[PostgreSQL실용]_7_키지정(CONSTRAINT,REFERENCES)과 테이블 병합 (JOIN ON/USING, UNION, INTERSECT, EXCEPT의 차이)
데이터베이스(SQL)
SELECT*
FROM테이블1JOIN테이블2
ON테이블1.컬럼1 = 테이블2.컬럼1

가상 테이블 생성
CREATE TABLE 테이블명1 ( 컬럼명1 타입, 컬럼명2 타입, 컬럼명3 타입, CONSTRAINT 가상테이블명1 PRIMARY KEY (컬럼명1), CONSTRAINT 가상테이블명2 UNIQUE (컬럼명2, 컬럼명3), 컬럼명4 타입 REFERENCES 테이블명2 (테이블명2의 컬럼명만) );
CCONSTRAINT제약조건이름(아무거나가능)PRIMARY KEY기준컬럼명
PRIMARY KEY 를 지정할 기준컬럼명에 대한 제약조건을 거는 쿼리입니다.CONSTRAINT제약조건이름아무거나UNIQUE(컬럼1, 컬럼2)
( ) 안의 조합이 중복되지 않고 고유해야 합니다.- 컬럼명 타입
REFERENCES다른테이블명 (다른테이블의 컬럼명)
해당 컬럼은 다른테이블 컬럼과 일치하다. PrimaryKey를 가져오는 외래키이기 때문에 이 경우 중복되거나 비어있어도 된다고 합니다.
Primary Key (기본 키)는 고유하게 식별하는 열 입니다.
결측값 X
중복값 X
Primary Key 를 가져오는 외래키 (위의 References)
결측값 O
중복값 O
공공기관의 부서별 급여 지출을 확인하는 데이터를 만들어보겠습니다.
부서관련 테이블 + 급여관련 테이블
CREATE TABLE departments (
dept_id integer,
dept text,
city text,
CONSTRAINT dept_key PRIMARY KEY (dept_id),
CONSTRAINT dept_city_unique UNIQUE (dept, city)
);
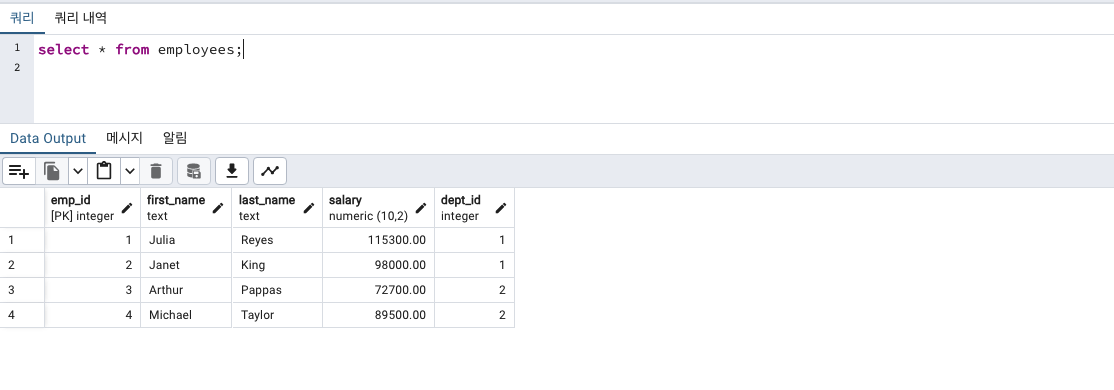
CREATE TABLE employees (
emp_id integer,
first_name text,
last_name text,
salary numeric(10,2),
dept_id integer REFERENCES departments (dept_id),
CONSTRAINT emp_key PRIMARY KEY (emp_id)
);
INSERT INTO departments
VALUES
(1, 'Tax', 'Atlanta'),
(2, 'IT', 'Boston');
INSERT INTO employees
VALUES
(1, 'Julia', 'Reyes', 115300, 1),
(2, 'Janet', 'King', 98000, 1),
(3, 'Arthur', 'Pappas', 72700, 2),
(4, 'Michael', 'Taylor', 89500, 2);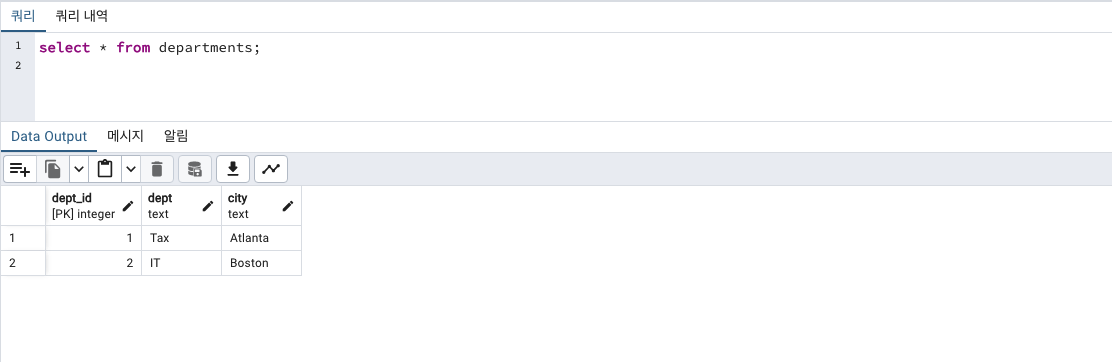
CONSTRAINT 제약조건명 PRIMARY KEY (컬럼명)
이렇게 고유한 PK키가 되는 컬럼은 [PK]라고 표시됩니다!
특성에 따른 테이블
처음부터 데이터베이스의 데이터를 테이블로 저장할때,
하나의 테이블로 한꺼번에 저장하면 좋겠지만
수천개 수만개의 데이터의 경우 각 특성에 따라 테이블을 나누어 저장하는게 좋습니다.
