Python 부트캠프(멀티잇 데이터 분석&엔지니어링 캠프) 에서 배운 pandas, matplotlib, seaborn 포함 데이터 분석 수업을 기반으로 직접 2023년 9월경 다른 블로그에 작성한 글을 가져왔습니다.

작업: VS코드
환경: Python 3.10 버전
0. 프로젝트 목표와 목차
- 한국교통안전공단 자동차 결함 리콜 데이터를 분석하여 유의미한 정보 도출
- 탐색적 데이터 분석을 수행하기 위한 데이터 정제, 특성 엔지니어링, 시각화 방법 학습
- 데이터 읽기: 자동차 리콜 데이터를 불러오고 Dataframe 구조를 확인
1.1. 데이터 불러오기
- 데이터 정제: 결측치 확인 및 기초적인 데이터 변형
2.1. 결측치 확인
2.2. 중복값 확인
2.3. column 변형
2.4. column 복제
2.5. column 삭제
- 데이터 시각화: 각 변수 별로 추가적인 정제 또는 feature engineering 과정을 거치고 시각화를 통하여 데이터의 특성 파악
3.1. 제조사별 리콜 현황 출력
3.2. 모델별 리콜 현황 출력
3.3. 월별 리콜 현황 출력
3.4. 생산연도별 리콜 현황 출력
3.5. 4분기 제조사별 리콜 현황 출력
3.6. 하반기 생산연도별 리콜 현황 출력
3.7. 워드 클라우드를 이용한 리콜 사유 시각화
1. 데이터 불러오기
1.1 셋팅
깃배쉬 터미널 환경 셋팅
python -m venv venv
python --version # 3.10 버전이 나와야
pip install jupyterVS코드 오른쪽 상단 Select Kernal의 explorer 관련
Python 3.10버전 으로 선택 아래 라이브러리 깃배쉬로 불러오기
pip install numpy pandas matplotlib seaborn
나의경우,
python -m pip install 설치라이브러리1.2 데이터 읽기
라이브러리 불러오기
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns변수 = pd.read_csv(불러오는 파일 위치)
encoding='euc_kr'한국어 텍스트 데이터를 다룰 때 사용되는 문자 인코딩
df = pd.read_csv('./data/한국교통안전공단_자동차결함 리콜현황_20221231.csv',encoding='euc_kr') 변수.head() : 상위데이터 불러오기
총 5개이며, 인덱스 0번 row부터 시작한다.
df.head() # 상위 5개 = 기본
df.head(4) # 상위 4개
df.head(10) # 상위 10개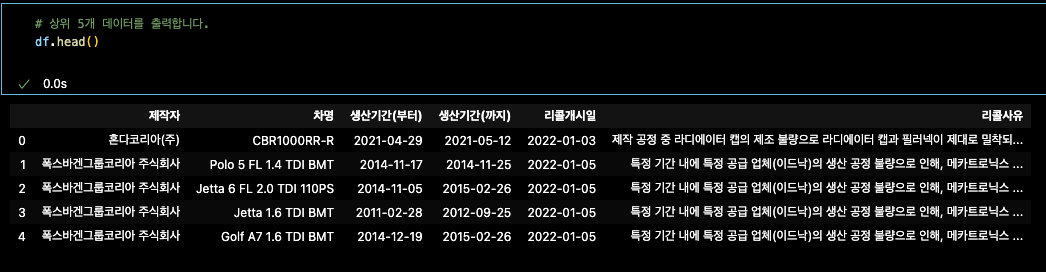
column은 제작자,차명,생산기간(부터),생산기간(까지),리콜게시일,리콜사유 가 있다
row는 총 5개 있다. 인덱스 0부터 ~ 인덱스 4까지
변수.tail() : 하위데이터 불러오기
df.tail() # 하위 5개 = 기본
df.tail(4) # 하위 4개
df.tail(10) # 하위 10개 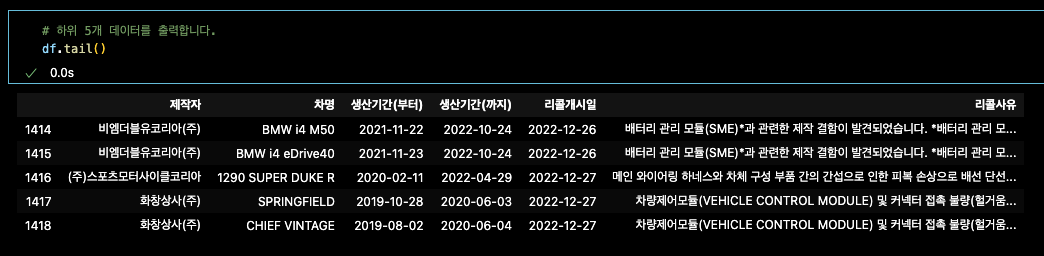
총 1418 row행까지 있다.
변수.info(): 필요 정보 보기
column명, column당 갯수, 타입 등
관측치의 갯수는 1419개이다.
컬럼의 갯수는? 6개이다.
결측치의 갯수는 ? 0 이다. non-null
중복행의 갯수는 ? 모른다!
각 피처의 타입은 적절한가?
-> 피처 : 데이터프레임의 column을 가르킴
-> 모든 피처의 데이터 타입은 "object"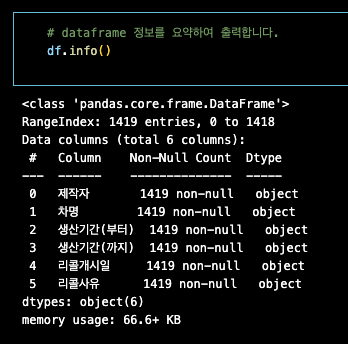
변수.describe() 기초 통계 정보 파악하기
df.describ()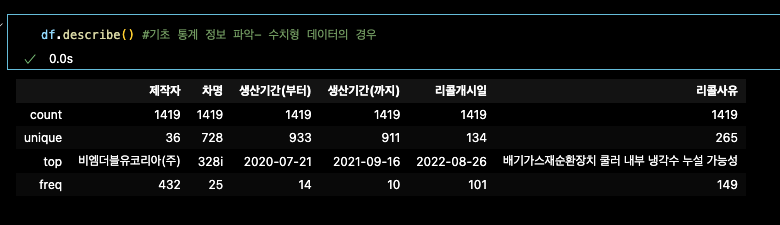
변수.info 와 변수.describe 는 다르다.
.info() 는 각 column에 대한 정보
.describe는 수치형 데이터 파악 = count, unique, top, freq
2. 데이터 정제
2.1 결측치 확인
변수.isnull() 함수를 이용한다.
변수.isnull() : 전체 데이터프레임 결측치 T or F
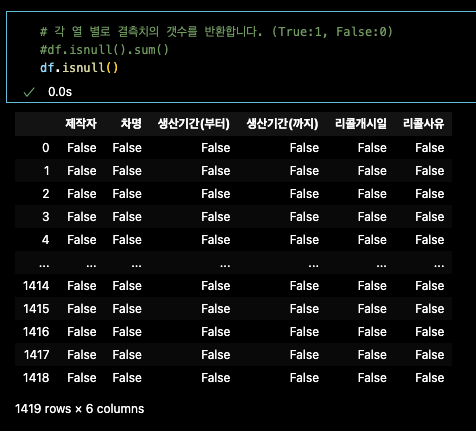
변수.isnull().sum() : 전체 데이터 프레임 결측치 갯수
각 컬럼별 갯수가 깔끔하게 나온다. 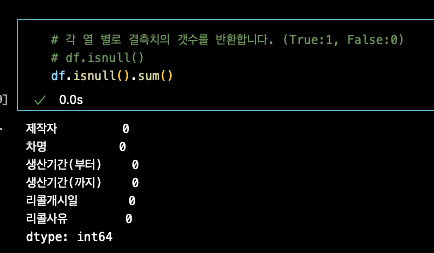
2.2 중복값 확인
중복값 확인
변수.duplicated() 함수를 이용한다.
df.duplicated() # 중북값이 있는지 없는지 -> 중복값이 있으면 True
# 중복값이 있으면 첫번째 중복값만 True 이고, 나머지 중복값들은 모두 False
df.duplicated(keep=False) # 중복값이 있는지 없는지 -> 중복값이 있으면 True
# 중복값이 있으면 첫번째인지 아닌지 상관없이 무조건 다 True 지금 데이터는 중복값이 없길래 상관없이 모두 결과는 False 로 나온다.
중복값이 여러개로 추정될 경우 (keep=False)를 꼭 넣자.
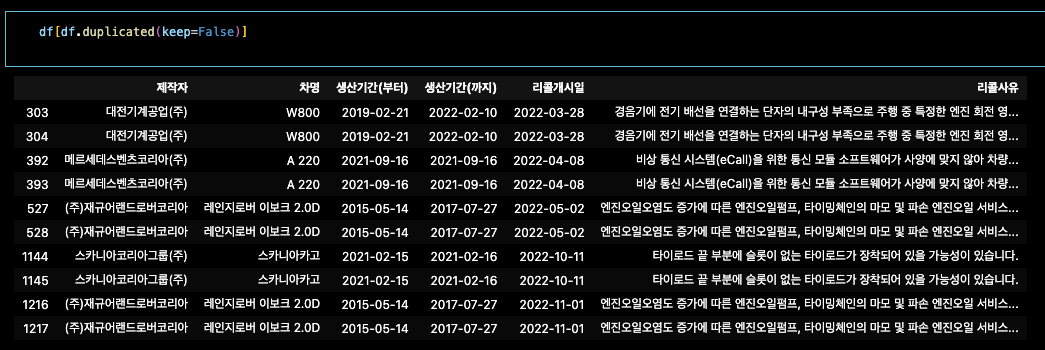
이걸 또 데이터프레임화 시켜줘야함
변수.duplicated(keep=False) -> 값이 T/F로 쭈루룩 나옴
변수[ 변수.duplicated(keep=False) ] -> 값이 데이터프레임화로 나옴
df[df.duplicated(keep=False)]는 중복된 모든 행을 선택한 것
df.duplicated(keep=False).sum() 중복된 행의 갯수 계산
중복값 제거
변수 = 변수.drop_duplicates() : 기본 5개의 rows 바로 삭제됨
한 번 엔터치면 5개가 날라가고
한 번 더 엔터치면 총 10개가 날라가고~
중복된 행이 제거된 새로운 데이터프레임이란 거다.
df = df.drop_duplicates() # 하게되면 기본5개의 중복된행 삭제됨 
2.3 column 변경/추가
2.3.1 생산기간(부터)
column 파악
df.info() # 전체 column 파악
df['생산기간(부터)'] # 특정 column 보기 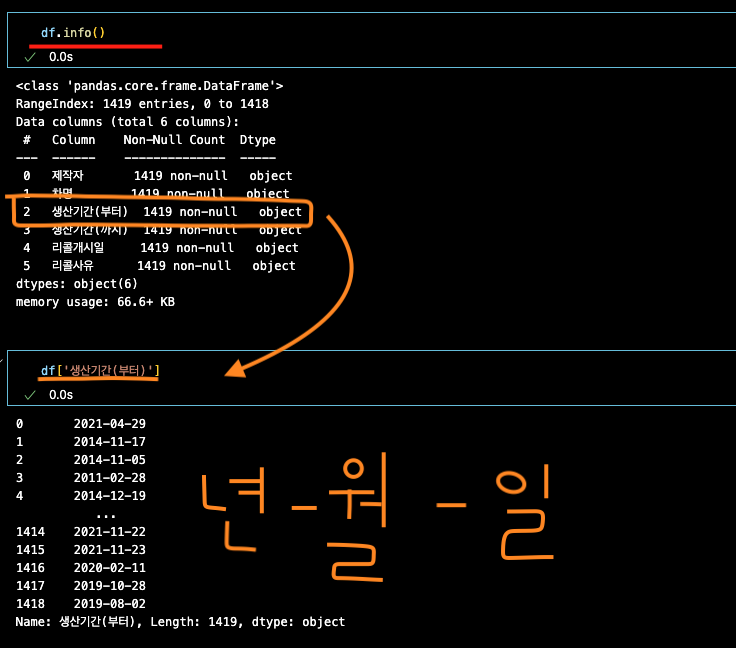
column 기존값 변형/추가
.to_datetime(): 해당 함수 사용
이렇게 하면 해당 열의 데이터가 날짜로 인식
pd.to_datetime(): 가져온 함수를 -> 판다스 라이브러리로 이용
변수 = pd.to_datetime(): 변수에 씌우겠다.
