0.05)를 많이 사용한다.
- 내가
결정한 것! (예를 들어 내 마음의 기준인 것! 예를 들어 최소한 이 정도는 되어야 소개팅을 하겠다, 같은 것!)
3) p-값을 계산한다
p-값: 귀무가설이 참일 때 검정통계량 이상이 나올 확률- 데이터로
계산해서 나온 것
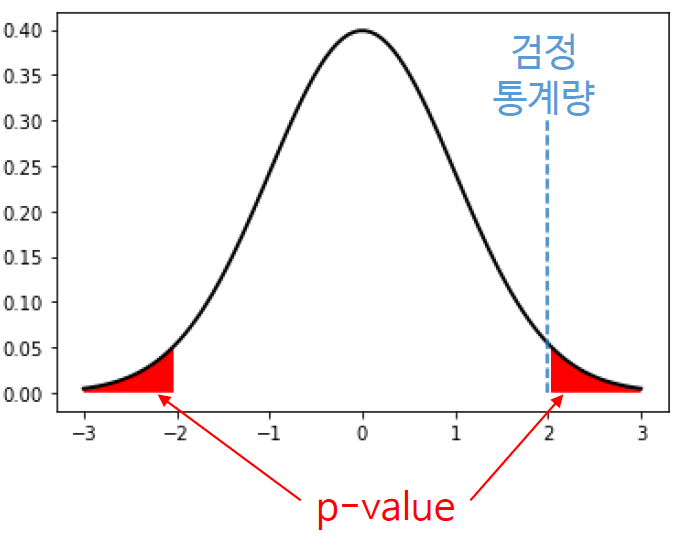
4) p값과 유의수준을 비교한다
p > 유의수준- 결론을 유보한다
- 결론을 내릴 필요가 있을 경우 데이터를 더 모은다
- 단, 반복해서 가설검정을 할 경우 유의수준을 조정한다
p < 유의수준- 귀무가설을 기각한다
- 흔히
통계적으로 유의하다라고 표현(현실적으로 유의미한 것은 아님)
6.2 Python에서 평균의 가설 검정
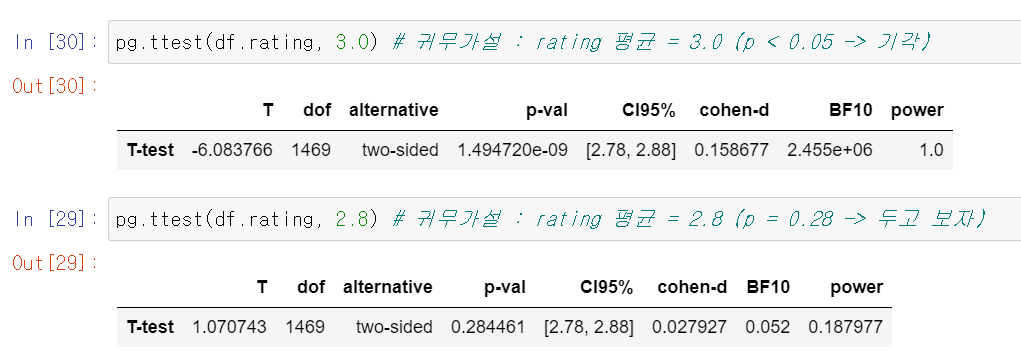
- p-value는 신뢰구간의 값에 영향을 받지 않는다 (유의수준은 우리의 맘 속에 있는 거니까)
가설 검정 2.8이라는 기각을 시도해보자!
- 성공 -> 기각
- 실패 -> 기각 못함
- 신뢰구간 2.78~2.88 : 2.8일 수도 있지만 2.81도 가능하고 2.82도 가능하고... 단, 3.0은 아니고!
- 그냥
신뢰구간을 보면 되는데, 100년이나 사용했고 남들이 하니까통계적 가설 검정도 볼 필요는 있당- 미국 통계 학회도 인정한, 남용하면 안되는
가설검정
6.3 통계적 가설 검정 순서도
6.4 가설 검정의 결과
- 두 가지 오류가 있을 수 있다.