- 데이터가 늘어날 수록 중복되는 긴 문자열을 저장하는데 소모되는 공간 낭비됨
- 관련없는 데이터를 한 테이블에 넣게 된다면 오류 및 관리가 어려움
조인
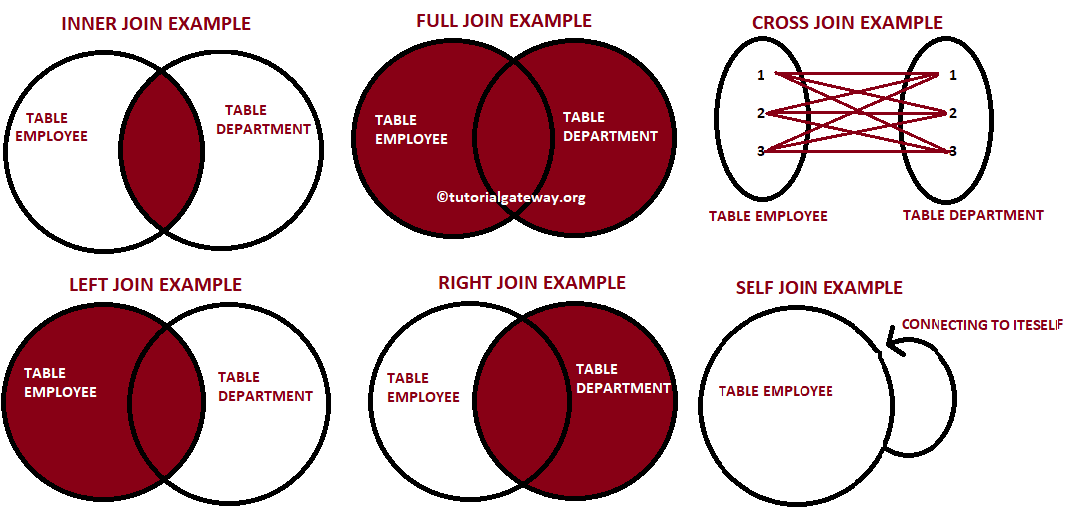
Join, Inner Join
SELECT *
FROM 테이블1 JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼1
ORDER BY 기준되는테이블.컬럼1
select *
FROM employees JOIN departments
ON employees.dept_id = departments.dept_id
ORDER BY employees.dept_id;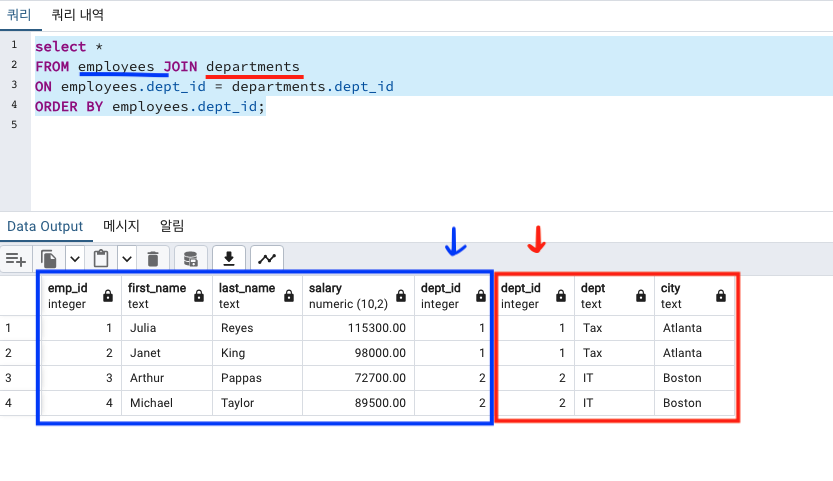
똑같은 컬럼이 2개가 되어 붙었습니다.
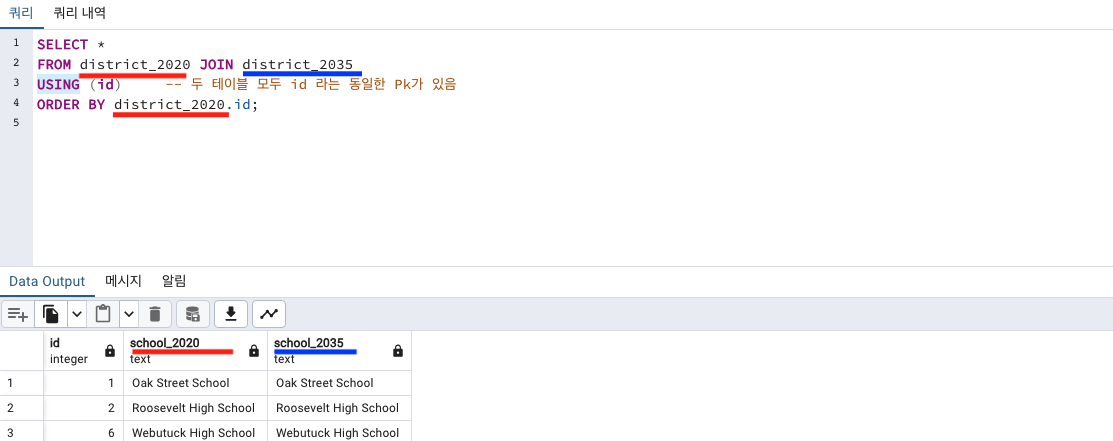
어자피 똑같은 컬럼인데 1개로만 나오게 하고싶은 경우 JOIN ON 이 아닌, JOIN USING 을 사용해야 합니다. 대신 두 컬럼의 이름이 같아야합니다.
JOIN 테이블 USING (컬럼)
JOIN, LEFT JOIN, LIGHT JOIN 등에서 사용될 수 있습니다.
