상관 분석
다변수 확률변수 간의 상관관계를 숫자로 나타낸 것이 상관계수이며, 이러한 상관계수를 가지고 하는 분석을 상관 분석이라고 한다.
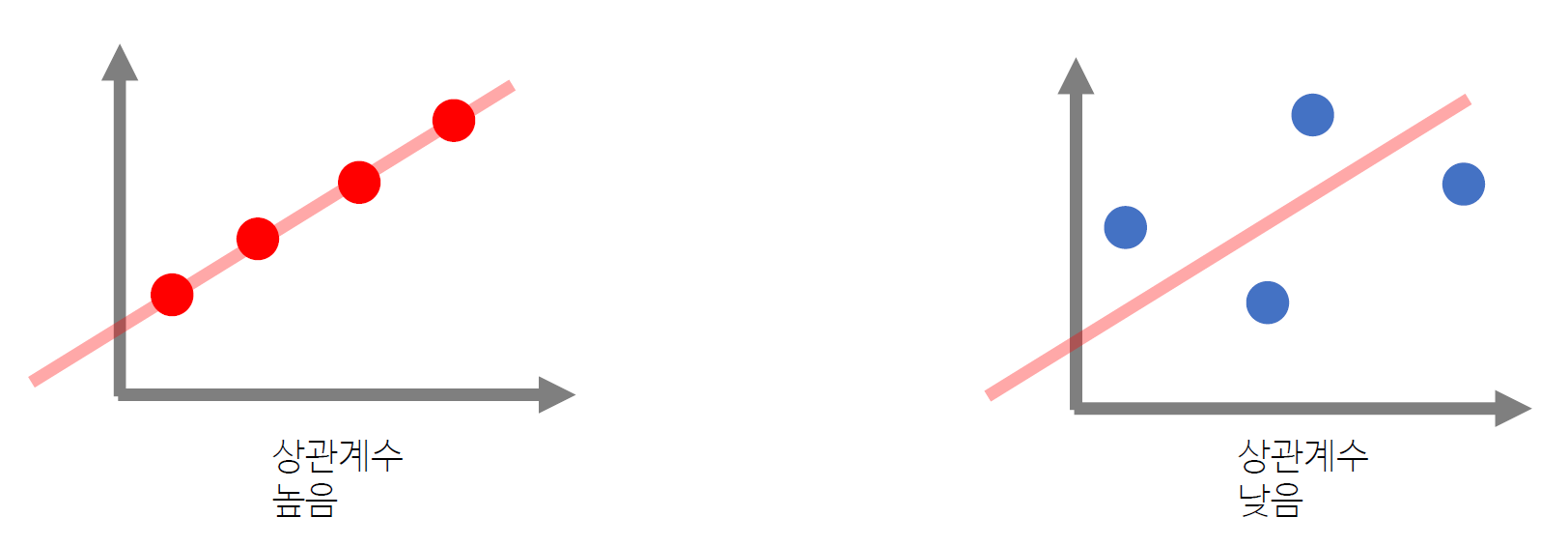
1. 상관계수correlation coefficient
- 두 변수의 연관성을
-1~+1범위의 수치로 나타낸 것 두 변수의연관성을 파악하기 위해 사용- 어휘력과 독해력의 관계 (독해력이 좋은 사람을 뽑고 싶은데, 독해력은 측정하기 어려우니 어휘력 시험을 보자!)
- 주가와 금 가격의 관계
- 엔진 성능과 고객만족도의 관계

상관계수 ρ가-1, 0, 1인 경우를 각각 다음과 같이 부른다.ρ=1: 완전선형 상관관계ρ=0: 무상관 (독립과는 다름)ρ=−1: 완전선형 반상관관계
1) 상관계수의 해석
위의 내용을 조금더 자세하게 풀어쓰면,
- 부호
+:두 변수가 같은 방향으로 변화 (하나가 증가하면 다른 하나도 증가)-: 두 변수가 반대 방향으로 변화 (하나가 증가하면 다른 하나는 감소)
- 크기
0:두 변수가 독립 , 한 변수의 변화로 다른 변수의 변화를 예측하지 못함1: 한 변수의 변화와 다른 변수의 변화가 정확히 일치
2) 기울기와 상관계수
흔히 상관계수가 기울기와 관련있다고 착각하곤 하는데, 상관계수와 기울기는 다른 개념이다!
