
기본 수학 연산자
표준SQL 언어가 아니며, PostgreSQL 에만 해당됩니다.
+더하기
-빼기
*곱하기
/나누기 (몫만 반환됩니다 = 나머지 확인불가)
%나누기 (나머지값만 반환됩니다 = 몫 확인 불가)
^지수화
|/제곱근 또는sqrt(n)
||/세제곱근
!팩토리얼
덧셈,뺄셈 등
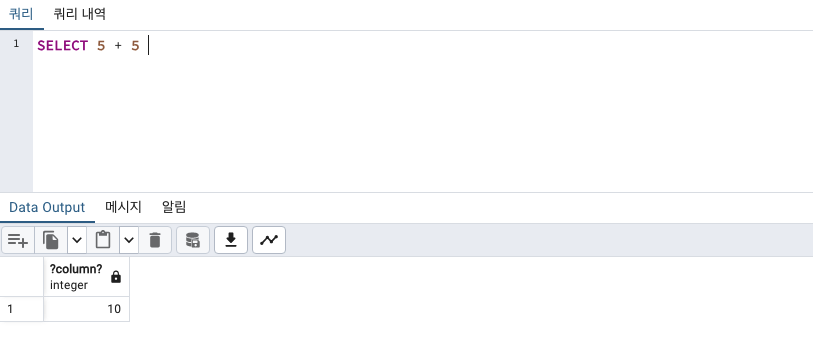
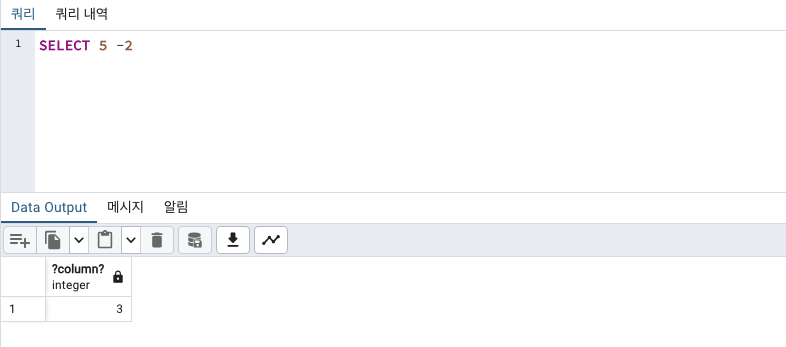
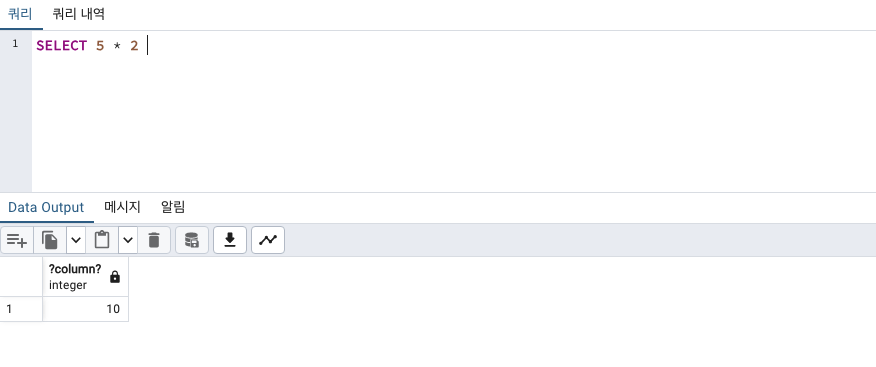
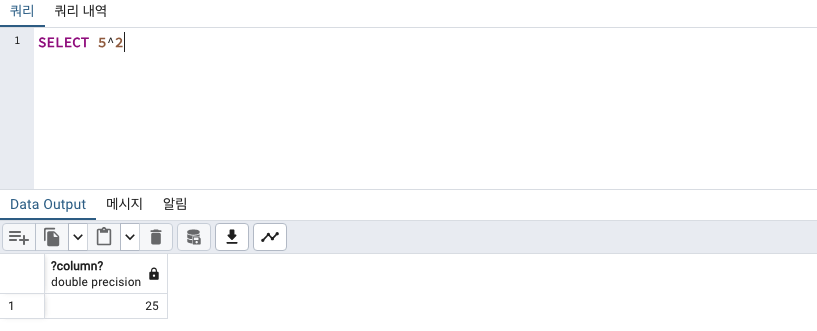
column명을 지정해주고 싶다면 as 로 가능합니다.
나누기(정수,소수 등)
-- 10 나누기 3 하면 몫(3), 나머지(1) 나옵니다.
-- 10 나누기 3 하면 3.33333333333 나옵니다.
-- / 하면 몫만 나옴
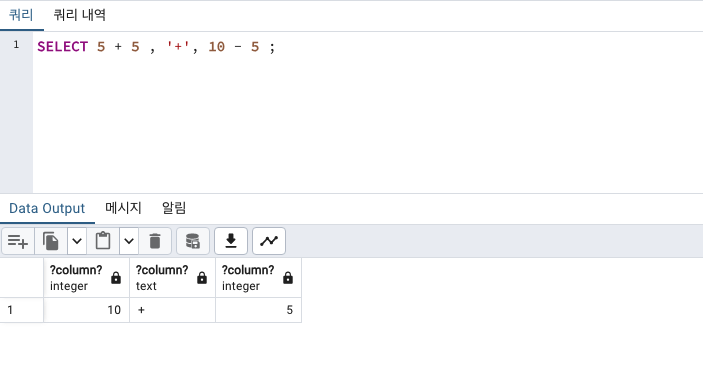
SELECT 10 / 3 as TEST ; -- 3
SELECT 10.0 / 3 as TEST; -- 3.3333333333333333
-- % 하면 나머지만 나옴
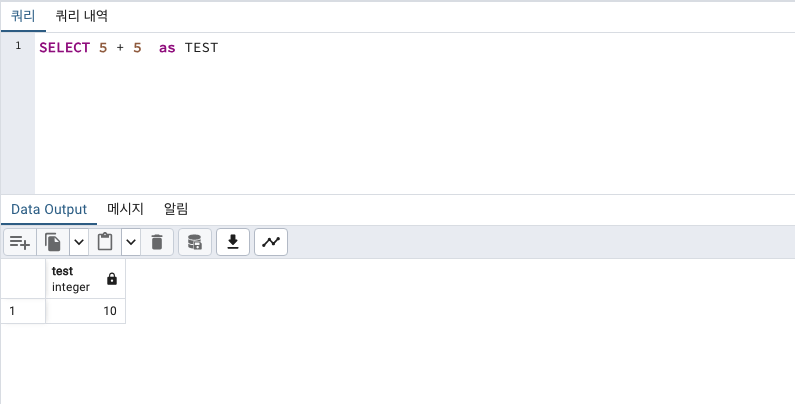
SELECT 10 % 3 as TEST ; -- 1
SELECT 10.0 % 3 as TEST; -- 1.0
-- CAST()함수로 numeric 타입으로 변환할경우 정수->소수로 나옴
SELECT CAST (10 AS numeric(3,1)) / 3; -- 3.3333333333333333
SELECT CAST (10 AS numeric(4,1)) / 3; -- 3.3333333333333333
SELECT CAST (10 AS numeric(4,2)) / 3; -- 3.3333333333333333데이터로 계산하기
데이터 확인
이전 COPY로 데이터 불러온, 2019년 미국 인구조사의 인구 추정 테이블로 진행하겠습니다.
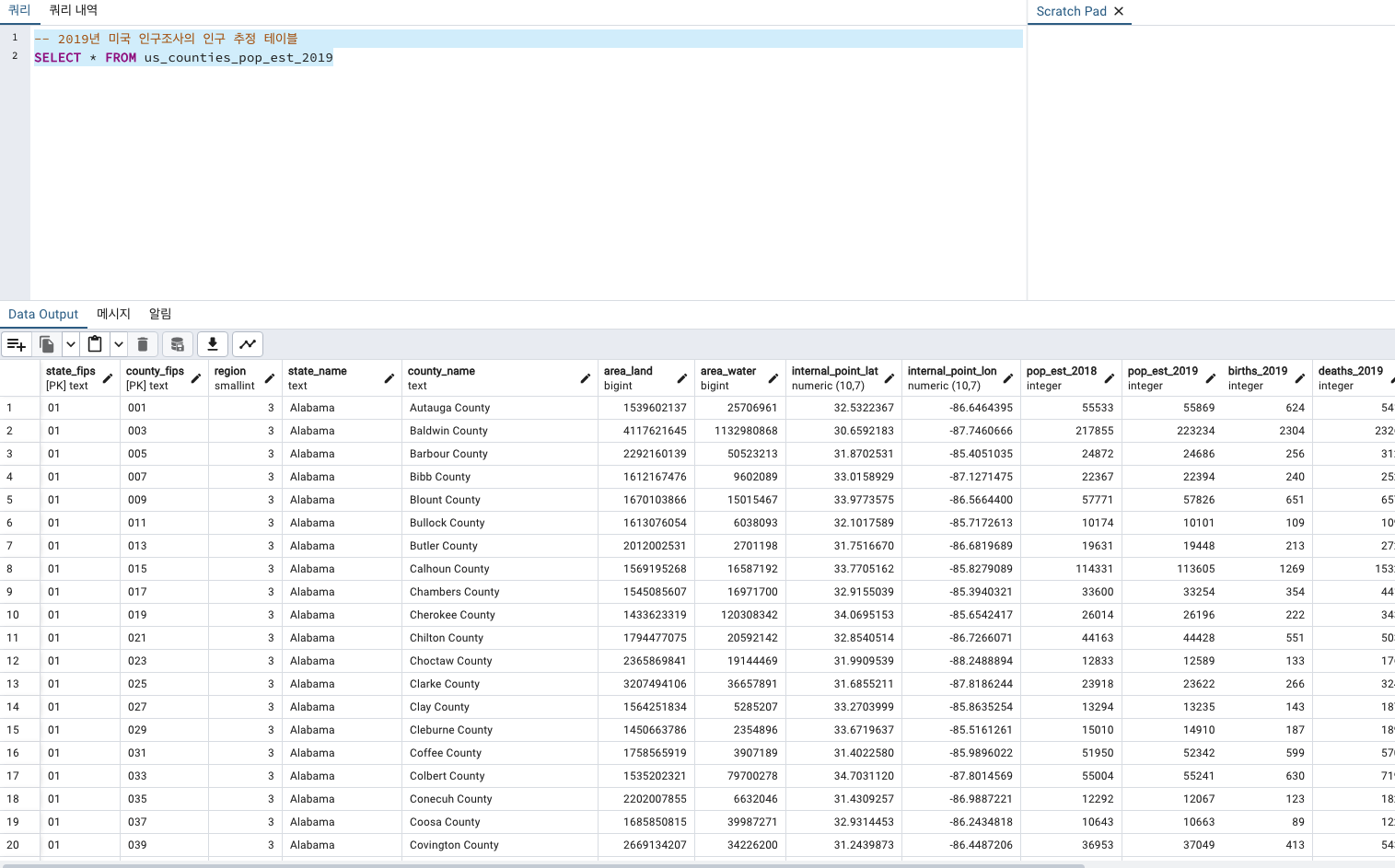
컬럼들이 많습니다.