dt.year년도로 인식dt.month월별로 인식dt.day날짜로 인식
변수[' 특정컬럼명 '] = pd.to_dateime( 변수[' 특정컬럼명 '])
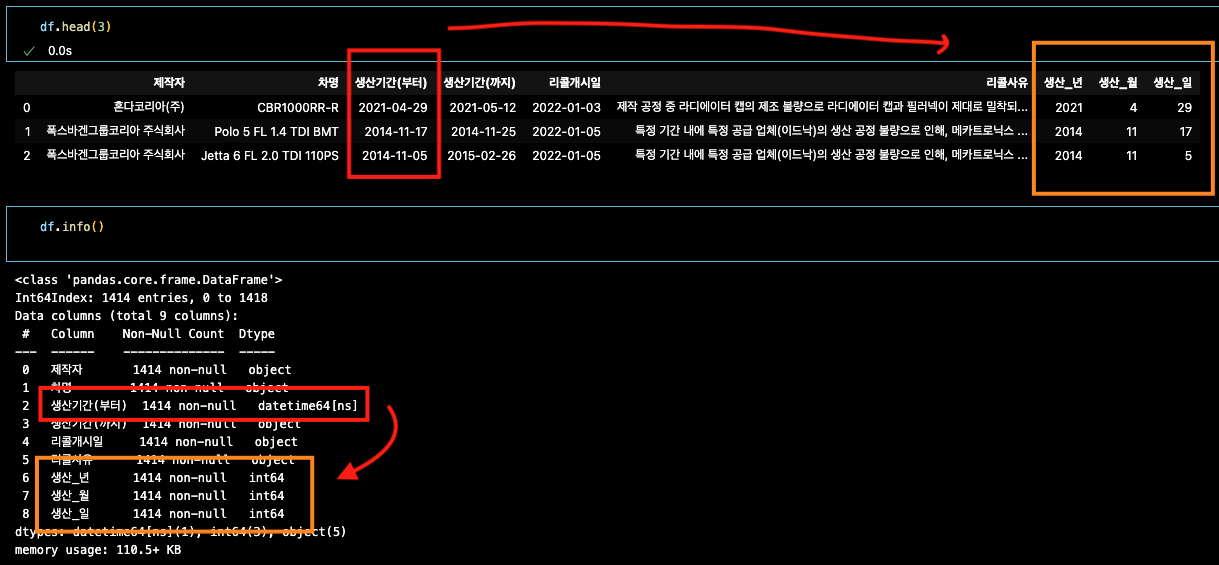
# 생산기간(부터) 컬럼을 종료_년, 종료_월, 종료_일 컬럼으로 분해
df['생산기간(부터)'] = pd.to_datetime(df['생산기간(부터)'])
df['생산_년']=df['생산기간(부터)'].dt.year
df['생산_월']=df['생산기간(부터)'].dt.month
df['생산_일']=df['생산기간(부터)'].dt.day수정되었는지 확인
df.head(3)
df.info() 기존 column 삭제되지 않는다.
2.3.2 리콜개시일
생산기간(까지)컬럼은 year-month-day 로 되어있으며,
이를 각각 생산종료년도, 생산종료월, 생산종료날짜로 나누어졌다.동일한 방식으로
리콜개시일 컬럼을 기준으로
리콜년도, 리콜월, 리콜일 컬럼으로 분해하라.
# 생산기간(까지) 컬럼을 종료_년, 종료_월, 종료_일 컬럼으로 분해
# df['생산기간(까지)'] = pd.to_datetime(df['생산기간(까지)'])
# df['종료_년']=df['생산기간(까지)'].dt.year
# df['종료_월']=df['생산기간(까지)'].dt.month
# df['종료_일']=df['생산기간(까지)'].dt.day
# 리콜개시일 컬럼을 리콜_년, 리콜_월, 리콜_일 컬럼으로 분해
df['리콜개시일'] = pd.to_datetime(df['리콜개시일'])
df['리콜_년']=df['리콜개시일'].dt.year
df['리콜_월']=df['리콜개시일'].dt.month
df['리콜_일']=df['리콜개시일'].dt.day
확인
df.info()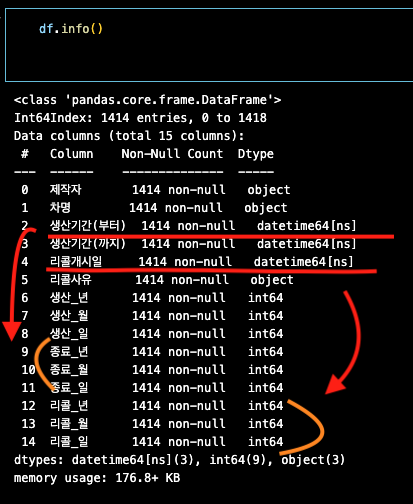
2.4 column 복제
동일한 컬럼을 하나 더 만드는 방법
변수['원본컬럼복사'] = 변수[원본컬럼]
df['생산기간(부터)복사본'] = df['생산기간(부터)']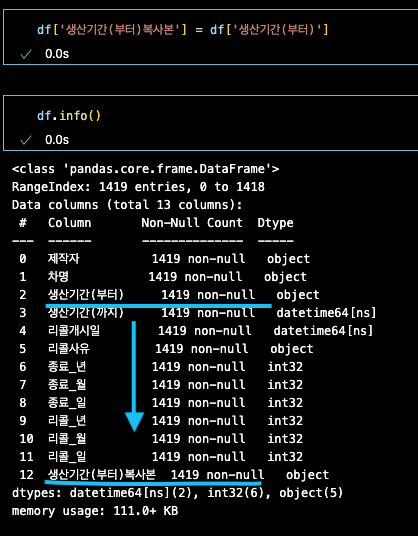
2.5 column 삭제
변수.drop(columns=['삭제컬럼1','삭제컬럼2']) 인건 동일하나, 삭제적용 X
- 변수 =
변수.drop(columns=['삭제컬럼1','삭제컬럼2']) 변수.drop(columns=['삭제컬럼1','삭제컬럼2']inplace=True)
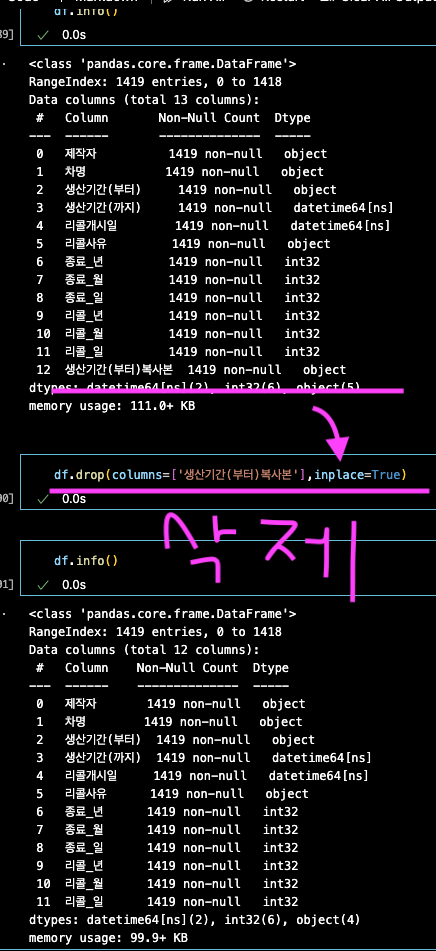
1개 컬럼 삭제
df.drop(columns='생산기간(부터)복사본', inplace=True)
df.drop(columns=['생산기간(부터)복사본'],inplace=True)2개 이상 컬럼 삭제
df.drop(columns=['생산기간(부터)복사본'],inplace=True) # 1개여도 동일 가능
df.drop(columns=['생산기간(부터)', '생산기간(까지)', '리콜개시일'],inplace=True)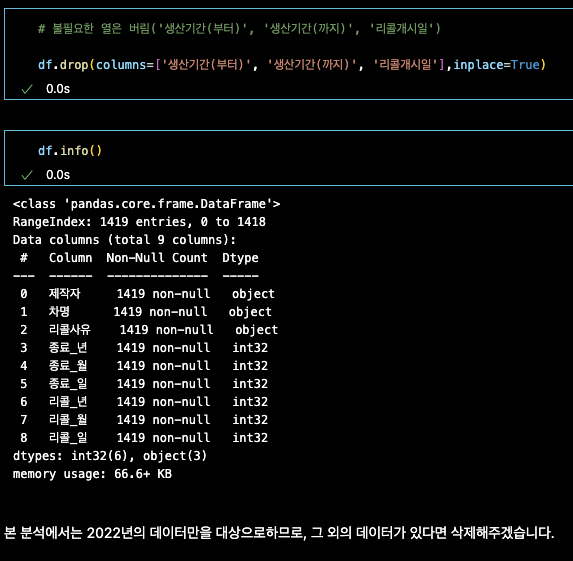
2.6 column안의 값
어떠한 column에 정해진 데이터값이 있으면 뭐가 있는지 확인해보자
(예를들면 2022년도 출생 데이터에 born_year 카테고리에 2021,2019 등 섞여 있는지 조회 가능)
변수['특정컬럼'] : 해당 컬럼의 모든 데이터 세로 나열
변수['특정컬럼'].unique() : 해당 컬럼의 중복값 제거되서 세로 나열 - 갯수가 안나온다.
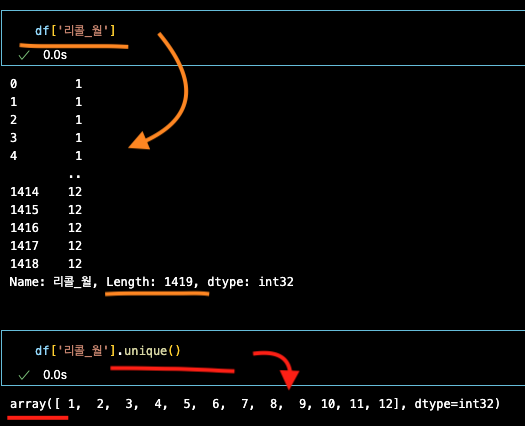
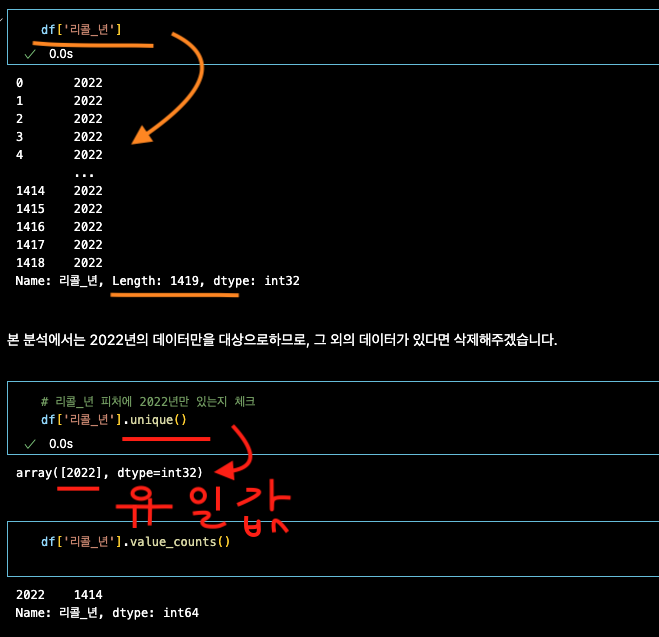
column안의 정해진 값 카운팅을 해보자
변수['특정컬럼'] : 해당 컬럼의 모든 데이터 세로 나열
변수['특정컬럼'].value_counts() : 각 데이터값의 갯수
3. 데이터 시각화 - bar,pie
3.1 제조사별 리콜 현황
확인하기
컬럼 중 하나 인 '제조사' 기준으로 확인해보자.
