코랩에서 실행합니다.
Speech to text
오디오파일을 텍스트로 변환해봅니다.
transcription사용
OpenAI 모듈설치
!pip install openaiopenai에 api키 연결
import openai
import os
os.environ["OPENAI_API_KEY"] = "나의~~생성~~api키~~~~" # 생성한 api 키
# 또는 API키 비공개로 하는법 (위에 직접적으로 쓰는 한 줄 대신)
# with open('api키를텍스트파일로저장.txt', 'r') as file:
# os.environ["OPENAI_API_KEY"] = file.read().strip()
openai.api_key = os.getenv("OPENAI_API_KEY")음성을 읽어주는 모델 세팅
client = OpenAI()
# 또는 client = openai.OpenAI()
audio_file = open("audio_test.mp3", "rb")
transcription = client.audio.transcriptions.create( # 여기에 아래 모델을 불러와서 저장해라
model="whisper-1", # 음성파일을 읽는 모델
file=audio_file
)
print("Done")음성파일은 유투브에서 대충 2분짜리 영상을 mp3로 변환하여 저장해줍니다.
(1) 유투브에서 영상 찾기
(2) mp3파일로 변환해주는 사이트
(3) 코랩 drive에 저장하기
음성파일 텍스트로 불러오기
print(transcription.text)
print("")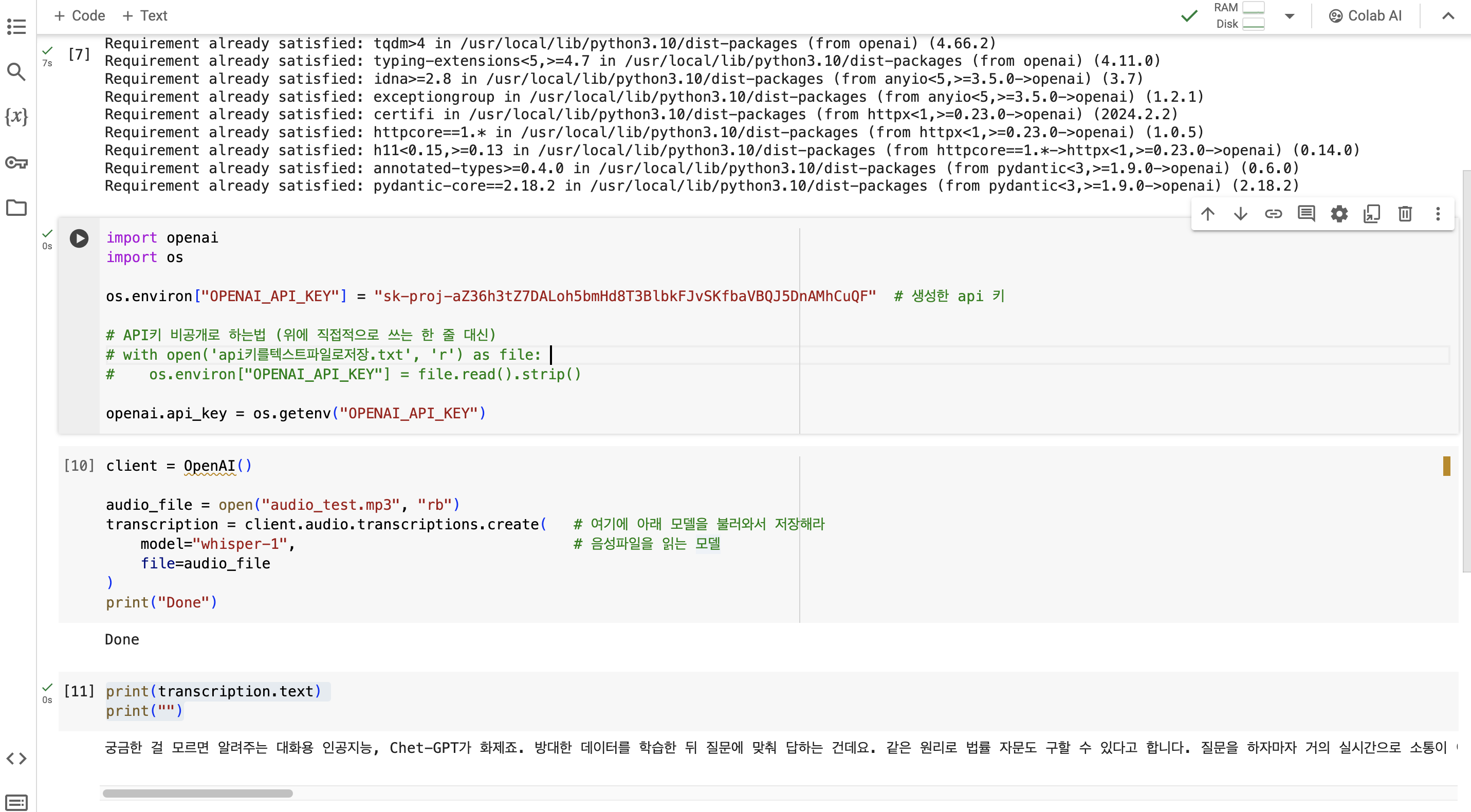
위의 유투브에서 추출한 파일 음성내용과 일치합니다!