SELECT *
FROM 테이블1 JOIN 테이블2
ON (테이블1과 테이블2의 동일한 컬럼명1)
또는ON (테이블1과 테이블2의 동일한 컬럼명1,컬럼명2,,)로 여러개의 컬럼 지정 가능
ORDER BY 기준되는테이블.컬럼1
select *
FROM employees JOIN departments
USING (dept_id)
ORDER BY employees.dept_id;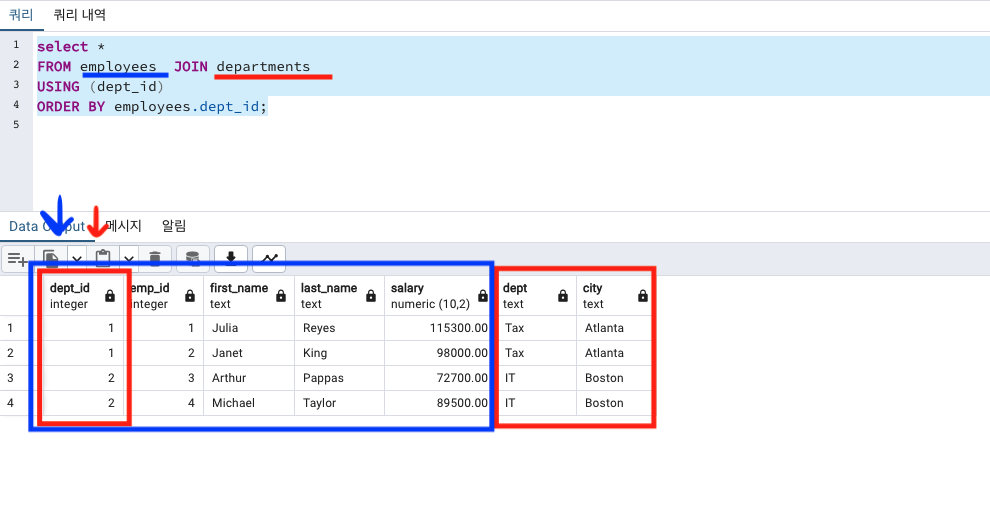
CROSS JOIN
중복되는지는 상관 없고, 두 테이블의 각 행을 정렬하여 모든 행의 조합
두 테이블의 동일한 컬럼을 찾을 필요가 없어 ON 이 없습니다.
방대한 두 테이블을 크로스조인으로 합칠경우 과부하가 걸릴 수 있으니 주의해야 합니다.
SELECT *
FROM 테이블1 JOIN 테이블2
ORDER BY 기준되는테이블.컬럼1
결측치
참고로 0 또는 '' 이렇게 빈 문자열과
결측치 Null값은 다릅니다!
- 결측치 Null값은 데이터 타입에도 사용할 수 있습니다.
- NULL은 데이터가 없음을 명시적으로 나타내기 때문에 0이나 빈 문자열과는 구분됩니다.
NULL일 경우, 그 값은 정의되지 않았거나 존재하지 않음을 나타내게 됩니다.
결측값 확인
SELECT
FROM 테이블1 JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼1
WHERE 테이블2.컬럼1 IS NULL;
테이블2의 컬럼1이 결측치가 있는 모든 열만 불러옵니다.
결측치있는 테이블 생성
CREATE TABLE departments_null (
dept_id integer,
dept text,
city text,
CONSTRAINT dept_key_null PRIMARY KEY (dept_id),
CONSTRAINT dept_city_unique_null UNIQUE (dept, city)
);
CREATE TABLE employees_null (
emp_id integer,
first_name text,
last_name text,
salary numeric(10,2),
dept_id integer REFERENCES departments (dept_id),
CONSTRAINT emp_key_null PRIMARY KEY (emp_id)
);
INSERT INTO departments_null
VALUES
(1, 'Tax', 'Atlanta'),
(2, 'NULL', 'Boston');
INSERT INTO employees_null
VALUES
(1, 'Julia', 'Reyes', 115300, 1),
(2, 'NULL', 'King', 98000, 1),
(3, 'Arthur', 'Pappas', NULL, 2),
(4, 'Michael', 'NULL', 89500, 2);
결측치있는 테이블 조인
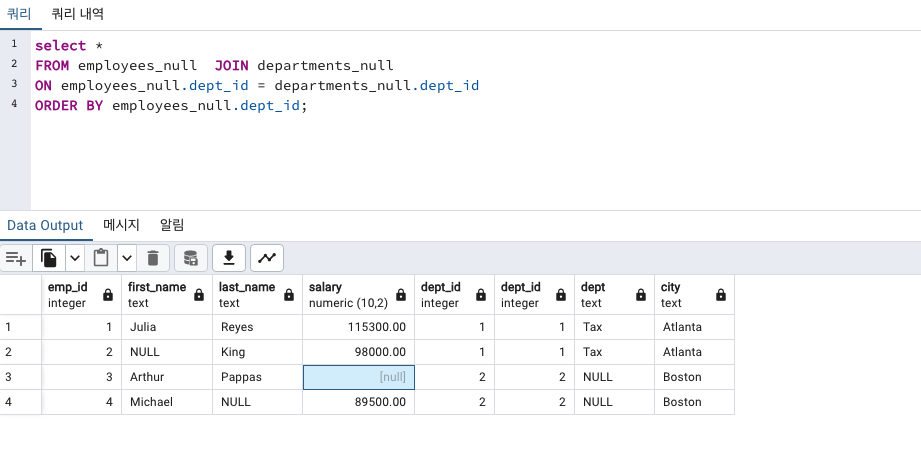
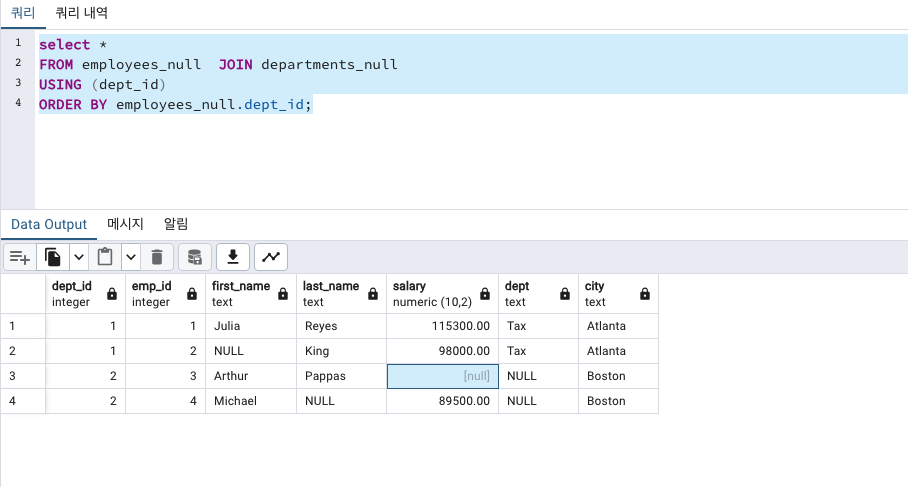
결측치있는 행 찾기
SELECT
FROM 테이블1 JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼1
WHERE 테이블2.컬럼1 IS NULL;
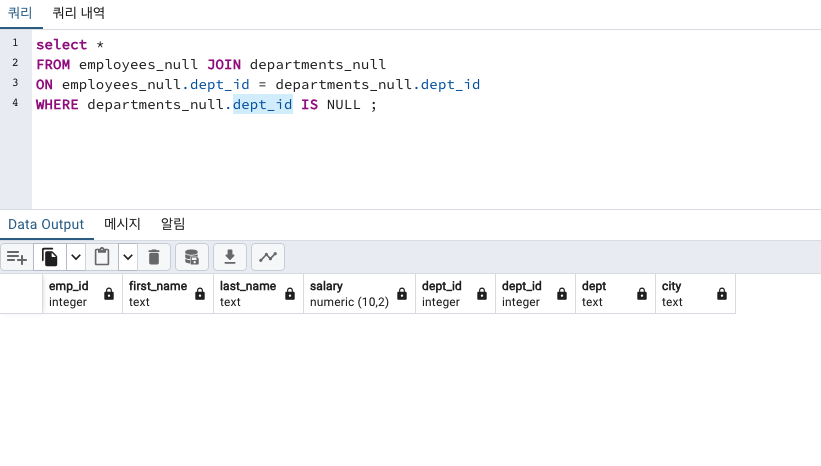
아무것도 안나옵니다!
