지금까지 배운 것은 어떤 현황을 보여준다고 한다면, 오늘 배울 회귀분석은 예측을 하는 것이다.
- 기술통계
- 신뢰구간과 가설검정
- 집단 간 비교 (A/B테스팅)
- 상관 분석
지도학습 supervised learning
- x를 이용하여 종속변수 y를 예측하는 것
회귀분석은 크게 지도학습에 속한다.
여기서 지도는 '가르친다'는 의미다.
- x는 여러가지가 될 수 있는데, 예를 들어 x가 주택의 여러 정보(평형, 역까지의 거리) 등으로 주택의 가치를 예측할 수 있고 이를 통해 적절한 금액을 대출받을 수 있는 것이다. 이런 여러 가지 상황에 대해 다루는 게 지도학습이다.
- 통상적으로 예측은 미래에 대한 것을 이야기하지만, 통계에서 예측은 꼭 미래를 말하는 것은 아니다. 정보 같은 것(주택의 가치), 아는 것을 통해 모르는 것을 짐작하는 것을 예측이라고 한다.
- 독립변수 independent variable : 예측의 바탕이 되는 정보, 인과관계에서 원인, 입력값
- 종속변수 dependent variable : 예측의 대상, 인과관계에서 결과, 출력값
- 결국 주택의 가치는 여러 정보에 달려 있기 때문에 종속변수인 것이다.
1. 통계에서 예측의 의미
- 통계학에서
예측(prediction)은 어떤 값에 대한 추론을 의미 - 시간적인 의미는 아님 (그래서 아래 미래 예측을 부르는 명칭이 따로 있다)
- 지도학습에서 예측은 변수들 사이의 패턴을 파악하여 한 변수로 다른 변수를 추론하는 것
- 시계열 분석 등에서 하는 미래에 대한 예측은
forecasting이라고 구분
2. 종속변수에 따른 지도학습의 구분
