A/B 테스팅
- 과학 분야에서
무작위 대조군 실험(Randomized Controlled Trials)을 주로 웹 서비스 등의 분야에서A/B 테스팅이라는 명칭을 사용하는 것 - 고객들에게 서로 다른 웹 페이지나 광고를 보여주고
목표 지표(ex: 전환율)를 측정 - https://goodui.org/leaks/
예시 : 당근마켓 팀 - 키워드 알림
1. 다양한 분야의 A/B 테스팅
1) 근거 기반 의학에서 근거의 수준
- Level I: 무작위 대조군 실험에서 얻어진 근거
- Level II-1: 대조군 실험에서 얻어진 근거 무작위 할당이 아님
- Level II-2: 동일 집단 연구 등
- Level II-3: 대조군이 없는 극적인 결과 등
- Level III:
임상 경험에 근거한 전문가의 의견 등
근거 기반 의학에서 가장 강한, 이상적인 근거로 보는 것이 바로Level I: 무작위 대조군 실험에서 얻어진 근거이다.A/B 테스팅같은 것!!!!근거 기반 의학이라는 명칭이 말하듯 여전히임상 경험에 근거한 것도 있다.
2) 정책에서 A/B 테스팅
- 대표적인 것이 2019년 노벨경제학상 수상자(아브지히트 바네르지 , 에스테르 뒤플로 , 마이클 크레이머)의 케이스
- 개발도상국에서 빈곤 해결을 위한 정책 개발에 무작위 대조군 실험을 사용
- 거대 담론이 아닌 작고, 실행 가능하고, 정교한 문제(정책)들을 실험
- https://youtu.be/0zvrGiPkVcs
선진국의 잘못된 개발도사국 지원 예시
- 플레이 펌프 : 깨끗한 물이 나오게 만든 아이들을 위한 놀이기구
2. A/B 테스팅에서 중요한 점
작은 실험을자주,많이해야 한다- 할 수 있다면 가능한 여러 가지 변수를 동시에 실험해야 한다
- 실험을 많이 할 수 있는 기술적, 문화적 환경의 형성되어야 한다
- 당연하거나 터무니 없어보이는 아이디어도 실험할 필요가 있다
서비스와 시장은 계속 바뀌기 때문에 실험을 자주 해야 한다.
올해와내년이 달라질 수 있는 것. 그렇기 때문에작은 실험을 해야 한닷!
최소 생존가능한 제품 Minimum Viable Product, MVP
- 대부분의 스타트업들은 누구도 사용하지 않을 제품을 만들기 때문에 실패한다
- "이 아이디어는 확실해!"
- "내 주변에서는 다 좋다고 하던대"
- "나오기만 하면 산다고 말했어!"
그러나 아무도 사지 않는다...
- 제품이 시장가치가 충분히 있는지 알기 위해
MVP를 만들어 테스트한다 - 가치가 확인되면 고객을 확보하고, 자금을 마련하여 기능을 추가한다
즉, MVP는
- 핵심가치를 검증하기 위해 필요한 최소한의 버전
- 최대한 빨리 배우는 것이 목표
- 제품/서비스의 가치가 초기 사용자를 참여시킬 수 있을 만큼 매력적인지(desirable) 테스트할 수 있어야 함
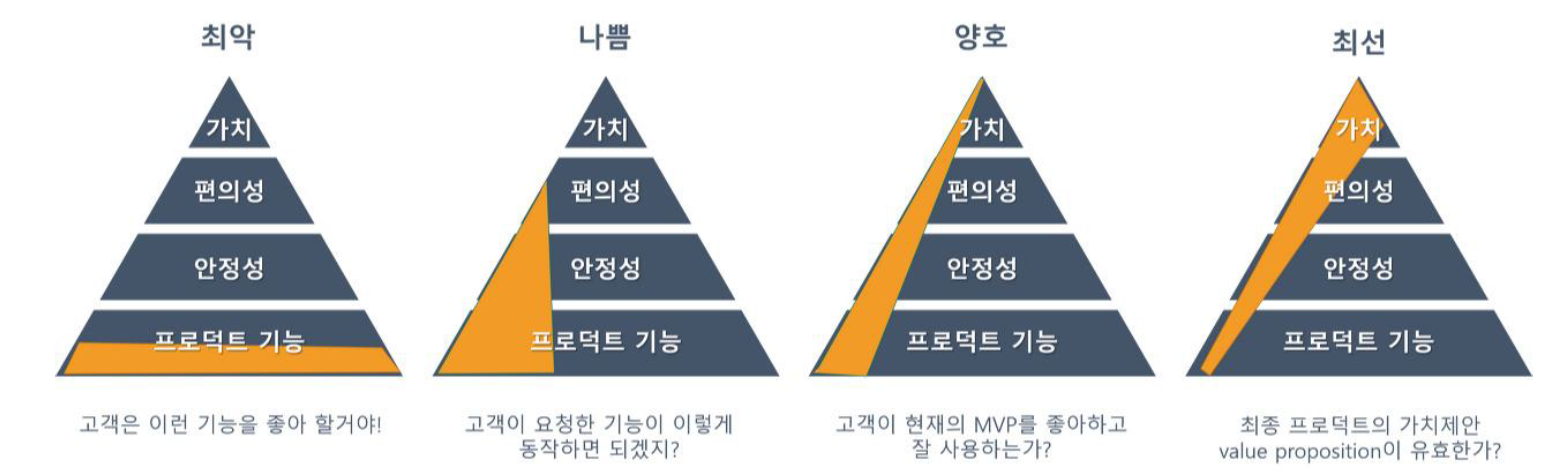
1. MVP의 예
1) 사람이 대신하기
- 제품이 해야할 일을 사람이 수동으로 처리
- 배달의 민족 : 앱에서 고객이 주문하면 매장으로 대신 전화
- 토스 : 앱에서 간편 송금을 하면 일정 시간마다 사람이 손으로 처리
- 리멤버 : 고객이 명함 사진을 찍으면 사람이 명함 내용을 손으로 입력
- 복잡하고 어려운 제품 개발 과정을 생략하고 핵심 가치를 먼저 제안
2) 소개만 만들기
- 제품을 만들기 전에 먼저 판매 (예: 크라우드펀딩)
- 가짜 광고를 만들어 핵심 가치에 고객이 반응하는지 확인
- 제품에 관심이 있는 사람들의 연락처를 받아 대기자 명단에 등록
- Dropbox의 예
- 제품의 기능을 설명하고 보여주는 영상 제작
- 기능 설명 영상이 입소문을 타면서 며칠만에 7만 5천명의 구독자를 확보
- 구독자 중에 스티브 잡스가 있어서 2억 5천만달러를 투자 받음
3) 기성품을 이용한 검증
- 기존의 제품을 이용해서 가설을 검증
- 제품의 내용이 동일할 경우 기존의 제품의 포장을 바꿈
- 예: 가격을 싸게 만들 방법이 있을 경우 일단 기존 제품을 사서 싸게 팔아본다 (유통기한이 임박하지 않았는데 유통기한 할인 스티커를 붙여서 판매해 보는 것)
- 기존의 제품들을 조합하여 비슷한 기능을 제공
- 예: 판매 사이트를 만드는 대신 이메일을 받아 노션에 수동으로 매물 목록을 게재
아이디어의 핵심을 빨리 검증해보는 것!!