제조사? 뭐가 있을까
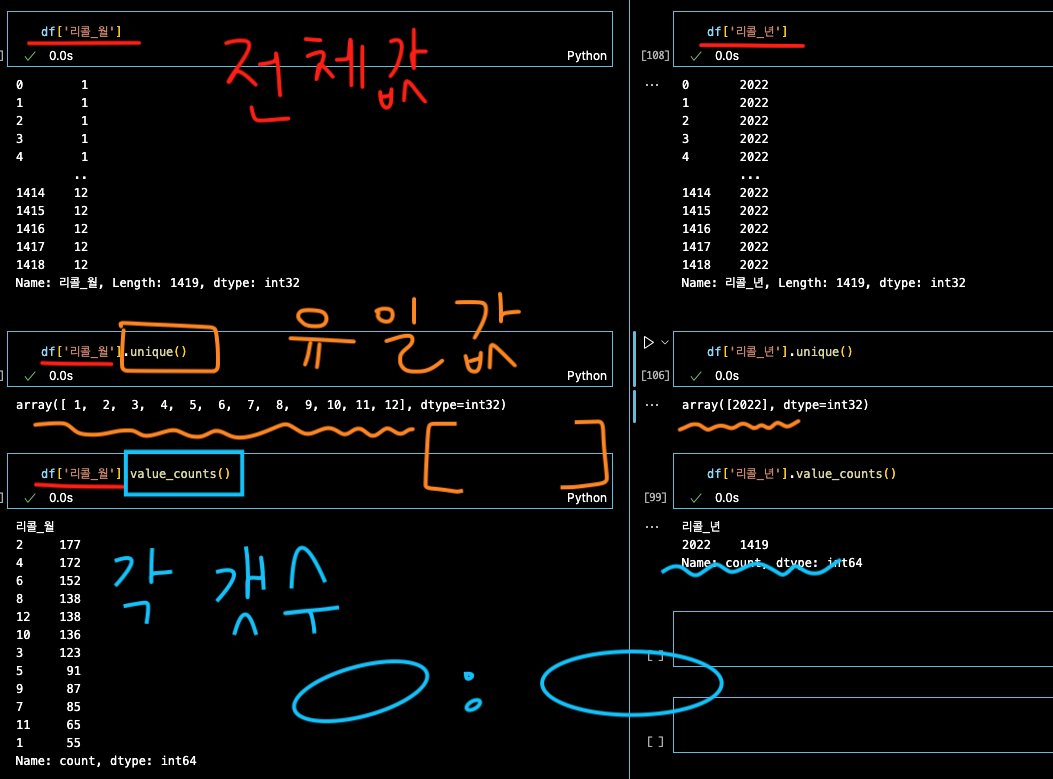
df['제작자'].unique()
# array([ 하고 모든 데이터값 쭈루룩,쭈루룩,쭈루룩,,,너무길어,,,쭈루룩 ])
df['제작자'].nunique()
# 달랑갯수만나옴
# 36총 36개의 제조사가 있다.
해당 컬럼(제조사)별 데이터값 보기
변수.groupby('컬럼명') .size( )
df.groupby('제작자')
# <pandas.core.groupby.generic.DataFrameGroupBy object at 0x11f7bdcf0>
df.groupby('제작자').count()
# 해줘야 각각의 데이터 값이 몇 개 있는지 카운팅 해줌 = 중복되는 갯수
df.groupby('제작자').size()
# 해줘야 count로 나열된(중복된) 걸 하나로 보여준다. 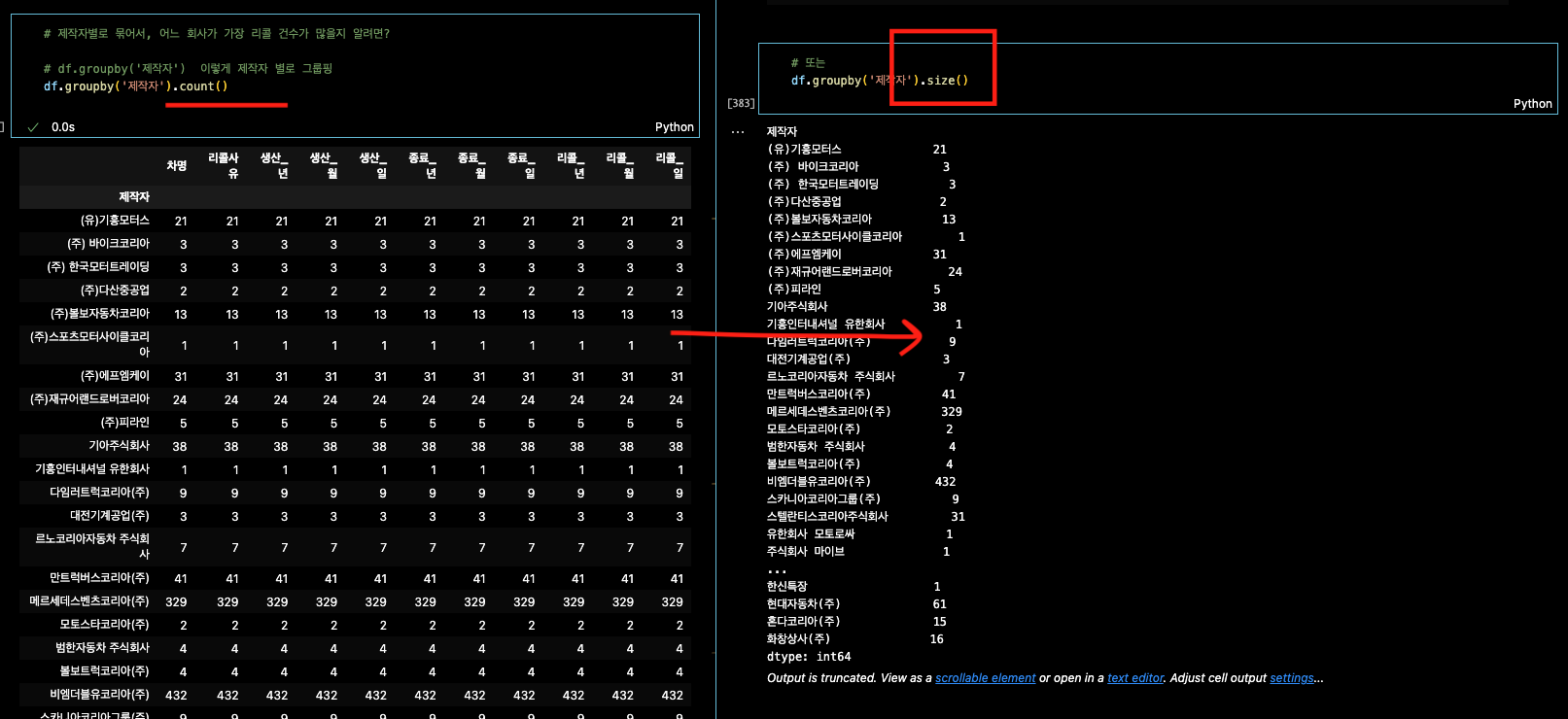
예를 들어,
'제작자' 컬럼 안에
['현대', '기아', '르노삼성', '현대', '기아'] 각각 중복된 데이터값이 나열되어 있을 경우,
df.groupby('제작자').size()하게되면
제작자
기아 2
르노삼성 1
현대 2
dtype: int64
이것을 작은 순서값 대로 순서대로 정리해보자.
df.groupby('컬럼명').size.sort_values()
df.groupby('제작자').size().sort_values() # 작은 순->큰 순
df.groupby('제작자').size().sort_values(ascending=False) # 큰 순 -> 작은 순 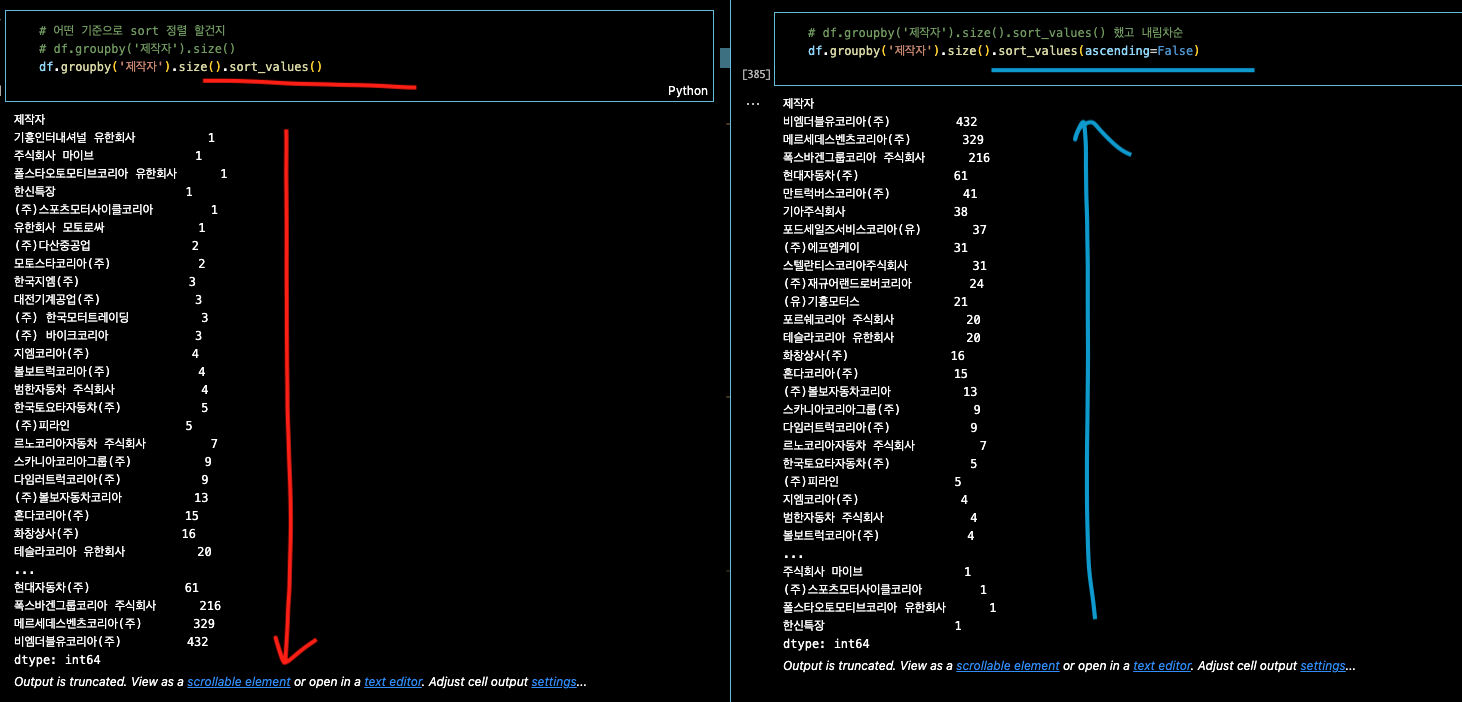
다시 이걸 frame화 시키자
df.groupby('제작자').size().sort_values(ascending=False).to_frame('기준통계함수'
df.groupby('제작자').size().sort_values(ascending=False)
