
결측치 있는 데이터 불러오기
데이터베이스 연결
PostgreSQL에 가져올 데이터가 있는 데이터베이스 연결 ok
pdAdmin 테이블 생성
해당 데이터베이스 에서 쿼리도구 연결해서 테이블생성 ok
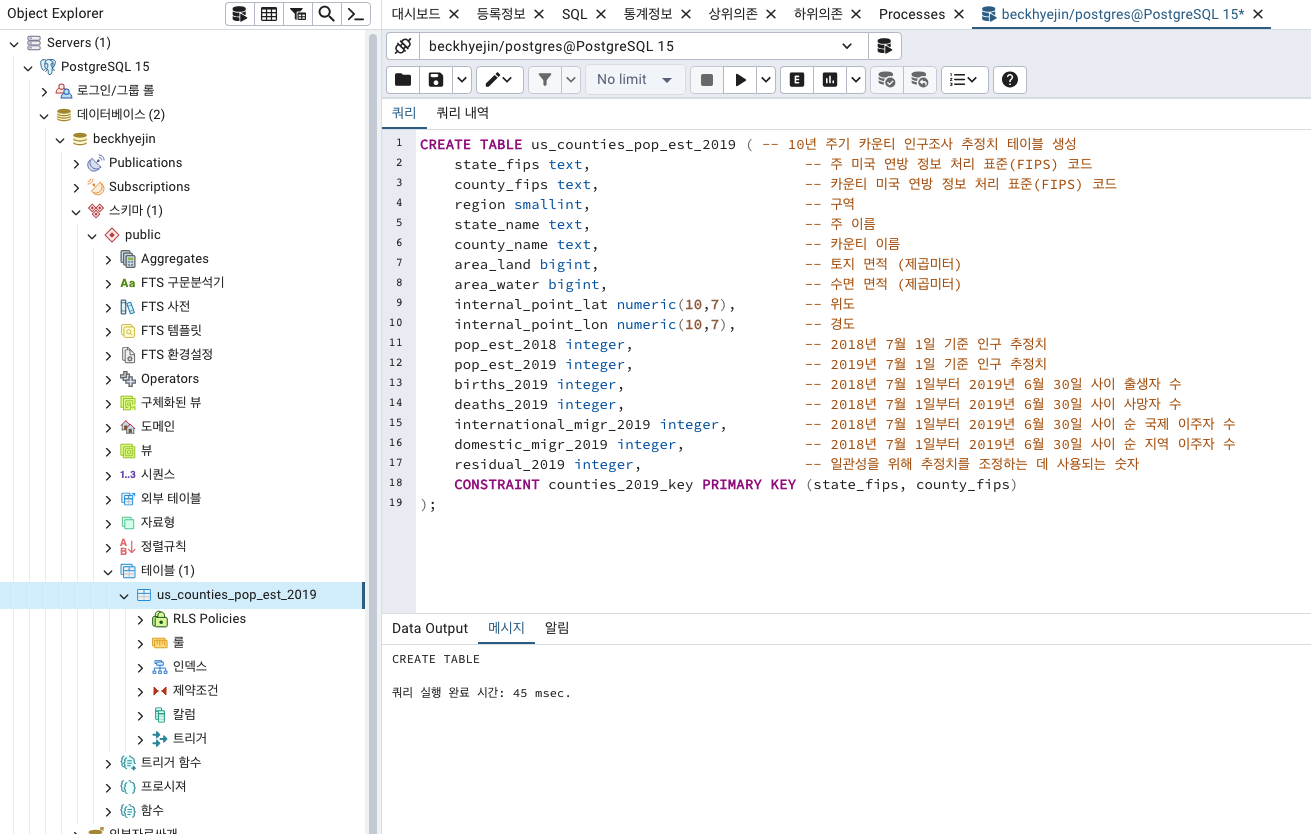
CREATE TABLE us_counties_pop_est_2019 ( -- 10년 주기 카운티 인구조사 추정치 테이블 생성
state_fips text, -- 주 미국 연방 정보 처리 표준(FIPS) 코드
county_fips text, -- 카운티 미국 연방 정보 처리 표준(FIPS) 코드
region smallint, -- 구역
state_name text, -- 주 이름
county_name text, -- 카운티(행정구역) 이름
area_land bigint, -- 토지 면적 (제곱미터)
area_water bigint, -- 수면 면적 (제곱미터)
internal_point_lat numeric(10,7), -- 위도
internal_point_lon numeric(10,7), -- 경도
pop_est_2018 integer, -- 2018년 7월 1일 기준 인구 추정치
pop_est_2019 integer, -- 2019년 7월 1일 기준 인구 추정치
births_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 출생자 수
deaths_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 사망자 수
international_migr_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 순 국제 이주자 수
domestic_migr_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 순 지역 이주자 수
residual_2019 integer, -- 일관성을 위해 추정치를 조정하는 데 사용되는 숫자
CONSTRAINT counties_2019_key PRIMARY KEY (state_fips, county_fips)
-- CONSTRAINT 제약 조건
-- PRIMARY KEY 결측값이 없어야함 + UNIQUE 중복값이 없어야함
);실행한 뒤, Refresh로 테이블 생성됨 확인 ok
빈 테이블이 생성되어 아직 데이터값 없음 확인 ok
데이터 가져오기 COPY
- COPY 테이블명
- FROM 데이터베이스에 있는 데이터의 전체 경로
- WITH (FORMAT 형식, 헤더행이 있는지 없는지)
데이터베이스 안에 있는 데이터 파일 오른쪽 클릭 > COPY PATH로 경로 확인 >FROM 뒤에 붙혀넣기 해줍니다.
COPY us_counties_pop_est_2019 -- 테이블명
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/us_counties_pop_est_2019.csv'
WITH (FORMAT CSV, HEADER); 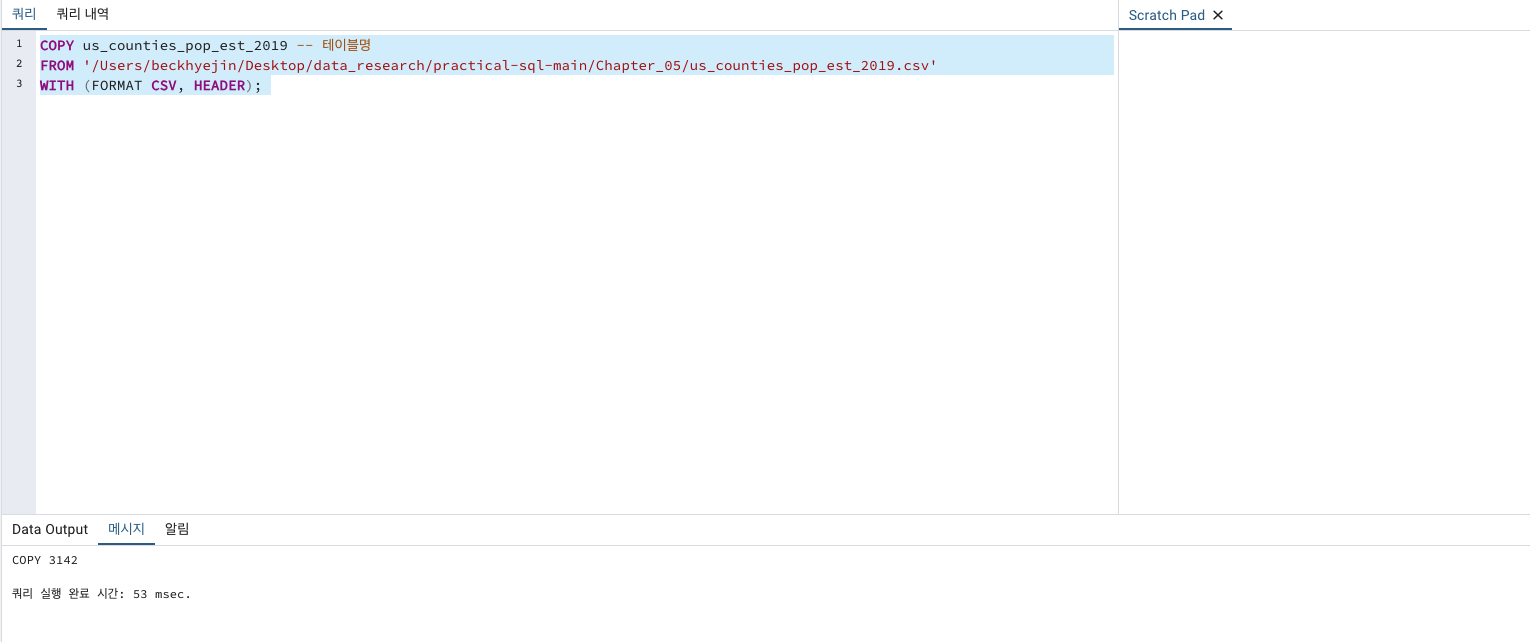
다행히 이전과 달리 에러가 나지 않습니다!!!!