- 다이슨 진공청소기가 아이디어부터 첫 시제품이 나올 때까지 2시간이 걸렸다는 유명한 일화가 있다.
- 청소기가 이런 식으로 생겼으면 좋지 않을까? 라는 생각에 자신의 집에 있는 진공청소기와 아이들의 시리얼 박스를 사용해 청소기를 만들어 주변 사람들에게 사용해보라고 한 것)
- 사이트를 개발하는 데에 너무 많은 시간을 쓰지 말고 이메일이나 유튜브, 노션 등을 활용해 바로 바로 해보는 것! 역시
실행력!!!!
4) 커뮤니티 만들기
- 어떤 문제를 해결하고자 하는 사람들의 커뮤니티 만들기
- 무신사(패션), 야놀자(여행) 등이 커뮤니티로 시작
Q. 실험할 때는 변수 통제가 중요, 실무에서는 리소스 절감을 위해 어느 정도 타협해서 진행할까?
A: Multi-Armed Bandit!리소스 통제는 Multi-Armed Bandit의 아주 정교한 알고리즘으로 계산, 이 알고리즘으로 만든 솔루션을 사와서 실험을 걸면 알려준다.
집단 비교 통계
- 이러한 실험을 통계적으로 어떻게 분석할까?
집단 비교 통계
집단 비교 통계 처리 순서도
- 다양한 집단 비교 통계가 있는데 우리는
독립표본 t-검정과분산 분석,카이제곱 검정을 확인해본다.
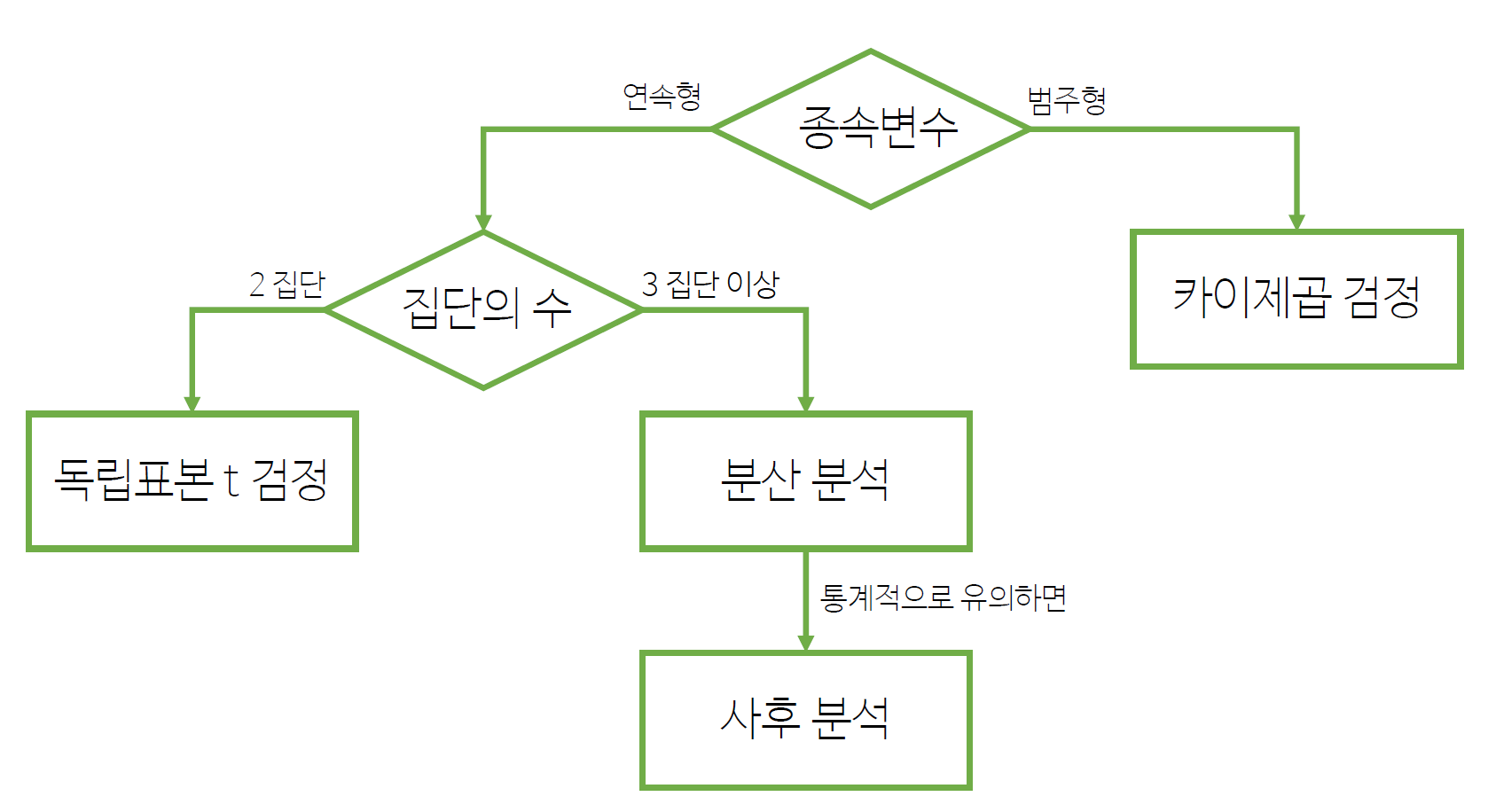
- 비교해야 하는
종속변수가연속형(ex: 매출)일때와범주형 (ex: 구매/비구매)일 때 다르며,비교하는 집단의 수가2개일 때와2개 이상일 때가 다름!