(1) 기울기

- 기울기는
𝑦 = 𝑎𝑥 + 𝑏에서𝑎- 𝑥가 1 만큼 변할 때 𝑦의 변화량을 나타냄
- 기울기가 클 수록 𝑦가 크게 변함
(2) 상관계수
(3) 기울기 vs. 상관계수
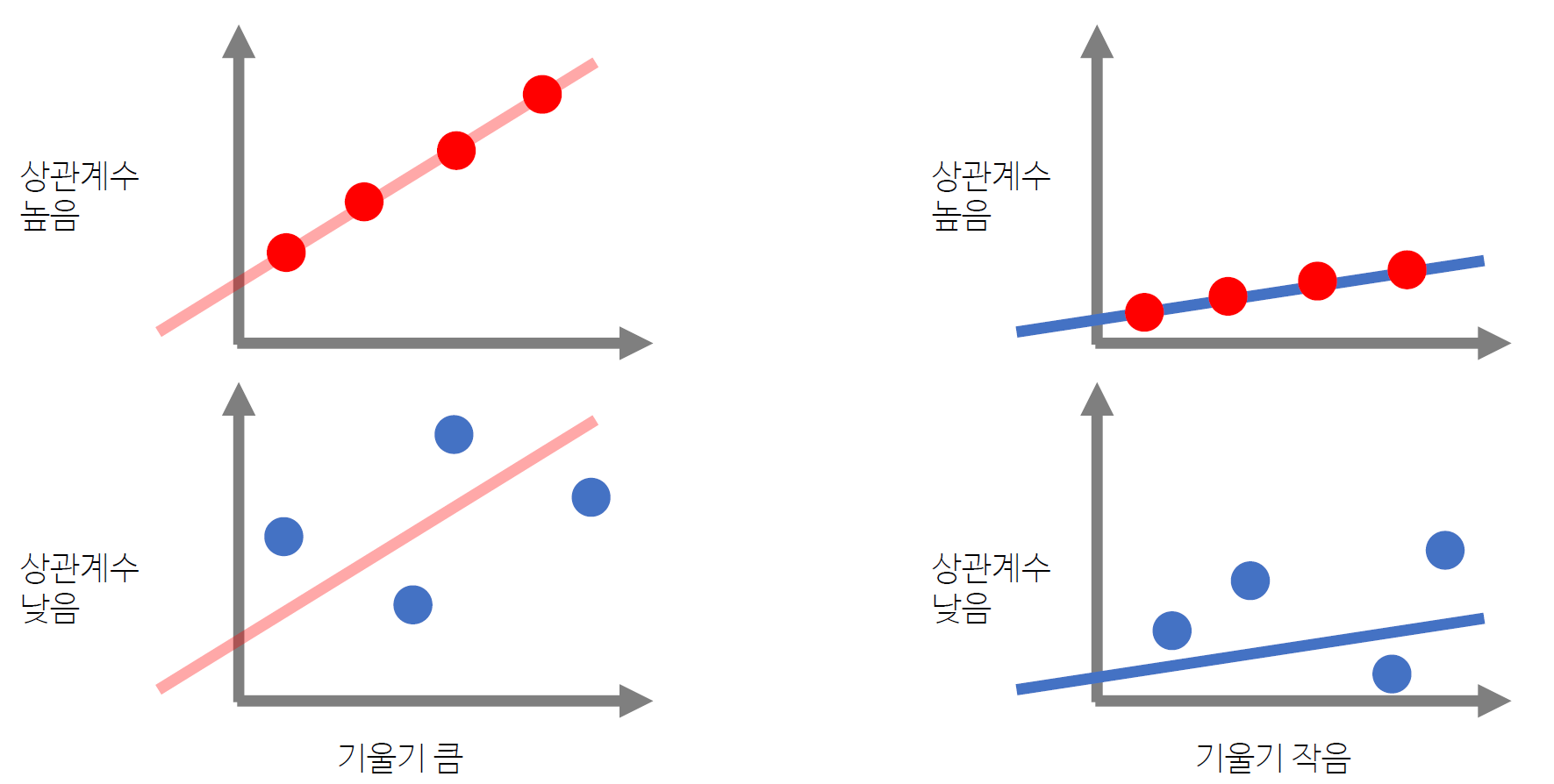
- 기울기는 직선이 가파르게 올라가느냐, 완만하게 올라가느냐 같은 개념에 대한 것이다.
- 상관계수는 이 직선이 가파르게 올라가는지, 완만하게 올라가는지는 신경 쓰지 않는다.