지도학습은 종속변수(예측하는 대상(y))에 따라 구분한다.

- 종속변수가 연속(가격, 크기, 선호도)라면 회귀분석이라고 한다.
- 예측하는 것을 회귀분석이라고 하는 구나, 또 통계분석가들이 이름을 이상하게 붙였구나,...
- 회귀선(추세선)을 찾는 것
단순 회귀 분석 : 변수가 1개인 경우
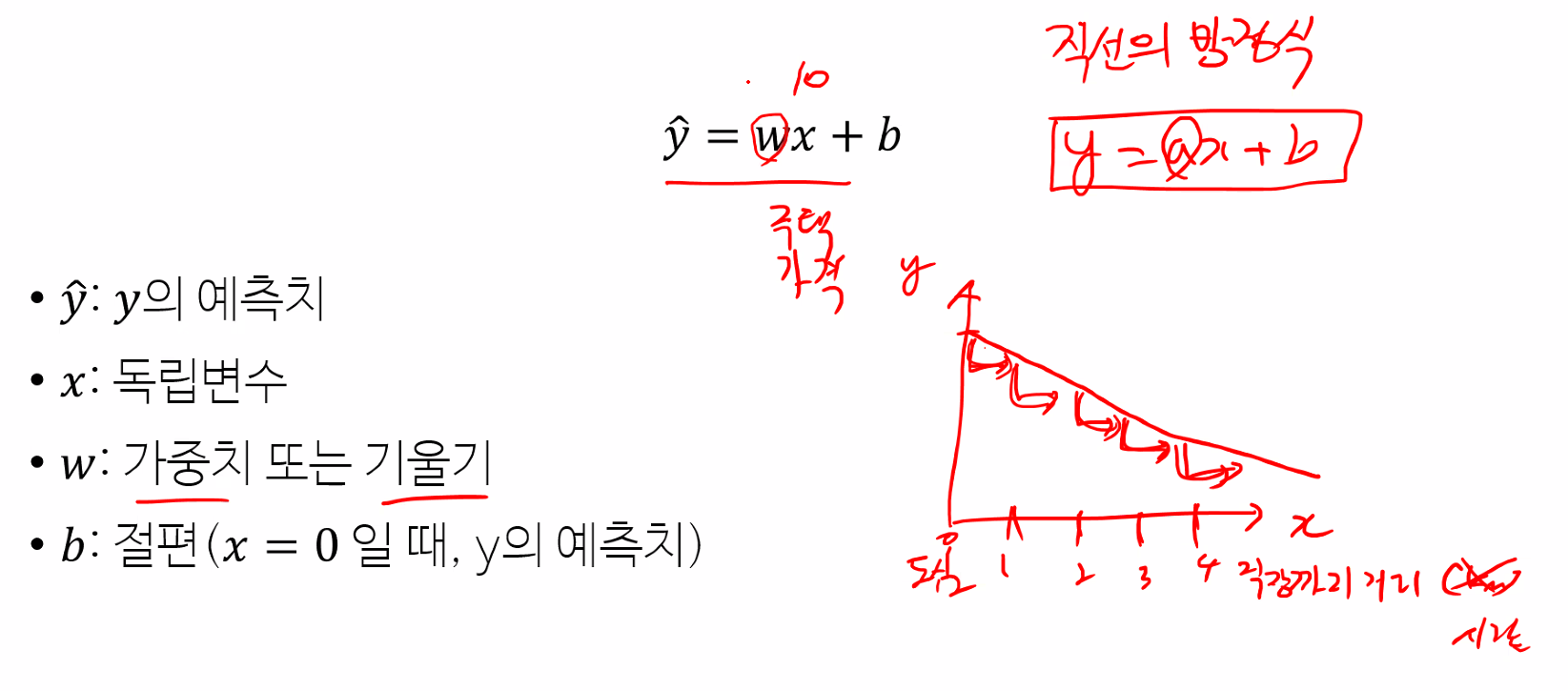
1. 선형 모형
예측할 때 공식,
직선의 방정식(y = ax + b)으로 선형 모형을 만들었다.
1) 선형 모형 회귀분석 예시: 피부암 사망률
- 독립변수 (x): 위도
- 종속변수 (y): 천만명 당 사망자 수
2. 잔차 residual

어떤 의미에서 전차분삭과 분산이 같다. 예를 들어 고객의 만족도를 모를 때 평균으로 그 고객의 만족도를 예측하는 것이다. "남들도 3점 정도로 만족하니까 선생님도 3점 정도 만족하겠죠." 이런 식으로 평균으로 예측할 수 있는데, 그렇게 하면 잔차분산은 분산이랑 같다.
차이를 제곱하니까 더 커지는 것!
잔차분산이 작은 게 좋은 것이다.
3. 최소제곱법 Ordinary Least Squares
- 최소제곱법(ols): 잔차 분산이 최소가 되게 하는 w, b 등 계수를 추정
- 최소
제곱법인 이유 분산의 계산에 제곱이 들어가므로 - 가장 널리 사용되는 추정방법
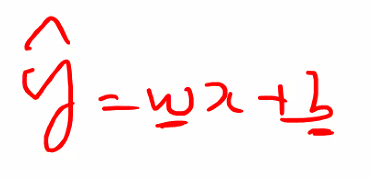
잔차분산이 최소가 되는 걸 찾는 게 중요!
4. Python 회귀분석
car 데이터를 활용한 실습
- 가져오기
from statsmodels.formula.api import ols - 분석: 종속변수(y) ~ 독립변수(x) 형식으로 관계식을 표현