1. 독립표본 t-검정
지난 시간에 했던 것은
하나의 평균에 대한
- 평균의 신뢰 구간
- 평균에 대한 가설 검정
이번 시간은
두 개의 평균을 가지고 같냐, 다르냐, 뭐가 크냐 등의
- 평균 차이의 신뢰구간
- 평균 차이에 대한 가설 검정
- 평균 차이(A평균 - B평균)
1) 두 집단의 평균 차이
- 𝑋1: 대조군 평균
- 𝑋2: 실험군 평균
- 두 집단의 모집단이 모두 정규분포를 따르거나 또는 각 집단의 크기가 충분히 큰 경우(𝑛 > 30)
t-분포를 이용해서𝑋1−𝑋2의 신뢰구간을 계산 - 가설검정의 경우
독립표본 t-검정을 수행
2) 독립표본 t-검정 순서도
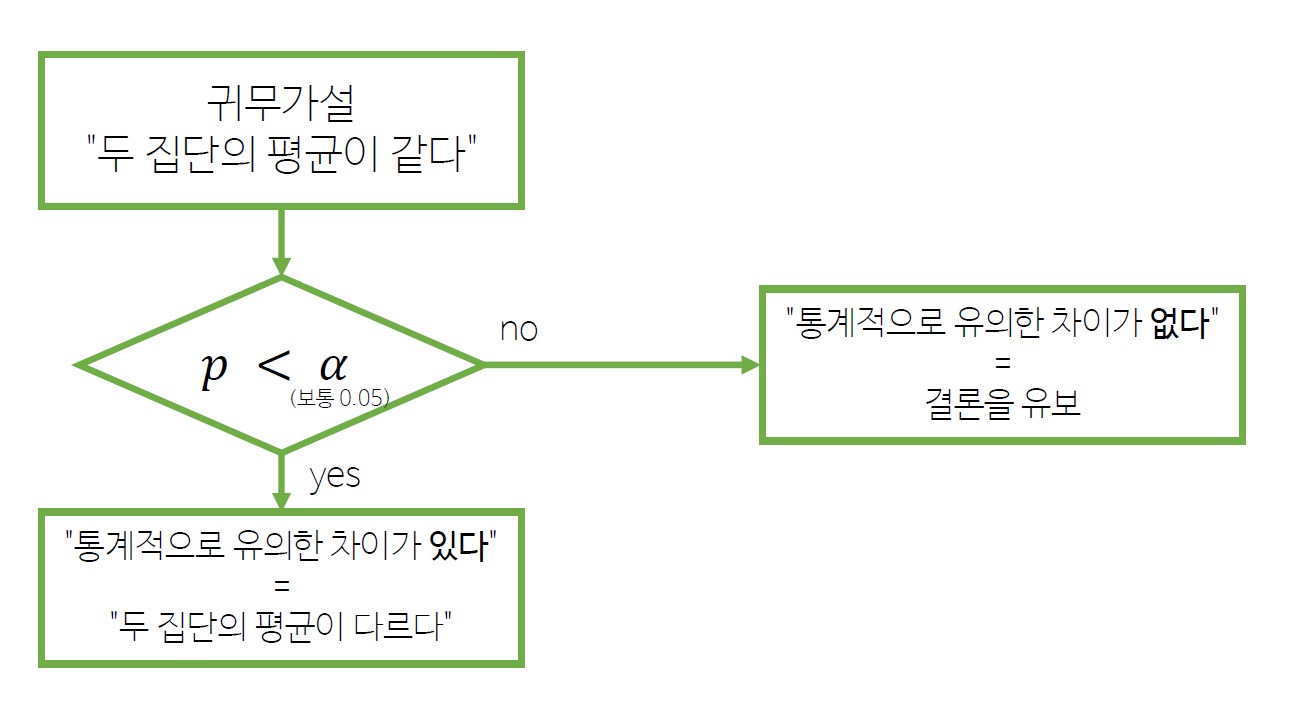
귀무가설 :
두 평균이 같다는 말은 곧평균차이 = 0이라는 말
귀무가설을 기각한다는 것은두 집단의 평균이 다르다는 것
3) Python에서 독립표본 t-검정
pg.ttest(k3, 800): k3의 평균이 800인가?pg.ttest(k3, avante): k3의 평균과 avante의 평균이 같은가? (즉,평균 차이 = 0인가?
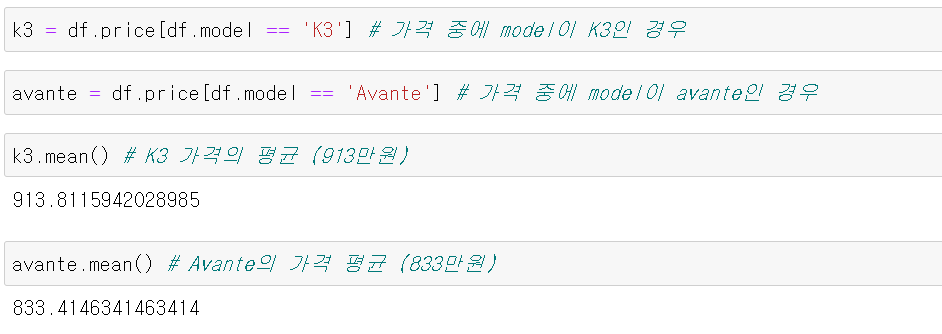
표본에서는 K3가 Avante보다 평균 80만원이 더 비싸다
그러면 모집단에서도 그럴까?

- 귀무가설은 모집단에서는
평균차이 = 0, 즉K3 평균 = Avante 평균이라는 것이다.- p-value를 보니 0.05보다 작음 > 귀무가설 기각
- 신뢰구간으로 보면 더 확실하게 해석할 수 있다.
- K3 평균 - Avante 평균 = 8만원 ~ 152만원 (신뢰구간)
- 이 말은 모집단에서는 K3가 Avante보다 못해도 8만원, 많게는 152만원까지 비쌀 것 이다는 의미이다
- 어쨌든 K3는 아반테보다 비싸다고 결론 내릴 수 있다!
Q. 실제 t-검정은 언제 사용할까?
A. 비교 대상이 있는 모든 경우에 사용할 수 있다!
- 신약 개발 : 신약 (평균 5일) vs. 플라시보-가짜 약(평균 7일)
- 제품 : 신제품 (만족도 3.8) vs. 경쟁제품 (만족도 2.9)
4) 검정력 power
유의수준(𝛼): 귀무가설이 참일 때 기각하는 1종 오류의 확률𝛽: 귀무가설이 거짓일 때 기각하지 못하는 2종 오류의 확률검정력(1−𝛽): 귀무가설이 거짓일 때 이를 올바르게 기각할 확률- 보통 검정력은
0.8이상을 요구 - 표본의 크기가 크면 증가
- 분석 결과에 나오는 검정력은 모수가 통계량과 같다는 가정 아래 계산됨
5) 효과 크기 effect size
- 관찰된 현상의 크기를 나타내는 방법
- 원래 숫자로 계산을 하면 확인하기 힘드니까! (예를 들어 아파트 부동산은 억단위로 가격이 바뀜)
- 방법
- 분산을 이용하는 방법 : 에타 제곱
- 평균 차이를 이용하는 방법 : 코헨의 d
5-1) 에타 제곱 𝜂2 eta squared
- 분산을 이용한 효과 크기 표현 방법
- 𝜂2=처치SS/전체SS
- 전체SS = (X - 전체평균)^ 의 합계
- 처치SS = (집단평균 - 전체평균)^의 합계
- SS: 편차제곱합 (Sum of Squares)
5-2) 에타 제곱의 의미
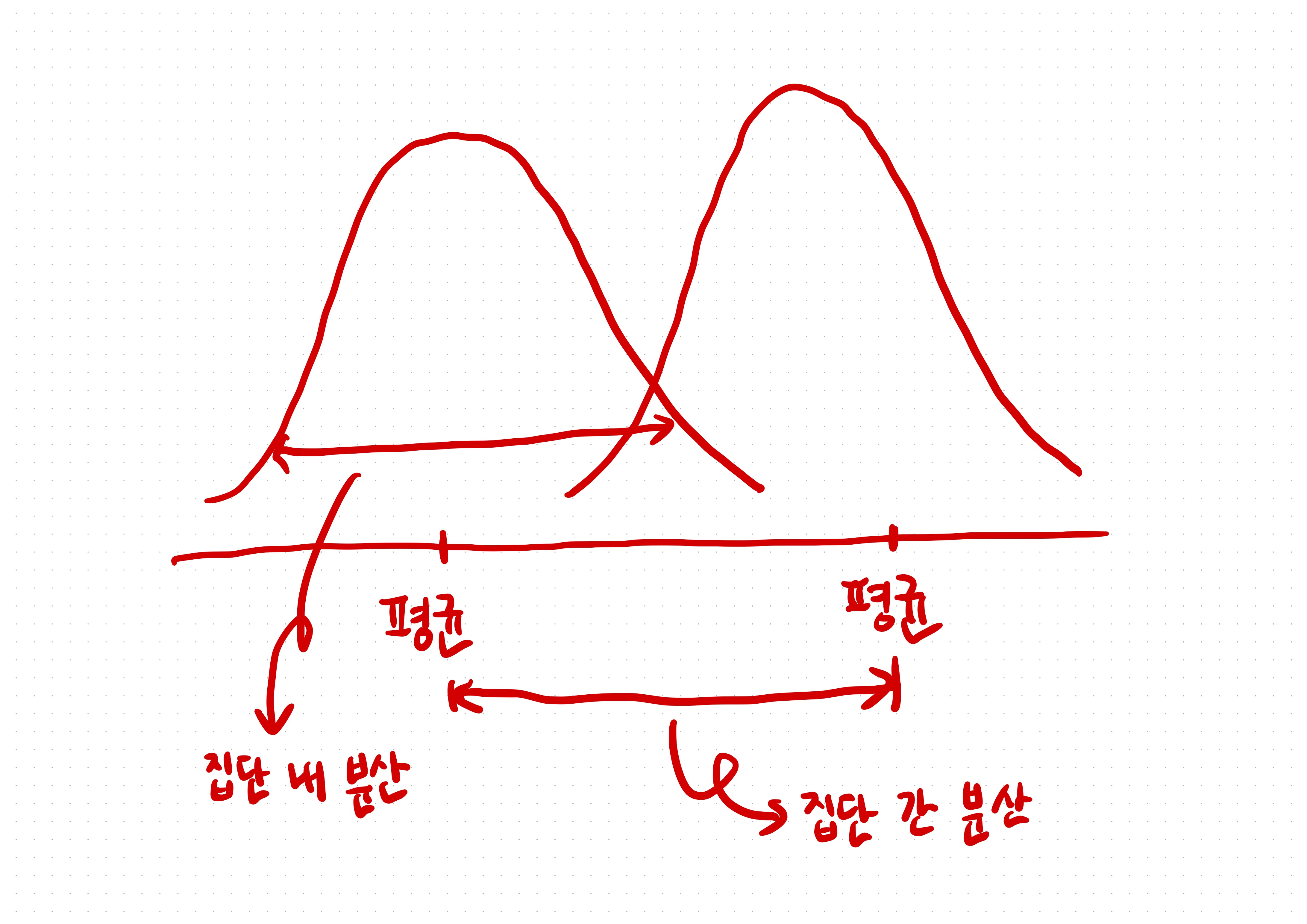