컬럼이름만 확인해보겠습니다.
SELECT column_name -- 컬럼이름만 보겠다.
FROM information_schema.columns -- 특정 테이블의 컬럼 정보를 얻기위해 information_schema
WHERE table_name = 'us_counties_pop_est_2019'; -- 어디서? 테이블이름 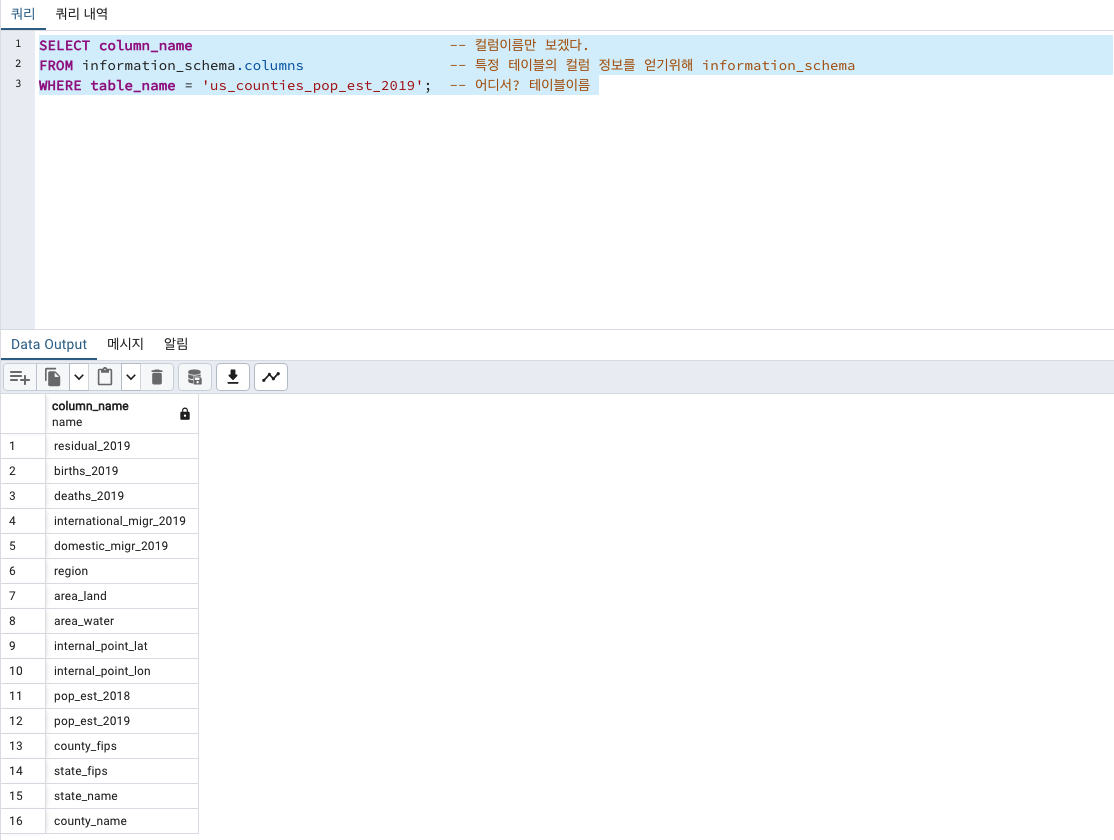
계산
출생자-사망자= 인구 증감
양수라면 해당 지역 또는 기간 동안의 인구가 증가하고,
음수라면 인구가 감소하는 것을 의미합니다.
출생인구 - 사망인구 = 인구 증감
births - deatchs = natural_increase
참고로 as 별칭으로 하게되면 에러발생되니, 번거롭더라도 기존 컬럼명으로 진행
SELECT
county_name as county -- 자치구
, state_name as state -- 지역
, pop_est_2019 as pop -- 인구
, births_2019 as births -- 출생인구
, deaths_2019 as deaths -- 사망인구
, international_migr_2019 as int_migr -- 국제 이주자
, domestic_migr_2019 as dom_migr -- 지역 이주자
, residual_2019 as residual -- 일관성을 위해 추정치를 조정하는 데 사용되는 숫자
, births_2019 - deaths_2019 as natural_increase
FROM us_counties_pop_est_2019; 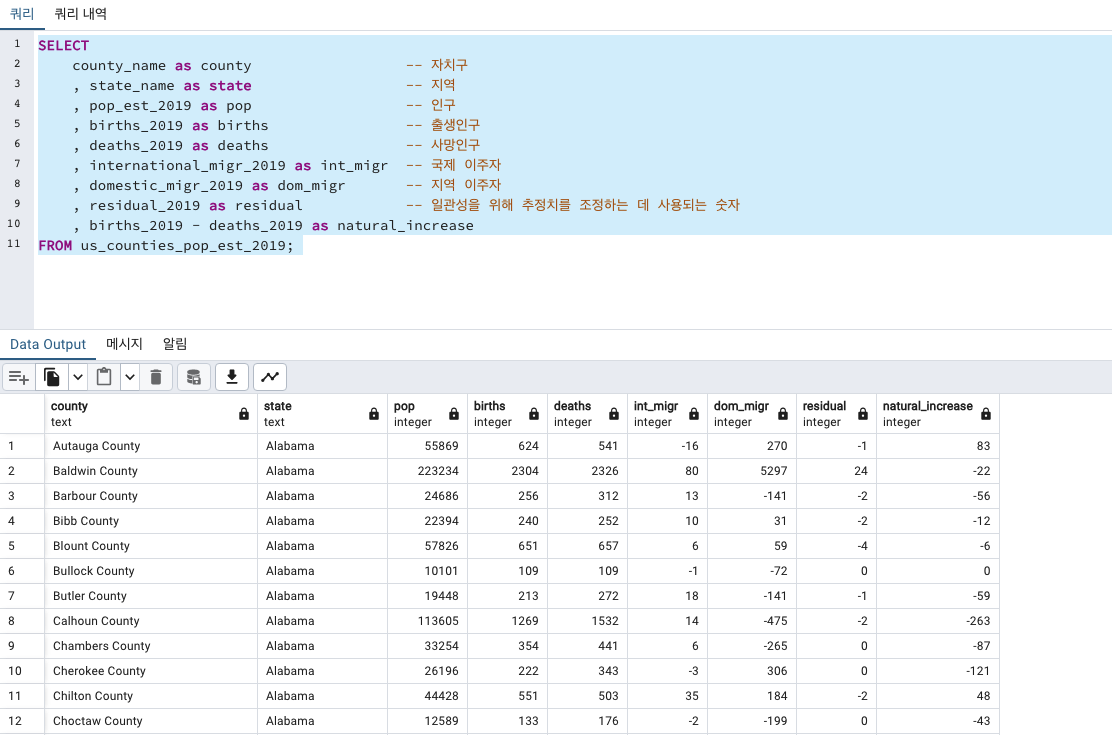
인구 증가지역 top
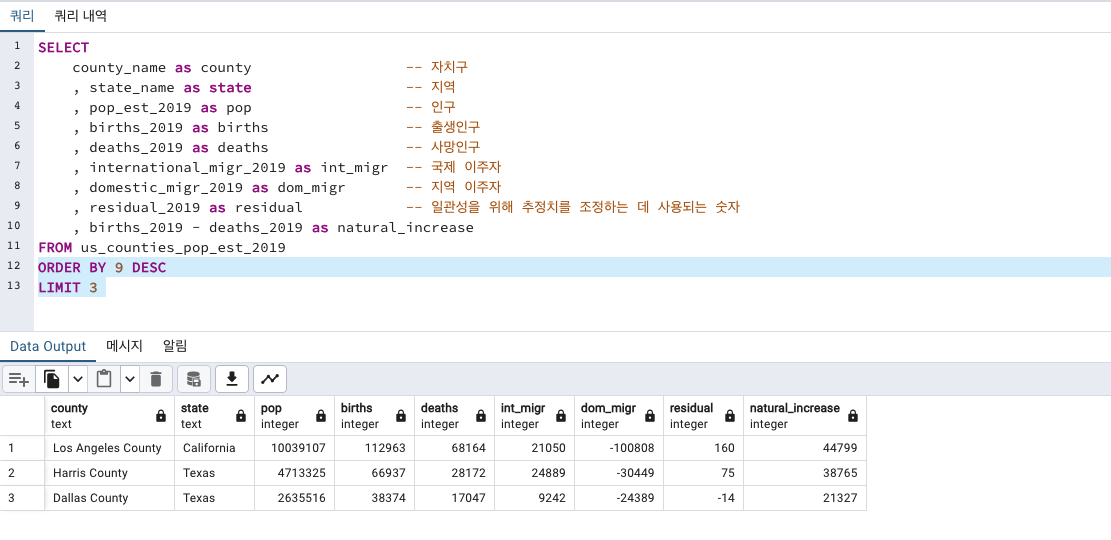
California가 가장 인구증가가 높으며, 그 다음 Texas가 높습니다.