당연합니다!
departments_null 테이블의 dept_id 컬럼에는 결측값이 없으니깐요!
결측값은 employees_null테이블의 salary 컬럼에 하나 있었습니다.
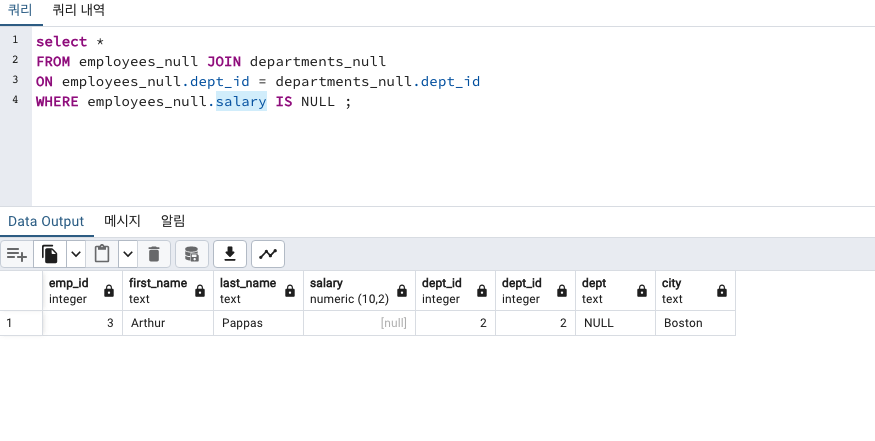
다행히 하나의 row만 잘 나옵니다!
일부 컬럼만
SELECT 테이블1.컬럼1
SELECT
컬럼1
테이블1.컬럼1 as 별칭1,
테이블1.컬럼3 ,
테이블2.컬럼4
FROM 테이블1 JOIN 테이블2
ON 테이블1.컬럼1 = 테이블2.컬럼1
SELECT 다음에 컬럼명만 작성하면 어떤 테이블의 컬럼인지 인식하지 못하는 경우가 있습니다. (여러테이블에서 동일한 이름의 컬럼이 있을 경우)
as로 단순화
SELECT
별칭1.컬럼1 ,
별칭2.컬럼2
FROM 테이블1 as 별칭1 JOIN 테이블2 as 별칭2
ON 별칭1.컬럼1 = 별칭2.컬럼1
FROM에는 정확한 테이블 명과 그에 따른 별칭을 적어줘야 합니다.
그 외에는 별칭만 적어줘도 됩니다.
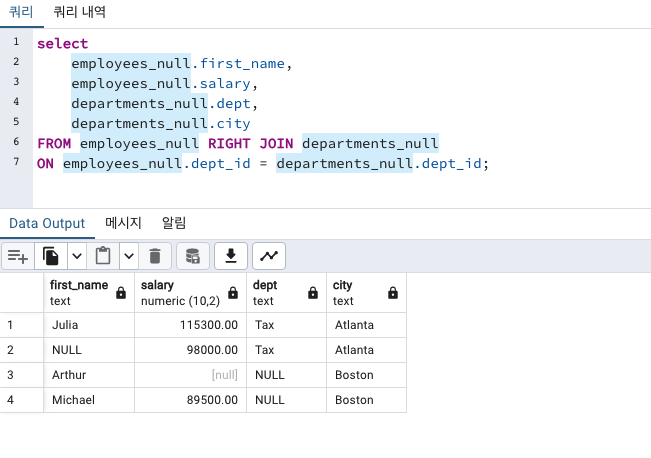
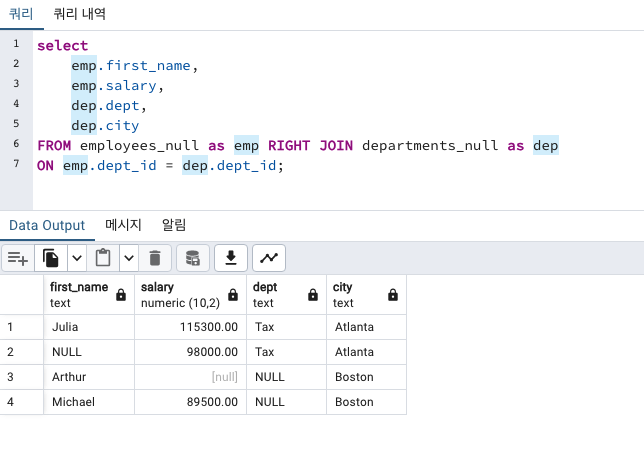
확실히 FROM에서 지칭해준 별칭을 다른 SELECT, ON 등에 적용하니 쿼리가 짧아졌습니다.