# 그냥 데이터갯수 역순으로만 나열되며, 길면 다 보여주지도 않는다.
df.groupby('제작자').size().sort_values(ascending=False).to_frame('count')
# frame화 시켜서 정리 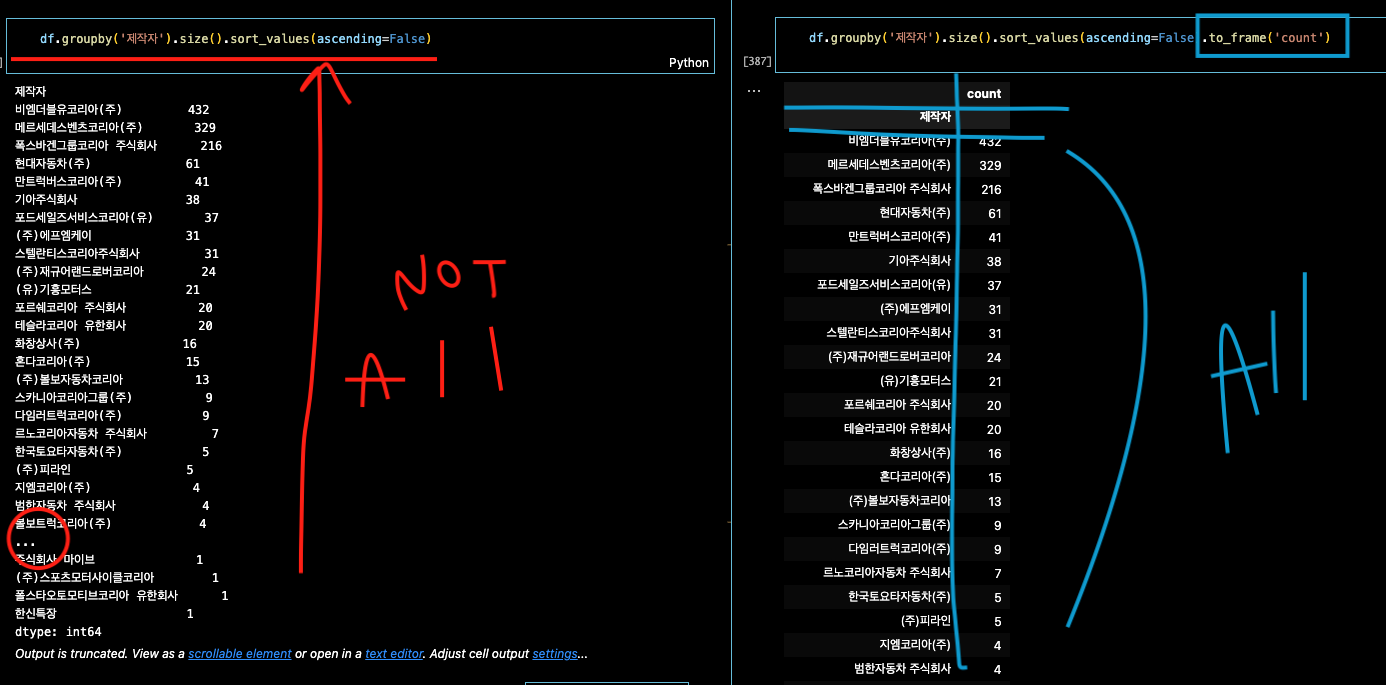
제조사별 리콜 현황 정답
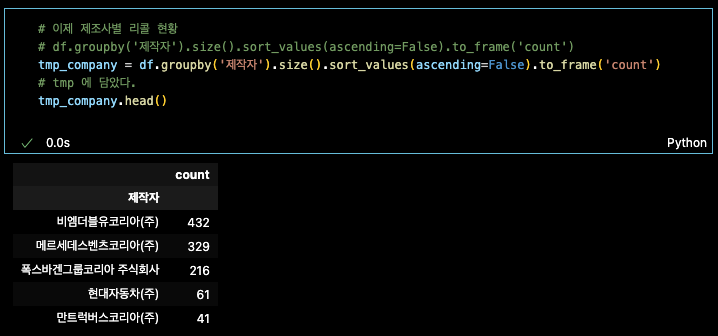
tmp_company = df.groupby('제작자').size().sort_values(ascending=False).to_frame('count') tmp_company.head()
bar 그래프
일단 셋팅
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
# font_path = './NanumGothic.ttf' # 폰트 위치
# plt.rc('font', family=font_name)
# plt.rc('font', family='Malgun Gothic') 나는 애플이니까
plt.rc('font', family='AppleGothic')
plt.rcParams['axes.unicode_minus'] = False # 마이너스 깨짐 현상 해결 제조사별 리콜 갯수 차트로 구해보자.
x = tmp_company.index # x에는 제조사
y = tmp_company['count'] # y에는 그 갯수
plt.figure(figsize=(8,3)) # 스케치북 (가로,세로)
plt.bar(x=x,height=y) # bar 차트에 x,y 값 할당 (x는 막대기 타이틀,y는 수치)
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('제조사별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라
# 한글이 깨지지 않고 잘 나옴 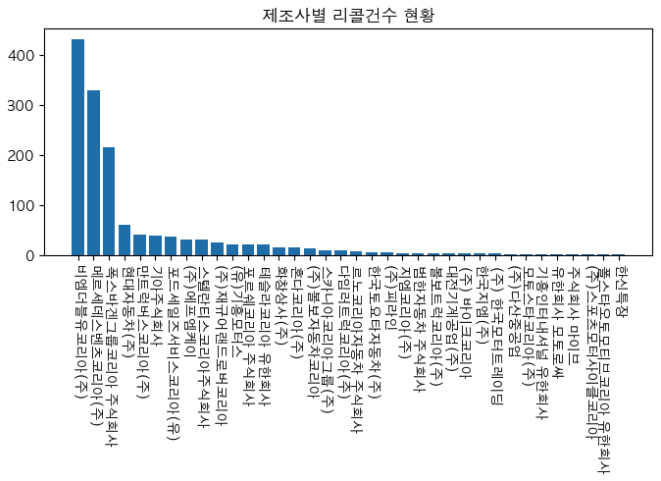
모든 제조사 -> 상위 10개만
tmp_company = df.groupby('제작자').size().sort_values(ascending=False).to_frame('count').head(10)
x = tmp_company.index
y = tmp_company['count']
plt.figure(figsize=(6,3)) # 스케치북
plt.bar(x=x,height=y) # bar 차트에 x,y 값 할당 (x는 막대기 타이틀,y는 수치)
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('제조사별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라
# 한글이 깨지지 않고 잘 나옴 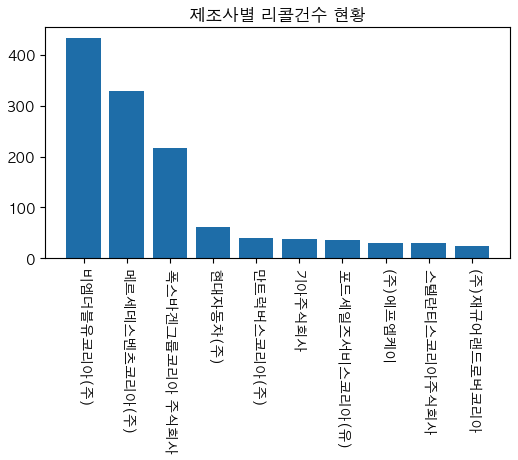
pie 그래프
초안
x = tmp_company.index
y = tmp_company['count']
plt.figure(figsize=(16,6)) # 스케치북 (8,3) 하면 50% 사이즈 작아짐
plt.pie(y)
plt.title('제조사별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라
# 한글이 깨지지 않고 잘 나옴 
plt.pie(y) --> plt.pie(y,labels=x)
label=x 값 붙히기
x = tmp_company.index
y = tmp_company['count']
plt.figure(figsize=(8,3)) # 스케치북
plt.pie(y,labels=x)
plt.title('제조사별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라
# 한글이 깨지지 않고 잘 나옴 
모든 제조사 ---> 상위10개 제조사만
백분률 미표기--->백분률 중, 소수점 1자리까지만 출력
tmp_company = df.groupby('제작자').size().sort_values(ascending=False).to_frame('count').head(10)
x = tmp_company.index
y = tmp_company['count']
plt.figure(figsize=(8,3)) # 스케치북
plt.pie(y,labels=x, autopct='%.1f%%') # 뒤에 소수점 1자리까지 나오도록 할래
plt.title('제조사별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라 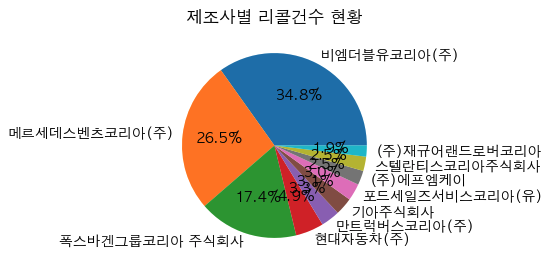
결과
제조사별 리콜건수 현황을 알아본 결과, 2022년 한 해 동안 여전시 독일 3사의 리콜 수가 가장 많은 것으로 보인다
tmp_company.head()
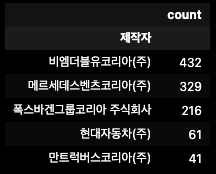
3.2 모델별 리콜 현황
확인하기
순서
df['차명'].unique() ---> 리스트 주루룩
df['차명'].nunique() ---> 그 안에 갯수 728 개
df.groupby('차명').count()
또는
df.groupby('차명').size() --> 중복값 포함 나열
어떤 기준으로 sort 정렬 할지
df.groupby('차명').size().sort_values()