(1) 대조군 데이터는 1, 1, 1 이고 실험군 데이터는 3, 3, 3 인 경우
- 집단 내 차이는 없고 집단 간 차이만 존재
- 에타 제곱 = 1
= 100%
그러니까 에타제곱 1이라는 것은 어마어마한 것, 개인의 차이는 오로지 100% 집단에 의해 결정!
(2) 대조군 데이터는 1, 2, 3 이고 실험군 데이터도 1, 2, 3 인 경우
- 집단 내 차이만 있고 집단 간 차이는 없음
- 에타 제곱 = 0
즉,
(3) 에타 제곱 = 1
- 집단 간 차이만 있고 집단 내 차이는 없음
- 실험 조건에 따라 모든 것이 달라짐
- 실험 조건이 같으면 결과도 같음
(4) 에타 제곱 = 0
- 집단 간 차이는 없고 집단 내 차이만 있음
- 실험 조건에 따라 아무 것도 달라지지 않음
- 같은실험 조건에도 서로 다름
분산분석 했을 때 np2 값이 에타 제곱
- 0이면 영향이 없고 1이면 무한대로 영향이 있는 것
- 예를 들어 np2가 0.17 나왔다는 것은 치료효과(y)의 분산의 17%를 치료 방법이 설명한다.
- 이것은 어떤 사람은 치료 효과가 좋고, 어떤 사람은 나쁘고, 이런 차이가 있는데, 그 차이 중에 17% 정도는 치료 방법에 따른 것이라는 의미다!!!!! 오호!
- 주의!!! 개인의 점수의 17%라는 얘기가 아님!! 서로 다른 부분의 17%!
- 그래서 만약에 예
5-3) 코헨의 d Cohen's d
- 두 집단의 평균 차이를 데이터의 표준편차로 나눈 것
- (𝑋1−𝑋2)/𝑠
- 평균 차이의 크기를 알기 쉽게 나타낸 것
pg.ttest를 사용하면 나온다
예를 들어 IQ 검사에서 표준편차가 15다, A가 100이고, B는 115 일때 코헨즈d는 1이다. 코헨즈d가 1이면 상당히 많이 차이나는 것! 효과가 크다 적다의 절대적인 기준은 없고 위의 아이큐처럼 주관적으로 판단하는 것
세상에 절대적인 것은 없다!유의수준 0.05또한 주관적으로 결정한 것. 코헨즈디
5-4) 효과 크기 계산
- 에타 제곱
pg.compute_effsize(avante, k3, eftype='eta-square') - 코헨의 d
pg.compute_effsize(avante, k3, eftype='cohen')
그렇지만 안 해도 나오기 때문에 그냥
pg.ttest만 해도 된닷
2. 분산 분석 Analysis of Variance
- 집단 간 차이가 크다면
집단 내 분산에 비해집단 간 분산이 커질 것 - 모집단이 정규분포를 따르거나 각 집단의 표본 크기가 충분히 크면 집단 간 분산/집단 내 분산의 비율은 F 분포를 따름
- 이를 통해
모든 집단들의 평균이 같다는 귀무가설을 검정할 수 있음 - 귀무가설을 기각할 경우
적어도 한 집단의 평균은 다르다라는 대립가설을 채택
두 집단은
ttest와 똑같이 나오므로, 세 집단부터 분산분석을 사용한다.
1) Python 분산 분석
anova명령어를 사용한다
pg.anova(dv='price', between='model', data=df, detailed=True)dv는종속변수로 여기에서는 가격을 비교한다!- 나오는 정보를 자세하게 보려면
detailed=True를 설정한다 - 안 해도 OK! 안 하면 핵심 지표만 본다!
