캐시(Cache)란?
- 자주 사용하는 데이터나 값을 미리 복사해 놓는 임시 장소.
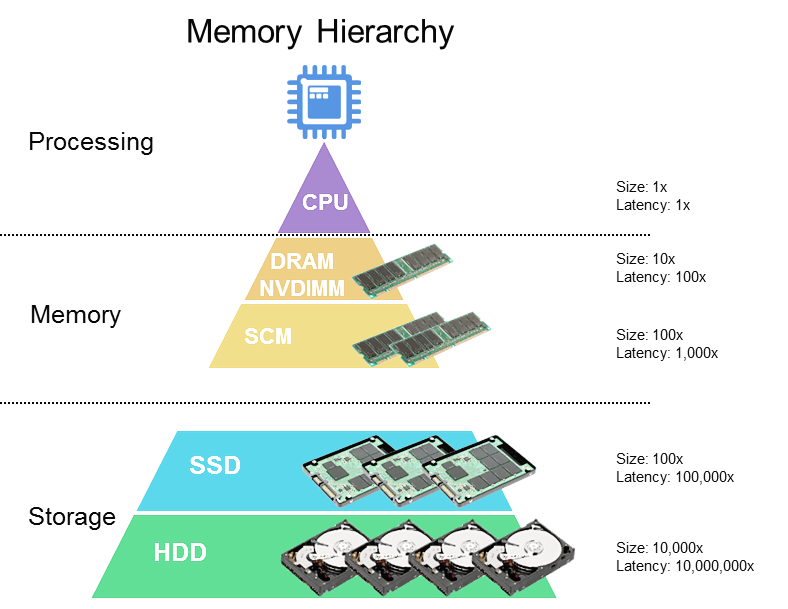
아래와 같은 저장공간 계층 구조에서 확인할 수 있듯이, 캐시는 저장 공간이 작고 비용이 비싼 대신 빠른 성능을 제공한다.

캐시를 사용하면 좋은 경우
- 접근 시간에 비해 원래 데이터를 접근하는 시간이 오래 걸리는 경우(서버의 균일한 API 데이터)
- 반복적으로 동일한 결과를 돌려주는 경우(이미지나 썸네일 등)
캐시의 등장배경
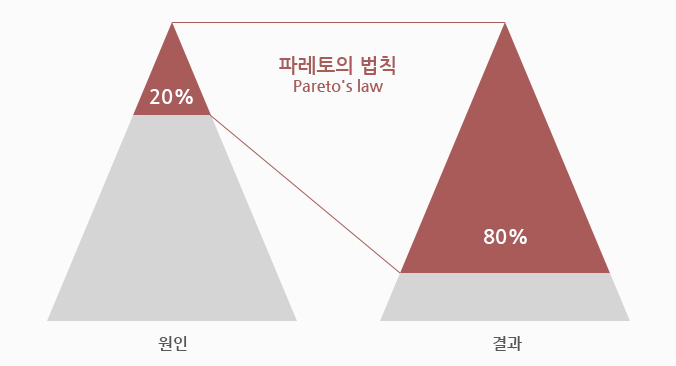
- 하단의 파레토 법칙(80퍼센트의 결과는 20퍼센트의 원인으로 인해 발생)과 같이, 프로그래밍에서도 자주 그리고 반복해서 사용하게 되는 데이터들이 있다.
- 이러한 데이터를 빠르게 접근하여 사용할 수 있으면 프로그램의 성능도 향상될 것이다. 이렇게 탄생한 것이 캐시(cache) 이다.
- 모든 결과를 캐싱할 필요는 없으며, 우리는 서비스를 할 때 많이 사용되는 20%를 캐싱한다면 전체적으로 영향을 주어 효율을 극대화 할 수 있다.
어떤 정보를 캐시에 담아야 할까?
- 모든 데이터를 캐시에 담기에는 캐시라는 저장 공간은 작다. 그렇기 때문에 많이 사용되는 소수의 데이터를 선별해야 하는데, 이때 사용되는 것이 지역성이다.

시간적 지역성
- 특정 데이터가 한번 접근되었을 경우, 가까운 미래에 또 한번 데이터에 접근할 가능성이 높은 것을 말한다. 메모리 상의 같은 주소에 여러 차례 쓰기를 수행할 경우 상대적으로 작은 크기의 캐시를 사용해도 효율성을 꾀할 수 있다.