m = ols ("price ~ mileage", data = df).fit() - 결과
m.summary()
1) 회귀계수 추정 결과
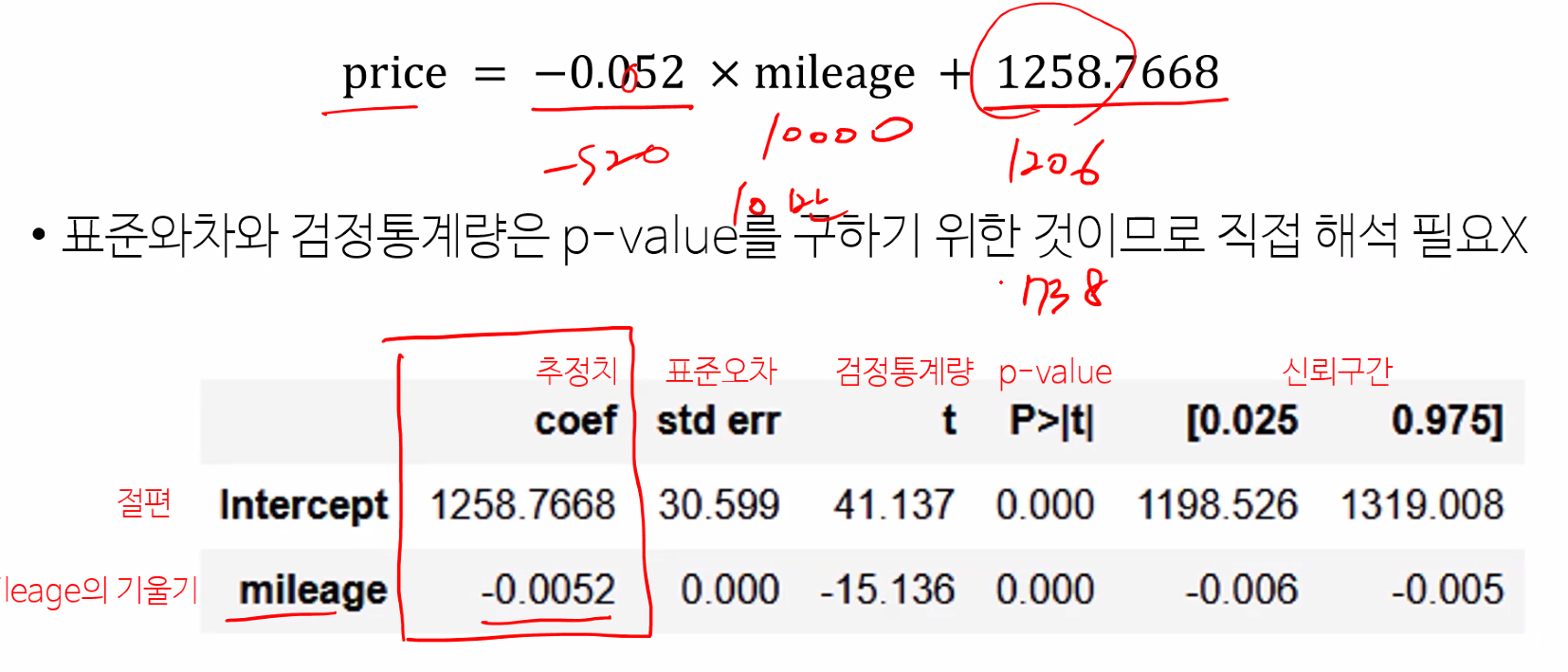
추정치
절편 : 주행거리가 0인 차의 가격은 1258.7668일 것이다.
기울기 : 주행거리를 대입하면 가격을 예측할 수 있는 공식이 완성
신뢰구간
2) 회귀계수의 가설 검정
p-value : 모든 것을 0이다라고 보고 판단(귀무가설 : 모집단에서 회귀계수 = 0)
3) 예측
위에서 만든 수식이 저장된 m 변수로 새로운 데이터를 예측한다.
- 새로운 데이터 만들기
- 위에 m은 가격을 산정하는 하나의 공식을 만들었다고 생각하면 됨!
new_df = pd.DataFrame ({'mileage': [10000, 20000]}) - 모형에 입력하여 예측
m.predict(new_df)
위의 방식으로 실무에서 수요 예측을 할 수 있다.
마켓컬리에서 일을 한다고 했을 때 추석에 전복이 얼마나 나갈까?
이런 정보를 대입해보니까 이번에 전복의 판매는 이정도가 예상된다.
커머스에는 이런 식으로 예측을 하는 것이다.
5. R제곱 R Sqaured
- 회귀 분석에서 예측의 정확성을 알기 쉽게 판단할 수 있게 만든 지표 (0~1, 즉 0%~100%)
𝑅제곱 = 1−(잔차분산/분산) => 잔차분산이 0이면 1, 즉 100%가 된다 - R제곱 = 0: 분석결과가 y의 예측에 도움이 안됨
- 0이 나왔다는 것은 잔차분산과 분산이 같은 경우
- 잔차분산(실제 - 예측) = 분산(실제값 - 평균), 즉 평균이랑 예측이 같다는 것이지!!