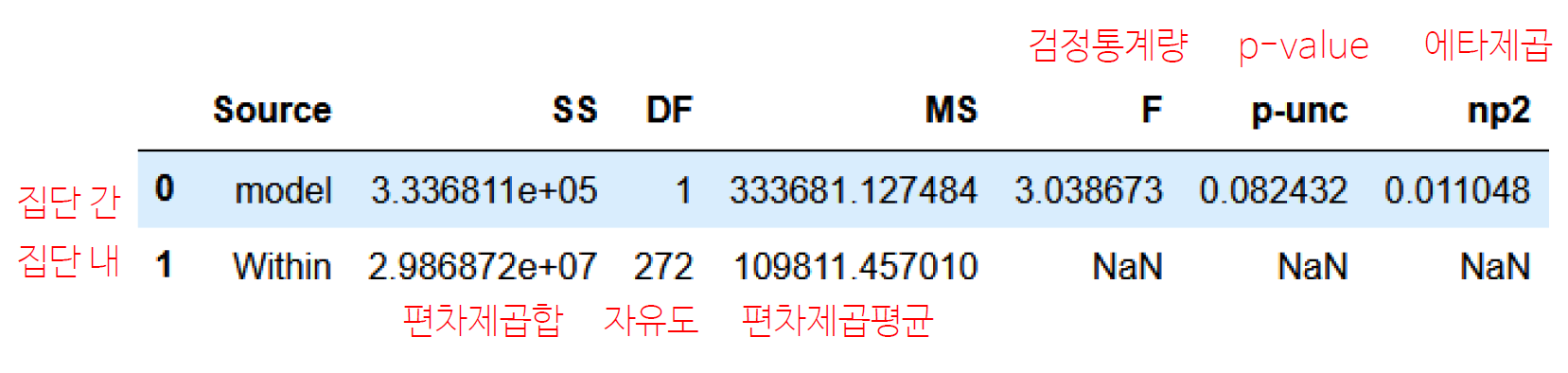
이거는 model이 2개 밖에 없기 때문에
T-검정과 것과 p-value가 같다.
Q. 그런데 p-value의 값이 다르게 나왔다면?
A. 원래 T-test는 두 집단의 분산이 같아야 한다. 그래서 서로 분산이 다르면(별도의 가설검정을 통해) 자동으로 보정을 해준다. 데이터가 크면 보정을 한 것과 안 한 것의 차이가 크게 없다.
그런데 두 집단 t-test의 p-value와 anova의 p-value가 다르다면, t-test의 correction 속성에 변화를 준다.correction=False하면 보정을 안한 결과를 출력해준다. (anova는 보정을 안한 결과를 출력한다)
이처럼 애매한 값은 보정을 하냐 안하냐에 따라 결과가 달라진다!
pg.ttest(k3, avante, correction=False) # p-val 0.082432 pg.ttest(k3, avante) # p-val 0.028187```
2) 다중 비교 multiple comparison
- 분산 분석은 한 번에 여러 집단을 비교할 수 있음
- 독립표본 t-검정은 한 번에 두 집단만 비교 가능
(집단이 여러 개 있을 경우 독립표본 t 검정은 집단 간의 모든 짝을 비교해야 한다)
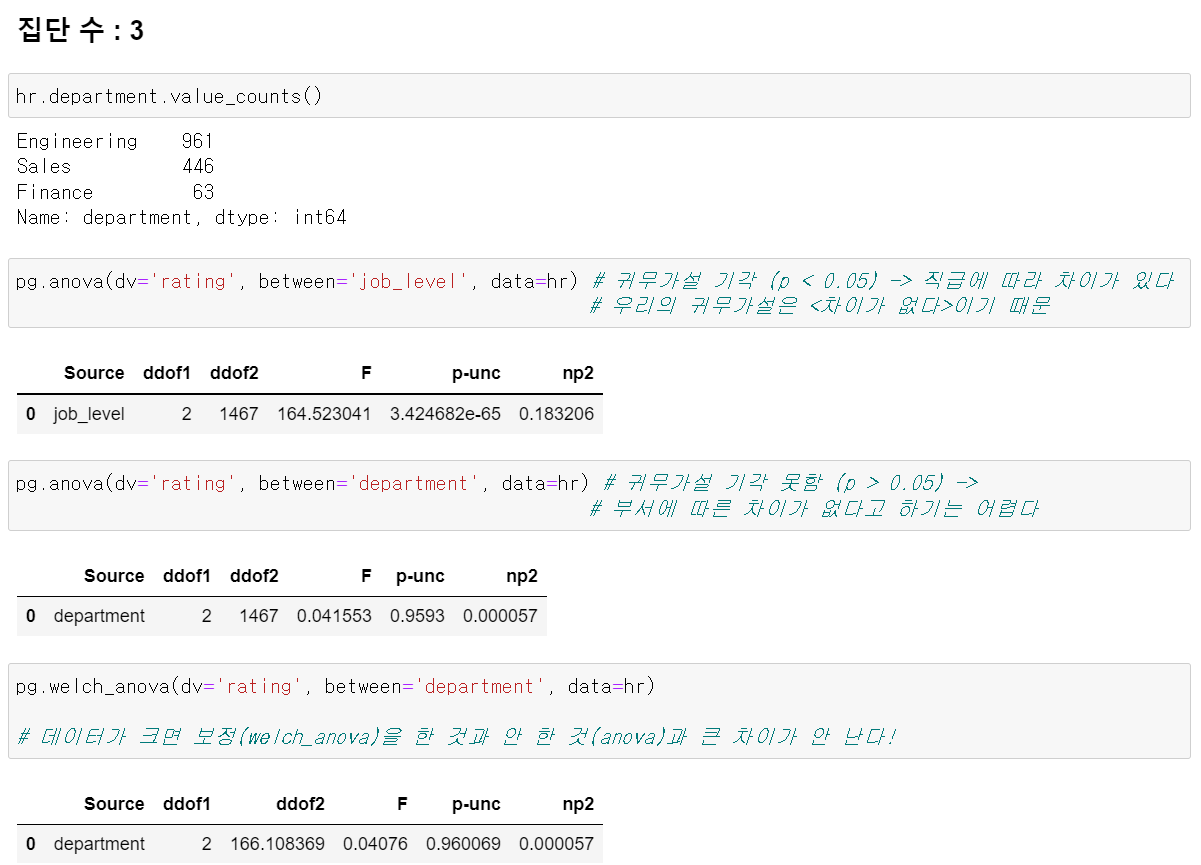
- 위에
귀무가설 기각 못함은부서에 따른 차이가 없다, 즉부서에 따른 차이가 있다고 하긴 어렵다임
귀무가설 기각 = 다르다!
- t-test : 다르다 (2개만 비교하니까 하나라도 다르면 그냥 다른 것)
- anova : 적어도 하나는 다르다 (3개의 집단 비교하니까)
3) FWER Familywise Error Rate
- 다중 비교를 할 경우 적어도 한 번 1종 오류가 발생할 확률
- 세 집단이 모집단에서 평균이 모두 같은 경우 유의수준 5%인 비교를 3번해서 3번 모두 1종 오류를 피할 확률(독립적이라고 가정할 경우) :
95% X 95% X 95% ≈ 86% - 바꿔 말하면 적어도 한 번 1종 오류가 발생할 확률(
FWER)은 14% - 비교를 많이 할 수록 FWER 은 증가함
Q. 같은 반에 몇 명이 있으면 생일이 겹치는 사람이 나올까?
A. 365명이 있으면 나올 것 같지만, 이보다 훨씬 적은 수가 있어도 나온다!
- 생일이 겹칠 확률 : 1/365
- 생일이 안 겹칠 확률 : 364 / 365
이걸 계속 곱하면 직관에 반하는 결과가 나온다!- 20명의 생일이 전부 다를 확률(한 번도 안 겹칠 확률)은 55%다. => 20명의 반 3~4개만 모여도 같은 생일이 있는 학생이 나온다!