- 귀무가설이 참인데 기각하는 경우를
1종 오류라고 한다. (ex: 배 나온 남성에게 임신이라고 하는 것) - 귀무가설이 거짓인데 기각하지 못하는 경우를
2종 오류라고 한다. (ex: 임신한 여성에게 임신이 아니라고 하는 것)
| 실제/가설검정 | 귀무가설 기각 | 귀무가설 기각 못함 |
|---|---|---|
| 귀무가설이 참 | 1종 오류 (False Alarm) | |
| 귀무가설이 거짓 | 2종 오류 (Miss) |
- 1종 오류는 유의수준만큼 발생 (유의수준이 1종 오류를 결정짓는다)
- 유의수준을 낮추면 1종 오류가 감소하고 2종 오류가 증가
사실(실제)과 나의 판단(가설 검정)은 다른 것이다!
6.5 1종 오류 vs. 2종 오류

- 귀무가설 : 평균 = 3.0일 것이다
- (참) 실제로도 3.0 (전수조사를 해야하기 때문에 우리는 평생 할 수 없다!)
- (거짓) 실제로는 3.0이 아님
- 여기에서 우리가 할 수 있는 것은 귀무가설을 기각 하거(p < 0.05)나 기각을 못하는 것(p > 0.05)
- 그런데 실제로 3.0이 맞더라도 기각하는 경우가 있음 : 이를 1종 오류 (예를 들어 재미있는 사람이 맞는데 소개팅 당일 긴장해서 재미있지 않아서 차였다)
- 그런데 실제로 귀무가설이 참일 때 기각할 경우는 5%이다. 우리가 유의수준을 5%로 잡았기 때문!
- 참과 거짓을 알 수 없으나 최악의 판단을 해도 5%라는 것.
우리는 판단(가설 검정)을 할뿐이지 실제로 알 순 없음!!!!
6.6 가설검정과 신뢰구간의 관계
- 통계적 가설검정과 신뢰구간은 동일한 이론의 양면
- 95% 신뢰구간이 귀무가설의 모수를 포함하지 않으면
- 5% 유의수준에서 가설검정은 귀무가설을 기각
6.7 p-value 에 영향을 주는 요소들
- 관찰된 통계량이 귀무가설에서 멀리 떨어져 있으면
p-value가 작아짐 - 표본의 크기가 크면
p-value가 작아짐
데이터를 충분히 많이 모았는지를 판단하는 데에도 사용할 수 있다
6.8 통계적 유의함 statistical significance
- 통계적 가설검정에서 귀무가설을 기각하는 경우
통계적으로 유의하다라고 함 - 동일한관계의 변수라도 표본이 크면 p-value 가 작아지고 통계적으로 유의하게 됨
- 어떠한 관계가 있다고 주장하기에 표본의 크기가 충분하다는 것으로 이해할 수 있음
- 현실적으로 유의미함을 의미하는 것으로 오해하지 말 것
현실적 유의미함은가치 판단의 대상예를 들어 어떤 약을 가지고 1000명 임상실험을 했다, 이것의 귀무가설은
효과가 없다이며 이때 대립 가설은효과가 있다이다. 이것이 통계적으로 유의미하다(귀무가설을 기각하는 경우)는 것은효과가 없다고 할 정도는 아닐 만큼 시험을 해봤다정도의 의미이다. 이 약을 먹을까 말까는현실적 유의미함이다.
구간 추정과 가설 검정
- 방향성이 반대, 서로 동전의 양면의 방법 같은 것이다!
- 구간 추정 : 표본 통계량 -> 모수 추정
- 대표적인 구간 추정 방법 중 하나가
신뢰구간
- 대표적인 구간 추정 방법 중 하나가
- 가설 검정 : 모수에 대한 귀무가설 -> 표본 통계량에 비추어 귀무가설 기각
- 가설 검정은
귀무가설을 먼저 설정하는 것
- 가설 검정은
여기서 잠깐!
- python : 프로그래밍 언어(영어, 한국어 같은 언어)
- pandas : 라이브러리(명령어 모음집)
- seaborn : 라이브러리(시각화)