인구 감소지역 top
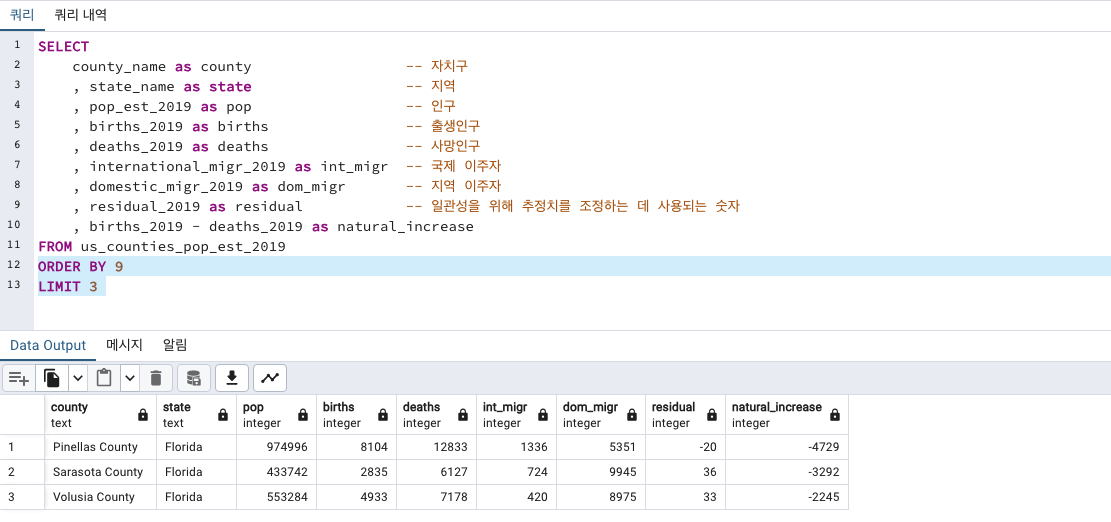
Florida가 인구감소가 많이 일어나는 지역입니다.
전체 백분율
물비중이 가장 적은 지역
물의 면적 / (토지 면적 + 물 면적) * 100
수치를 구해주기위해 분자인 물의면적을 numeric 형태로 해줘야 합니다.
cast(컬럼 as numeric) 해도 되고,
컬럼명 ::numeric 해도 됩니다.
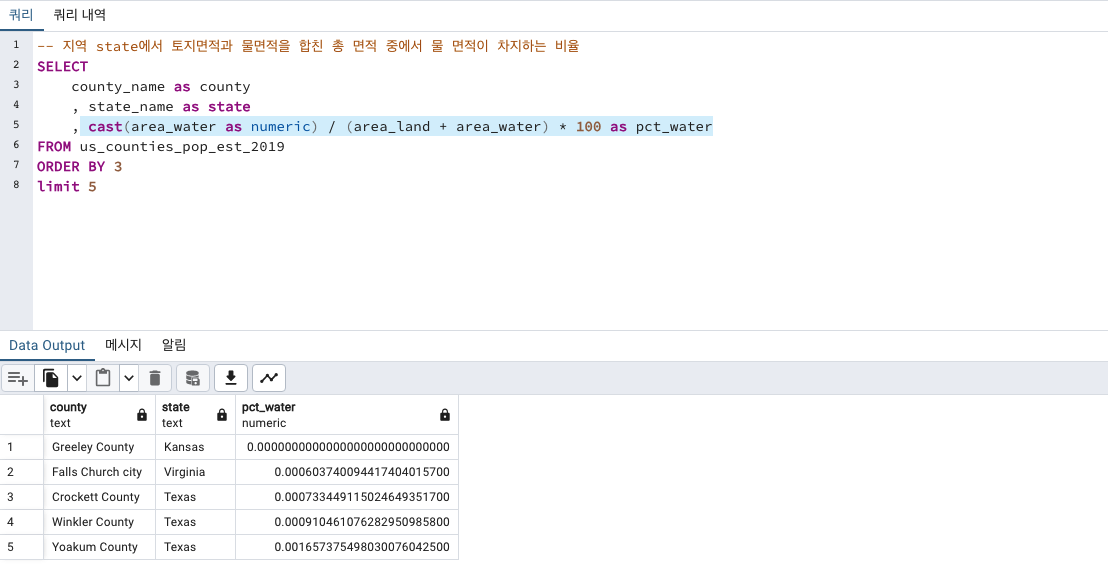
Kansas > Virginia > Texas 순으로 물이 없습니다.
물비중이 가장 많은 지역
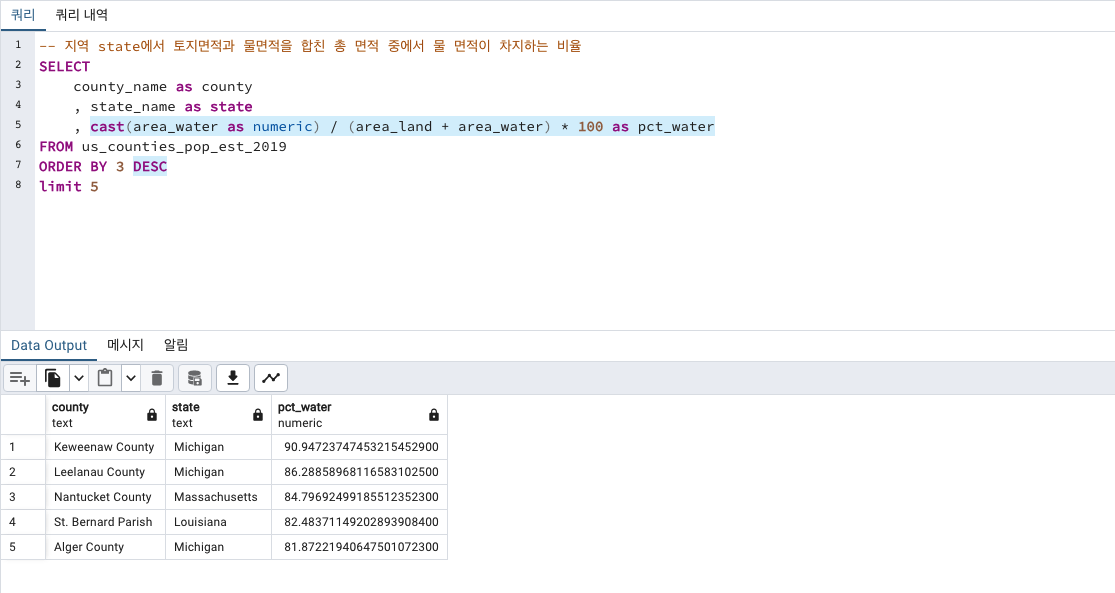
역시 미시간 호수가 있는 Michigan 지역이 가장 많군요
백분율인데 소수점이 너무 많습니다.
백분율 구하는 쿼리문을 round( 쿼리문 as는 비포함, 소숫점자리수) 함수를 사용해서 두번째 자리수까지 나오도록 반올림 하겠습니다.
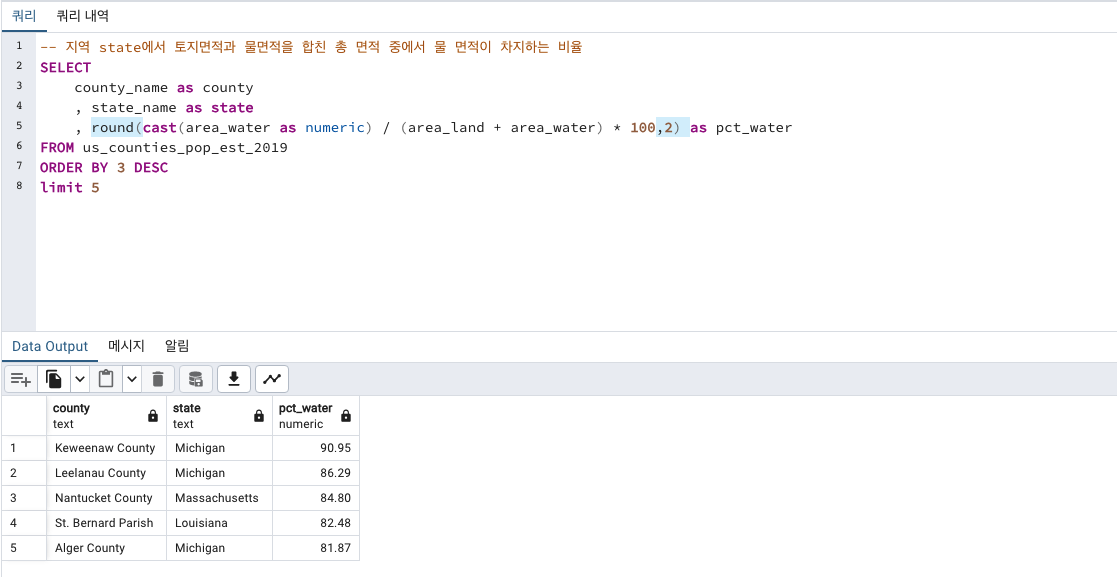
훨씬 보기 편한것 같습니다.
변화율
(최신 숫자 - 이전 숫자) / 이전 숫자 증감에 대한 변화율을 알 수 있습니다.
2018년 인구에 비해 2019년 인구가 얼마나 달라졌는지 확인해보겠습니다.

엥? 왜 다 수치가 0 으로 나오는걸까요?
테이블을 보면 pop2018과 pop2019 수치가 달라서 diff 값이 음수던 양수던 나와야 되는데 말이죠
생각해보니 분자를 numeric 형태로 해줘야 될 것 같습니다.