테이블명 as 별칭에서 as를 제거해도 됩니다.
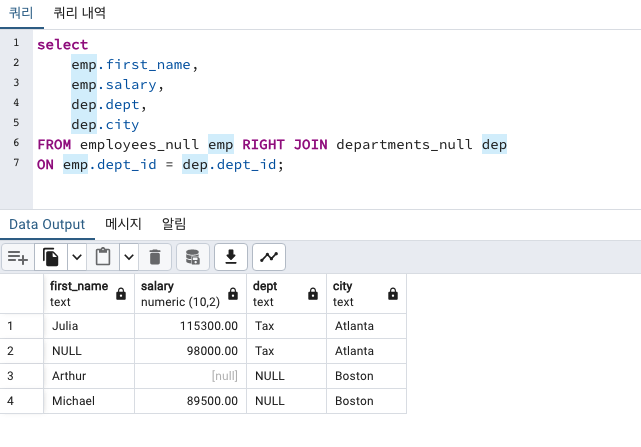
n개 테이블 조인
세 개의 테이블을 다시한번 만들어보겠습니다.
CREATE TABLE district_2020 (
id integer CONSTRAINT id_key_2020 PRIMARY KEY,
school_2020 text
);
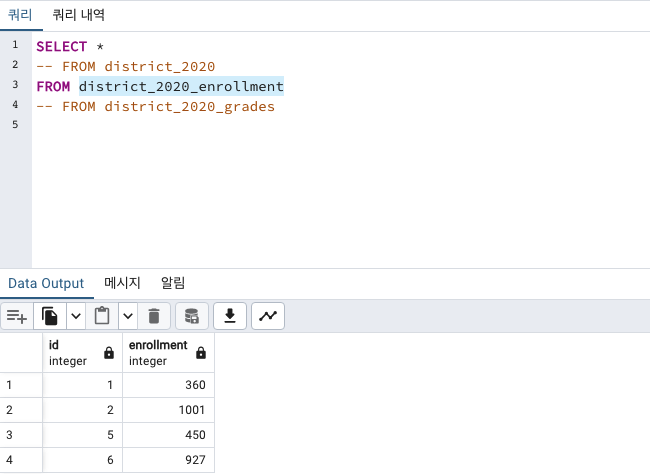
CREATE TABLE district_2020_enrollment (
id integer,
enrollment integer
);
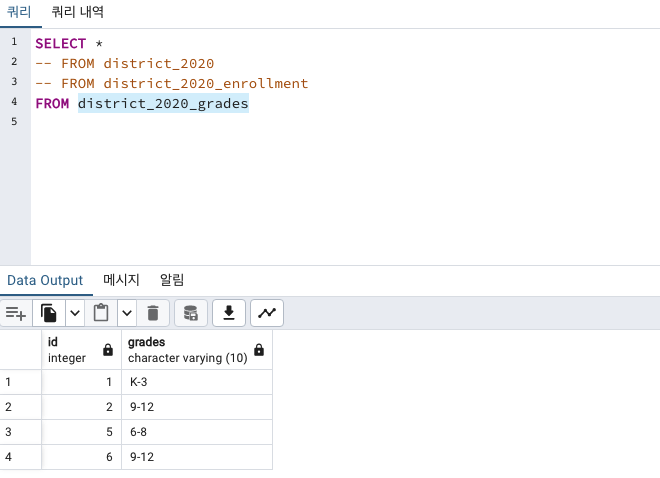
CREATE TABLE district_2020_grades (
id integer,
grades varchar(10)
);
INSERT INTO district_2020 VALUES
(1, 'Oak Street School'),
(2, 'Roosevelt High School'),
(5, 'Dover Middle School'),
(6, 'Webutuck High School');
INSERT INTO district_2020_enrollment
VALUES
(1, 360),
(2, 1001),
(5, 450),
(6, 927);
INSERT INTO district_2020_grades
VALUES
(1, 'K-3'),
(2, '9-12'),
(5, '6-8'),
(6, '9-12');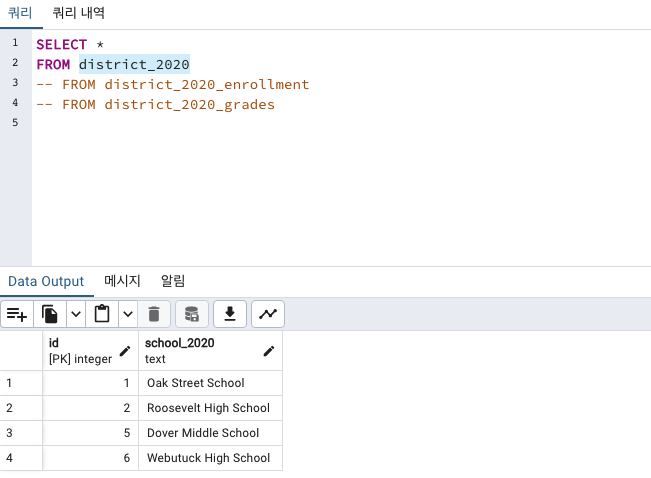
그러고는 JOIN ON 을 두 번 하여, 두 개의 조인을 해보겠습니다.