df.groupby('차명').size().sort_values(ascending=False)
df.groupby('차명').size().sort_values(ascending=False).to_frame
df.groupby('차명').size().sort_values(ascending=False).to_frame('count')
변수에 저장
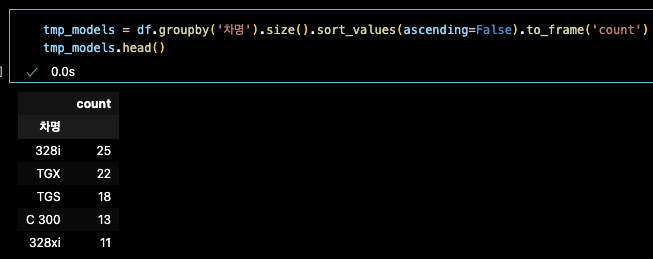
tmp_models = df.groupby('차명').size().sort_values(ascending=False).to_frame('count') 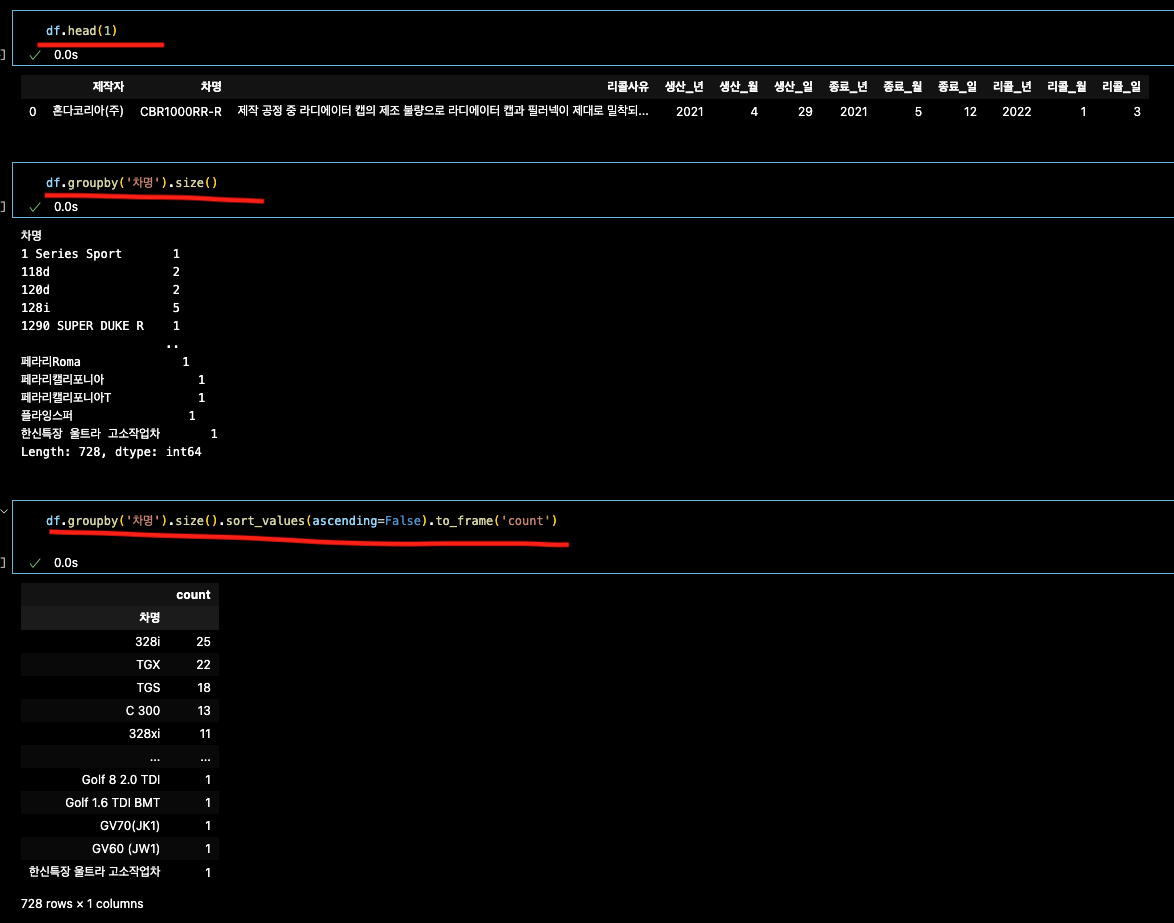
bar 그래프
모델별(컬럼:'차명') 리콜 건수 상위 30개
tmp_models = df.groupby('차명').size().sort_values(ascending=False).to_frame('count').head(30)
x = tmp_models.index
y = tmp_models['count']
plt.figure(figsize=(8,3)) # 스케치북
plt.bar(x=x,height=y) # bar 차트에 x,y 값 할당 (x는 막대기 타이틀,y는 수치)
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('모델별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라 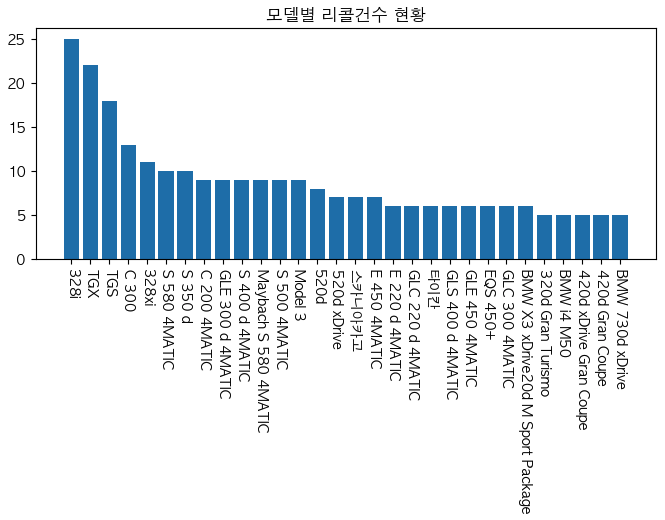
pie 그래프
모델별(컬럼:'차명') 리콜 건수 상위 7개
tmp_models = df.groupby('차명').size().sort_values(ascending=False).to_frame('count').head(7)
x = tmp_models.index
y = tmp_models['count']
plt.figure(figsize=(10,6)) # 스케치북
plt.pie(y,labels=x, autopct='%.1f%%') # 뒤에 소수점 1자리까지 나오도록 할래
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('모델별 리콜건수 현황') # 차트 제목
plt.show() # 출력하라 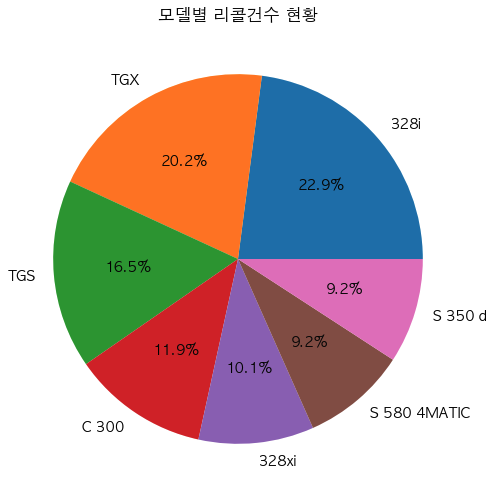
정리
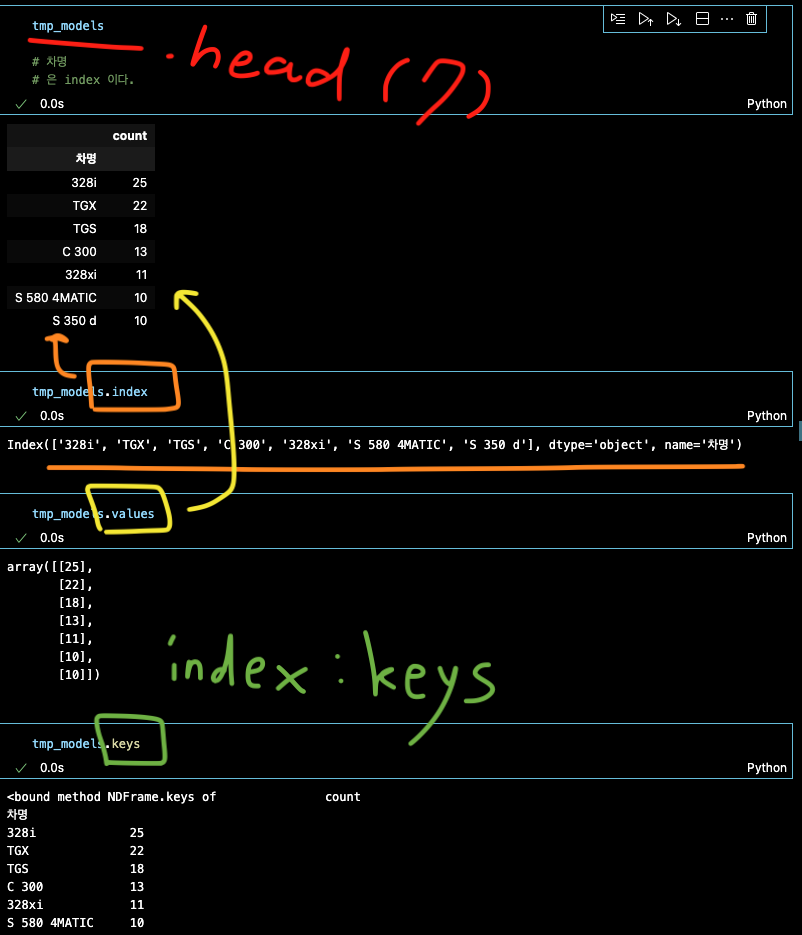
이 중 리콜 수가 제일 많은 1등은 !!!!!
tmp_models.index[0]
'328i' 결과
print(f'2022년 가장 리콜이 많은 제조사는? {tmp_company.index[0]}') print(f'2022년 가장 리콜이 많은 모델은? {tmp_models.index[0]}')2022년 가장 리콜이 많은 제조사는?
비엠더블유코리아(주)
2022년 가장 리콜이 많은 모델은?328i
3.3 생산연도별 리콜 현황
확인하기
df.head(2)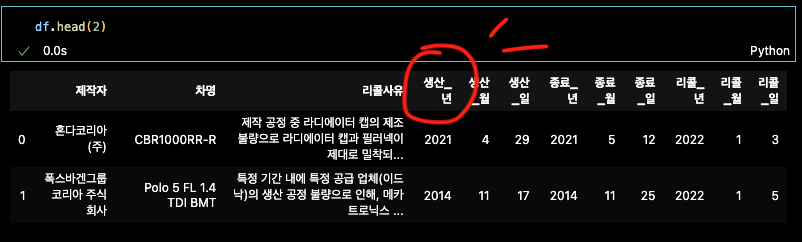
bar 그래프
tmp_year = df.groupby('생산_년').size().sort_values(ascending=False).to_frame('count').head(20)
x = tmp_year.index
y = tmp_year['count']
plt.figure(figsize=(8,3)) # 스케치북
plt.bar(x=x,height=y) # bar 차트에 x,y 값 할당 (x는 막대기 타이틀,y는 수치)
plt.xticks(rotation=270,ticks=tmp_year.index) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('생산년도별 리콜 현황') # 차트 제목
plt.show() # 출력하라 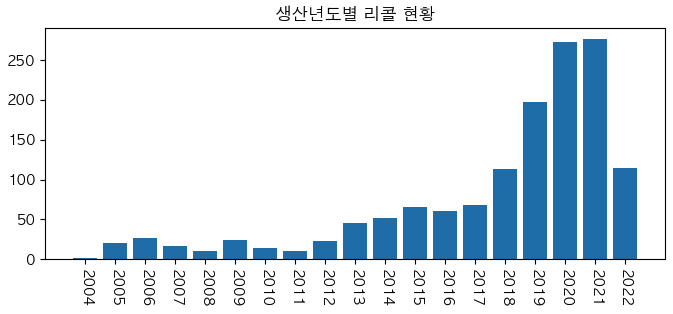
pie 그래프
tmp_year = df.groupby('생산_년').size().sort_values(ascending=False).to_frame('count').head(20)
x = tmp_year.index
y = tmp_year['count']
plt.figure(figsize=(10,6)) # 스케치북
plt.pie(y,labels=x, autopct='%.1f%%') # 뒤에 소수점 1자리까지 나오도록 할래
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('생산년도별 리콜 현황') # 차트 제목
plt.show() # 출력하라 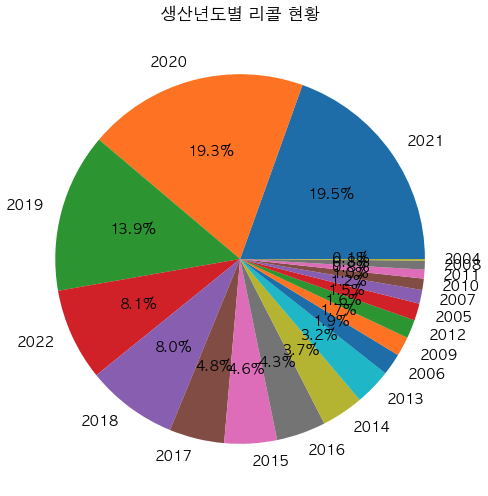
정리
print(f'2022년 가장 리콜이 많은 제조사는? {tmp_company.index[0]} 회사 입니다.') print(f'2022년 가장 리콜이 많은 모델은? {tmp_models.index[0]} 제품 입니다.') print(f'가장 리콜이 많은 년도는? {tmp_year.index[0]}년입니다.')2022년 가장 리콜이 많은 제조사는? 비엠더블유코리아(주) 회사 입니다.
2022년 가장 리콜이 많은 모델은? 328i 제품 입니다.
가장 리콜이 많은 년도는? 2021년입니다.
