
지표
지표의 속성
지표를 속성에 따라 분류하면 스톡(Stock) 형태와 플로(Flow) 형태로 구분할 수 있다.
스톡은 특정 시점의 스냅숏(snapshot)에 해당하는 지표로 시작과 끝이라는 개념 없이 특정한 찰나(한 시점)에 관찰할 수 있는 누적된 값이다. 일반적으로 사용하는 스톡 지표에는 누적 가입자 수, 누적 거래액, 누적 다운로드 수 등이 있다.
플로는 스톡과 반대로 시작과 끝이라는 개념이 존재하며, 일정한 시간 동안의 변화량을 나타내는 지표다. 대표적인 플로 지표에는 1월 1일 가입자 수(1월 1일 0시 ~ 1월 1일 24시라는 범위), 월 매출, 일 평균 메세지 수 등이 있다.
일반적으로는 지표의 변화 방향이나 추이, 속도에 대해 더 많은 정보를 줄 수 있는 플로 지표가 스톡 지표에 비해 핵심 지표로 쓰인다. 단순 누적량을 보여준다는 측면에서 스톡 지표는 허무 지표에 가깝다고 볼 수 있지만 누적량 자체가 유의미한 자산으로 활용된다면 이 경우에는 스톡 지표가 핵심 지표로 활용되기도 한다. (멜론의 누적 보유곡 수 혹은 링크드인의 누적 프로필 수 등이 있다)
따라서 핵심 지표를 선정하거나 그로스 실험의 성과를 측정할 때는 목표 지표가 스톡 형태인지 플로 형태인지 정확히 구분해서 활용해야 한다.
명확한 지표 정의하기
또한 지표를 명확하게 정의할 필요가 있다. 예를 들어 MAU(Monthly Acive User)를 확인한다고 가정해보자. MAU의 개념적 정의는 명확하지만 구체적인 조작적 정의가 명확하지 않다면 어떤 기준으로 MAU를 구해야 할까? 한 달간 우리 서비스에 로그인한 사용자라고 정의하면 될까? 그러면 방문한 사용자는 포함되지 않는 걸까? 방문한 사용자 모두를 정의해야 할까? 그렇다면 앱과 웹 모두 방문했다면 이는 1명으로 세어야 할까? 한 사람이 하루에 두 번 방문한다면 이는 1명으로 세어야 할까?
이 부분을 보고 명확한 지표를 정의하는 것이 정말 중요하다고 느꼈다. 같은 서비스를 이용하는 사람들 사이에서도 같은 지표를 서로 다르게 생각하는 경우가 매우 빈번하게 발생해 구성원들이 서로 다른 기준과 의미로 이해한 채 커뮤니케이션을 한다는 문제가 있다. 실제로 서비스마다 중요하게 생각하는 부분이 다를 수 있고 그에 맞는 더 적합한 측정 기준이 있을 수 있기에 정답은 없다. 가장 중요한 것은 원칙을 세우는 일이다.
MAU나 결제 전환율처럼 상대적으로 명확해 보이는 지표들도 미스커뮤니케이션 되는 경우가 많다는 것을 감안하면 자체적으로 만들어서 관리하는 지표에는 조작적 정의가 잘 되어있지 않을 가능성이 훨씬 크다. 지표에 대한 조작적 정의를 하기 위해서는 그 기준이나 원칙을 어떻게 세울 것인가에 대해 답할 수 있어야 한다. 이 과정에서 서로 생각하는 기준을 공유하고, 질문하고, 답변하며 지표에 대해 점점 구체화할 수 있고, 모두가 공감하는 기준을 세울 수 있다. 모호한 지표는 모호한 액션을 이끌 수밖에 없다.
허무 지표
좋은 지표의 조건 중 하나는 그 지표를 바탕으로 행동할 수 있어야 한다는 것이다. 하지만 행동을 이끌어내지 못하는 의미 없는 지표가 있는데 이를 허무 지표 혹은 허상 지표라고 한다.
스톡 지표의 경우 특별한 맥락에서 사용되는 일부를 제외하면 허무 지표인 경우가 많다. ‘누적 다운로드’, ‘누적 방문자’, ‘페이지 뷰’ 등 시간이 지나면 자연스레 높아질 수밖에 없는 지표들로 서비스가 올바른 방향으로 가고 있는지에 대한 정보를 거의 주지 못한다.