너무 기분이 좋습니다!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
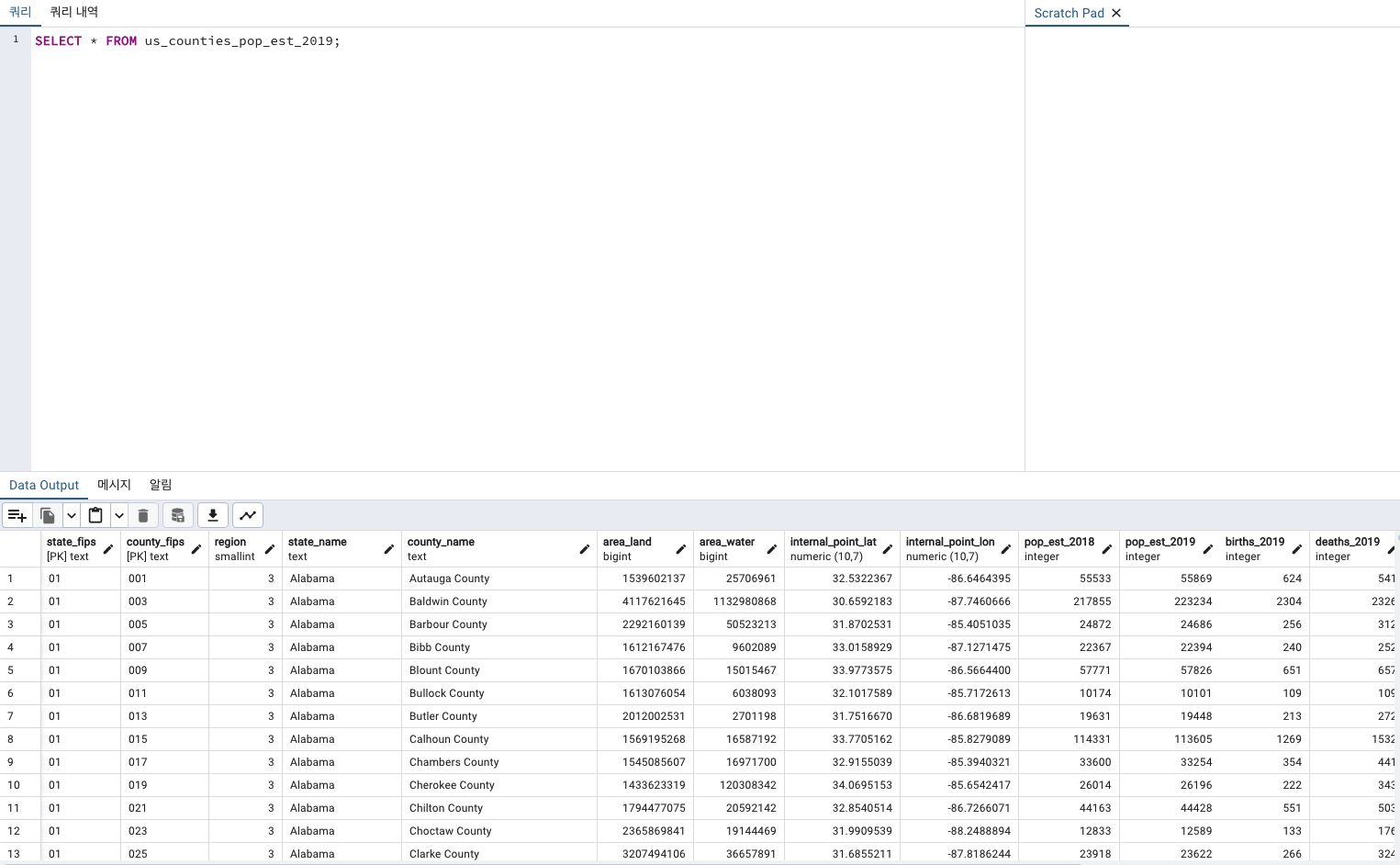
3,142개의 rows가 있습니다.
데이터 파악
state_fips text, -- 주 미국 연방 정보 처리 표준(FIPS) 코드
county_fips text, -- 카운티 미국 연방 정보 처리 표준(FIPS) 코드
region smallint, -- 구역
state_name text, -- 주 이름
county_name text, -- 카운티(행정구역) 이름
area_land bigint, -- 토지 면적 (제곱미터)
area_water bigint, -- 수면 면적 (제곱미터)
internal_point_lat numeric(10,7), -- 위도
internal_point_lon numeric(10,7), -- 경도
pop_est_2018 integer, -- 2018년 7월 1일 기준 인구 추정치
pop_est_2019 integer, -- 2019년 7월 1일 기준 인구 추정치
births_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 출생자 수
deaths_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 사망자 수
international_migr_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 순 국제 이주자 수
domestic_migr_2019 integer, -- 2018년 7월 1일부터 2019년 6월 30일 사이 순 지역 이주자 수
residual_2019 integer, -- 일관성을 위해 추정치를 조정하는 데 사용되는 숫자