3.4 문제) 2022년 리콜 가장 많이 일어난 달과 적게 일어난 달의 차이 건수 구하기
초안
df.groupby('리콜_월').size().to_frame('count')
# 리콜_월 을 기준으로 그룹핑
# .size 해서 갯수
# .to_frame('count') 갯수 기준 프레임씌우기 발전 : 변수화 + 역순 정렬해서 count기준 프레임씌우기
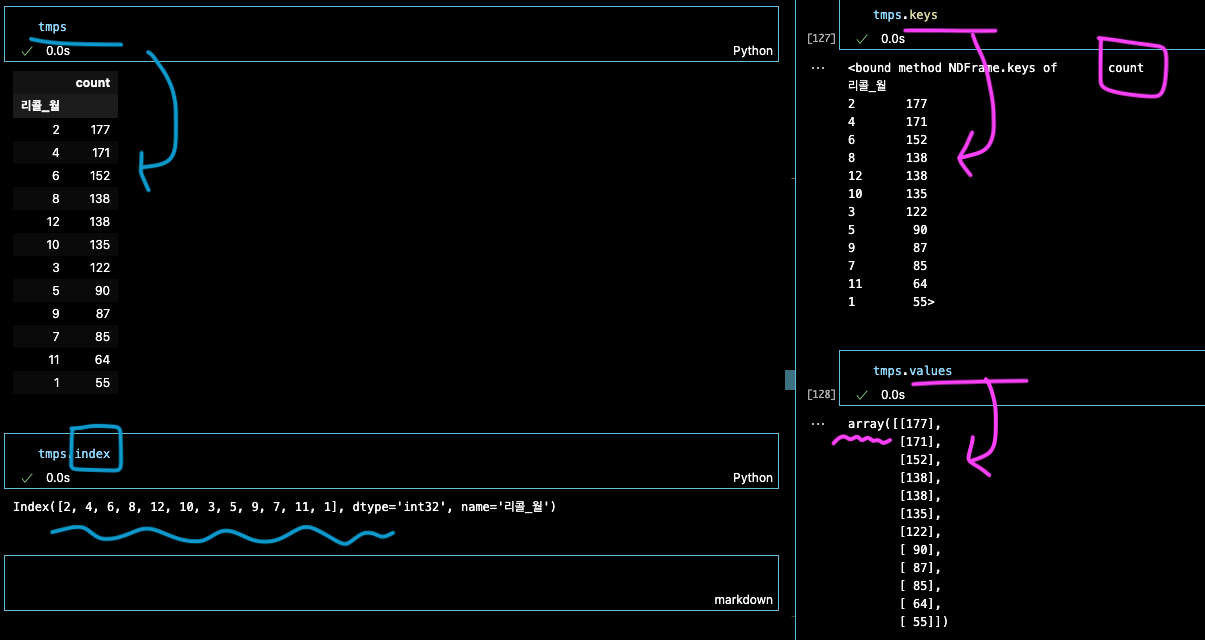
tmps = df.groupby('리콜_월').size().sort_values(ascending=False).to_frame('count') 최대값과 최소값
tmps.head(1), tmps.tail(1)차이 갯수 구하기
tmps['count'].max() - tmps['count'].min() 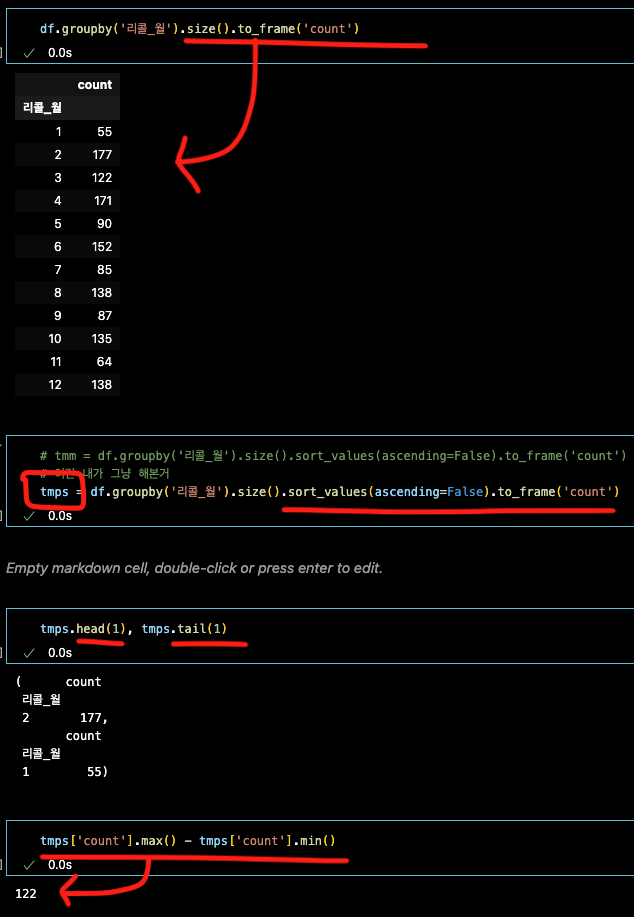
3.5 4분기-제조사별 리콜 현황
2022년 4분기 (10,11,12월) 제조사별 리콜 현황 시각화하기
확인하기
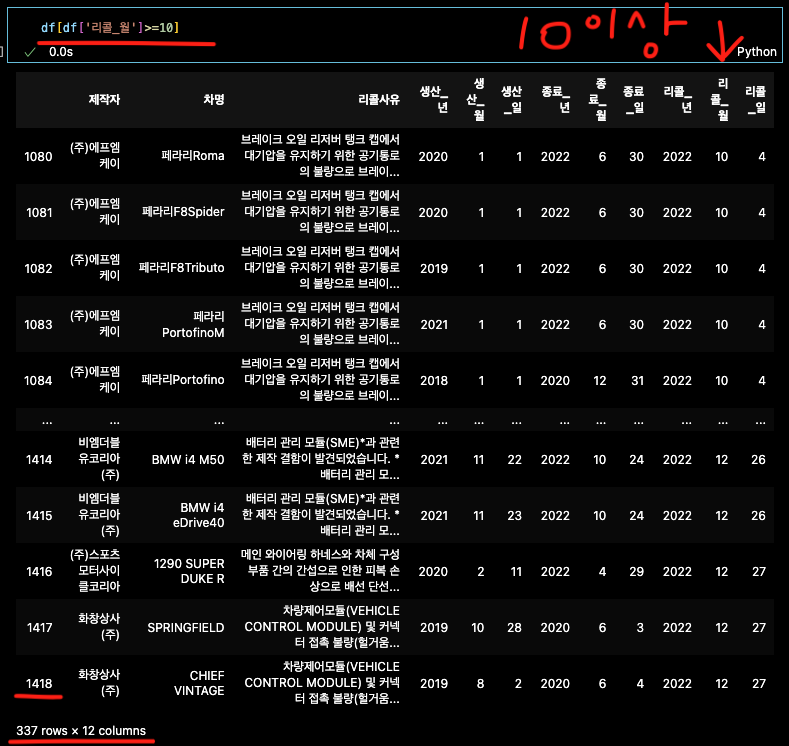
'리콜_월'칼럼 기준 데이터값 1~12월 중에 10월,11월,12월만
df[df['리콜_월']>=10] 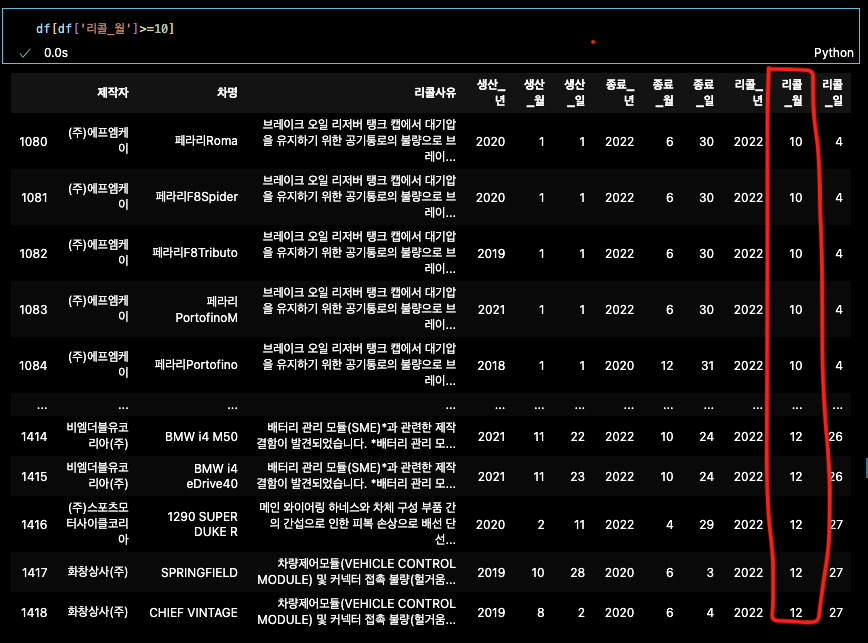
변수화 필수
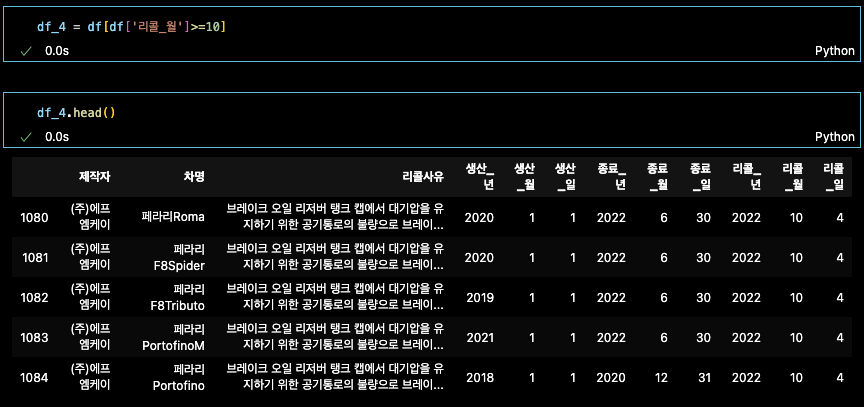
df_4 = df[df['리콜_월']>=10] # 변수화 필수
df_4.head() # 일단 5개만 추려서 상위데이터만 출력
bar 그래프
tmp_4 = df_4.groupby('제작자').size().to_frame('count')
x = tmp_4.index
y = tmp_4['count']
plt.figure(figsize=(8,3)) # 스케치북
plt.bar(x=x, height=y)
plt.xticks(rotation=270, ticks=tmp_4.index) # 축 이름 회전
plt.title('2022년 4분기 제작자별 리콜 건수') # 차트 제목
plt.show() 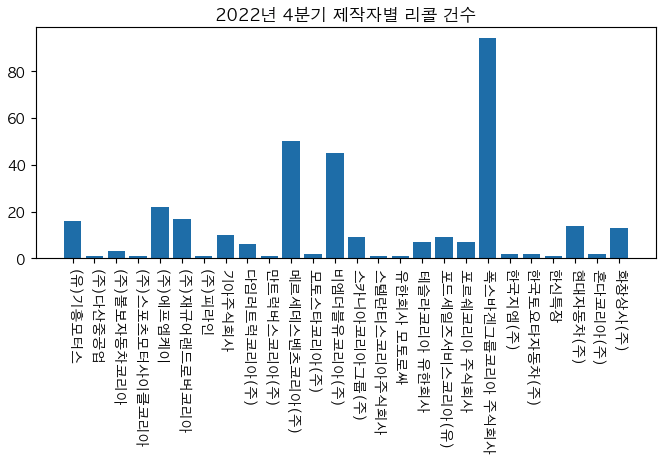
pie 그래프
tmp_4 = df_4.groupby('제작자').size().sort_values(ascending=False).to_frame('count').head(10)
x = tmp_4.index
y = tmp_4['count']
plt.figure(figsize=(10,6)) # 스케치북
plt.pie(y,labels=x, autopct='%.1f%%') # 뒤에 소수점 1자리까지 나오도록 할래
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('2022년 4분기 제작자별 리콜 건수') # 차트 제목
plt.show() # 출력하라 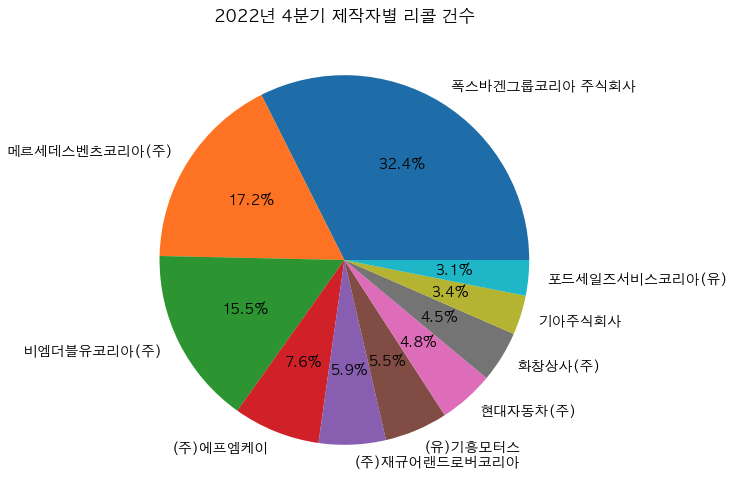
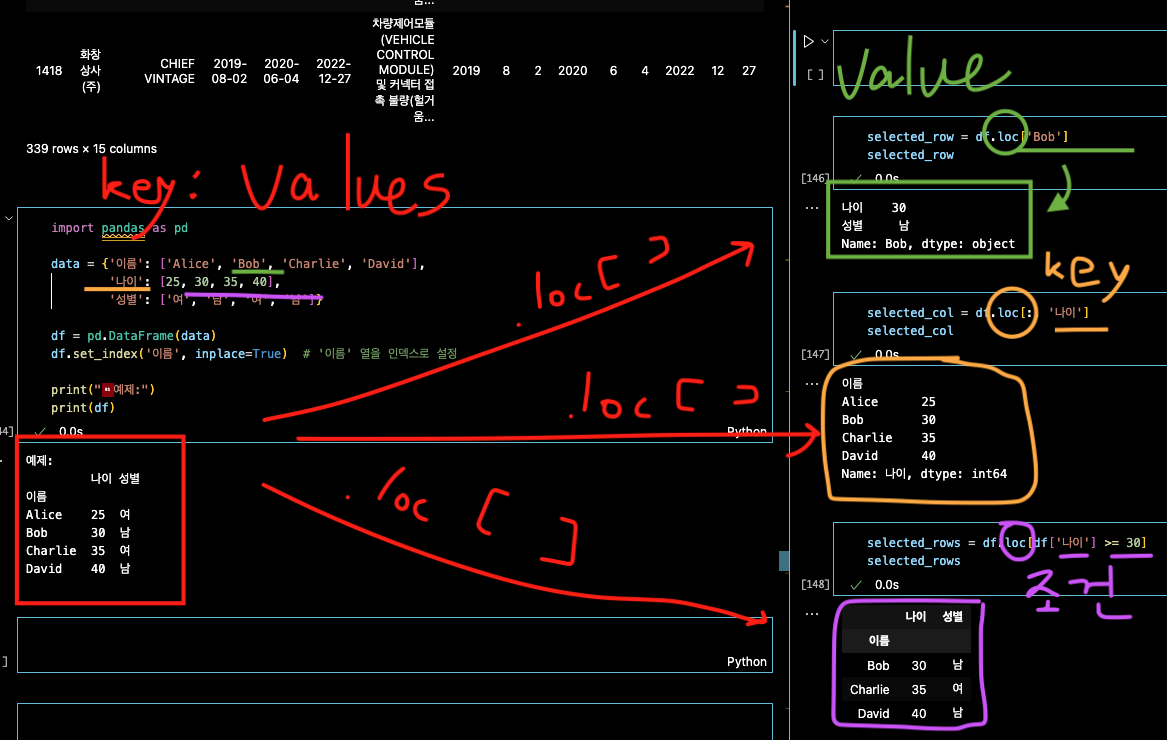
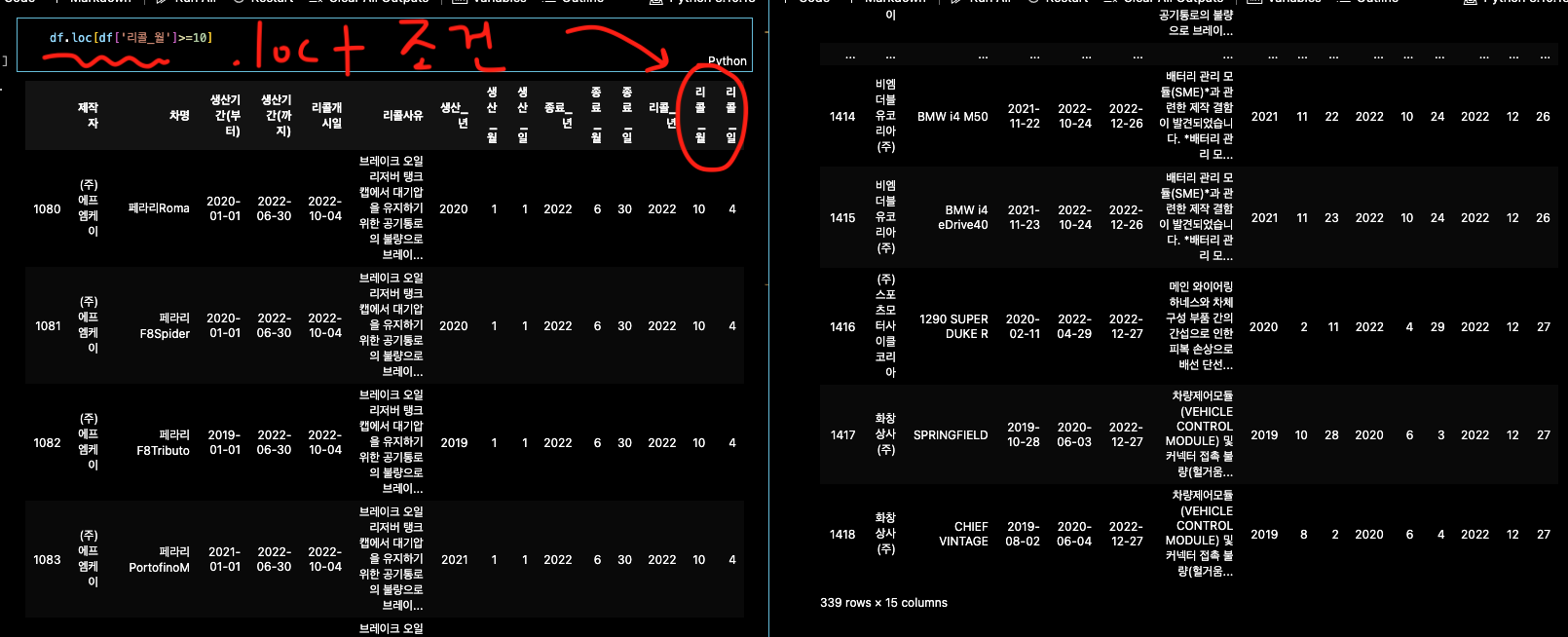
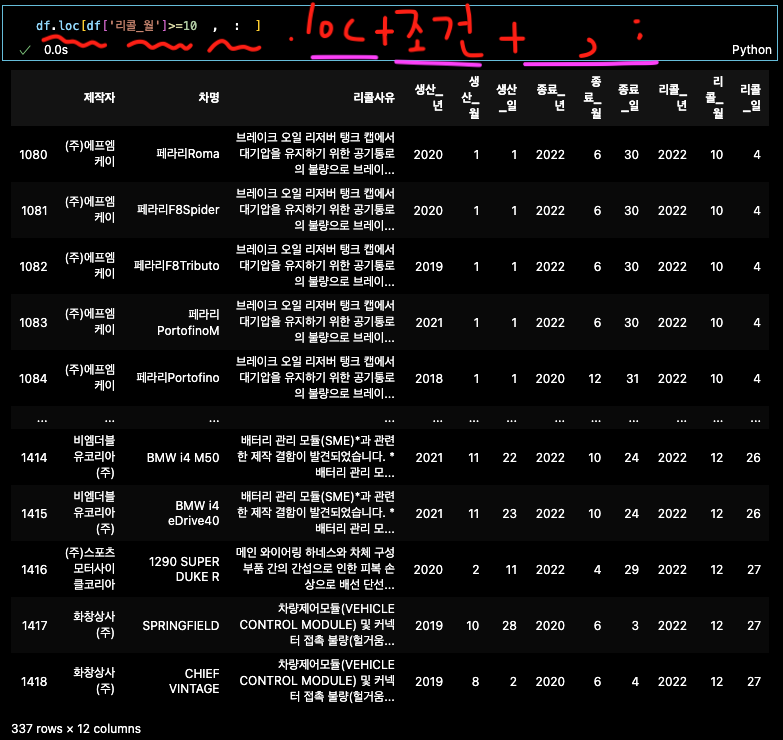
.loc()통해서 특정 열,행을 선택->새로 데이터프레임화
특정 행, 특정 열, 특정 조건에 맞는 행 선택시 필요
3개의 비슷하지만 다른
df
[df['리콜_월']>=10]: 해당column 행 선택
df.loc[df['리콜_월']>=10] : 해당 column행
df.loc[df['리콜_월']>=10, :]
3.6 하반기-생산년도별 리콜 현황
2022년 하반기 (7월~12월) 개시된 리콜 건들을 생산 게시 연도 기준으로 시각화하기
기준 = '리콜_년'이 2022년
조건 = '리콜_월'이 7월부터~ (7월~12월)
확인하기
변수 = (df['컬럼1'조건]) & (df['컬럼2'조건])
변수
cond = (df['리콜_년']==2022) & (df['리콜_월']>=7)
cond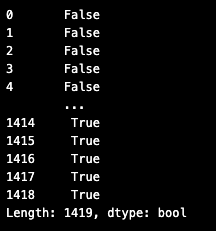
df[변수]
df[cond]
df.loc[cond, ]
# 둘 다 어자피 출력값은 같다. 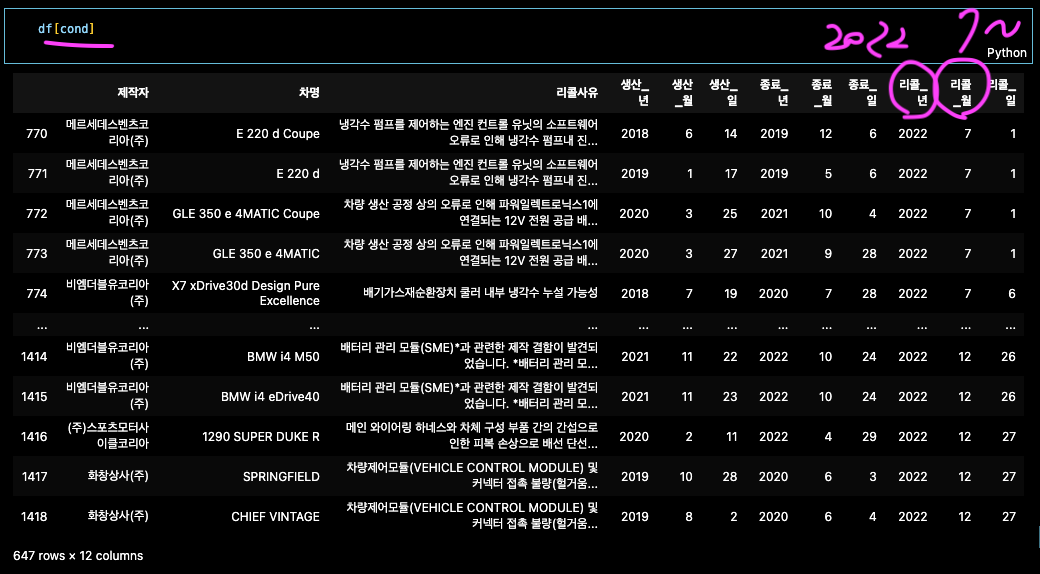
bar 그래프
순서
# 코드 제작 순서 (하나씩 해보고 실행하는지 체크해보면서 하자)
df['리콜_년']==2022
df['리콜_월']>=7
(df['리콜_년']==2022) & (df['리콜_월']>=7)
(df['리콜_년']==2022) & (df['리콜_월']>=7).groupby('생산_년')
(df['리콜_년']==2022) & (df['리콜_월']>=7).groupby('생산_년').size()
(df['리콜_년']==2022) & (df['리콜_월']>=7).groupby('생산_년').size().to_frame('count')코드
cond = (df['리콜_년']==2022) & (df['리콜_월']>=7)
tmp_after = df.loc[cond].groupby('생산_년').size().to_frame('count')