- 0이 나왔다는 것은 잔차분산과 분산이 같은 경우
- R제곱 = 1: y를 완벽하게(100%!!!) 정확히 예측할 수 있음
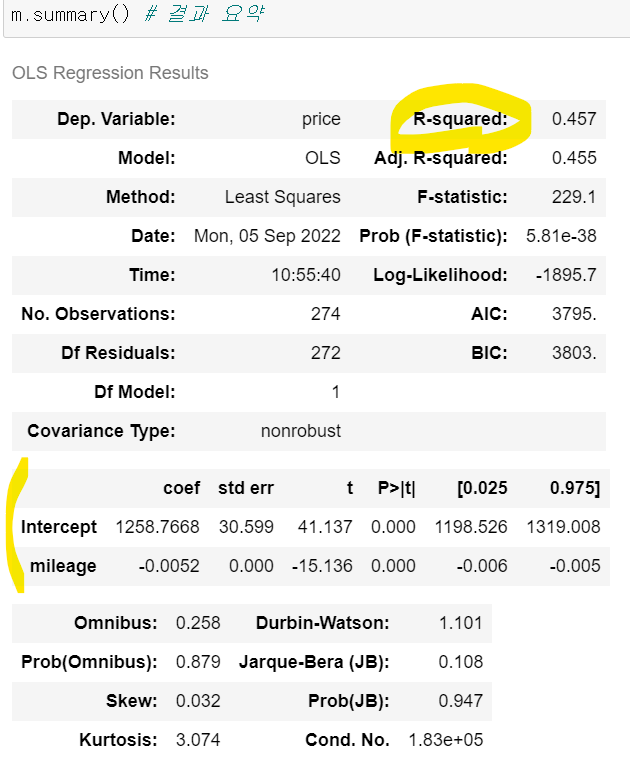
위에서 예측을 평균으로 할 수도 있다고 했는데, 그렇다는 것은 예측이 무난한 예측이라는 것이다. 이것에 따르면 마일리지라는 변수가 가격을 예측하는 데 별 도움이 안되는 것이지. 어차피 평균 가격으로 예측할 거잖아!
- R제곱을 비교하면 어떤 변수를 갖고 한 예측이 더 잘 맞는 예측인지 볼 수 있겠지
Q. R제곱이 100%가 나와야 하나요?
A. 아니다. 우리가 할 수 있고 해야 하는 것은 조금 더 잘 예측하는 것이다.
세상에는 예측할 수 없는 것들이 있다는 것을 염두해야 한다.
필립 테틀록이 정치, 사회, 경제 전문가들의 예측 능력 연구했는데, 5년 이상 미래는 예측 못했다.
세상이 예측불가하다고 생각하는 사람들이 예측을 더 잘한다고 한다.
- 계속 의문을 갖고 세상을 바라보자
기업의 입장에서는 100% 예측하지 못해도 별 상관이 없다.
- 개개의 예측에 대한 이익이 -100, 0, +100 등으로 나오면, 한번 틀린 것이 다음에 만회가 되기 때문!
1) R제곱을 읽는 법
- R제곱을 읽을 때는 "모형이 종속변수의 분산의 ~%를 설명한다"라고 함
- 설명한다 = 1 - (잔차분산/분산)분석을 했기 때문에
- 예: R제곱 = 0.3 -> "분산의 30%를 설명한다"
- R제곱은 TSS(분산)에 비해 RSS가 얼마나 작아졌는지를 나타냄
- TSS와 RSS는 모두 평균 또는 예측에 대한 변산성(불확실성)
- 변산성이 줄어들었다 -> 불확실성이 줄어들었다 -> 설명이 되었다

2) R제곱과 피어슨 상관계수
- 단순회귀분석(독립변수가 1 개인 회귀분석)의 경우
- 회귀분석의 R제곱 = 독립변수와 종속변수의 피어슨 상관계수의 제곱
=> R제곱이 낮으면 상관계수의 제곱도 낮아지므로, 이렇게 나오면 다른 변수로 계산을 해보자.
3) 연식에 따른 가격 예측
m = ols('price ~ year', df).fit()
m.summary()에서 R제곱은 0.687, 마일리지와 가격에서 R제곱은 0.457로, 주행거리보다 연식이 더 예측을 잘한다.
그러므로 내가 중고차 딜러라면, 차를 판매하려는 사람에게 한 가지 질문을 할 수 있다고 할 때 가정할 때 제일 먼저 해야할 질문은 "차의 연식이 언제인가요?"가 될 것이다.