CONSTRAINT counties_2019_key PRIMARY KEY (state_fips, county_fips)
-- CONSTRAINT 제약 조건
-- PRIMARY KEY 결측값이 없어야함 + UNIQUE 중복값이 없어야함
LIMIT 숫자
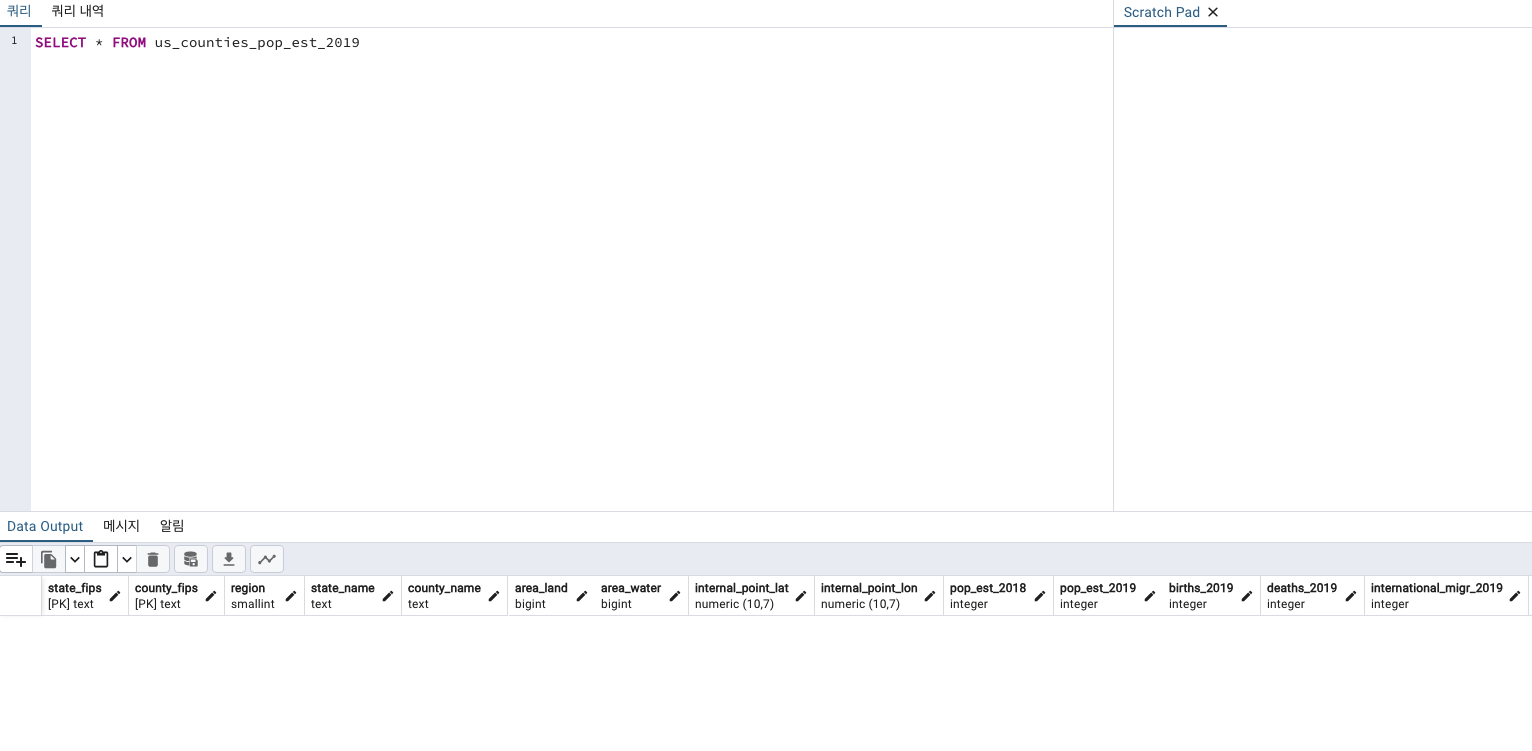
SELECT *
FROM us_counties_pop_est_2019
LIMIT 3 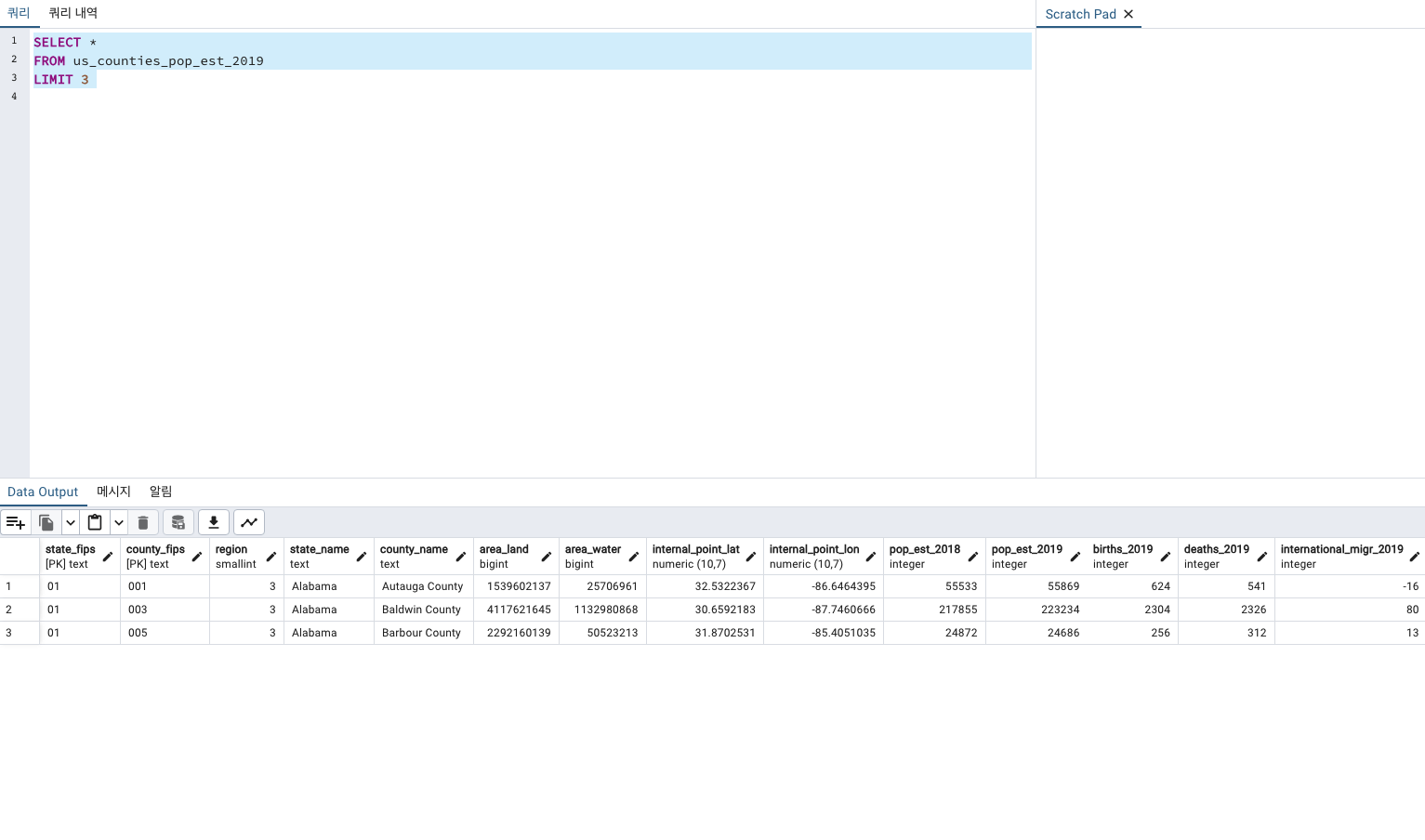
토지면적 정렬
토지면적 area_land 큰 top 5
카운티 이름 country_name, 주 이름 state_name, 토지면적 area_land의 값
SELECT area_land , state_name, county_name
FROM us_counties_pop_est_2019
ORDER BY area_land DESC
LIMIT 5 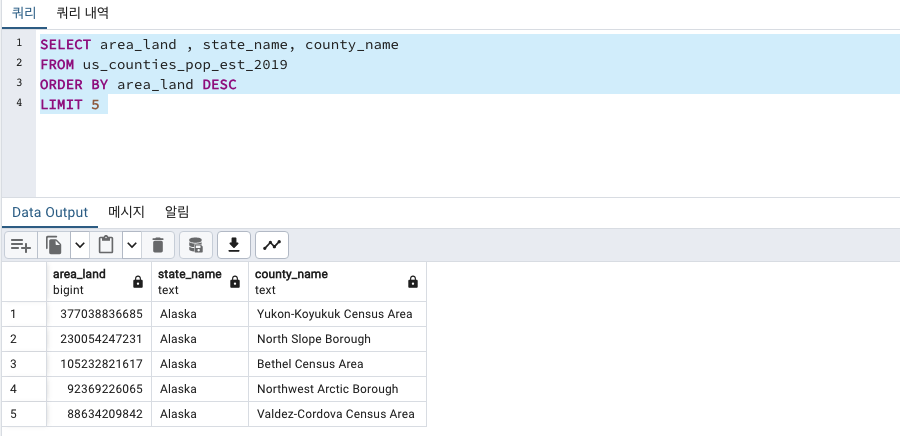
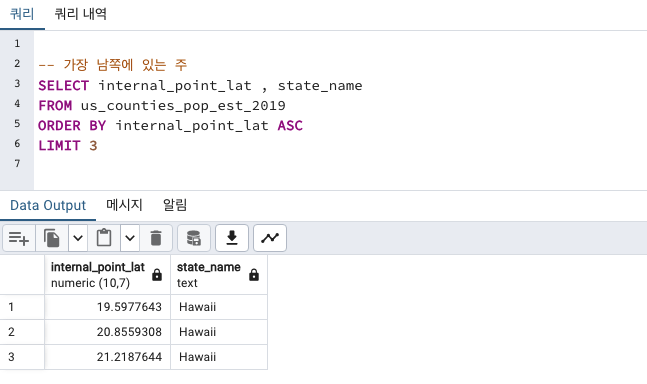
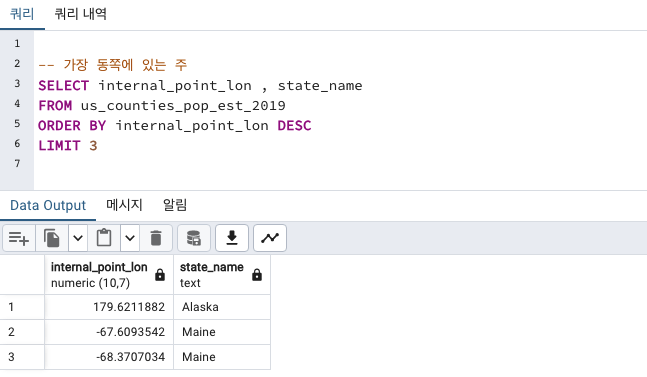
가장 북/남/동/서에 위치
경/위도로 확인 가능
internal_point_lat 위도 latitude (양수일수록 북쪽, 음수일수록 남쪽)
internal_point_lon 경도 longitude (양수일수록 동쪽, 음수일수록 서쪽)
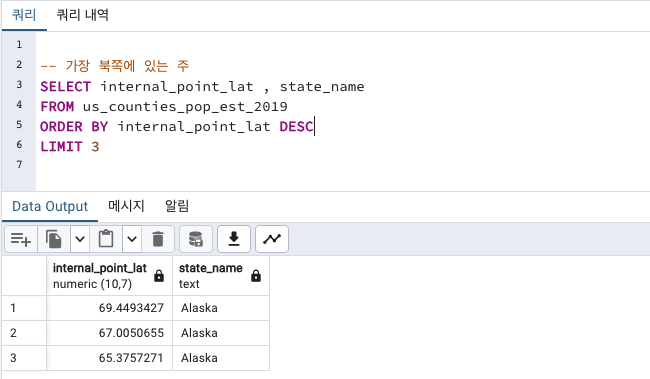
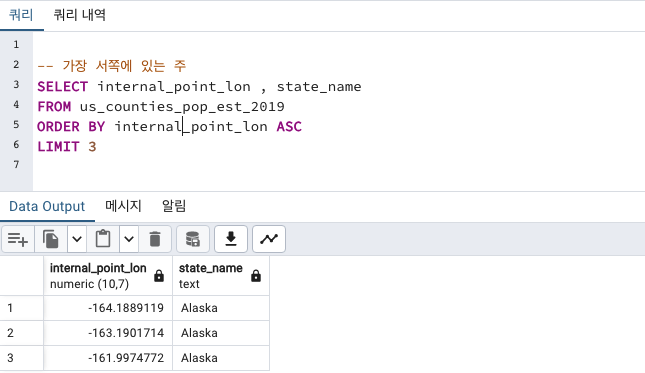
- 가장 북쪽에 있는 주 : Alaska
- 가장 남쪽에 있는 주 : Hawaii
- 가장 동쪽에 있는 주 : Alaska 그 다음 Maine
- 가장 남쪽에 있는 주 : Alaska
알래스카 지분이 많습니다.