SELECT d20.id,
d20.school_2020,
en.enrollment,
gr.grades
FROM district_2020 AS d20
JOIN district_2020_enrollment AS en ON d20.id = en.id
JOIN district_2020_grades AS gr ON d20.id = gr.id
ORDER BY d20.id;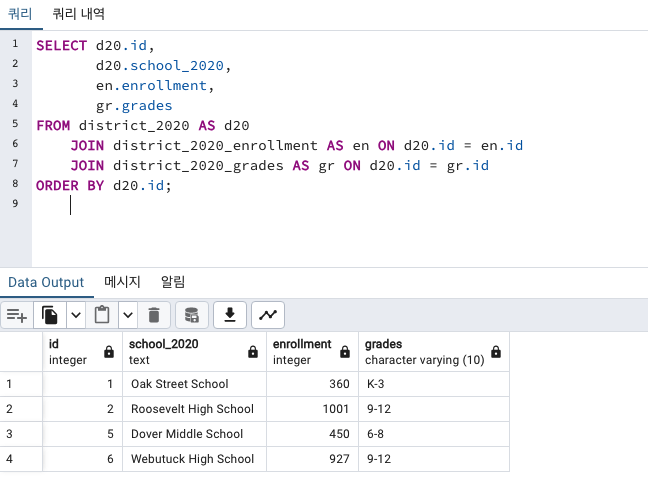
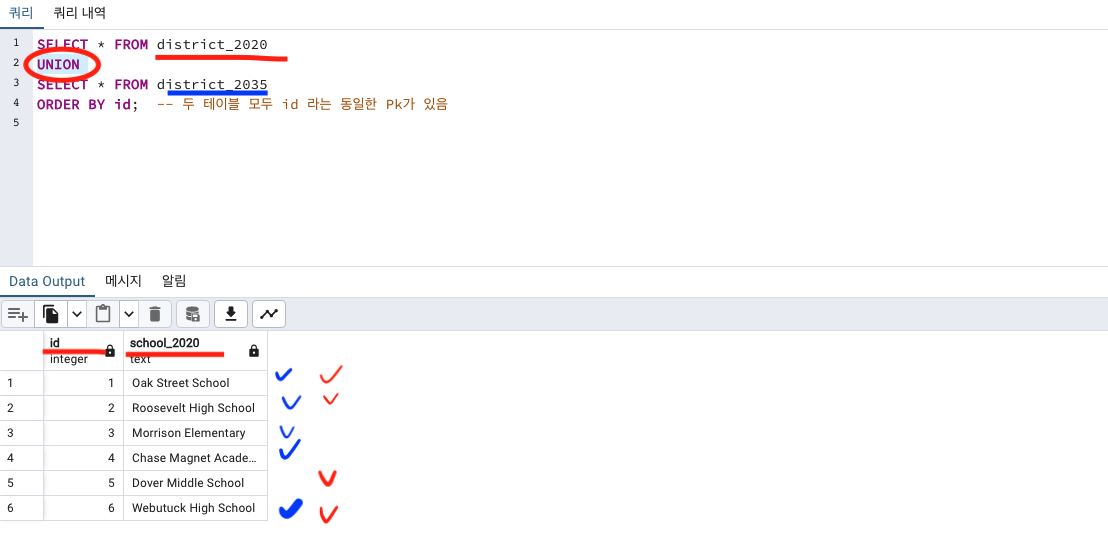
UNION
JOIN ON은 중복값까지 다 나옵니다.
JOIN USING은 중복값 제거되서 나옵니다.
똑같이 UNION을 통해서도 중복값 제거된 채로 병합할 수 있습니다.
CREATE TABLE district_2020 (
id integer CONSTRAINT id_key_2020 PRIMARY KEY,
school_2020 text
);
CREATE TABLE district_2035 (
id integer CONSTRAINT id_key_2035 PRIMARY KEY,
school_2035 text
);
INSERT INTO district_2020 VALUES
(1, 'Oak Street School'),
(2, 'Roosevelt High School'),
(5, 'Dover Middle School'),
(6, 'Webutuck High School');
INSERT INTO district_2035 VALUES
(1, 'Oak Street School'),
(2, 'Roosevelt High School'),
(3, 'Morrison Elementary'),
(4, 'Chase Magnet Academy'),
(6, 'Webutuck High School');이미 district_2020테이블과 값을 넣은 상태여서
district_2035 테이블만 추가 생성했습니다.
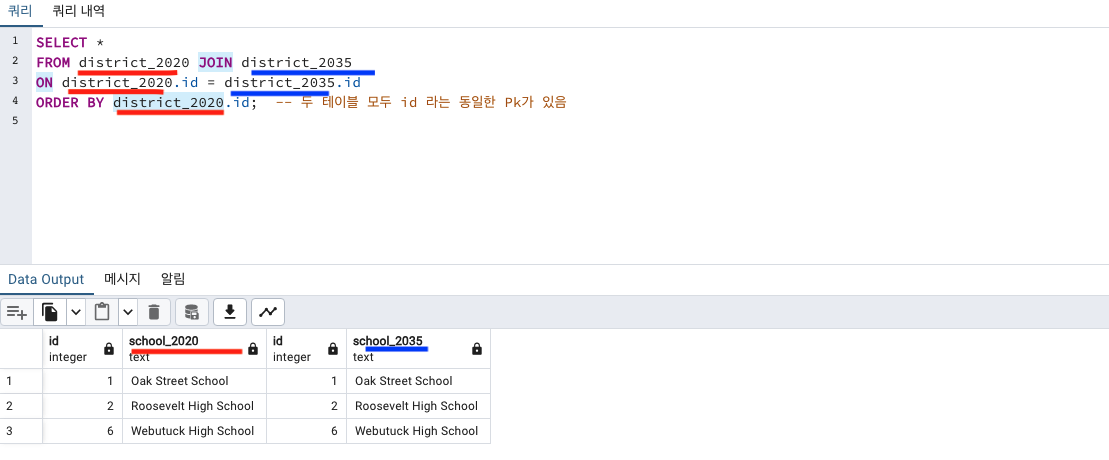
district_2035 테이블
| id[PK] | school_2035 |