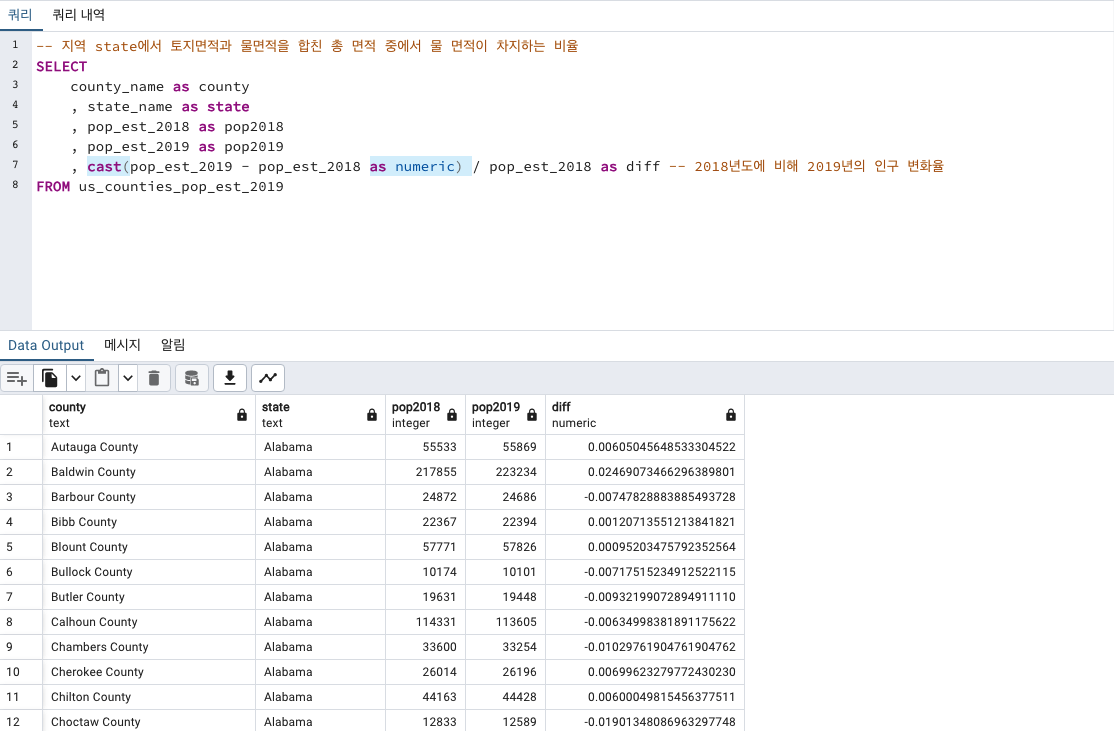
오 다행히 나옵니다!
백분율 등 소수점이 있는 정확한 수치를 나타내는 계산식에서는 분자를 꼭 numeric 형태로 해야하는것을 다음에도 잊지 않도록 합니다!
이제 round()로 소수점 3자리까지 반올림 한 뒤,
인구 변화율이 가장 높은곳과 낮은곳을 확인해보겠습니다.
인구가 증가한 지역
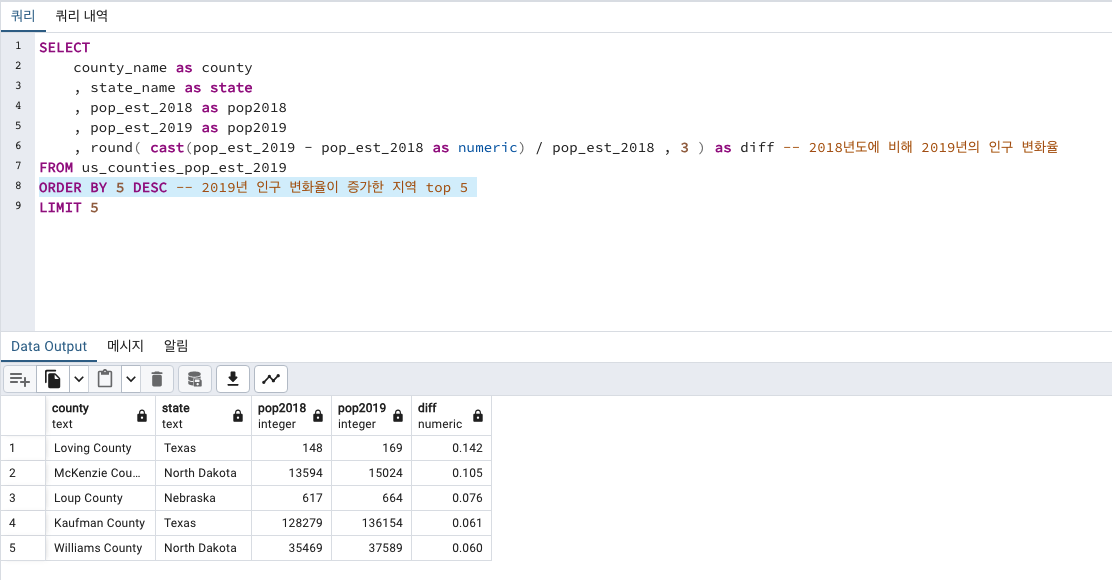
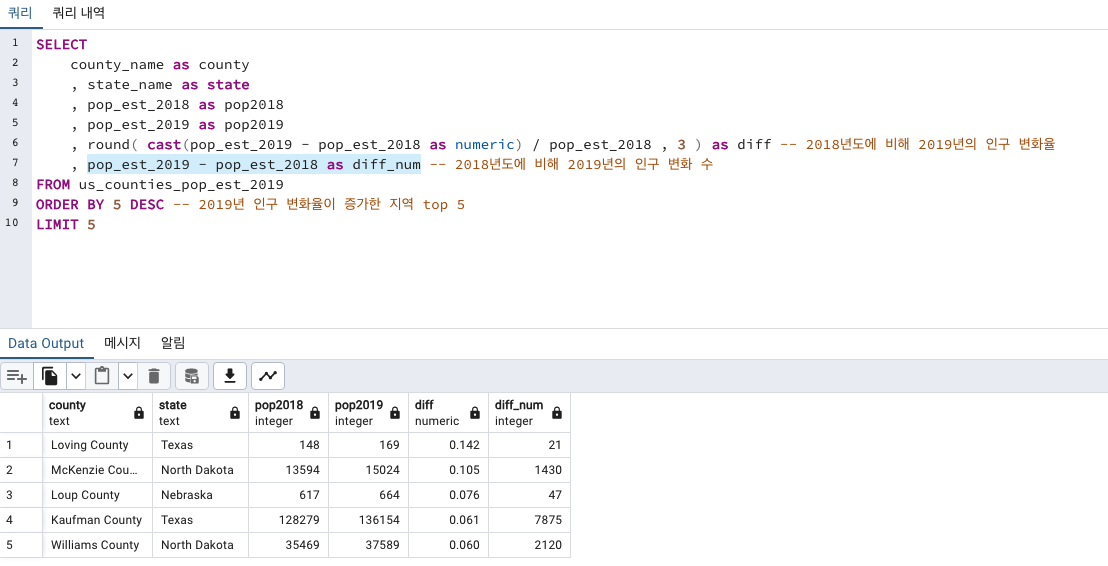
Texas > North Dakota > Nebraska 순서로 증가하였습니다.
사실 증가한 인구 수로만 봤을때엔 Texas에서도 Loving County보단 Kaufman County 가 더 많네요!
인구가 감소한 지역

비중으로 봤을 때엔 Florida주의 Gulf County 지역이 가장 감소 했습니다.
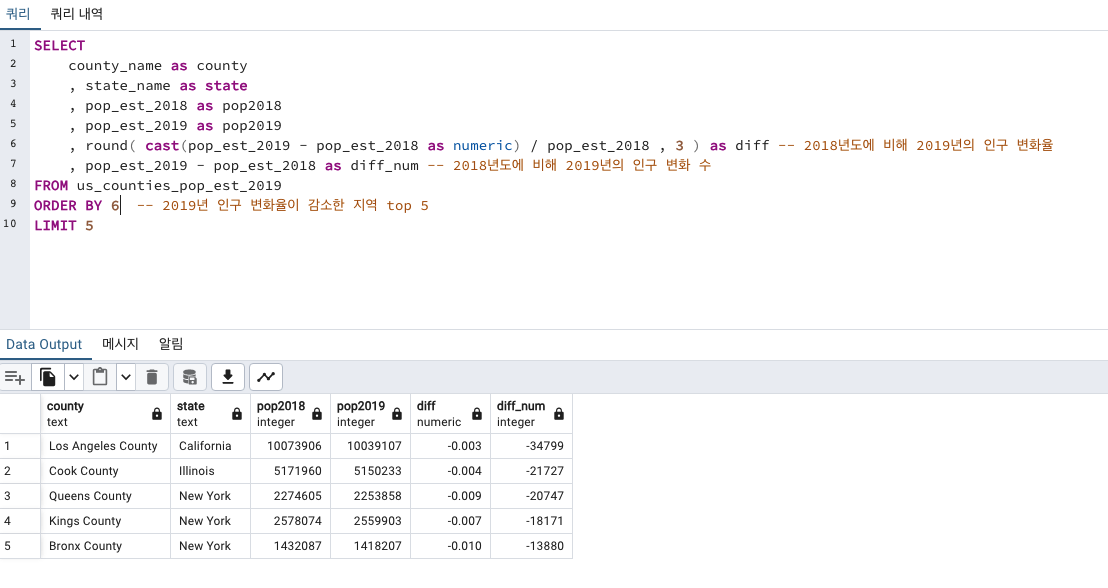
하지만 단순 수량으로 봤을 땐 California의 Los Angeles County 지역의 감소 인원 수가 가장 많네요! 아무래도 그만큼 인구가 많은 상업 도시라서 그런가 봅니다! 비중은 0.003 밖에 감소를 안했어요!
합계와 평균
실수
SELECT
county_name as county
, state_name as state
, sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
, avg(pop_est_2019) as county_avg -- 2019년 인구 수 평균
FROM us_counties_pop_est_2019;엥? 에러가 납니다!