-- 알래스카 주 데이터만
SELECT county_name, internal_point_lat, internal_point_lon
FROM us_counties_pop_est_2019
WHERE state_name = 'Alaska'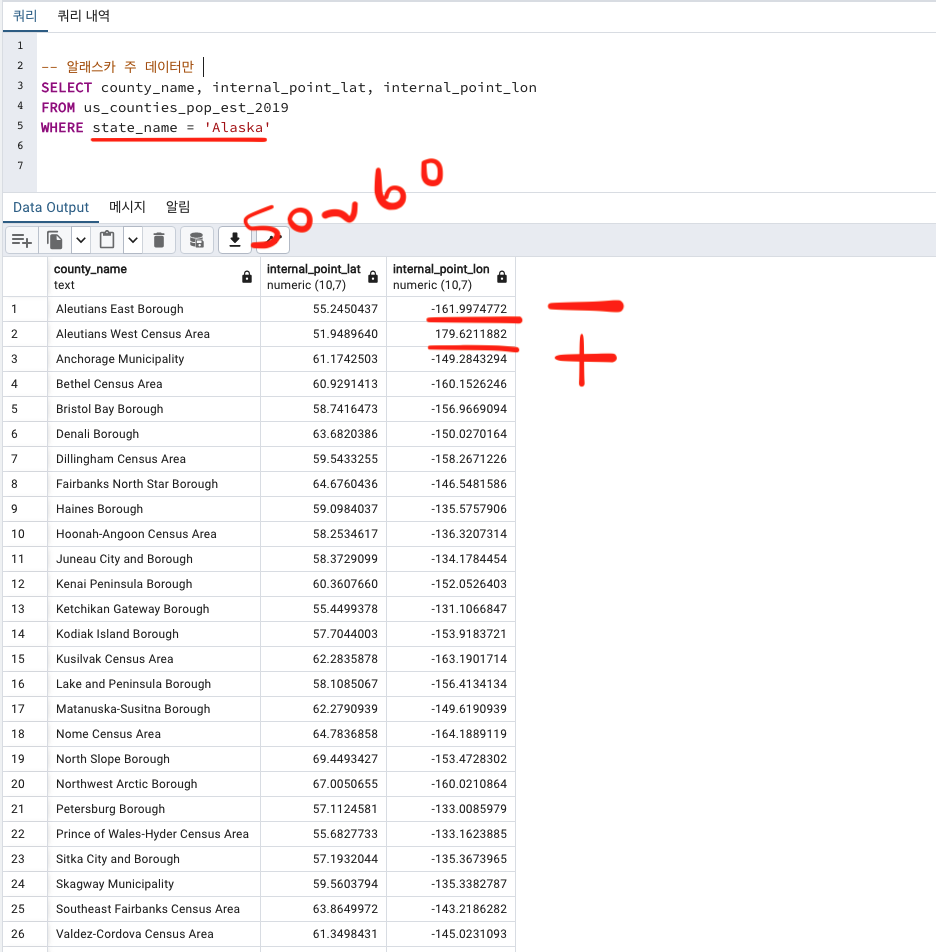
한번 더 데이터를 확인해보니, 위도 (북/남) 은 50~60 구간으로 한정되어있지만
경도(동/서) 는 -160 부터 +179까지도 있습니다.
세계의 UTC 지도를 보니, 경도 180도 (자오선)을 지나면 음수 -> 0 -> 다시 양수로 카운트 된다고 합니다.
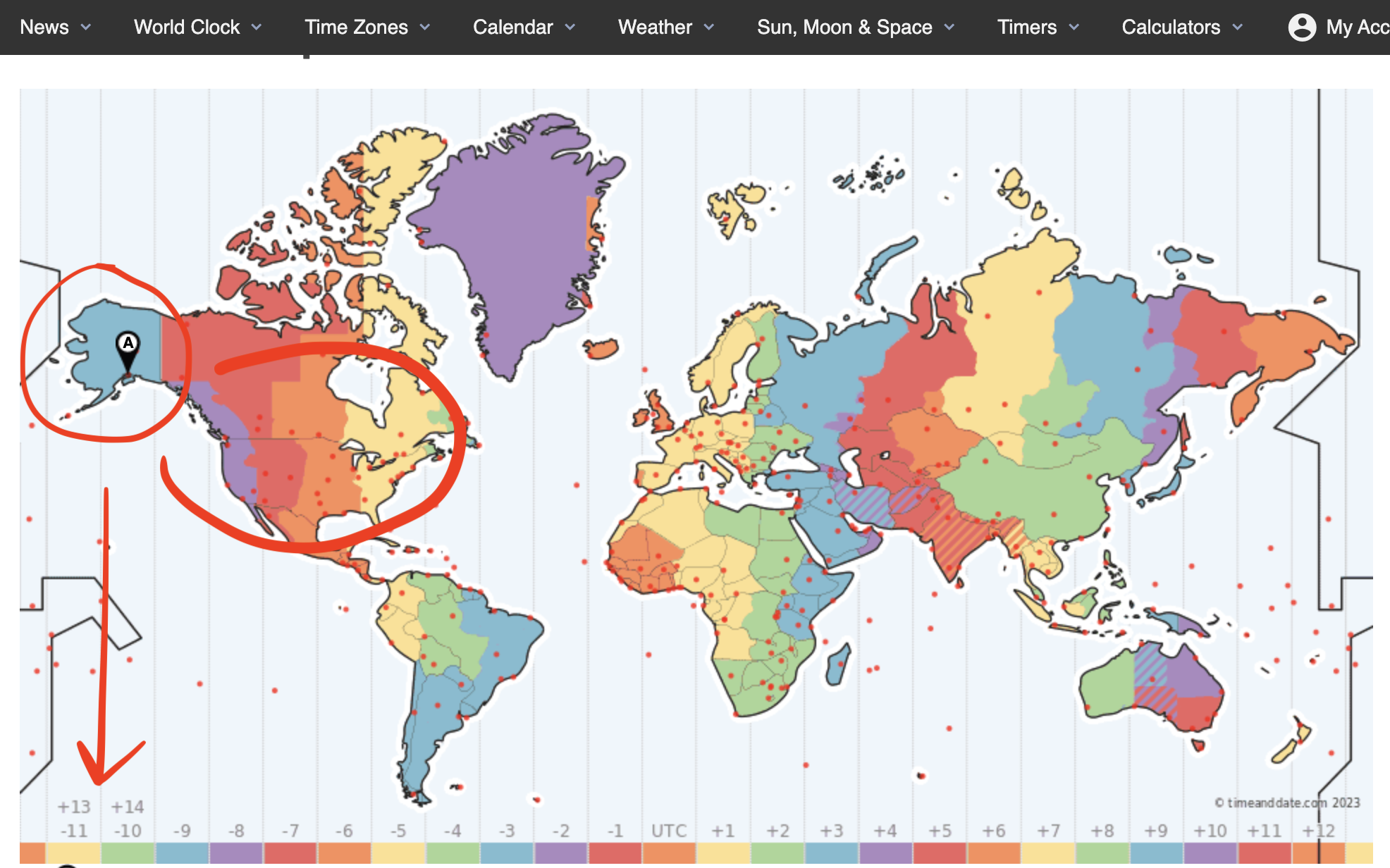
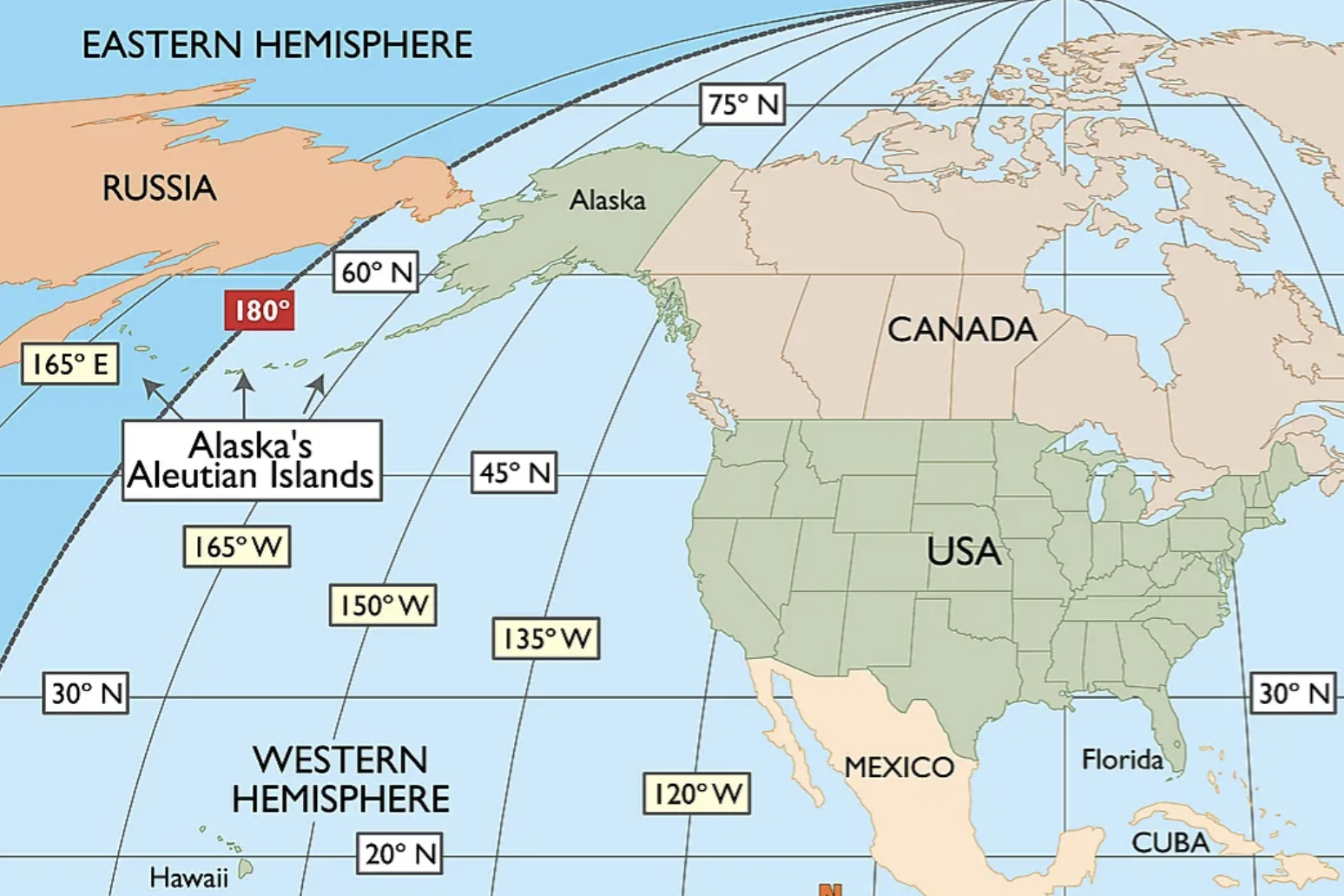
데이터에 이상은 없는것 같습니다.
결측치 있는 데이터 불러오기
위에는 결측치가 없는 조건으로 데이터를 불러왔습니다.
결측치가 있는 데이터를 가져와보겠습니다.
- 목표 : 지역별로 정부 지출 추세 분석
- 데이터 : 해당 주의 모든 마을 관리자의 정보 (마을,카운티,관리자이름,근로시작날짜,급여,혜택)
테이블 생성
CREATE TABLE supervisor_salaries(
id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
-- 자동으로 하나씩 1>2>3.. 증가되는 고유의 번호 열 (데이터 값을 일일이 부여할 필요 없음)
town text,
county text,
supervisor text,
start_date date,
salary numeric(10,2),
benefits numeric(10,2)
)
데이터 가져오기 COPY
COPY supervisor_salaries
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries.csv'
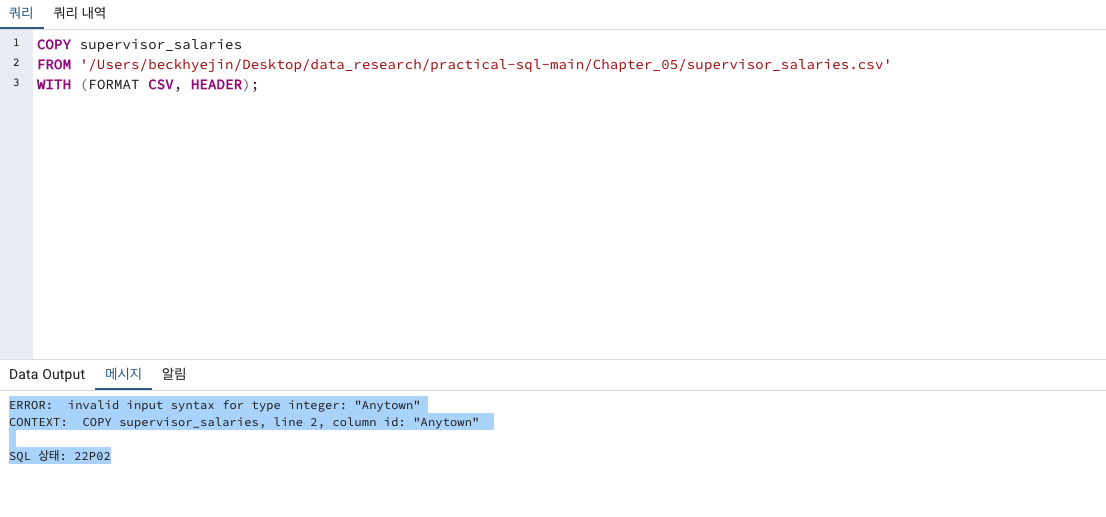