- 즉, 상관계수와 기울기는 다른 개념이다!
2. 공분산
공분산은 두 변수가 얼마나 같이 변하느냐(분산은 한 변수가 얼마나 변하냐)에 대한 것!!!! 일단 그냥 외우자....!
- X의 편차와 Y 의 편차를 곱한 것의 평균(X=Y 이면 분산과 같음)
- 왜
N이 아니라N-1로 나눠주는 걸까...? 모집단이 아니라 표본의 편차이기 때문에 보정을 위해서라는데, 아직 명확하게 이해되지는 않는다.
- 왜
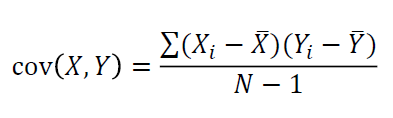
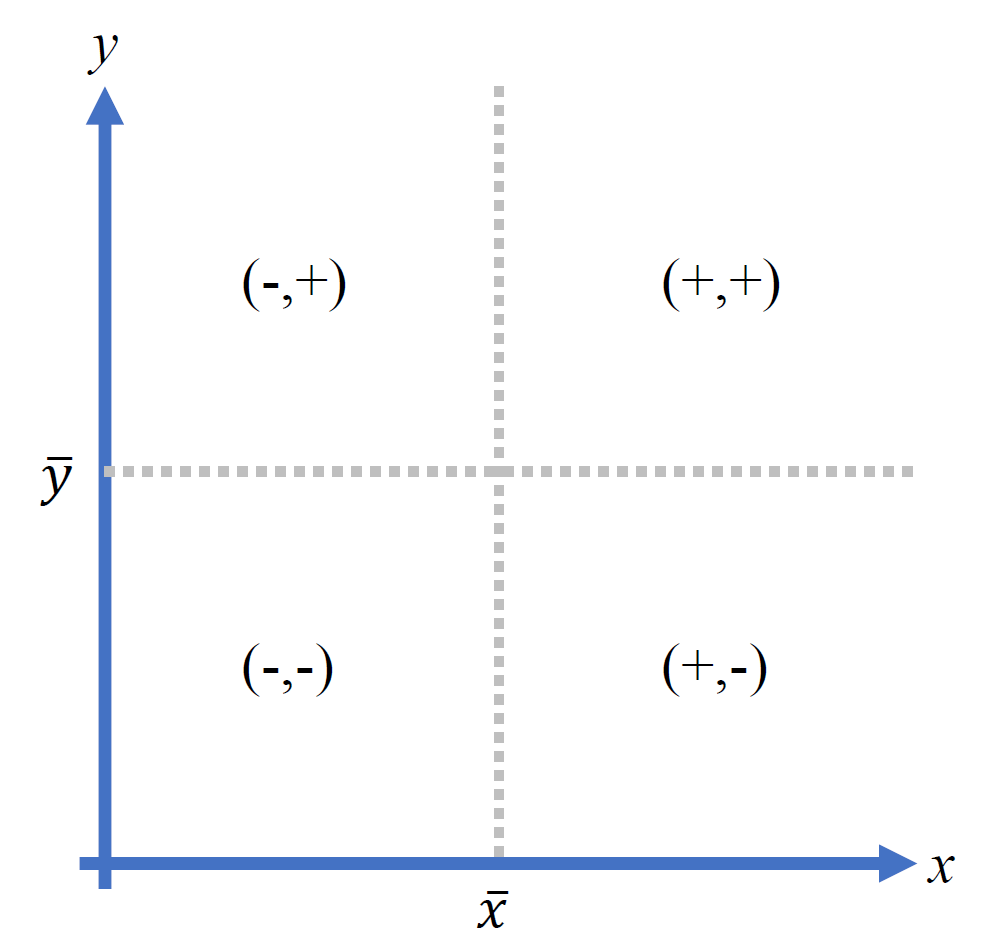
편차(deviation)는 관측값과 평균의 차이
- 우상향하는 추세인 경우
+로 커짐 - 우하향하는 추세인 경우
-로 커짐
3. 피어슨 적률 상관계수
- 가장 대표적인 상관계수
- 선형적인 상관계수를 측정
- 공분산을 두 변수의 표준편차로 나눔 ->
1~+1범위- 공분산을 파악하기 쉽게
-1~+1로 범위를 제조정한 것
- 공분산을 파악하기 쉽게
1) 피어슨 상관계수와 비단조적 관계
- 피어슨 상관계수는 우상향 또는 우하향 하는
단조적관계를 표현 - 복잡한 비단조적 관계는 잘 나타내지 못함
- 상관계수가 낮다고 해서 관계가 없는 것은 아님
단조적: 매끄럽게 올라가거나 내려간다는 의미! 희한하고 복잡한 모양이 아니라, 올라갈거면 그냥 매끄럽게 올라가고 내려갈거면 그냥 매끄럽게 내려가고~~

- 복잡하고 희안한 관계들....