ERROR: column "us_counties_pop_est_2019.county_name" must appear in the GROUP BY clause or be used in an aggregate function
LINE 2: county_name as countysum(), avg()처럼 집계함수를 쓸 때엔
집계함수를 사용하지 않은 컬럼들을 GROUP BY로 사용해줘야 합니다!
SELECT
county_name as county
, state_name as state
, sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
, avg(pop_est_2019) as county_avg -- 2019년 인구 수 평균
FROM us_counties_pop_est_2019
GROUP BY 1,2 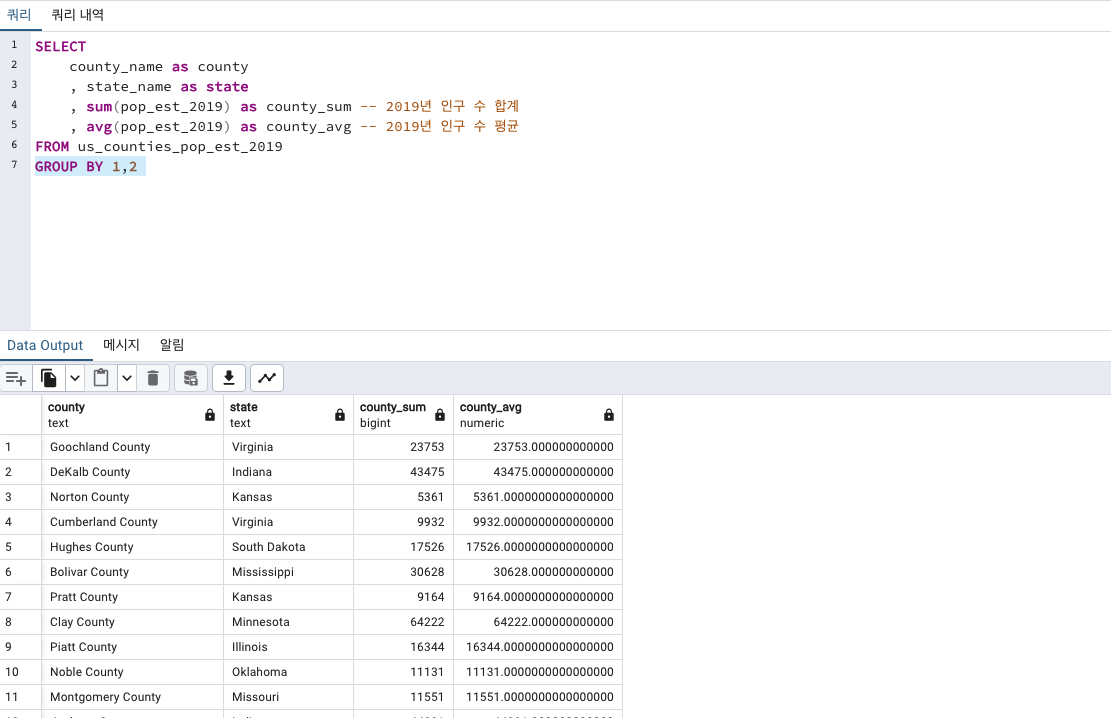
다행히 잘 나옵니다! 평균수치를 소수점이 없게 반올림하겠습니다.
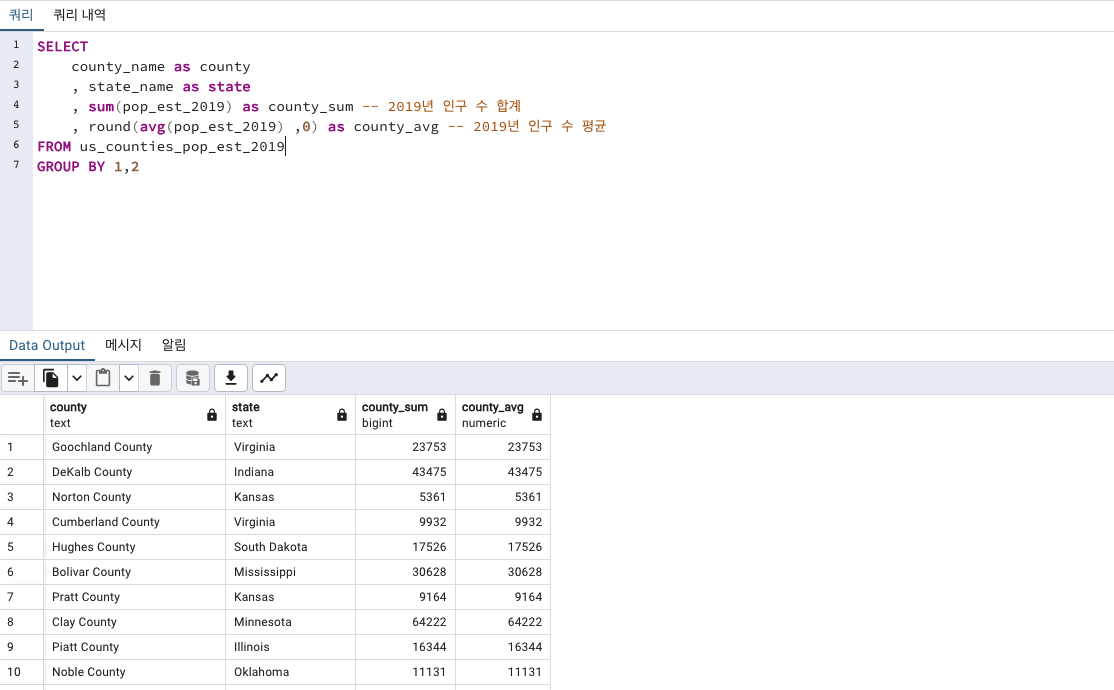
다만 바보같이! 각 하나의 row는 하나의 집계를 나타내기에 합계와 평균이 같을 수 밖에 없습니다!
주의
제가 알고 싶은건 "2019년 인구 수" 에 대한 합계와 평균입니다.
그렇다면 county_name, state_name같은 쓸데없는 컬럼은 필요가 없습니다!
이 두 쓸모없는 컬럼은 SELECT 절에서 제외하고, GROUP BY 절에서도 제외하겠습니다!
SELECT
sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
,round(avg(pop_est_2019) ,0) as county_avg -- 2019년 인구 수 평균
FROM us_counties_pop_est_2019훨씬 간편하고 올바른 수치 입니다!
그렇다면 2019년 인구수 합계와 2018년 인구수 합계의 차이는요?
그리고 평균의 차이또한 구해보겠습니다.
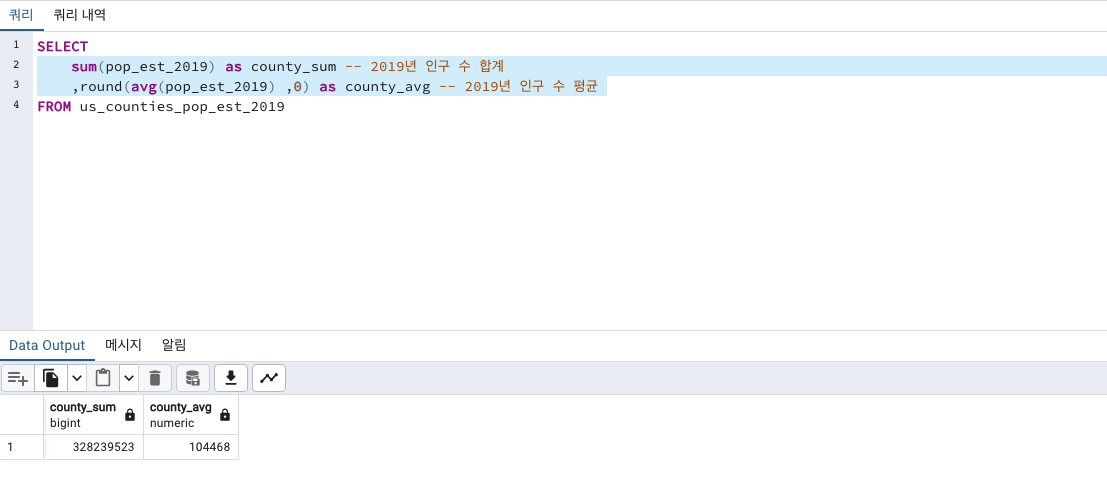
SELECT
sum(pop_est_2019) - sum(pop_est_2018) as sum_diff
, round(avg(pop_est_2019) ,0) - round(avg(pop_est_2018) ,0) as avg_diff
FROM us_counties_pop_est_2019오~ 2019년 인구수의 평균과 합계 모두 2018년에 비해 수치가 증가했군요!
중앙값과 백분위수
평균은 이상치가 있을 경우 정확한 값을 확인하기 어렵습니다.
(너무 수치가 큰 몇몇의 지역들때문에 인구 수 평균 등이 훅훅 올라가니깐요!)
평균(age)과 중앙값(media)은 가까울 수록 정규분포를 따르고 있어서 평균 수치에 대해 신뢰할 수 있습니다.
하지만 평균과 중앙값이 멀리 떨어져 있다면 중앙값을 신뢰하는게 좋습니다.
percentile_cont()within group()
세상에나! SQL 에서는 왜 중앙값을 구할때 이렇게 긴지 이해가 안되는군요!
percentile_cont(.수치) within group (order by 컬럼명)
혹시나 median(컬럼명이나 수치) 함수로 가능한지 검색했는데 안되는것 같습니다.