WITH (FORMAT CSV, HEADER);참고로 가져올 데이터
데이터 가져오기 ERROR
제가 만든 테이블의 컬럼은 id > town > county,,, 순으로서
첫번째 열이 숫자(정수)열 입니다.
그러나 가져올 데이터에는 Anytown 열이 integer 타입이 아니라서 에러가 나는 것 같습니다.
line2는 2번째 row부터 데이터가 들어가기에 안맞는다는것 같습니다.
(line1은 Header 컬럼명 값이니까, 본론적으로 데이터의 rows는 두번째 line인 행부터 들어갑니다)
해당 데이터는 town, supervisor, salary 이렇게 3개의 columns과 5줄의 rows로 이루어져 있습니다.
만든 테이블의 컬럼과 순서도, 갯수도 일치하지 않죠!
이럴 경우 가져올 데이터에 어떤 컬럼을 가져와야하는지 지정해줘야 합니다.
COPY 데이터명 (가져올 컬럼을 각각 지시)
FROM 파일 경로
WITH (포맷 지정, 헤더가 있는지 여부)
- 가져올 데이터의 컬럼 =
town,supervisor,salary - 이미 만든 빈 테이블의 컬럼 = id,
town, county,supervisor, start_date,salary, benefits
아~ 이렇게 테이블 컬럼과 가져올 데이터 컬럼 이름이 같아서 매칭을 해줄 수 있나 봅니다!
이런것 까지 생각해서 테이블을 만들때 테이블명을 확실하게 해줘야 되나 보군요!
컬럼 지정 후 데이터 가져오기 COPY
COPY supervisor_salaries (town, supervisor, salary)
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries.csv'
WITH (FORMAT CSV, HEADER);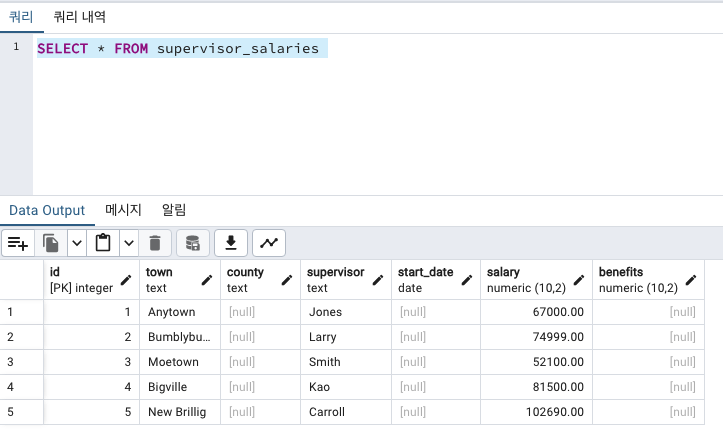
가져온 컬럼값만 채워졌습니다.
가져온 데이터 삭제하기 DELETE
DELETE FROM supervisor_salaries; 테이블(컬럼)은 그대로이지만, 그 안의 데이터는 삭제되었습니다.