4) 사후 검정 post hoc test
개별분석은 조금 더 까다롭게 한다.
- FWER을 통제하기 위해 분산 분석을 먼저 실시
- 분산 분석 결과가 통계적으로 유의하면(𝑝<𝛼) 사후 검정을 실시
- 여러 집단 중 통계적으로 유의한 차이가 나는 집단을 식별
- 사후 검정에서도 𝛼를 조절하여 FWER이 커지지 않도록 제어
- 각 집단의 분산이 같은 경우 : Tukey HSD
- 각 집단의 분산이 다른 경우 : Games Howell 검정
Tukey, Games Howell이 하는 일
1) 모든 조합에서 t-test를 자동으로 여러 번 반복 해준다
2) 많이 하다보면 어디선가 한번 틀릴 수 있음 -> 이걸 덜 틀리게 보정해준다(기준을 빡빡하게 잡으면 덜 틀리게 되어있지)
5) 등분산성 homoscedasticity
모든 집단의 분산이 같다~~~
집단간의 분산이 같다는 게 기본 가정으로 들어간다
- 집단간 분산이 같음은 Levene 검정으로 확인할 수 있음
pg.homoscedasticity명령어 사용
3. 분산 분석 실습
- 분산 분석 :
anova명령어 사용- 등분산이 아닐 경우
anova명령어 대신welch_anova를 사용함
- 등분산이 아닐 경우
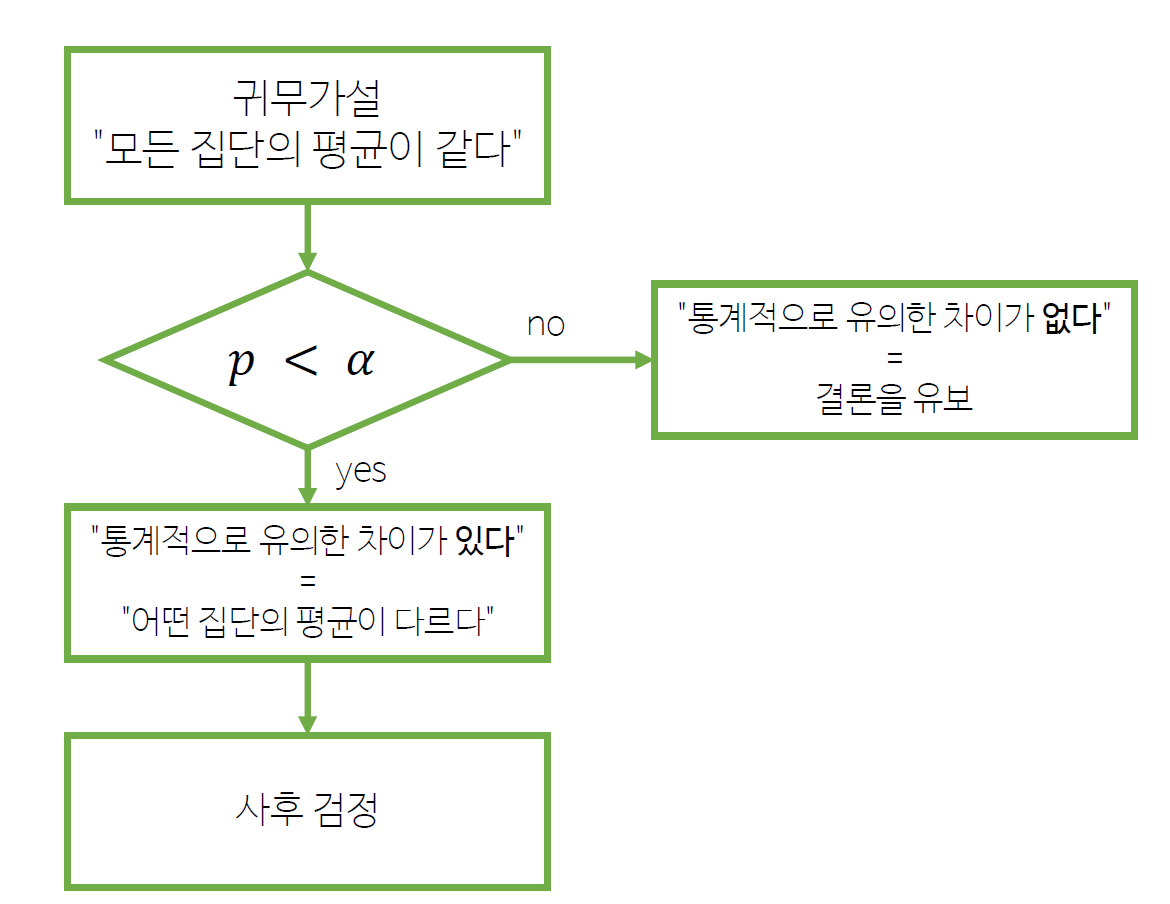
1) 분산 분석 순서도
2) 사후 검정
각 집단의 분산이 같은 경우: Tukey HSDpg.pairwise_tukey명령어 사용
- 각 집단의 분산이 다른 경우 : Games Howell 검정
pg.pairwise_gameshowell명령어 사용
분산 분석의 3 step
리마인드!