전체 관점에서의 최적화
지표를 활용할 때 주의해야 하는 점은 지표를 개선하기 위한 행동이 전체 관점에서 이루어져야 한다는 점이다. 특히 팀 간 업무 영역이 명확하게 구분된 회사에서 각자의 영역만 신경 쓰는 경우 부분 최적화 지표는 좋아지지만 전체 최적화에는 나쁜 영향을 주는 문제가 종종 발생한다.
한 가지 예시로, 텔레그램 알림 메시지가 있다. 텔레그램 메신저는 주소록에 있는 친구가 텔레그램에 가입할 때마다 대화방으로 알림 메시지가 전송된다. 수십 명의 친구들이 가입할 때마다 매번 똑같은 알림 메시지가 전송되는데 사용자 입장에서는 이 기능이 너무 불편해 나중에는 텔레그램을 삭제하는 데 크게 영향을 미쳤다.
이처럼 간단한 넛지를 이용한 활성화 전략은 대부분 DAU(Daily Active User)를 증가시키는 데는 무조건 도움이 된다. 하지만 이렇게 DAU가 증가하는 것을 긍정적으로 볼 수 있을까? 전체 최적화 관점에서 고민해봐야 할 질문이다.
심슨 패러독스
심슨 패러독스란 쪼개진 데이터에서 성립하는 관게가 합쳐진 데이터에서는 반대로 나타나는 현상을 말한다. 실제로 데이터를 통해 유의미한 인사이트를 찾아내기 위해서는 데이터를 쪼개서 살펴봐야 한다는 공통점이 있다. 전체 데이터에서 잘 드러나지 않는 특성들이 쪼개진 상태에서 명확히 드러나는 경우가 많기 때문에 데이터를 어떤 식으로 가공하느냐에 따라 얻는 인사이트가 완전히 달라질 수 있기 때문이다.
심슨 패러독스의 대표적인 사례 중 하나는 UC 버클리의 1973년 대학원 입시와 관련된 해프닝이다. 1973년, UC 버클리의 입시 결과를 놓고 소송이 제기됐다. 주장은 대학 측이 합격자 선발 과정에서 여학생들을 부당하게 차별했다는 것이다.
| 지원자 수 | 합격자 수 | 합격률 | |
|---|---|---|---|
| 남학생 | 8,442 | 3,714 | 44% |
| 여학생 | 4,321 | 1,512 | 35% |
실제로 이 데이터를 기반으로 카이제곱 검증을 하면 성별에 따른 합격률이 유의미한 차이가 있다는 결론이 나온다. 하지만 이를 학과별로 쪼개서 보면 전혀 다른 패턴이 발견된다.
[모집 인원이 많은 주요 학과에 대한 입시 결과]
| 남성 | 여성 | ||
|---|---|---|---|
| 학과 | 입학률 | ||
| A | 62% | 82% | |
| B | 63% | 66% | |
| C | 37% | 34% | |
| D | 33% | 35% | |
| E | 28% | 24% | |
| F | 6% | 7% | |
| … | … | … | |
| 44% | 30% |
전체 85개 학과 중 남학생의 합격률이 통계적으로 유의미하게 높은 학과는 4개에 불과했으며 오히려 학과별 합격률은 여학생이 더 높았다. 개별적으로 여학생들의 합격률이 더 높은 학과가 많은데도 6개 학과의 결과를 합산해서 보면 44 : 30으로 여학생의 합격률이 현저히 낮은 것을 볼 수 있다.
이러한 현상이 발생하는 이유는 경쟁률이 높고 합격률이 낮은 학과(C, E)에 여학생들이 상대적으로 많이 지원했기 때문이다. 학과별로 합격률이 일정하지 않은 상황에서 특정 학과의 쏠림 현상이 발생하는 경우 이처럼 전체 결과의 경향성이 부분 결과의 경향성과 일치하지 않을 수 있다.
서비스 데이터를 분석할 대도 이처럼 전체 데이터만 놓고 비교하는 경우 유의미한 결과를 놓치거나 데이터를 완전히 잘못 해석하는 사례가 발생할 수 있다. 실제로 마이리얼트립에서 경험했던 심슨 패러독스의 사례가 있다.