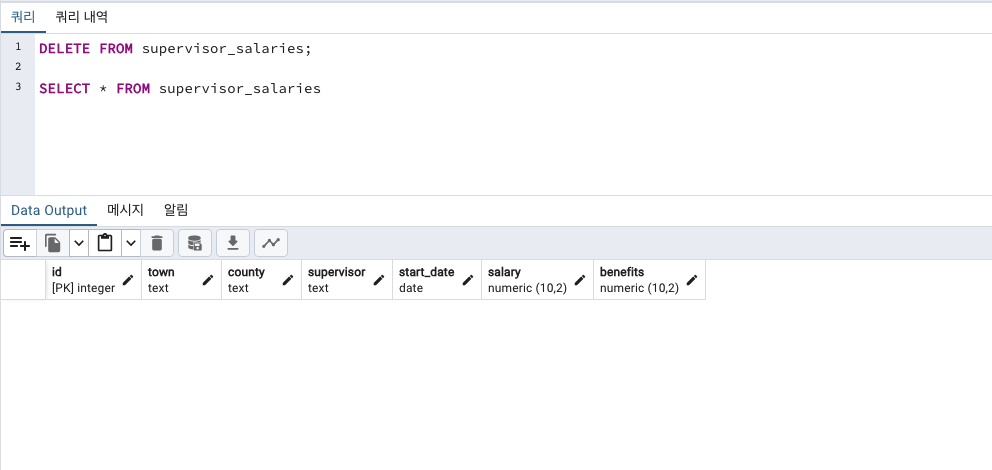
데이터 가져오기 COPY (일부행만 WHERE)
COPY데이터명 (가져올 컬럼을 각각 지시)
FROM파일 경로
WITH(포맷 지정, 헤더가 있는지 여부)
를 통해서 데이터를 가져와 테이블을 채울겁니다.
단! 다 채우는게 아니라 원하는 값의 row만 가져올겁니다!
COPY데이터명 (가져올 컬럼을 각각 지시)
FROM파일 경로
WITH(포맷 지정, 헤더가 있는지 여부)
WHERE컬럼 = '특정데이터값'
이렇게 하면 특정데이터값이 있는 row만 가져오게 됩니다.
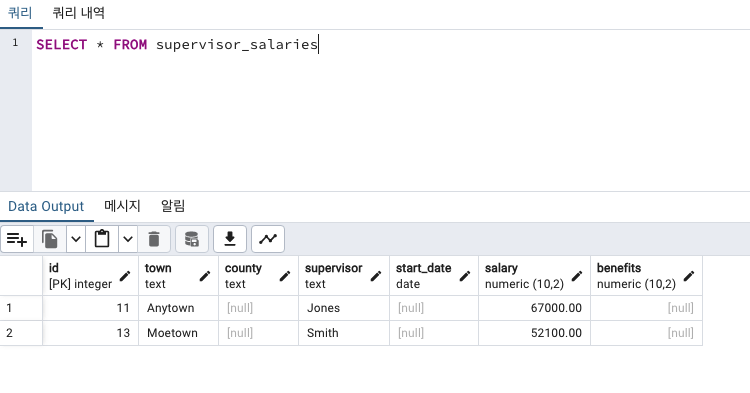
아까 town 컬럼에는 Anytown, Bumblyburg , Moetown, Bigville, New Brilling 이렇게 총 5개의 rows 가 있었는데
이 중 town으로 끝나는 마을 데이터만 가져와보겠습니다.
COPY supervisor_salaries(town, supervisor, salary)
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries.csv'
WITH (FORMAT CSV, HEADER)
-- WHERE town = '%town'-- 문자열을 찾을때는 like나 ilike 이용하자
WHERE town ilike '%town' -- town 으로 끝나는 모든 town데이터 WHERE 에서 문자열 필터링 할때는 꼭 ilike , not like, in (..) 등을 이용해야 합니다!!!
가져온 데이터 삭제하기 DELETE
DELETE FROM supervisor_salaries; 테이블(컬럼)은 그대로이지만, 그 안의 데이터는 삭제되었습니다.
데이터 가져오기 COPY (데이터값추가 INSERT INTO)
이미 만들어진 테이블의 빈 컬럼값을 별도로 채워넣고 싶습니다.
해당 데이터는 county가 'Mills' 인 데이터니까 INSERT INTO로 모두 값을 넣어 주면 되지 않을까요?
그렇기 위해서는 임시테이블로 만들어서 씌워야 된다고 합니다.
임시테이블 만들기
CREATE TEMPORARY TABLE임시테이블에 데이터 가져오기
COPY임시 테이블명 (가져올 컬럼명)
FROM데이터 경로
WITH(포맷형태, 헤더여부)기존테이블에 임시테이블 컬럼값 추가하기
INSERT INTO기존 테이블명 (가져올 컬럼명과 추가하고싶은 컬럼명)
SELECT기존 컬럼명, 기존 컬럼명, '추가 컬럼명', 기존컬럼명,,
FROM임시 테이블명임시테이블 삭제하기
DROP TABLE임시 테이블명
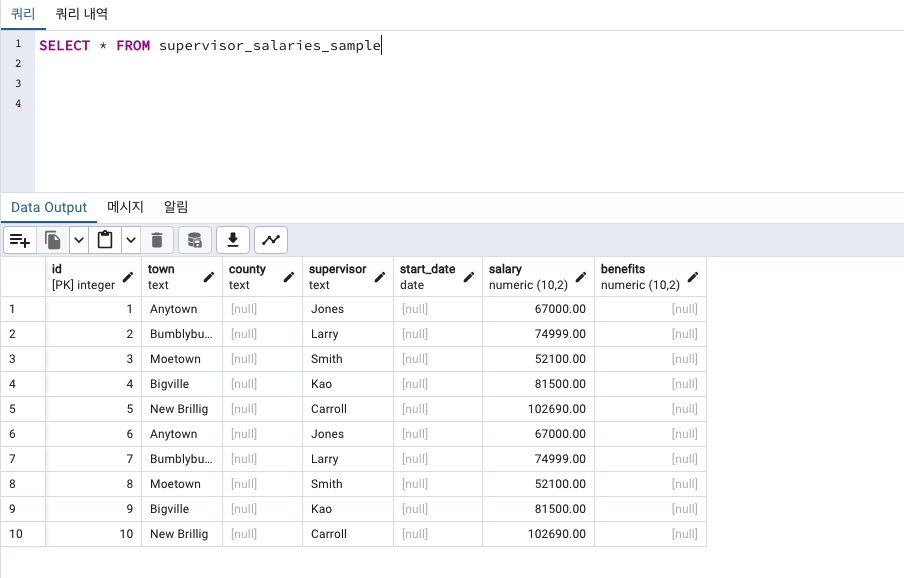
CREATE TEMPORARY TABLE supervisor_salaries_sample -- 임시 테이블을 만들건데
(LIKE supervisor_salaries INCLUDING ALL); -- 이미 만들어둔 테이블의 정보와 모두 똑같이!
COPY supervisor_salaries_sample (town, supervisor, salary) -- 임시테이블에도 기존테이블과 동일한 컬럼명을 지정
-- 임시테이블에도 똑같이 가져올 데이터 경로
FROM '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries.csv'
WITH (FORMAT CSV, HEADER)
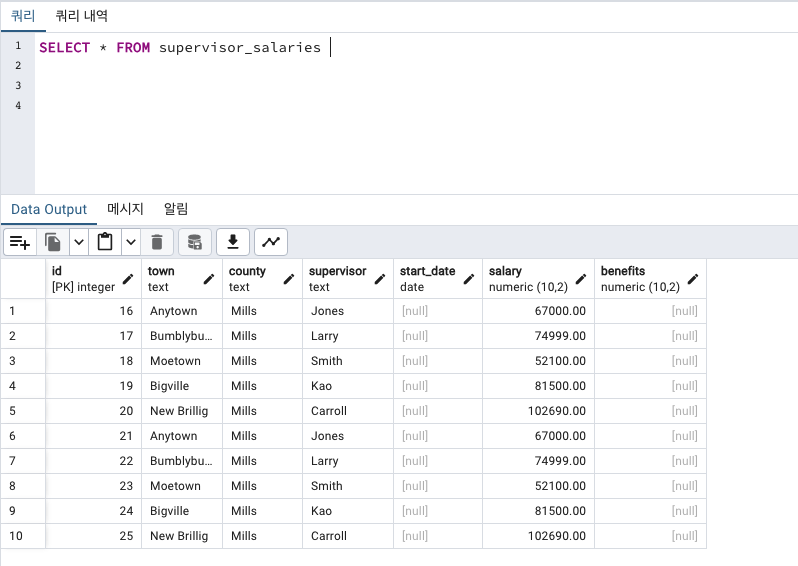
INSERT INTO supervisor_salaries (town, county, supervisor, salary) -- 기존테이블에 새 컬럼'county'포함한 모든 컬럼명
SELECT town, 'Mills', supervisor, salary -- 위의 추가할 컬럼에는 데이터값을 'Mills'
FROM supervisor_salaries_sample -- 임시테이블에서 가져옴
왜 임시테이블을 만들어야할까?