- 각 집단의 분산이 같은 경우 : Tukey HSD
- 각 집단의 분산이 다른 경우 : Games Howell 검정
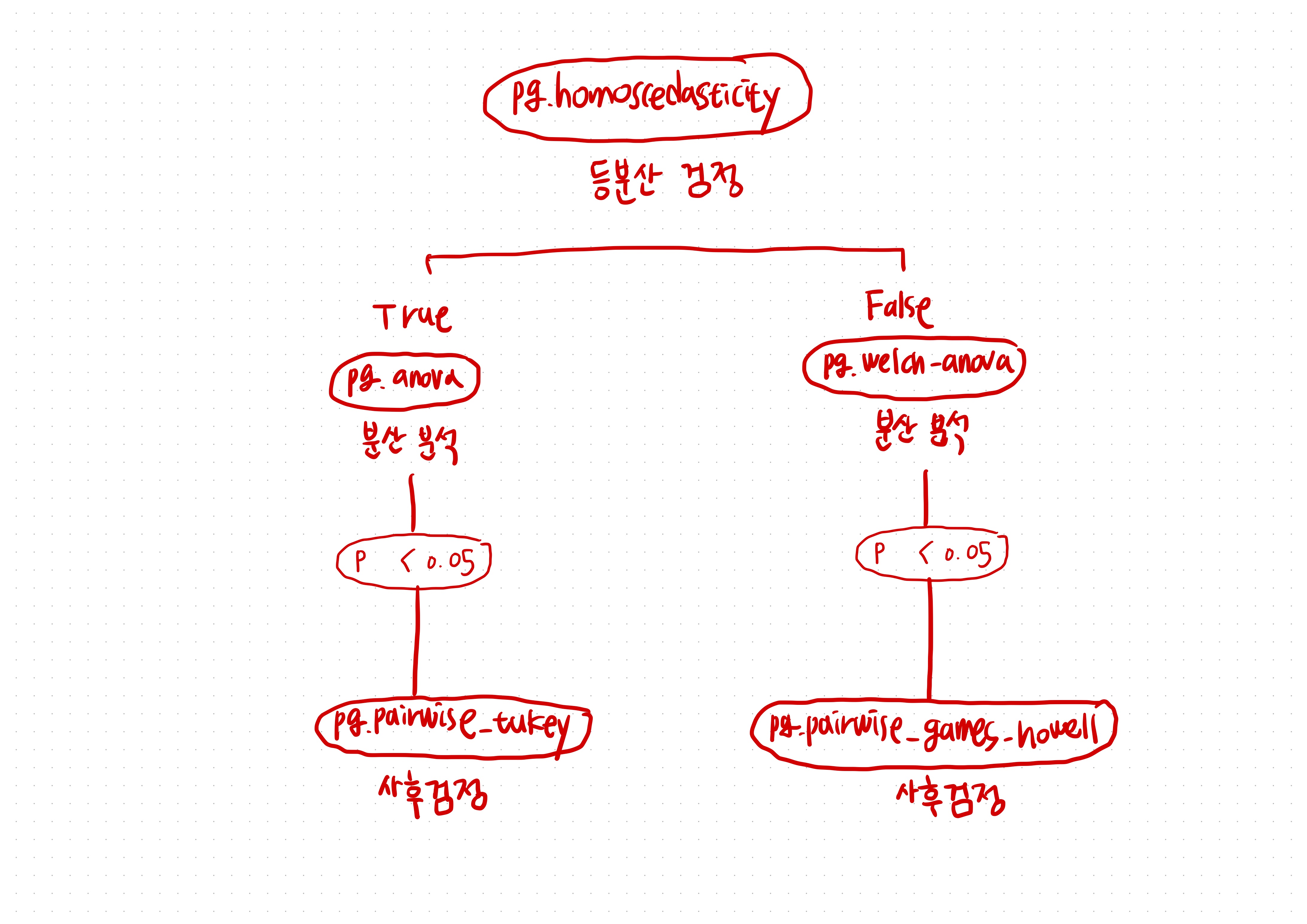
등분산성 검정이 통과되었을 때
- 등분산성 검정: pg.homoscedasticity를 사용해 분산이 같은지 확인 -> 통과 (equal_var = True)
- anova를 해준다 (pg.anova)
- 귀무가설이 기각되면 pg.pairwise_tukey를 사용해 개별 분석을 한다
등분산성이 깨졌을 때 보정하는 시나리오
- 등분산성 검정 : pg.homoscedasticity를 사용해 분산이 같은지 확인 -> 기각 -> 다르다(equal_var = False)
- welch_anova를 해준다 (pg.welch_anova)
- 귀무가설이 기각되면 pg.pairwise_gameshowell을 사용해 개별 분석을 한다!
아노바나 웰치 아노바를 꼭 해야하나?! 통계학자들은 유의수준에 집착한다! 그리고 집착할만한 이유가 있다!
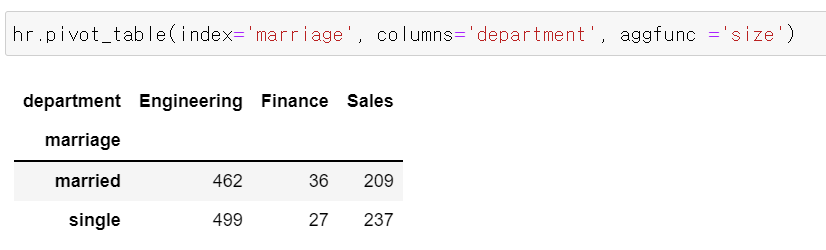
4 분할표 contingency table
- 행과 열이 서로 다른
범주형 변수의 값을 나타내는 표 - 표의 각 칸에는 사례 수를 표기
hr.pivot_table명령어 사용
- index : 행 방향
- columns : 열 방향
- aggfunc : 갯수로 칸을 채워라!
5. 카이제곱 검정
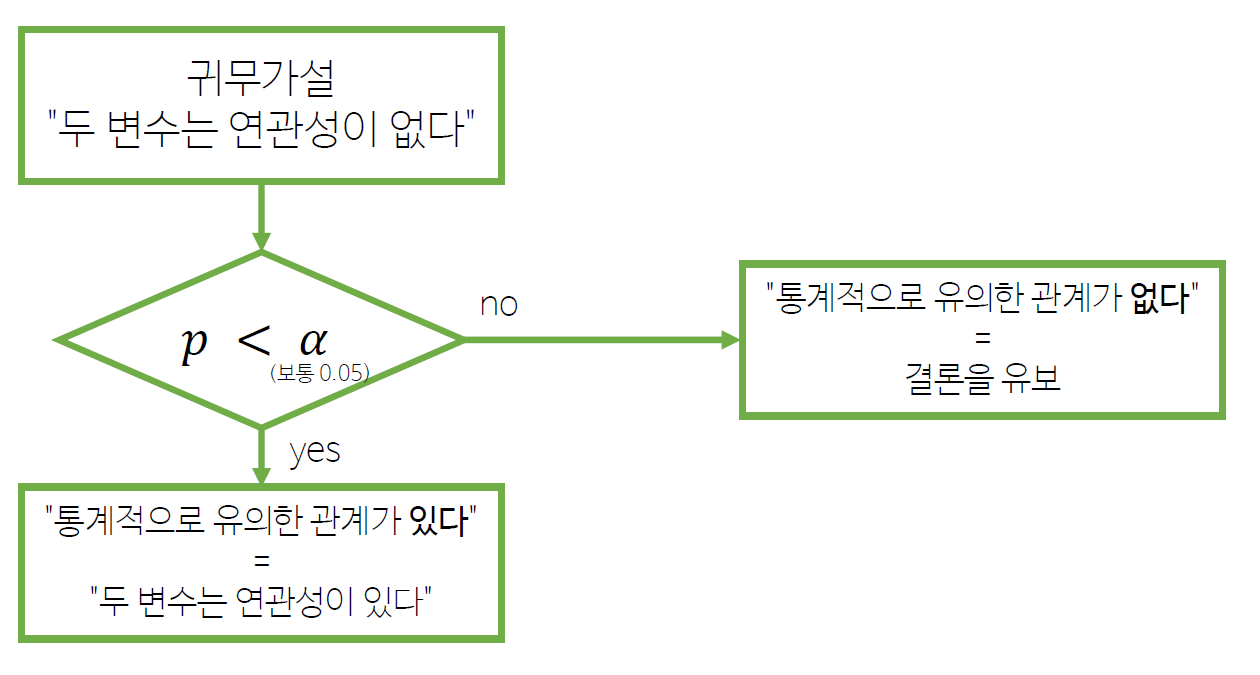
두 범주형 변수가 독립적이라는 귀무가설을 검정H0: 부서별 결혼 비율이 같다 (이걸 기각하면 -> 아래다르다가 나오는 것)H1: 부서별 결혼 비율이 다르다
- 데이터가 적으면 p-value가 부정확할 수 있음
- 기대 빈도(expected)가 5 이하인 경우가 20% 이하를 권장 :
expected를 했을 때 들어있는 숫자들이 너무 작으면 안 된다는 말!