공간적 지역성
- 특정 데이터와 가까운 주소가 순서대로 접근되었을 경우이다. CPU 캐시나 디스크 캐시의 경우 한 메모리 주소에 접근할 때 그 주소뿐 아니라 해당 블록을 전부 캐시에 가져오게 된다. 이 때 메모리 주소를 오름차순이나 내림차순으로 접근한다면, 캐시에 이미 저장된 같은 블록의 데이터를 접근하게 되므로 캐시의 효율성이 크게 향상된다.
순차 지역성
- 공간 지역성과 함께 설명되는데, 데이터가 순차적으로 엑세스되는 경향을 보이며 프로그램 내의 명령어가 순차적으로 구성된다.
캐시의 사용 구조
- Client로 부터 요청을 받는다.
- Cache와 작업을 한다.
- 실제 DB와 작업한다.
- 다시 Cache와 작업한다.
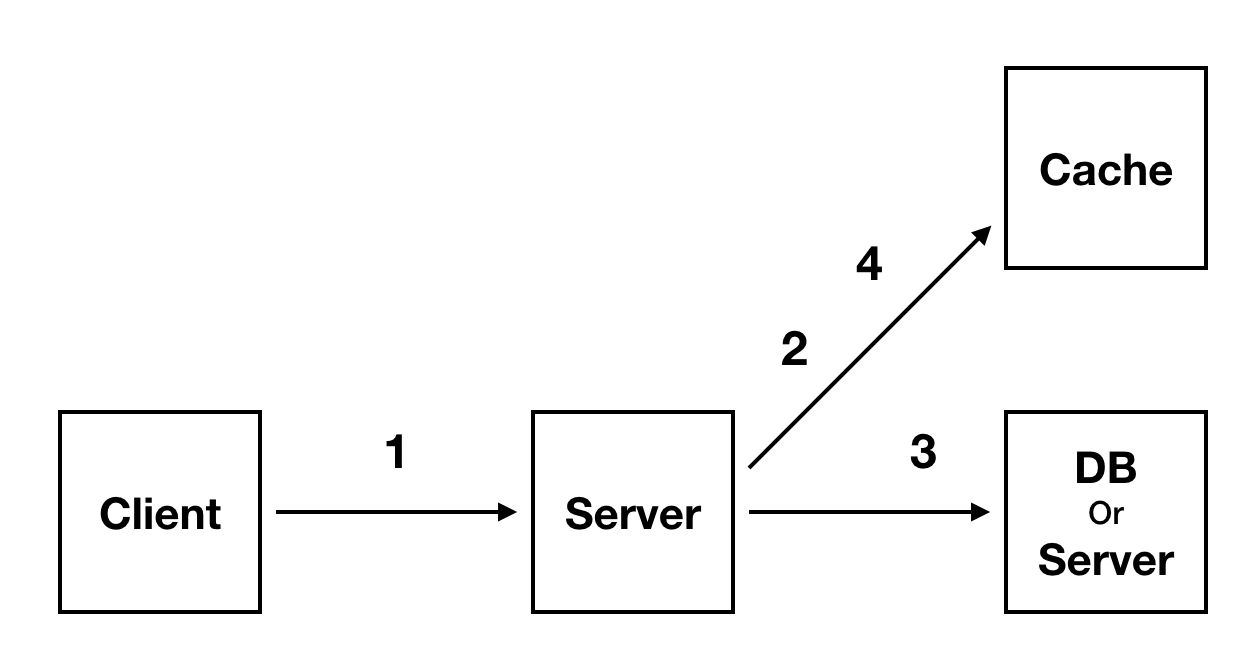
캐시의 동작 방식
- 데이터를 달라는 요청이 오면 먼저 캐시에서 데이터를 찾는다.
- 캐시가 없거나(cache miss) 너무 오래되면(expiration) 원본 데이터가 저장된 곳에서 데이터를 조회한다. 이때 캐시에도 데이터를 복사하거나 갱신한다.
- 캐시에 데이터가 있으면(cache hit) 캐시의 저장된 데이터를 제공한다.
- 캐시는 용량이 작은 공간으로 사용하지 않거나 오래된 데이터는 삭제한다.(eviction)
왜 20%만 캐싱할까?
- 컴퓨터를 구성하는 메모리 저장공간은 속도가 빠를 수록 용량이 작고 가격이 높다. 그래서 가격때문에 캐시에 저장할 적은 양의 정보를 잘 선택하는 것이 비용도 절약하고 효율도 높이는 방법이다.
출처: https://mangkyu.tistory.com/69
https://zangzangs.tistory.com/110