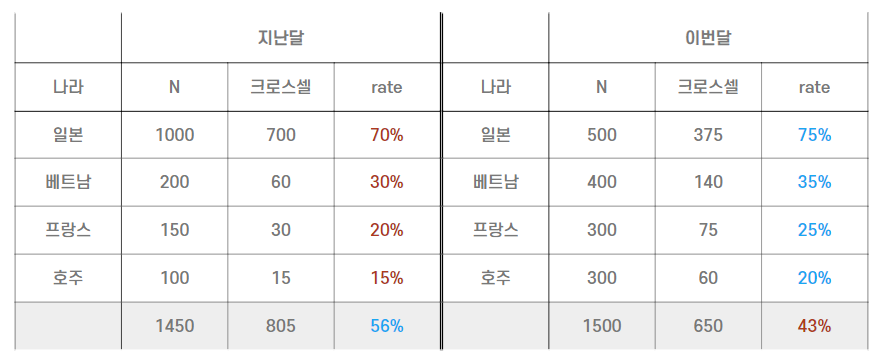
이처럼 국가별 크로스셀 비율은 꾸준히 증가하는데 전체 크로스셀 비율은 낮아진 것이다. 그 이유는 크로스셀 비율이 높았던 일본 여행이 전체에서 차지하는 비중이 줄어들면서 전체 국가를 기준으로 한 크로스셀 비율이 전월 대비 하락한 것이었다. 만약 데이터를 쪼개서 보겠다는 생각을 하지 못햇다면 원인을 찾는 데 훨씬 오랜 시간이 걸렸을 것이다.
대푯값 사용 주의점
가장 일반적으로 활용되는 대푯값은 평균값이지만 과연 모든 경우에 최선이라고 할 수 있을까?
데이터의 분포가 매우 극단적인 경우 평균값은 대푯값으로 적절하지 않다. 이 경우 평균값은 최빈값도, 이상값도 대표하지 못하는 경우가 많기에 데이터가 정규분포가 아니거나 이상치가 있는 경우 중앙값이나 최빈값과 같은 대푯값을 사용한다. 중앙값은 평균보다 이상치에 민감하지 않다는 특징이 있으므로 데이터 세트에 이상치가 있거나 분포를 알 수 없는 경우에 사용하는 것을 고려할 필요가 있다.
생존자 편향(Survivorship bias) 피하기
데이터를 분석하기 전 수집된 데이터가 분석에 적합한 데이터인지 확인하는 것이 꼭 필요하다. ‘Garbage In Garbage Out’이라는 말이 있는데, 말 그대로 잘못된 데이터로 분석하면 잘못된 결과가 나온다는 의미다. 여기에는 약간의 부주의 때문에 잘못된 데이터를 활용하는 경우도 포함된다. 그 중 대표적인 사례가 생존자 편향(Survivorship bias)이다. 생존자 편향에 대한 유명한 사례 중 하나는 제 2차 세계 대전 당시 미 해군에서 있엇던 전투기 장갑 보강에 관련된 이야기다.
당시 미군은 전투기의 생존율을 높이기 위해 귀환한 전투기들이 어디에 적탄을 맞았는지 조사한 후 피격 부위에 장갑을 보완하는 프로젝트를 진행하고 있었다. 조사 결과 동체와 날개 부분에 피탄 흔적이 집중되어 있었고, 어느 정도의 두께로 이를 보강해야 하는지에 대한 자문을 요청했다. 하지만 이 요청을 받은 통계학자는 피탄 흔적이 많은 동체와 날개가 아닌 피탄 흔적이 상대적으로 적은 엔진과 조종석을 집중적으로 보강해야 한다는 의견을 주장했다. ‘귀환에 성공한’ 전투기가 아닌 ‘귀환에 성공하지 못 한’ 전투기에 집중해야 한다는 것이다. 장갑 보완 프로젝트는 귀환에 성공한 전투기의 데이터만 수집해서 분석했기 때문에 자칫하면 전혀 잘못된 결론을 낼 수 있었던 사례 중 하나다.
분석 목표에 맞는 데이터를 신중하게 수집하고 가공하는 단계가 잘 진행되지 않으면 그 다음에 진행하는 어떤 고도화된 알고리즘이나 분석 방법도 의미가 없다는 점을 반드시 기억해야 한다.