4. 상관 분석 가설검정 순서도
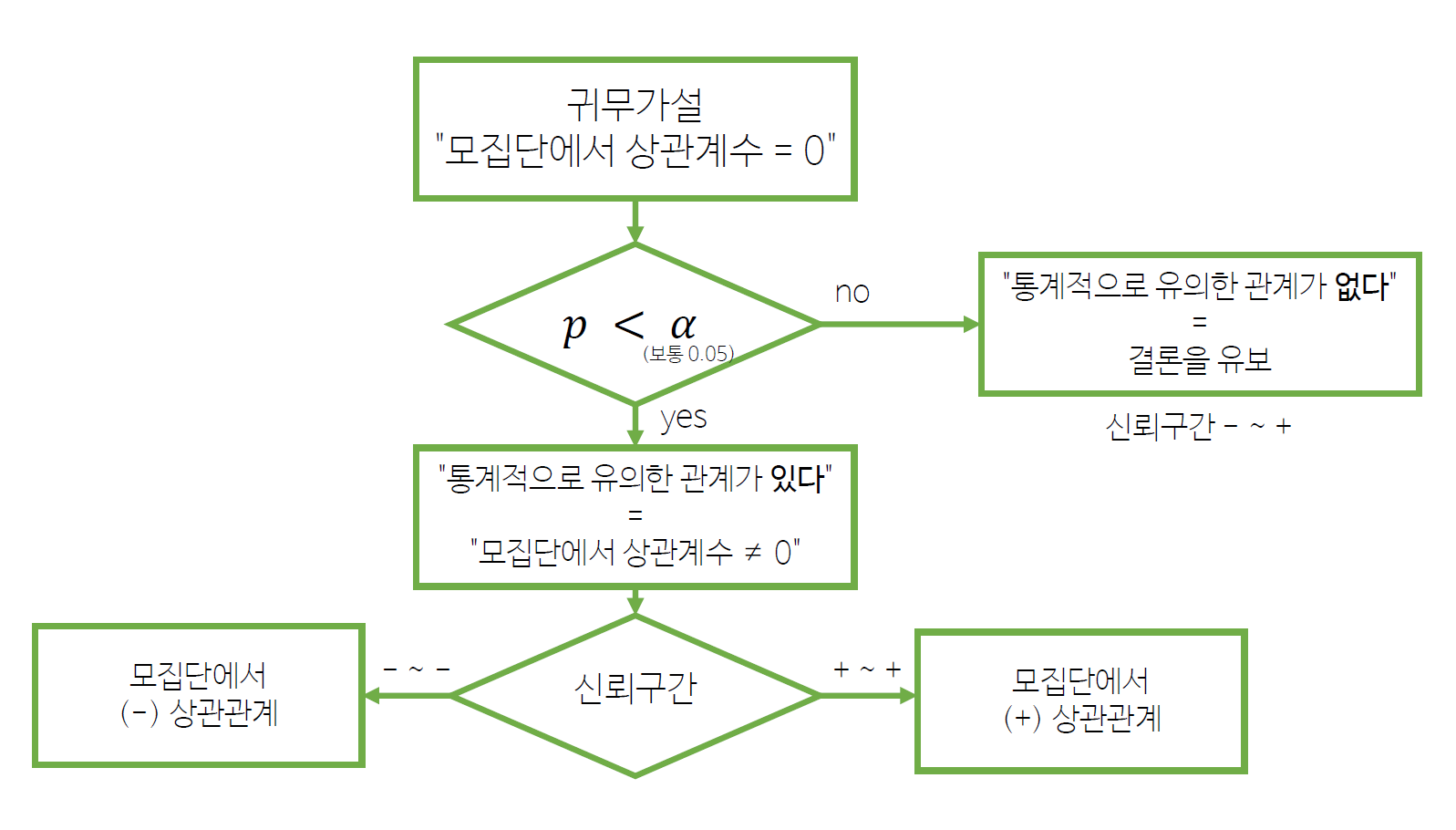
1) 상관계수의 신뢰구간
+ ~ +: 모집단에서 두 변수의 관계가+- ~ +: 모집단에서 두 변수의 관계는-, 0, +모두 가능- ~ -: 모집단에서 두 변수의 관계가-
2) 상관계수의 크기 해석
- 상관계수의 크기에 대해서는 몇 가지 권장 기준이 있으나(예: Cohen, 1988), 엄
밀한 근거에 바탕을 둔 것은 아님
- 낮음 ~0.1
- 중간 0.1 ~ 0.5
- 높음 0.5 ~ - 실제 의사결정에서는 상대적으로 비교하는 것이 바람직
- 예를 들어 상관계수 0.2인 요소 A와 0.3 인 요소 B가 있고 예산상 한 가지 요소만
고려할 수 있다면 요소 B를 고려
5. 피어슨 상관계수를 활용한 Python 상관 분석 실습
pg.corr()사용method옵션의 기본값이피어슨이다
1) 중고차 데이터 - 가격과 운전 거리의 상관 분석
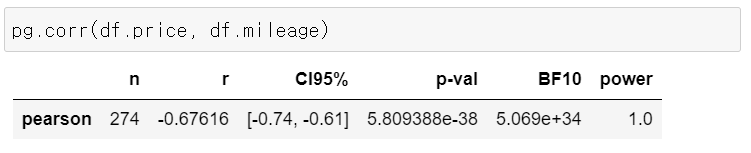
- 상관계수(r) : -0.67616
- 상관계수의 신뢰구간(CI95%) : -0.74, -0.61
- 평균의 신뢰구간과 달리 좌우 대칭이 아니다
- 귀무가설 : 상관계수 = 0
- p-val = 5.809388e-38 < 0.05
- 귀무가설 기각 -> 통계적으로 유의한 상관관계가 있다
Q. 평균의 신뢰구간과 달리 좌우 대칭이 아닌 이유는?
A. 평균은 범위가 -∞ ~ +∞, 상관계수는 범위가 -1 ~ +1로 막혀있기 때문에 한 쪽으로 치우치게 된다.
즉, 무한대로 가는 값을 -1과 +1 사이에 억지로 끼워 맞췄기 때문에 상관계수 신뢰구간은 대칭일 수 없는 것!