- 기대 빈도(expected)가 5 이하인 경우가 20% 이하를 권장 :
- Cramér's V: 두 변수의 관계를 0~1 로 표시
- 0: 전혀 관련이 없음
- 1: 완전히 일치
1) 카이제곱 검정 순서도
2) 카이제곱 검정 실습
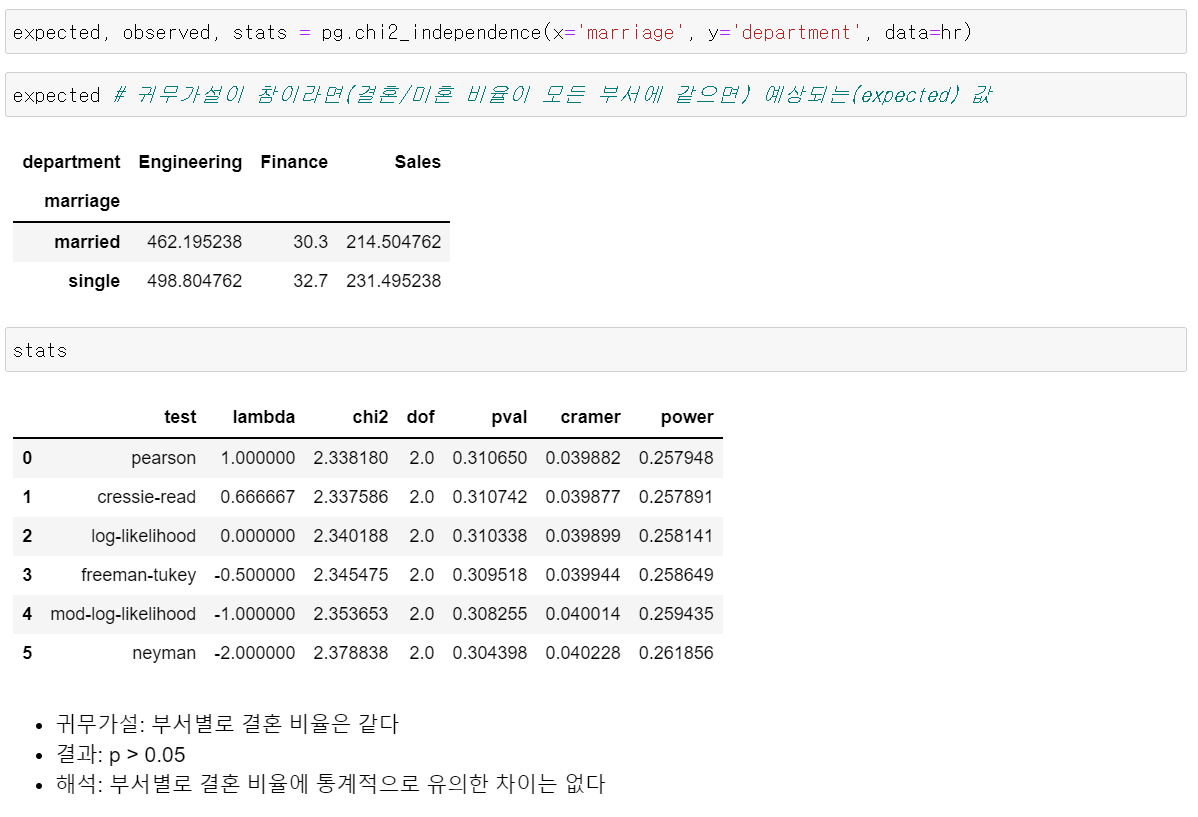
stats했을 때 첫 번째 줄을카이제곱 검정이라고 한다!! 첫 번째 줄만 보면 됨!!- 크래머
cramer: 집단 간의 관계 - 상관계수와 비슷한 것- 0은 전혀 관련이 없음!
- 1은 두 집단이 완전히 일치, 같이 움직이는 것
- chi2 : 근사치
기타
1. 독립표본 t-검정과 일표본 t-검정
독립표본 t-검정 independent samples t test
- pg.ttest(k3, avante)
- 귀무가설 : k3와 avante, 두 집단의 평균이 같다
- 신뢰구간 : k3와 avante의 평균 차이의 신뢰구간
일표본 t-검정 one sample t test
- pg.ttest(k3, 900)
- 귀무가설 : k3의 평균이 900이다
- 신뢰구간 : k3 평균의 신뢰구간 (평균 차이를 구하는 것이 아니다)
쓰는 함수는 같지만, 이 둘은 다른 분석이다!
900은 신뢰구간에 영향을 주는 숫자가 아니다!
신뢰구간은 가설과 상관없이 결정되는 값이다. 신뢰구간을 구하기 위해 필요한 것은신뢰수준!신뢰수준에 의해서만 달라진다!
2. 외우자!
- 신뢰구간 : 신뢰수준으로 계산
- 가설은 계산에 포함 X
- p-value : 가설로부터 계산
- 유의수준은 계산에 포함 X
- 계산된 p값과 유의수준을 비교
각각의 값을 구하기 위해 공통적으로 필요한 것 : 평균, 표준편차, 데이터 개수
여기서 잠깐!
독립표본
- one sample t-test (한 집단)
- independent sample t-test (독립표본, 두 집단)
- ex) 아이들이 부모와 같이 살고, 안 살고 : 짝이 되는 게 없다! 그래서 독립표본!
- paire samples t-test (대응표본, 두 집단) : 두 집단에 서로 자기 짝이 있다! -
- ex) 부부 연구
남편 집단 <-> 아내 집단
남편 A 아내 A
남편 B 아내 B
- ex) 부부 연구
3. 분산 분석은 분산으로 차이를 따지는 걸까?
-
분산 분석은
분산의 차이를 비교하는 게 아니다! 그리고 집단 별로 분산이 다르다고 보는 것도 아님! 이름에 속지 말것!분산 분석 = 집단 간 분산 / 집단 내 분산=> 이 비율을 보는 것(다른 집단끼리 차이) / (같은 집단이라도 성적이 다를 수 있음)
-
차이가 크다 작다는 무엇을 비교하느냐에 따라 다르다
- 1Km와 1mm는 전혀 다른 단위
- 그리고 1Km 걸어갈 때와 차를 탈 때도 다르다!
-
절대적인 건 없다 기준에 따라 다르다!
-
기준을 잡은 게 여기서는
같은 집단이라도 성적이 다를 수 있음(집단 내 분산)인 것이다.- 예를 들어
한국, 일본, 미국 집단 간 차이 / (한국 사람 간의 입맛 차이)
- 예를 들어
-
분석은 기준이 있어야 한다.
중요한 것은 분산 분석은 분산을 분석하는 게 아니라
평균 차이를 분석하는데, 그 과정에서 이 둘의 비율을 비교하기 때문에 이름이 분산 분석이다.
아주 인상적인 자소서를 쓰는 방법 : 깃헙 오픈 소스에 기여하기!
Q. 분산 분석은 언제 쓸까?
A. 평균을 비교할 때! (사실 평균을 비교하지 않는 게 있을까?)
- 서비스 제품을 만드는데 고객만족도의 평균을 비교하고 싶다
- A제품의 고객만족도
- B제품의 고객만족도
- C제품의 고객만족도
- 팀별 실적
- 1팀 평균 실적
- 2팀 평균 실적
- 3팀 평균 실적