|---|---|
| 1 | "Oak Street School" |
| 2 | "Roosevelt High School" |
| 3 | "Morrison Elementary" |
| 4 | "Chase Magnet Academy" |
| 6 | "Webutuck High School" |
district_2020 테이블
| id[PK] | school_2020 |
|---|---|
| 1 | "Oak Street School" |
| 2 | "Roosevelt High School" |
| 5 | "Dover Middle School" |
| 6 | "Webutuck High School" |
JOIN ON
JOIN USING
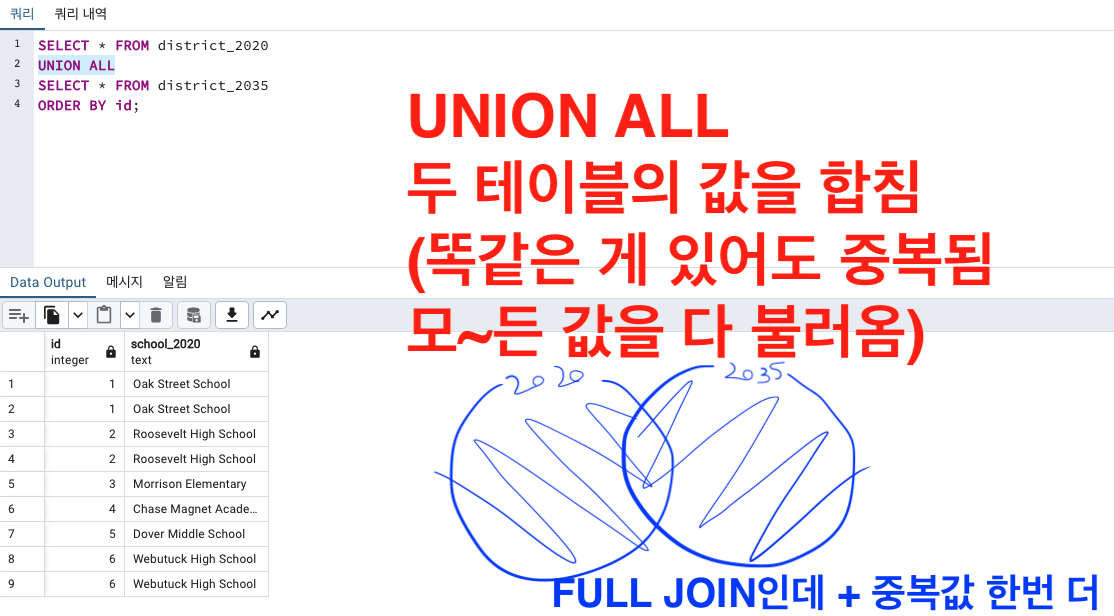
UNION
UNION ALL
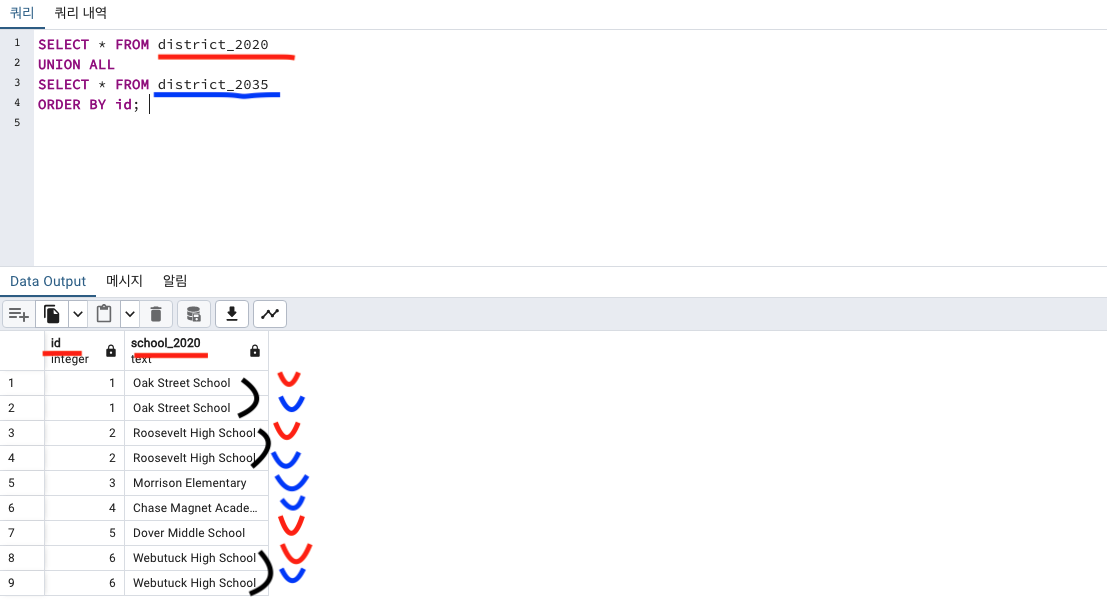
UNION ALL 을 하게되면 중복값까지 모두 나옵니다.
UNION 쿼리커스터마이징(컬럼명에서추출)
어느row가 어느 테이블에서 왔는지 확인할 수 있습니다.
SELECT
FROM district_2020
UNION ALL
SELECT
FROM district_2035
ORDER BY id;
UNION ALL 하게되면 테이블 두 개 모두 있는 중복값까지 나옵니다.
각 테이블에서 컬럼명의 문자열 일부를 추출해낼 수 있습니다.
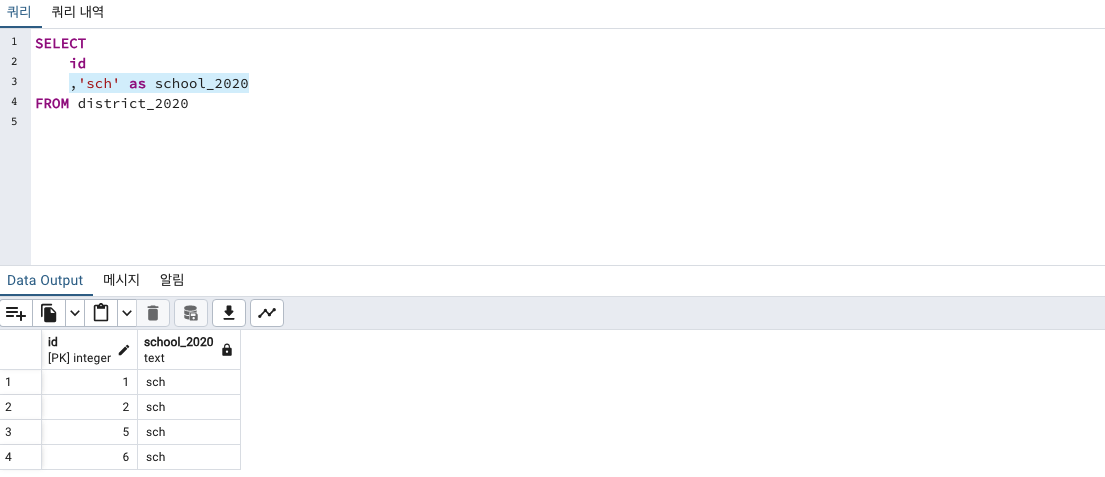
SELECT '컬럼명에서따로추출해낼문자' as 새컬럼명
FROM district_2020
UNION ALL
SELECT '컬럼명에서따로추출해낼문자' as 새컬럼명
FROM district_2035
ORDER BY id;
참고로 두 테이블에는 school_2020컬럼과 school_2035컬럼이 있기 떄문에
'2020' 추출해서 새 컬럼 생성
'2035' 추출해서 새 컬럼 생성
이렇게 일단 distric_2020테이블의 school_2020컬럼을 이용해서
2020(년도)와 school명 을 표시해줍니다.