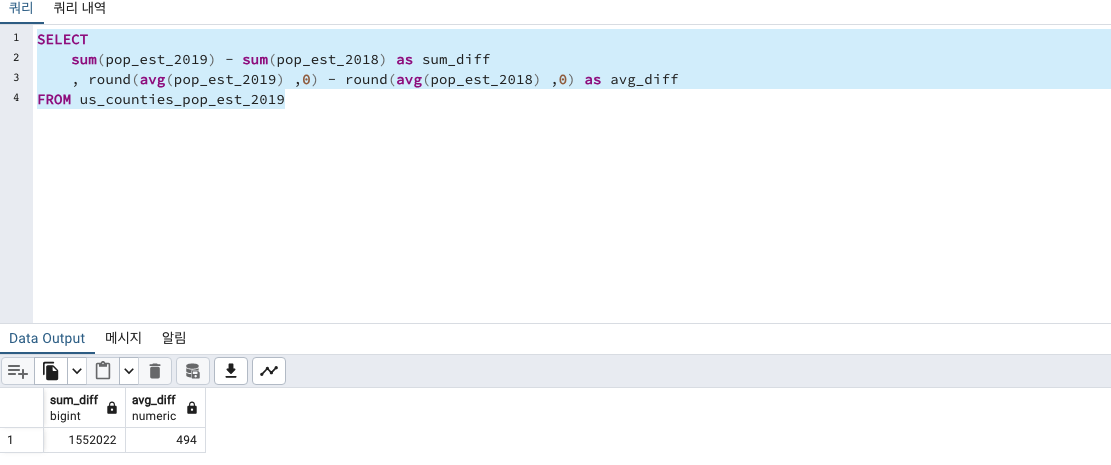
SELECT
sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
, round(avg(pop_est_2019), 0) as county_avg -- 2019년 인구 수 평균
, percentile_cont(.5) WITHIN GROUP (ORDER BY pop_est_2019) as county_median
-- , median(pop_est_2019) as county_median_short -- error
-- , median(cast(pop_est_2019 as numeric)) as count_median_short -- error
--, median(cast(pop_est_2019 as numeric), .5) as count_median_short -- error
FROM us_counties_pop_est_2019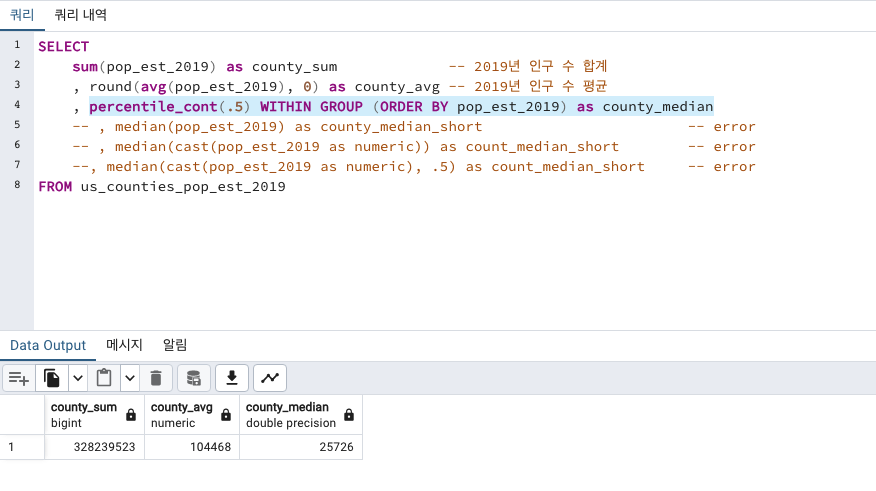
평균이 104468이고
중앙값 25726이면 꽤 차이가 나는것 같습니다.
인구 수가 엄~~~청 큰 일부 지역 덕분에 평균이 저렇게 엄청 높아졌습니다.
1분위수, 3분위수 값
그렇다면 미국 지역 별 2019년 인구 수치에 대해서
1분위(25%)와 2분위(50%) 그리고 3분위(75%) 수치를 구해보겠습니다.
3분위 수치값을 구해서, 그 값보다 넘어가면 아무래도 인구 수가 많은 상위권 지역이라고 생각할 수 있으니깐요!
SELECT
sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
, round(avg(pop_est_2019), 0) as county_avg -- 2019년 인구 수 평균
, percentile_cont(.25) WITHIN GROUP (ORDER BY pop_est_2019) as county_25 -- 1분위수
, percentile_cont(.5) WITHIN GROUP (ORDER BY pop_est_2019) as county_50 -- 2분위수
, percentile_cont(.75) WITHIN GROUP (ORDER BY pop_est_2019) as county_75 -- 3분위수
FROM us_counties_pop_est_2019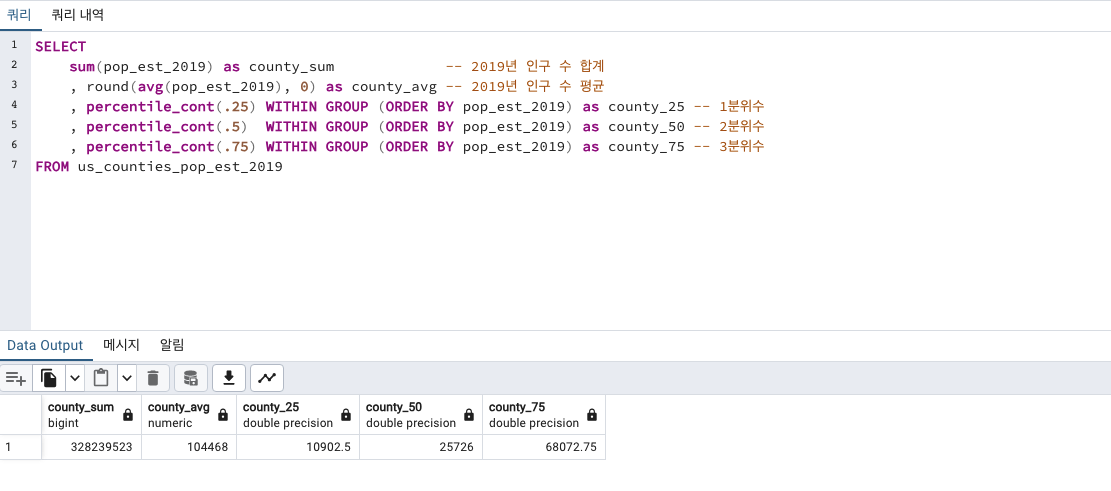
이렇게 할 수도 있고! 배열 array[,,,] 를 이용할 수도 있습니다.
SELECT
sum(pop_est_2019) as county_sum -- 2019년 인구 수 합계
, round(avg(pop_est_2019), 0) as county_avg -- 2019년 인구 수 평균
-- , percentile_cont( .25 ) WITHIN GROUP (ORDER BY pop_est_2019) as county_25
, percentile_cont(ARRAY[ .25 , .5 , .75]) WITHIN GROUP (ORDER BY pop_est_2019) as quartiles
FROM us_counties_pop_est_2019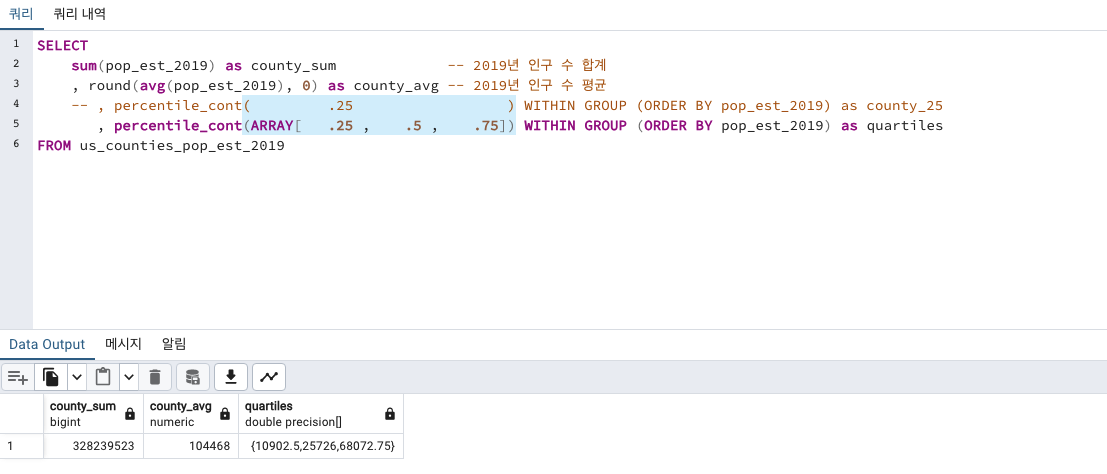
1분위수 10902.5 (하위25%)
2분위수 25726 (딱 중간)
3분위수 68072.75 입니다. (상위 25%)
2019년 인구 수 상위 25% 지역
SELECT
county_name as county -- 자치구
, state_name as state -- 지역
, pop_est_2019 -- 2019년 인구
FROM us_counties_pop_est_2019
WHERE pop_est_2019 >= 68072.75 -- 상위 25% 수치
ORDER BY 3 DESC 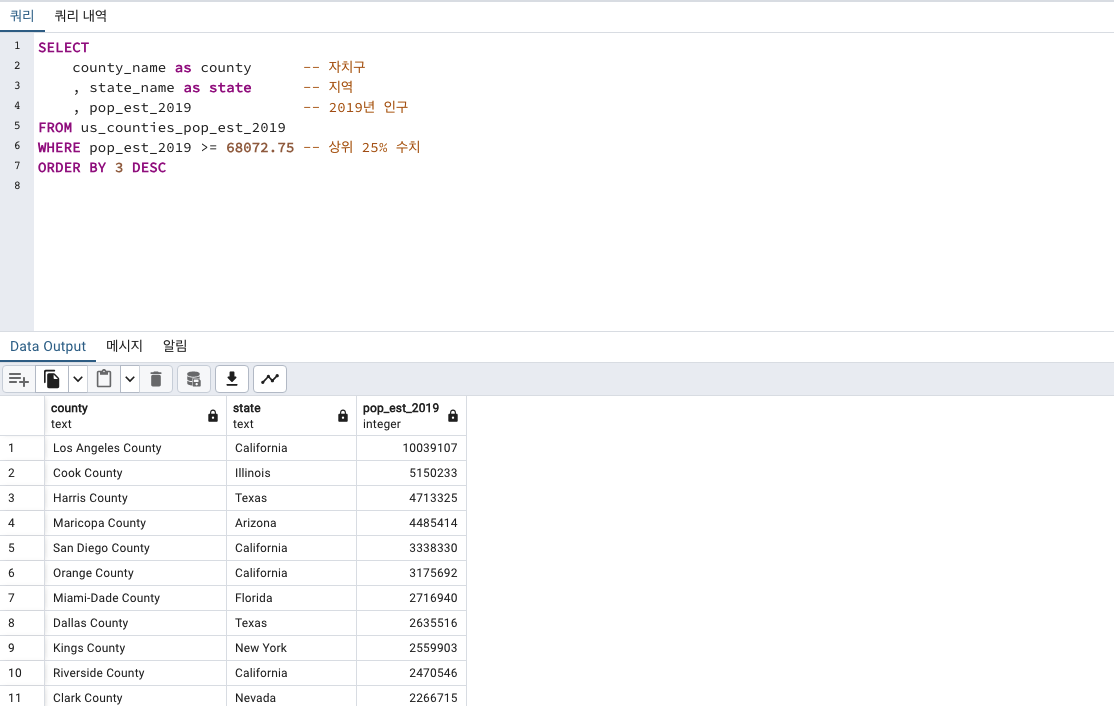
혹시 여기서 상위 25%를 나타내는 68072.75 수치를 다른 방식으로 작성할 순 없을까요?