신기하네요!
text to speech
이제는 오디오 파일을 만들어 봅니다.
자세한 정보 입니다.
speech 사용
speech_file_path = "speech_output.mp3" # mp3파일 형태로 여기에 저장할거야
response = client.audio.speech.create(
model = "tts-1",
voice = "alloy",
input = "안녕하세요. 저는 백혜진 입니다. 나는 꼭 에이아이 서비스 엔지니어가 될거야. 나는 존나 멋있으니깐"
)
response.stream_to_file(speech_file_path)from IPython.display import Audio, display
Audio("speech_output.mp3") # From URL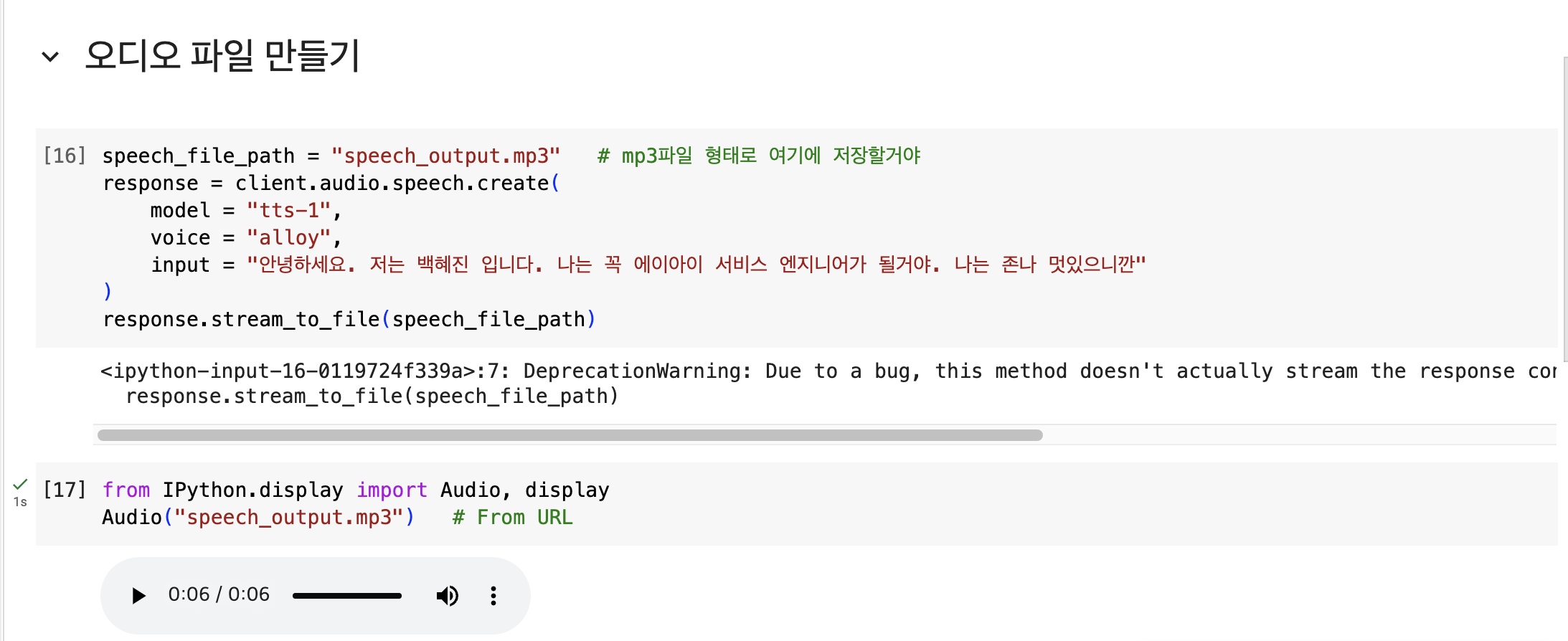
텍스트를 영어로 변역
audio_file = open("speech_output.mp3", "rb")
translations = client.audio.translations.create(
model = "whisper-1",
file = audio_file
)
print(translations.text)

데이터기반 스토리텔링을 통해 인사이트를 얻습니다.