독립변수가 범주형인 경우
- 앞서 했던 주행거리와 연식은 연속형 변수였음, 반대로 차종은 범주형 범주가 됨
- 범주형 변수는 기울기를 곱할 수 없음
- 연속 변수로 변환하여 모형에 투입
- 여러 가지 방법이 있으나 가장 많이 사용하는 것은 더미 코딩
- Jamovi, R, Python은 자동으로 더미 코딩
1. 더미 코딩 dummy coding
- 범주형 변수에 범주가 k개 있을 경우 k-1개의 더미 변수를 대신 투입
- 범주 중에 하나를 기준 범주로 지정
- 기본적으로 ABC 순으로 먼저 나오는 것이 기준 범주
- 변경할 수도 있음
- 기준 범주를 제외한 범주들은 범주별로 더미 변수를 하나씩 가짐
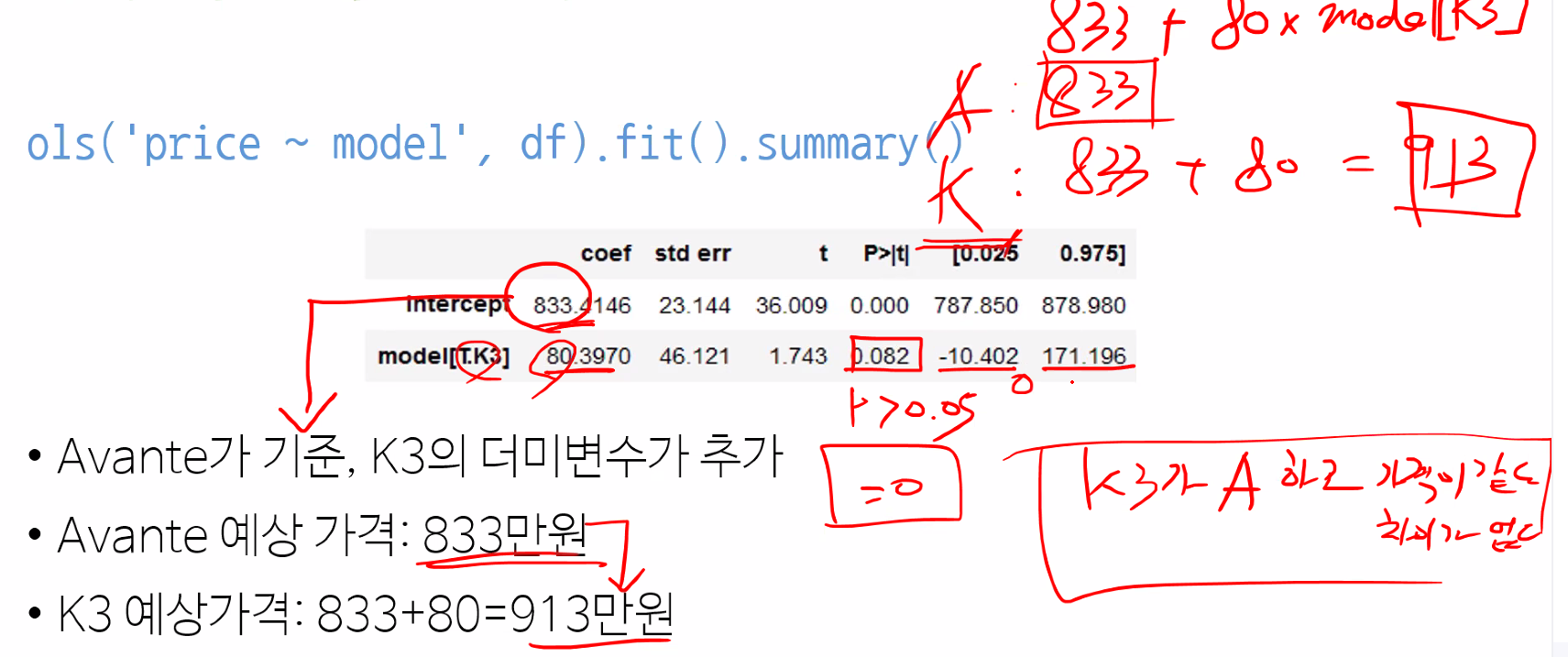
1) 범주가 2개인 경우
| model | model[T.k3] |
|---|---|
| Avante | 0 |
| K3 | 1 |
- ABC 순으로 기준이 잡히기 때문에 Avante가 기준 (기준이 빠지고 나머지가 변수가 됨)
- K3의 더미 변수 추가 (K3일때 1이되고 K3가 아닐 때 0이 됨)
- model[T.k3] = 0 => No, model[T.k3] = 1 => Yes로 이해
2) 범주가 3개인 경우
| TRT | TRT[T.B] | TRT[T.C] |
|---|---|---|
| A | 0 | 0 |
| B | 1 | 0 |
| C | 0 | 1 |
- ABC 순으로 A가 기준
- B와 C의 더미 변수 추가
- 0 = No, 1 = Yes로 이해
dep = pd.read_excel('depression.xlsx')