x = tmp_after.index
y = tmp_after['count']
plt.figure(figsize=(8,4)) # 스케치북
plt.bar(x=x, height=y)
plt.xticks(rotation=270, ticks=tmp_after.index) # 축 이름 회전
plt.title('2022 하반기(7~12월) 생산년도별 리콜현황') # 차트 제목
plt.show() 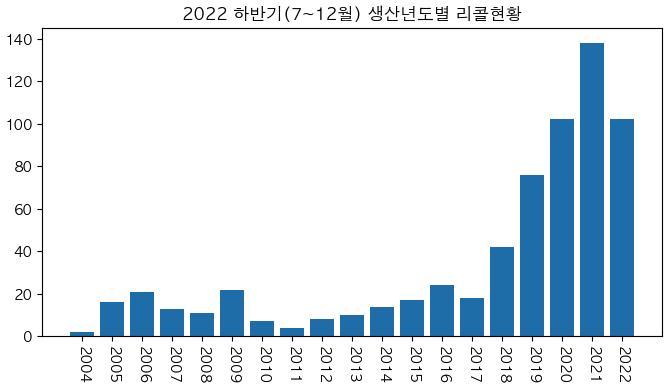
pie 그래프
cond = (df['리콜_년']==2022) & (df['리콜_월']>=7)
tmp_after = df.loc[cond].groupby('생산_년').size().to_frame('count').head(10)
x = tmp_after.index
y = tmp_after['count']
plt.figure(figsize=(10,6)) # 스케치북
plt.pie(y,labels=x, autopct='%.1f%%') # 뒤에 소수점 1자리까지 나오도록 할래
plt.xticks(rotation=270) # x 축 이름 회전 --> 이거 안하면 이름 가로로되서 다 뭉개지고 겹쳐짐
plt.title('2022 하반기(7~12월) 생산년도별 리콜현황') # 차트 제목
plt.show() # 출력하라 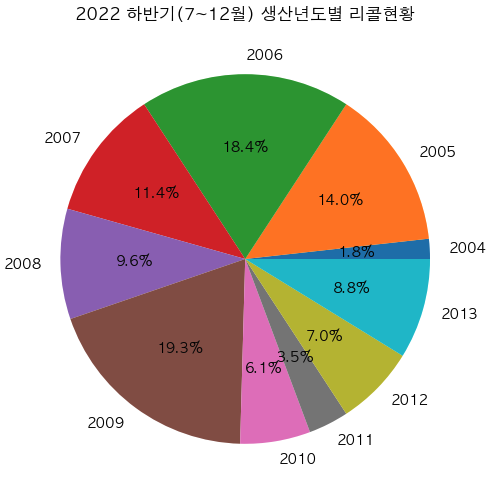
3.7 문제) 2022년 월 별 리콜 현황 많은 달부터 적은 달까지 bar그래프
# 2022년 월 별 리콜 현황이 가장 많은 순부터 적은 순으로 정렬해보자
# 월별 리콜 현황 출력_그래프 월별 구분 없이 내림차순으로 정렬해 보여주는 코드
month = df.groupby('리콜_월').size().sort_values(ascending=False).to_frame('count')
month_m = month.reset_index()
month_m
x = month_m.index
y = month_m['count']
plt.figure(figsize=(8,3))
plt.bar(x=x,height=y)
plt.xticks(rotation=270,ticks=x,labels=month_m['리콜_월'].values)
plt.title('월별 리콜 현황')
plt.show()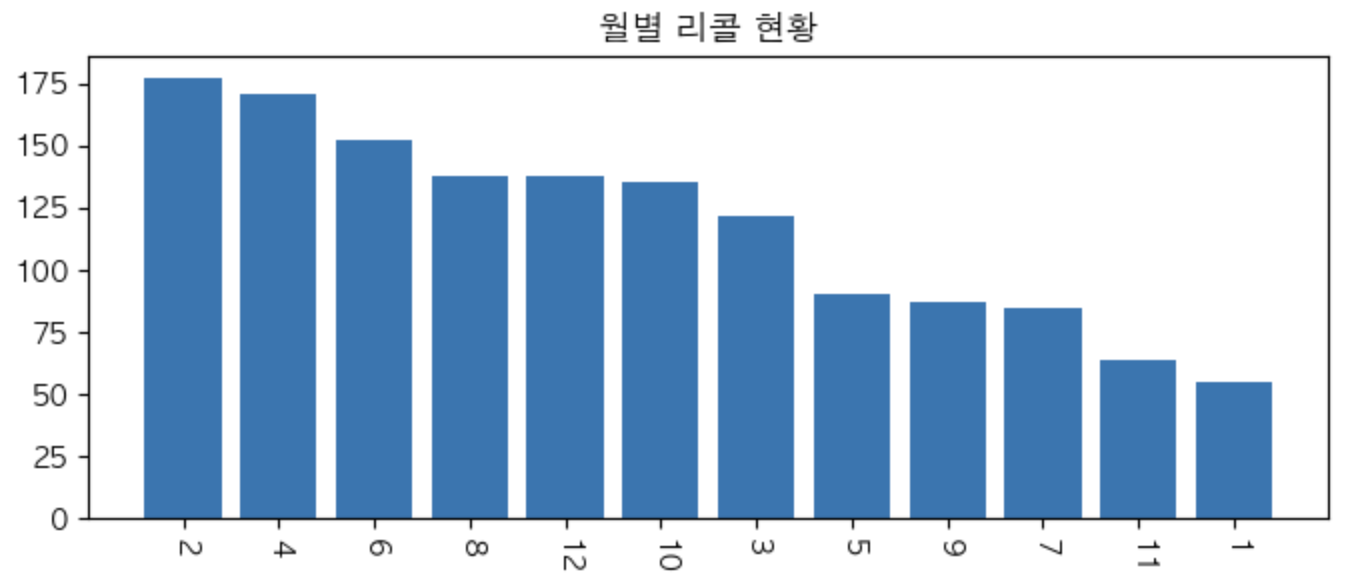
3.8 문제) 특정자동차회사 제품 중 가장 최근 리콜 개시제품명
확인하기
생각해보기 1
# 1. 기아자동차(주)
# '기아'가 들어있는 행 추출하기
# 문자열 포함 행 추출
# df['제작자'].str.contains('기아')
# df['제작자'].str.contains('기아').sum() -> 총 몇 건인지
# df['제작자'].str.contains('기아') 에서 df.loc 하면 해당 조건을 포함한다.
# df.loc[df['제작자'].str.contains('기아')] -> 이렇게 하면 기아주식회사 라고만 나오지, 기아자동차(주)가 안나옴
# 우리는 먼저! 기아자동차(주)가 데이터에 있었는지 확인부터 했었어야 했어
# df['제작자'].unique() --> 기아자동차(주)가 없었고, 기아주식회사가 있다는걸 알 수 있다.
kia_df = df.loc[df['제작자'].str.contains('기아')]생각해보기 2
# 2. 리콜 개시일 중 '최근' 필터링
# 리콜에는 _년, _월, _일 이 있는데 어떻게 해서 '최근'이란 조건을 만들어낼 것인가
# kia_df = df.loc[df['제작자'].str.contains('기아')]
# kia_df.sort_values(by=['리콜_년','리콜_월']) 하게되면
# kia_df.sort_values(by=['리콜_년','리콜_월'],ascending=False)
# 이게 최근 필터링 조건을 건 거다
recent_kia = kia_df.sort_values(by=['리콜_년','리콜_월','리콜_일'],ascending=False) recent_kia.iloc<pandas.core.indexing._iLocIndexer at 0x11fe9f3d0>
recent_kia.iloc[0,1]'카니발'
recent_kia['차명'].head(1).values[0]'카니발'
4. 데이터 시각화 - 워드 클라우드
4.1 STAPWORDS 지정
패키지 불러오기
# 워드 클라우드 생성을 도와주는 패키지를 가져옵니다.
from wordcloud import WordCloud, STOPWORDS시각화 제외할 단어들 따로 저장
# 문법적인 성분들을 배제하기 위해 stopwords들을 따로 저장해둡니다.
set(STOPWORDS)또는 그냥 별도 내가 지정해줄 수도!
# 손으로 직접 리콜 사유와 관련이 적은 문법적 어구들을 배제해보겠습니다.
spwords = set(["동안", "인하여", "있는", "경우", "있습니다", "가능성이", "않을", "차량의", "가", "에", "될", "이",