(상관계수가 0일때는 대칭일 수 있는데, 상관계수가 +로 가면 위쪽이 커지고, -로 가면 아래쪽이 짧아지며(?) 약간씩 비대칭이 된다고.... 어렵다...)
2) 중고차 데이터 - 운전 거리와 차 사고의 상관 분석

- 상관계수: 0.00795 (아주 작음)
- 상관계수의 신뢰구간: -0.11 ~ 0.13
- 이 값을 통해 2가지 사실을 알 수 있다
- 첫째: 어쨌든 작구나..(어떻게 해도 거의 0에 가까움)
- 둘째: -, 0, + 모두 가능하겠구나...(어떤 방향성있는 결론을 낼 수 없음)
- p-value = 0.89 > 0.05
- 귀무가설(상관계수 = 0)을 기각할 수 없음
- 통계적으로 유의한 상관관계가 없다 (둘째의 어떤 방향성 있는 결론을 낼 수 없는 것과 비슷한 의미인 것)
6. 스피어만 상관계수와 켄달 상관계수
피어슨 상관계수는 곡선으로 올라가거나 내려가면 상관계수가 떨어진다.
선형이 아니면 다 예외적인 상황으로 보기 때문에, 상관계수가 낮아도 다른 패턴이 나타날 수 있다(관계가 있을 수 있음).
스피어만 상관계수와 켄달 상관계수는 피어스 상관계수의 이러한 단점을 보완하기 위해 만들어졌다.
(그런데 두 변수의 관계가 비선형적인 것은 괜찮음, 근데 단조적이지 않으면 안돼!!)
1) 스피어만 상관계수
- 실제 변수값 대신 그 서열을 사용하여 피어슨 상관계수를 계산
- 한 변수의 서열이 높아지면 다른 변수의 서열도 높아지는지를 나타냄
- 두 변수의 관계가 비선형적이나 단조적일 때 사용
pg.corr함수에 옵션method='spearman’으로 사용
- 변수값을 줄 세워 등수를 매겨 어느 정도 곡선이어도 패턴을 파악해준다 . 단, 등수가 바뀌게 되는 경우(곡선선이 방향을 바꾸면) 안된다!