어자피 기존테이블에 county 컬럼이 있고 null값-> 'Mills' 로 채워넣으려는건데
굳~이 임시테이블을 기존테이블과 똑같이 만든 뒤에 INSERT INTO 기존테이블 해서 추가해야할 이유가 있을까요?
바로 기존테이블 county 컬럼 결측치 값을 모두 'Mills'로 바꾸면 되는거 아닌가요?이 교재에서는 '원하는 데이터를 얻으려면, 데이터 처리에 여러 단계가 필요한지 확인하는것이 좋다' 라는 이유에서 한 것 일지 잘 모르겠습니다.
아무튼 저는 따로 null값에 공통의 값을 넣는 방법으로 다시 해보겠습니다.
위에 데이터를 보면 supervisor_salaries_sample 테이블의 county 결측값을 anyang으로 바꾸겠습니다.
Null값을 바로 수정 (UPDATE와 SET)
UPDATE supervisor_salaries_sample -- 해당 테이블값을 수정하겠다.
SET county = 'Anyang' -- county 컬럼에 'Anyang'으로 채워넣겠다.
WHERE county IS NULL; -- county 컬럼의 결측치인 행들에게만! 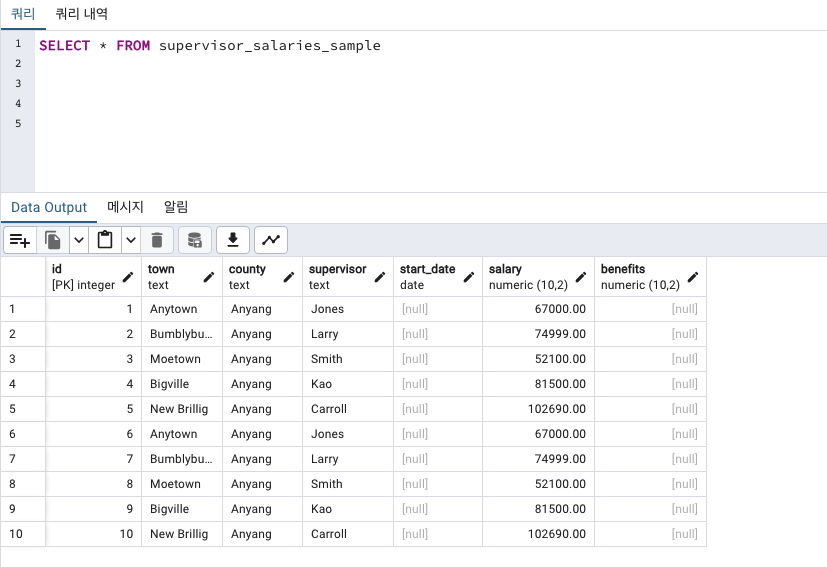
테스트용으로는 임시테이블의 쓰임새가 다했으니, 삭제해줍니다.
DROP TABLE supervisor_salaries_sample 근데 왜 DROP이죠? 삭제는 DELETE 아닐까요?
DROP과 DELETE
- DROP
테이블 전체 삭제- DELETE
테이블은 유지 , 데이터값만 삭제
데이터 내보내기 COPY
빈 테이블에 채워넣을 데이터를 가져올때도 COPY를 썼는데,
테이블을 파일로 보낼때도 COPY를 사용한다고 합니다.
데이터 가져오기 COPY
COPY테이블명 (가져올 컬럼을 각각 지시)
FROM파일 경로
WITH(포맷 지정, 헤더가 있는지 여부)데이터 내보내기 COPY(모두)
COPY테이블명
TO저장 파일 경로\파일이름.파일형식
WITH(포맷 지정, 헤더가 있는지 여부, 구분기호);데이터 내보내기 COPY(특정 columns만)
COPY테이블명 (컬럼명, 컬럼명,,)
TO저장 파일 경로\파일이름.파일형식
WITH(포맷 지정, 헤더가 있는지 여부, 구분기호);데이터 내보내기 COPY(특정 rows만)
COPY(
SELECT컬럼명
FROM테이블명
WHERE조건값
)
TO저장 파일 경로\파일이름.파일형식
WITH(포맷 지정, 헤더가 있는지 여부, 구분기호);
모두
-- HEADER 컬럼명 포함하고 , 대신 | 을 구분기호로
-- txt파일 장점 : 모든 텍스트 파일 형식으로 내보낼 수 있음
-- 주의 : 쉼표(,)를 구분기호로 사용할 때만 CSV 형식으로 저장하며 그 외 구분기호로는 CSV 저장 XXXXXXXX
COPY supervisor_salaries
TO '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries.txt'
WITH (FORMAT CSV, HEADER, DELIMITER '|')
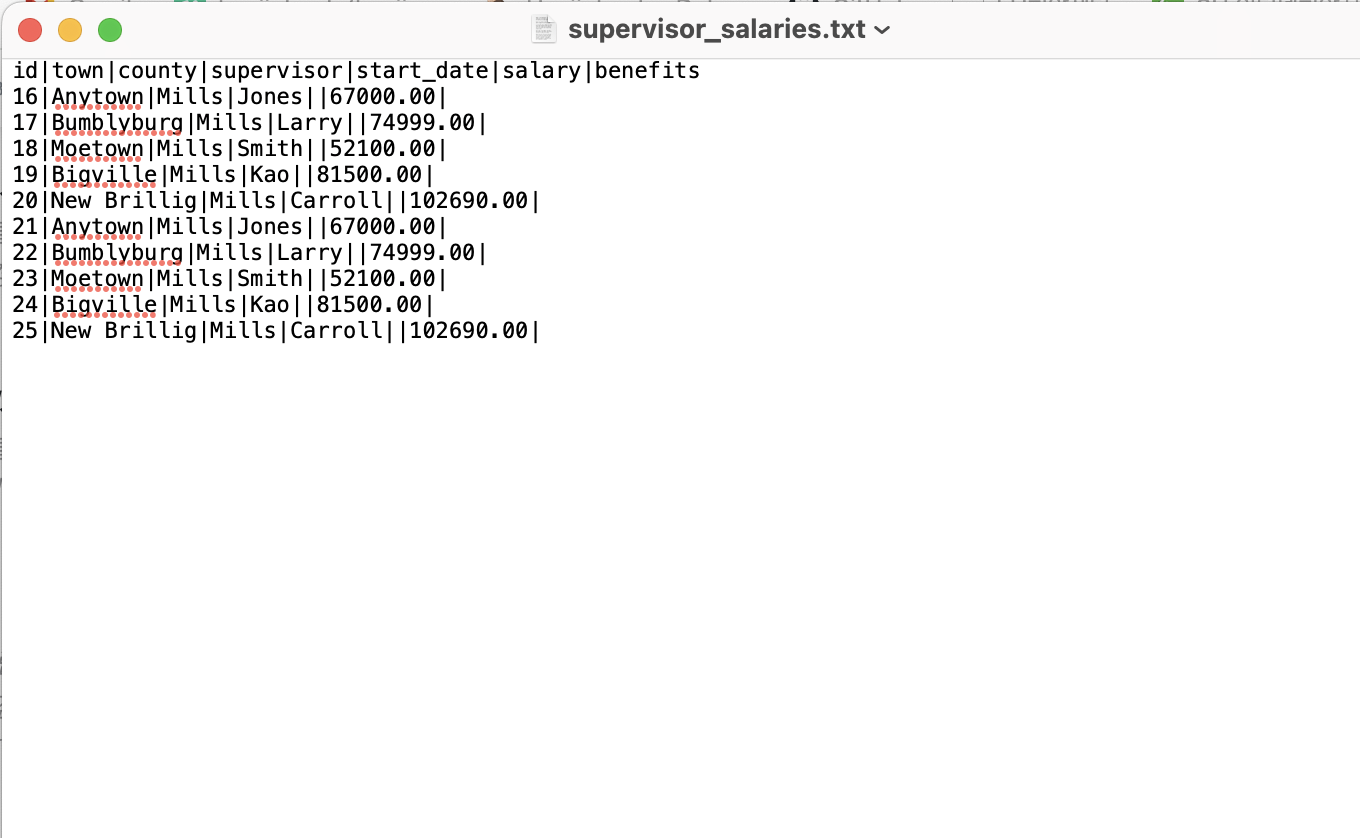
정상적으로 저장이 되었고, txt 형식으로도 잘 보입니다.