68072.75
= percentile_cont(.75) WITHIN GROUP (ORDER BY pop_est_2019) as county_75
인데 말입니다!
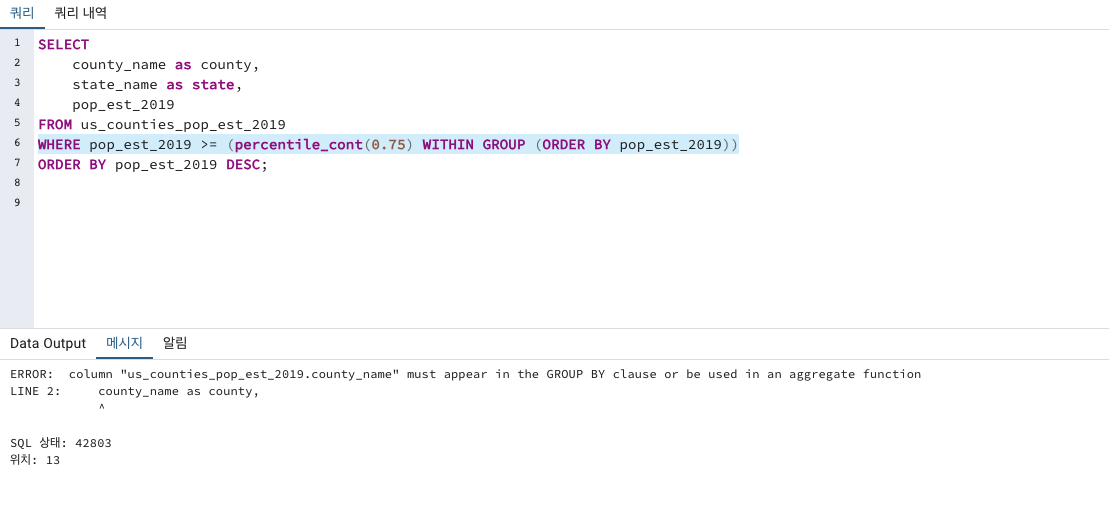
안되는것 같습니다! (괄호)를 치나 안치나 에러가 나는군요!
배열(가로형)->행(세로형)
백분위수 25%, 50%, 75% 를 각각 구하는데 {}괄호로 배열형태로 나와있어 보기에 깔끔하지 않습니다.
세로 형태로 출력해주느 unnest() 을 사용해보겠습니다.
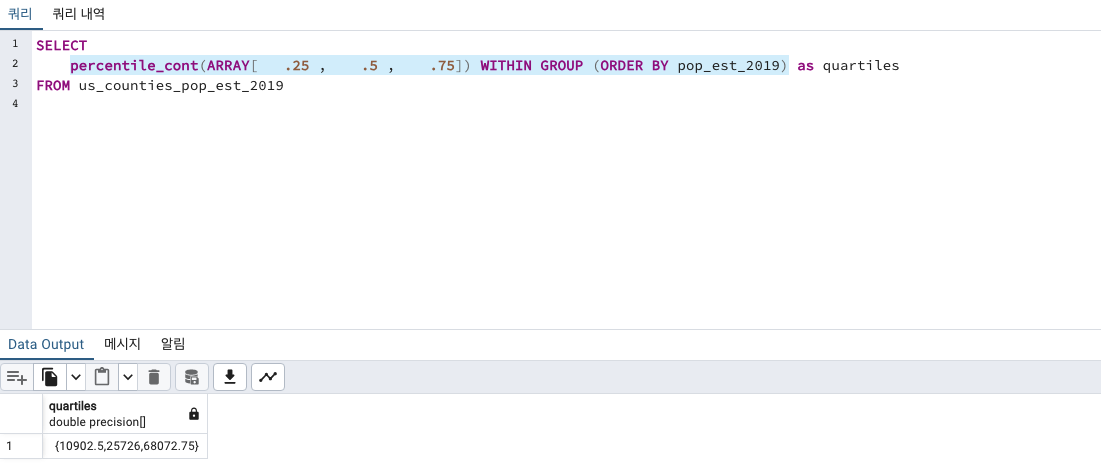
UNNEST()
SELECT
unnest(
percentile_cont(ARRAY[ .25 , .5 , .75]) WITHIN GROUP (ORDER BY pop_est_2019)
)
as quartiles
FROM us_counties_pop_est_2019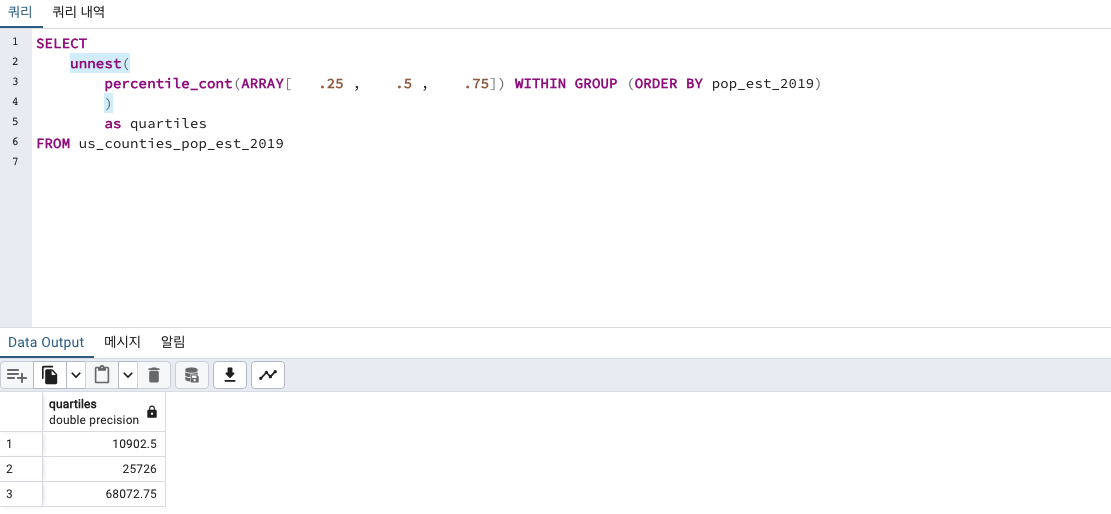
보기에 훨씬 깔끔한 것 같습니다.
문제
원의 면적 구하기
반지름이 5인치인 원의 면적을 계산하는 쿼리문 작성
(반지름^2) * 파이율 3.14
-- 반지름이 5인치인 원의 면적
-- 반지름의 제곱근 * 파이 3.14
SELECT 5^2 * 3.14딱 78.5 가 나온다.
인터넷 검색해보니 POW(반지름, 제곱근) * PI() 를 이용해서 구할 수 있다.
-- 정확한 파이(π) 값을 사용하여 원의 면적 계산
SELECT POW(5, 2) * PI() as pi;78.53981633974483 가 나온다. 신기하다
뉴욕주 각 카운티 출생 대비 사망비율
출생 대비 사망 비율 = 사망자 수 / 출생자 수
먼저 뉴욕주가 어떻게 표기되어있는지 확인하겠습니다.
New York City ?
New York ?