2) 켄달 상관계수
- 모든 사례를 짝지어 X의 대소관계와 Y의 대소관계가 일치하는지 확인
- 데이터가 작을 때 사용
pg.corr함수에 옵션method='kendall’로 사용
- 모든 변수를 짝지어 올라가는 관계와 내려가는 관계를 계산(예를 들어 올라가는 관계면 +1, 내려가는 관계면 -1, 이런 식으로 올라가는 관계가 많은지 내려가는 관계갸 많은지 확인)
- 휘어진 그래프를 지수화 시키기 위해 만들어졌다.
- 모든 데이터의 짝지어 계산하기 때문에 데이터가 많으면 계산량이 너무 많다!!! 그래서 데이터가 적고 휘어져서 올라갈 경우(
비선형) 사용한다.
7. 스피어만, 켄달 상관계수를 활용한 Python 상관 분석 실습
- 중고차 데이터로 차 사고와 운전 거리의 상관 분석
1) 스피어만 상관계수 활용

- 상관계수: 0.169259
- 신뢰구간: 0.05, 0.28
- 방향성이 + 방향이군
- P-value = 0.004966 < 0.05
- 귀무가설(상관계수 = 0)을 기각하여 통계적으로 유의한 상관관계가 있다
2) 켄달 상관계수 활용
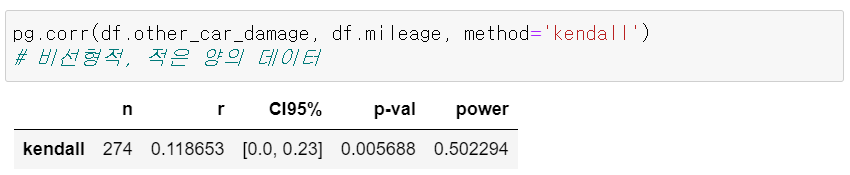
- 상관계수: 0.118653
- 신뢰구간: 0.0, 0.23
- 방향성이 + 방향이군
- P-value = 0.005688 < 0.05
- 귀무가설(상관계수 = 0)을 기각하여 통계적으로 유의한 상관관계가 있다
정리!
- 피어슨 적률 상관계수 : 선형적,
pg.corr()사용- 스피어만 상관계수 : 비선형적, 특이사례에 강함,
pg.corr()함수에 옵션method='spearman’- 켄달 상관계수 : 비선형적, 작은 데이터에 유용,
pg.corr()함수에 옵션method='kendall’
8. 상관과 인과 correlation and causation
- 두 변수의 상관관계는 인과관계를 담보하지 않음
- 상관관계 : 데이터에 관련이 있다!
- 인과관계 : 원인과 결과~~
- 상관관계가 있다고 반드시 인과관계가 있는 것은 아님!!!
- 제3변인의 존재
- 이질적인 집단들의 합 (심슨의 역설)
- 극단치(outliers)
1) 제3변인
- 도시 내 범죄 발생 건수와 종교 시설의 수는 양의 상관관계가 있음
- 범죄가 많아서 종교에 의존하는가? 또는 종교가 범죄를 부추기는가?
- 사실은 인구가 많아지면 범죄도 늘고, 종교 시설도 많아짐
사교육을 많이하면 성적이 높아진다는 것도 비슷한 케이크. 그런데 양쪽에 영향을 주는 변수는 다양하다. 예를 들면 부모의 학력, 소득 등...
2) 심슨의 역설
- 각 집단별 상관관계와 전체 총합의 상관관계는 다를 수 있음
- 상관 분석 결과가 예상과 다를 경우, 이질적인 하위집단들이 존재하는지 살펴 봐야 할 수도 있음
- 심슨의 역설과 비슷한 것 : 벅슨의 역설 (잘생긴 사람은 성격이 안 좋다? -> 못생긴 사람은 안 만남)
예를 들어 입학성적이 높은 학생이 들어가는 학과는 교수님이 점수를 짜게 준다, 그보다 입학성적이 낮은 과는 교수님들이 성적을 높게 준다. 학교 전체를 봤을 땐 입학성적이 높은 학생들이 학점을 낮게 받았다고 볼 수 있겠으나, 입학성적이 높은 것과 학점은 연관이 없는 것!
3) 극단치 outlier
- 자료 내에 극단치가 있을 때
- 존재하지 않는 상관관계가 나타나는 경우
- 존재하는 상관관계가 포착되지 못하는 경우