특정 컬럼만
COPY supervisor_salaries (town, supervisor)
TO '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries_columns.txt'
WITH (FORMAT CSV, HEADER, DELIMITER '|')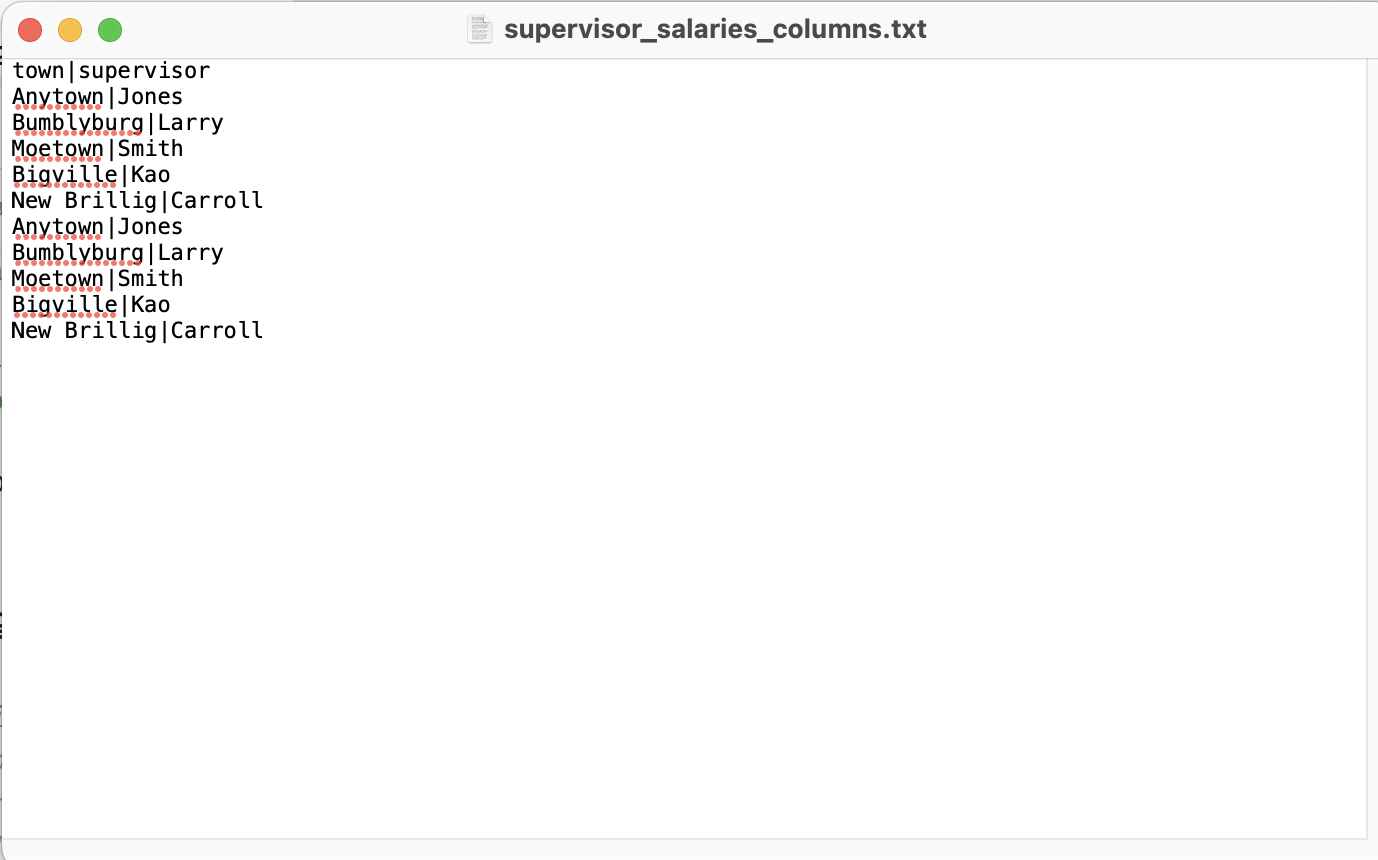
특정 값만
WHERE 절로 조건값을 필터링 걸어, 조건에 해당하는 데이터값들만 저장하도록 하겠습니다.
예를들면....
b로 시작하는 town의 모든 데이터값 만 저장하겠습니다.
COPY(
SELECT *
FROM supervisor_salaries
WHERE town ilike 'b%'
)
TO '/Users/beckhyejin/Desktop/data_research/practical-sql-main/Chapter_05/supervisor_salaries_b.txt'
WITH (FORMAT CSV, HEADER, DELIMITER '|')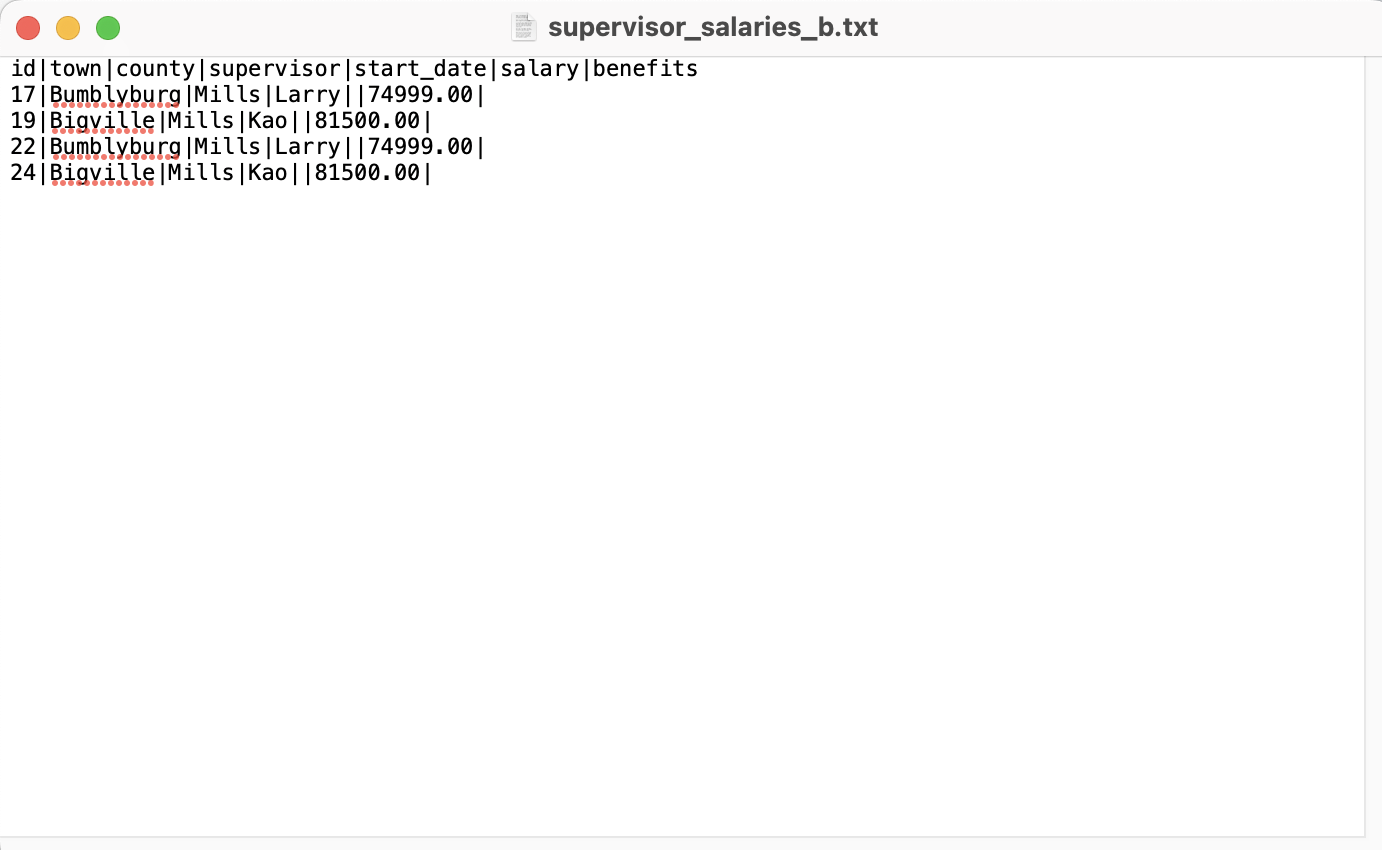
txt로 저장하는데 왜 FORMAT CSV?
TO 경로 할때 경로\파일명.txt 로 저장함을 알리는데
WITH (FORMAT CSV,, ) 를 굳이 하는걸까요?
따로 구글링을 해도 확인이 안됩니다.
일단 교재에 포스트잇으로 붙혀놔서 교재 진도가 완료될때까지도 이해가 안되면 출판사에 물어볼 예정입니다.
COPY 불가한 경우
AWS(Amazon Web Services)와 같은 다른 컴퓨터에서 PostgreSQL 인스턴스에 연결될 때 COPY로 데이터 불러오기/내보내기가 어렵다고 합니다.
파일경로를 찾지 못하니깐요! (원격 서버로 전송/받아올 권한이 없는 경우가 많음)
그럴땐 그냥 탐색기에서 데이터베이스> 스키마 > public> 테이블 오른쪽 클릭으로
Import/Export DATA... 를 눌러 수행하면 됩니다.