ols('y ~ TRT', dep).fit().summary()
- A(기준)의 치료효과: 62.3333
- B의 치료효과: 62.3333 - 10.4167 = 51.9166
- C의 치료효과: 62.3333 - 11.0833 = 51.2500
2. 선형 회귀분석과 분산 분석
- 분산 분석은 선형 회귀분석의 특수한 경우
- 선형 회귀 분석의 F 검정과 그 p 값을 보면 분산분석과 같음
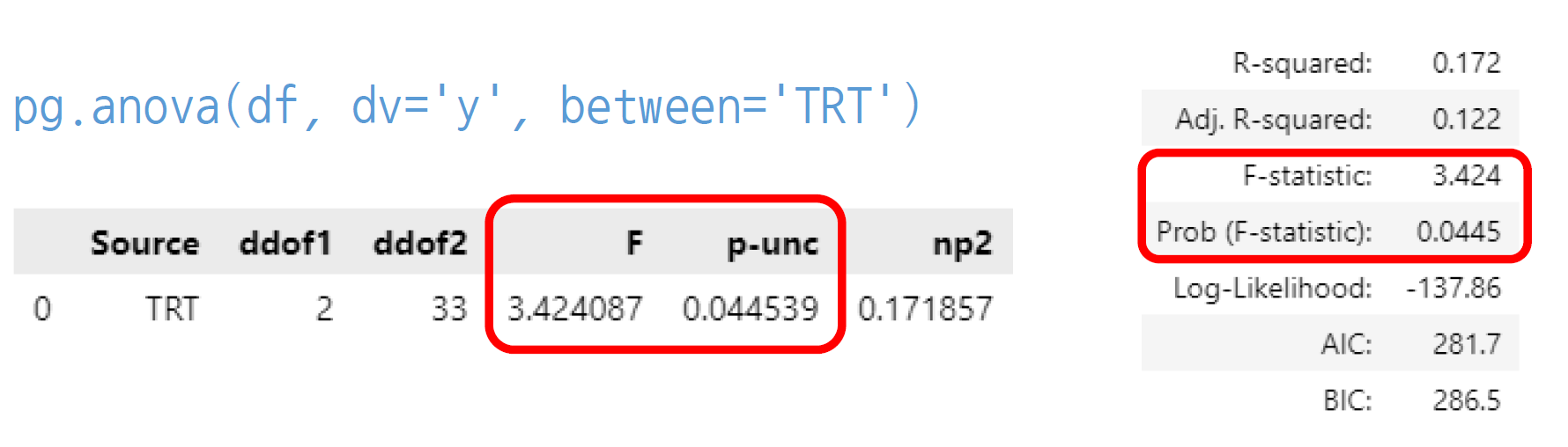
회귀분석: 주목적 -> 에측
공식을 얻는 것
분산분석: 비교
회귀분석 안에 지금까지 배운 통계분석이 다 들어있다고 봐도 된다!
3. 기준 범주 바꾸기
기준 범주는 분석 전에 정해야 한다.
범주가 2개일 때는 기준 범주를 바꾸는 것이 큰 의미가 없다 (방향만 바꾸는 꼴)
1) 범주 목록 보기
- unique 함수를 사용하면 변수에서 범주의 목록을 확인 할 수 있음
- 기준 범주는 더미 변수가 없으므로 범주 목록에서 확인
df.model.unique()
2) Python 관계식에서 더미 변수 다루기
- 변수 model을 명시적으로 범주형 변수로 지정하기(변수가 수치형인 경우에만 필요)
price ~ C(model) - 변수 model의 기준 범주를 K3로 지정하기
price ~ C(x, Treatment("K3"))
=>ols('price ~ C(model, Treatment("K3"))', df).fit().summary()

저 지금 통계 회귀분석에서 너무나 헤매고 있는데, 정리 꼼꼼하게 하신거 너무 대단하셔요! 통계..얼른 나름대로 정복하고 싶어요 ㅋㅋㅋ