"인해", "수", "중", "시", "또는", "있음", "의", "및", "있으며", "발생할", "이로", "오류로", "해당"])4.2 준비
df['리콜사유']
# 이렇게 하면, 중복값들도 너무 많이 나온다. 줄줄이 다 나옴!!
0 어쩌구저쩌꾸저너쩌구...
1 이러쿵저러웈ㄴ이렁쿵
2 이러럴어뭉ㅋ 저러웈ㅇ...
1417 차량제어모듈(VEHICLE CONTROL MODULE) 및 커넥터 접촉 불량(헐거움...
1418 차량제어모듈(VEHICLE CONTROL MODULE) 및 커넥터 접촉 불량(헐거움....valuses 는 리스트형식으로 가로로 줄줄이 다나온다.
df['리콜사유'].values
# 이렇게 하면, array([ 리스트 해서 가로로 줄줄이 나온다...중복중복)] 중복값 제거
변수['찾는컬럼명'].drop_duplicates()
df['리콜사유'].drop_duplicates() 하나의 문자열로 합쳐주기
' '.join(변수)
tlist = [ '리콜사유1' , '리콜사유2' , '리콜사유3' ] # 안에 각각의 문자열이 들어가 있다.
# 여기서 ' '.join(tlist) 를 하면 공백으로 하나의 문자열로 합쳐준다.
' '.join(tlist)
하게되면 결과는 단어 사이마다 띄어쓰기가 한 칸 있는 하나의 문자열로 합쳐진다.
'리콜사유1 리콜사유2 리콜사유3'4.3 중복 허용 style
하나의 문자열로 합쳐주기
text = ' '.join(df['리콜사유'].values)
text출력값
'제작 공정 중 라디에이터 캡의 제조 불량으로 라디에이터 캡과 필러넥이 제대로 밀착되지 않아 라디에이터 내부 압력을 일정하게 유지할 수 없습니다. 이로 인해 라디에이터 내부 압력이 높아지면 냉각수 저장.....시각화
# 한글을 사용하기 위해서는 폰트를 지정해주어야 합니다.
pont_path = './NanumGothic.ttf'
wc1 = WordCloud(max_font_size=200, stopwords=spwords, font_path=pont_path,
background_color='white', width=600, height=600)
wc1.generate(text)
plt.figure(figsize=(6, 6))
plt.imshow(wc1)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
stopwords를 추가 + 일부 단어 더 기재해보자.
# 손으로 직접 리콜 사유와 관련이 적은 문법적 어구들을 배제해보겠습니다.
spwords = set(["동안", "인하여", "있는", "경우", "있습니다", "가능성이", "않을", "차량의", "가", "에", "될", "이",
"인해", "수", "중", "시", "또는", "있음", "의", "및", "있으며", "발생할", "이로", "오류로", "해당"])그리고 똑같이
# 한글을 사용하기 위해서는 폰트를 지정해주어야 합니다.
pont_path = './NanumGothic.ttf'
wc1 = WordCloud(max_font_size=200, stopwords=spwords, font_path=pont_path, # 여기에 stopwards 추가 하면 제거됨
background_color='white', width=600, height=600)
wc1.generate(text)
plt.figure(figsize=(6, 6))
plt.imshow(wc1)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
4.4 중복 제거 style
df['리콜사유'].drop_duplicates().values 추가
df['리콜사유'].drop_duplicates().values
text = ' '.join(df['리콜사유'].drop_duplicates().values)
# 한글을 사용하기 위해서는 폰트를 지정해주어야 합니다.
font_path = './NanumGothic.ttf'
# 손으로 직접 리콜 사유와 관련이 적은 문법적 어구들을 배제해보겠습니다.
spwords = set(['차량','성능과',"동안", "인하여", "있는", "경우", "있습니다", "가능성이", "않을", "차량의", "가", "에", "될", "이",
"인해", "수", "중", "시", "또는", "있음", "의", "및", "있으며", "발생할", "이로", "오류로", "해당"])
wc1 = WordCloud(max_font_size=200, stopwords=spwords, font_path=font_path,
background_color='white', width=600, height=600)
##############################
wc1.generate(text)
##############################
plt.figure(figsize=(6, 6))
plt.imshow(wc1)
plt.tight_layout(pad=0)
plt.axis('off')
plt.show()