SELECT
'2020' as year --school_2020컬럼에서 2020만 추출하는 열 생성
, school_2020 as school --school_2020컬럼 그 자체
FROM district_2020 이제 두 테이블을 UNION 해줍니다.
SELECT
'2020' as year --school_2020컬럼에서 2020만 추출하는 열 생성
, school_2020 as school --school_2020컬럼 그 자체
FROM district_2020
UNION ALL
SELECT
'2035' as year --school_2035컬럼에서 2035만 추출하는 열 생성
, school_2035 as school --school_2035컬럼 그 자체
FROM district_2035 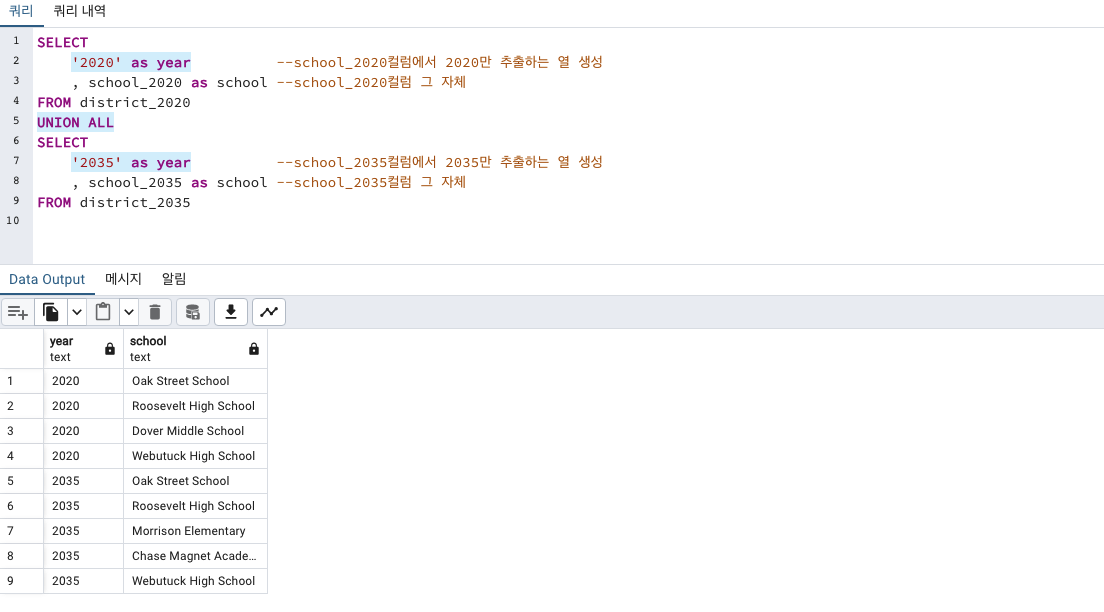
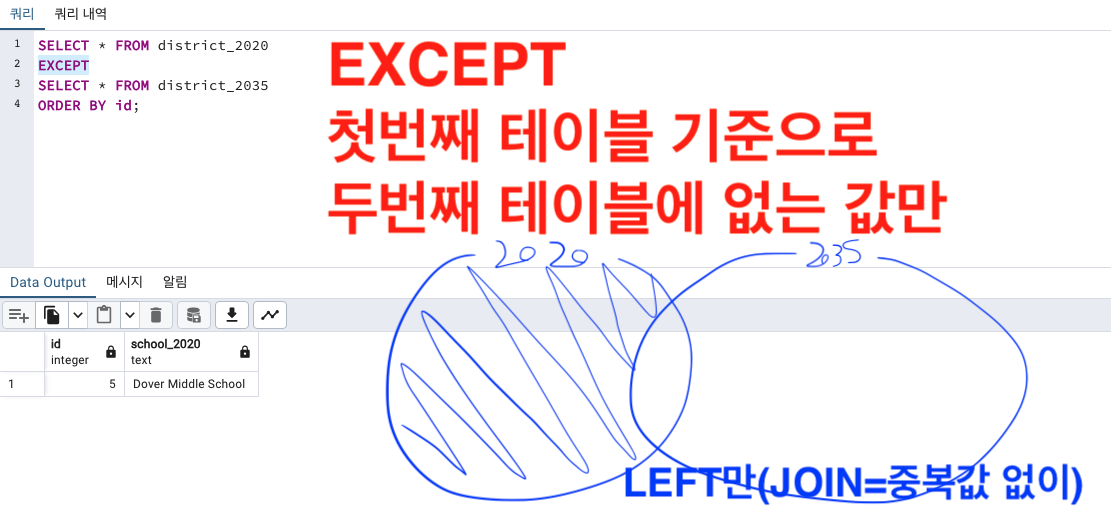
UNION,INTERSECT,EXCEPT
UNION과 비슷하게 중복값을 제거합니다.
UNION, INTERSECT, EXCEPT 모두 비슷하니 헷갈립니다.
다시한번 정리해보겠습니다.
district_2020 테이블
id[PK] school_2020 1 "Oak Street School" 2 "Roosevelt High School" 5 "Dover Middle School" 6 "Webutuck High School" district_2035 테이블
id[PK] school_2035 1 "Oak Street School" 2 "Roosevelt High School" 3 "Morrison Elementary" 4 "Chase Magnet Academy" 6 "Webutuck High School" 여기서 겹치는 중복값은 id기준 1,2,6 (총 3개) 입니다.