-- 뉴욕주에 한해서 찾아야 하니까, 뉴욕주가 어떻게 표기되어있는지 먼저 확인
SELECT DISTINCT state_name
FROM us_counties_pop_est_2019
WHERE state_name ilike '%new%'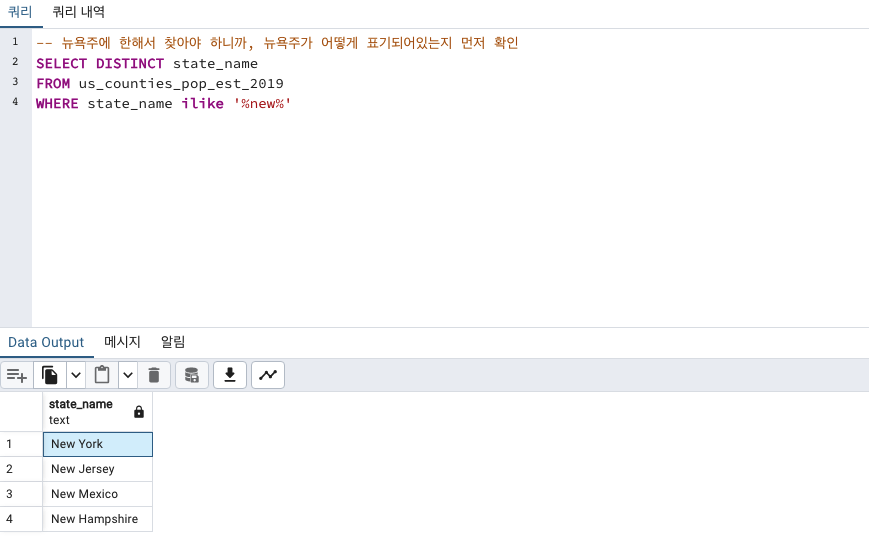
그렇다면 이제 WHERE state_name = "New York" 필터링을 걸면 되겠군요
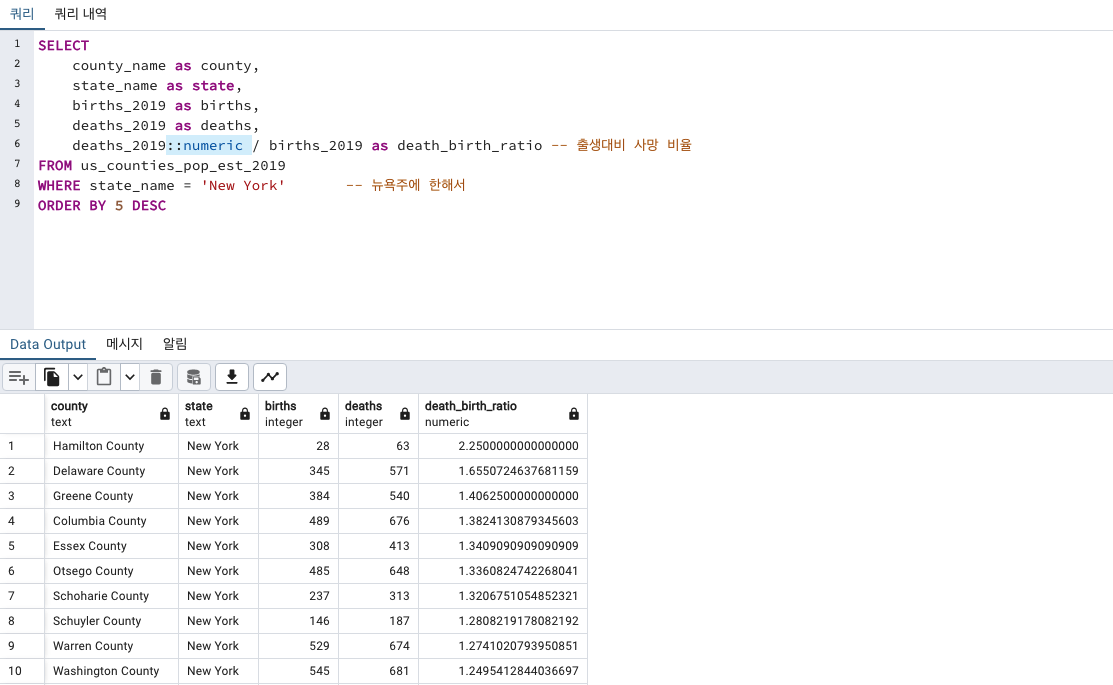
SELECT
county_name as county,
state_name as state,
births_2019 as births,
deaths_2019 as deaths,
deaths_2019 / births_2019 as death_birth_ratio -- 출생대비 사망 비율
FROM us_counties_pop_est_2019
WHERE state_name = 'New York' -- 뉴욕주에 한해서
ORDER BY 5 DESC -- 높은 순서 대로 
New York 주 안에서는 Hamilton County가 사망자 비율이 높습니다.
혹시 몰라서 ::numeric 으로도 보겠습니다.
그렇다면 사망대비 출생비율은요?
그냥 ORDER BY 5 DESC 에서 DESC 를 빼줍니다.
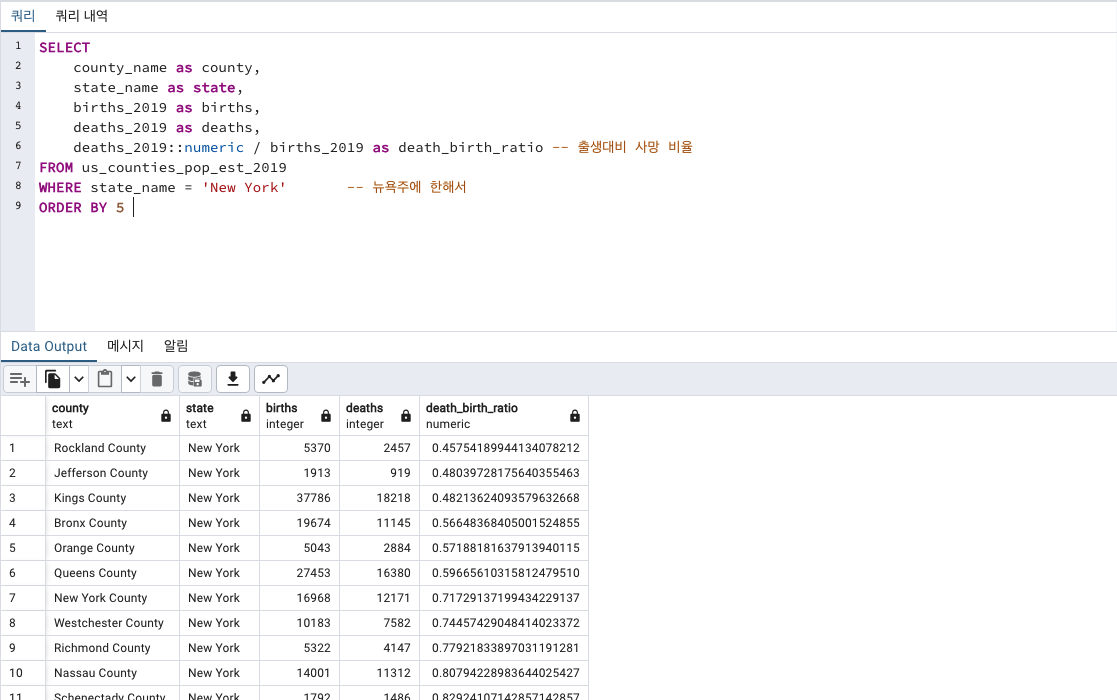
New York 안에서는 Rockland County 가 사망자 비율이 낮습니다.
뉴욕과 캘리포니아의 인구 중앙값 비교
우선 다시한번 state_name 이름을 확인합니다.
-- 지역명 확인
SELECT DISTINCT state_name
FROM us_counties_pop_est_2019;
-- 뉴욕 state_name = 'New York'
-- 캘리포니아 state_name = 'California'
-- 하와이 state_name = 'Hawaii'먼저 뉴욕주의 인구수 중앙값을 확인합니다.
SELECT
percentile_cont(.5) WITHIN GROUP (ORDER BY pop_est_2019) as county_50 -- 2분위수
FROM us_counties_pop_est_2019
WHERE state_name = 'New York' 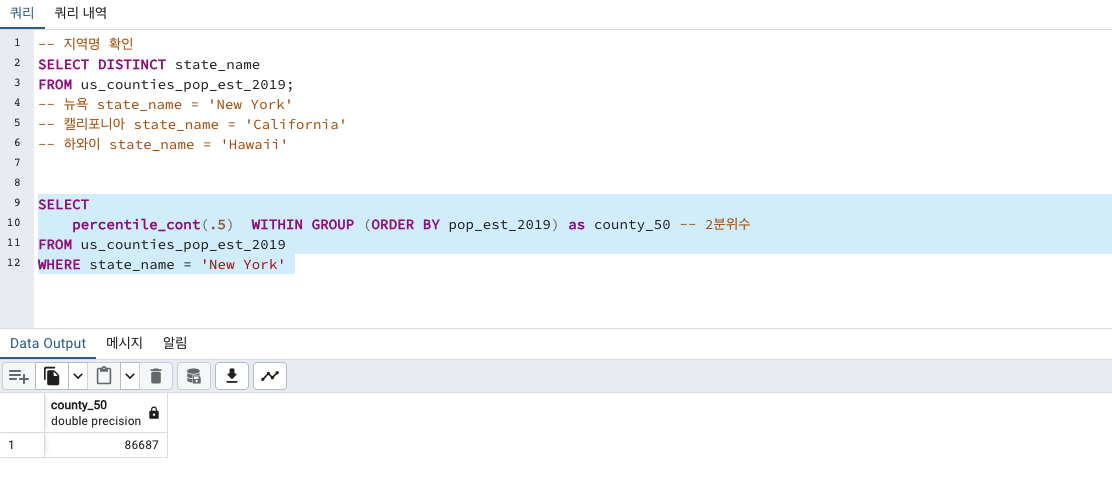
뉴욕의 2019년 인구 수 중앙값은 86687 이군요
물론 뉴욕, 캘리포니아 이렇게 2열 2행으로 결과물이 출력되게 나오면 좋겠지만
사실 거기까진 복잡해지는 것같습니다.
CASE WHEN 등을 사용해서 하나씩 주마다 필터를 걸어 구할수도 있겠지만
일단 지금은 하나씩 비교해보겠습니다.
SELECT
percentile_cont(.5) WITHIN GROUP (ORDER BY pop_est_2019) as county_50 -- 2분위수
FROM us_counties_pop_est_2019
-- WHERE state_name = 'New York' -- 86687
-- WHERE state_name = 'California' -- 187029
WHERE state_name = 'Hawaii' -- 167417 어라 생각보다 뉴욕의 인구수 중앙값이 적습니다!
캘리포니아와 하와이의 절반밖에 안됩니다!
SELECT
sum(pop_est_2019),
sum(pop_est_2018),
sum(pop_est_2019 + pop_est_2018)
FROM us_counties_pop_est_2019
WHERE state_name = 'New York' -- 86687 중앙값 38983912 2018년과 2019년의 합계
-- WHERE state_name = 'California' -- 187029 중앙값 , 78973811 2018년과 2019년의 합계
-- WHERE state_name = 'Hawaii' -- 167417 중앙값 , 2836465 2018년과 2019년의 합계 엥? 뭐죠!
중앙값으로 했을땐 뉴욕주가 작았는데
합계로 하니 캘리포니아보단 작지만 하와이보단 더 많습니다!
아무래도 하와이는 뉴욕주에 비해 지역이 많지도 않으며, 그에 따라 인구 수의 편차가 크지 않아서 중앙값이 높은 것 같습니다.
