데이터 다운받기
import pandas as pd
import numpy as np
data = pd.read_csv('./learn/data20230930/서울교통공사 역주소 및 전화번호_20230831.csv', encoding='euc-kr')
data.info()
data.head()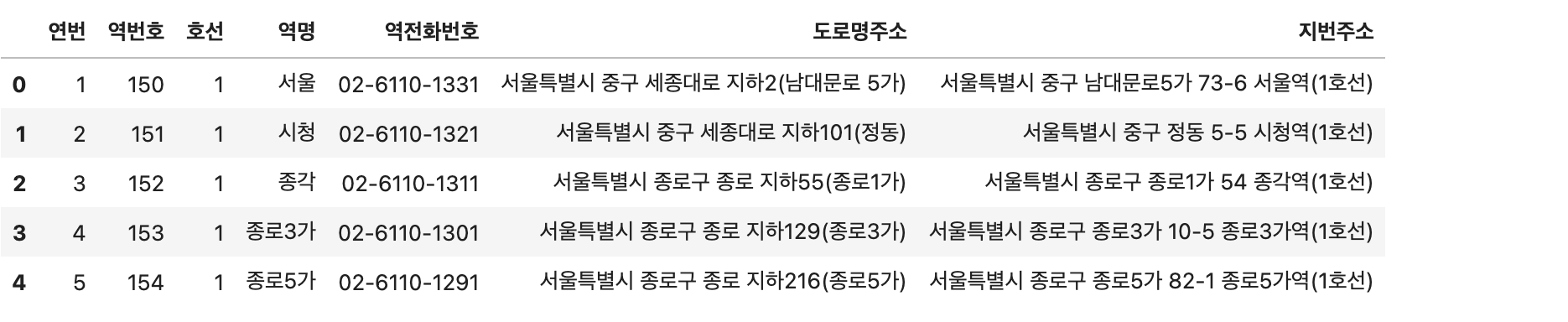
# 호선에 따른 중복되는 역명 확인 (중복값 확인)
data['역명'].value_counts()
중복값 제거
예를들면 '서울'역 1호선과 4호선 = 2개 중복 되어있음
그냥 역이름 한개씩만 남기고 나머지 중복값 제거
# 첫번째값만 남기고 나머지 중복값 삭제
data = data.drop_duplicates('역명', keep='first') # 마지막거 살릴경우 'last'
# 확인
data[data['역명']=='서울']
# 호선에 따른 중복되는 역명 확인 (중복값 확인)
data['역명'].value_counts()
# 발췌할 주소 확인
data['도로명주소']
data['도로명주소'][0]
위도/경도 추출해서 지도 시각화
만들어둔 함수에 주소 추출해서 지도 시각화

viz_map(data['도로명주소'][0])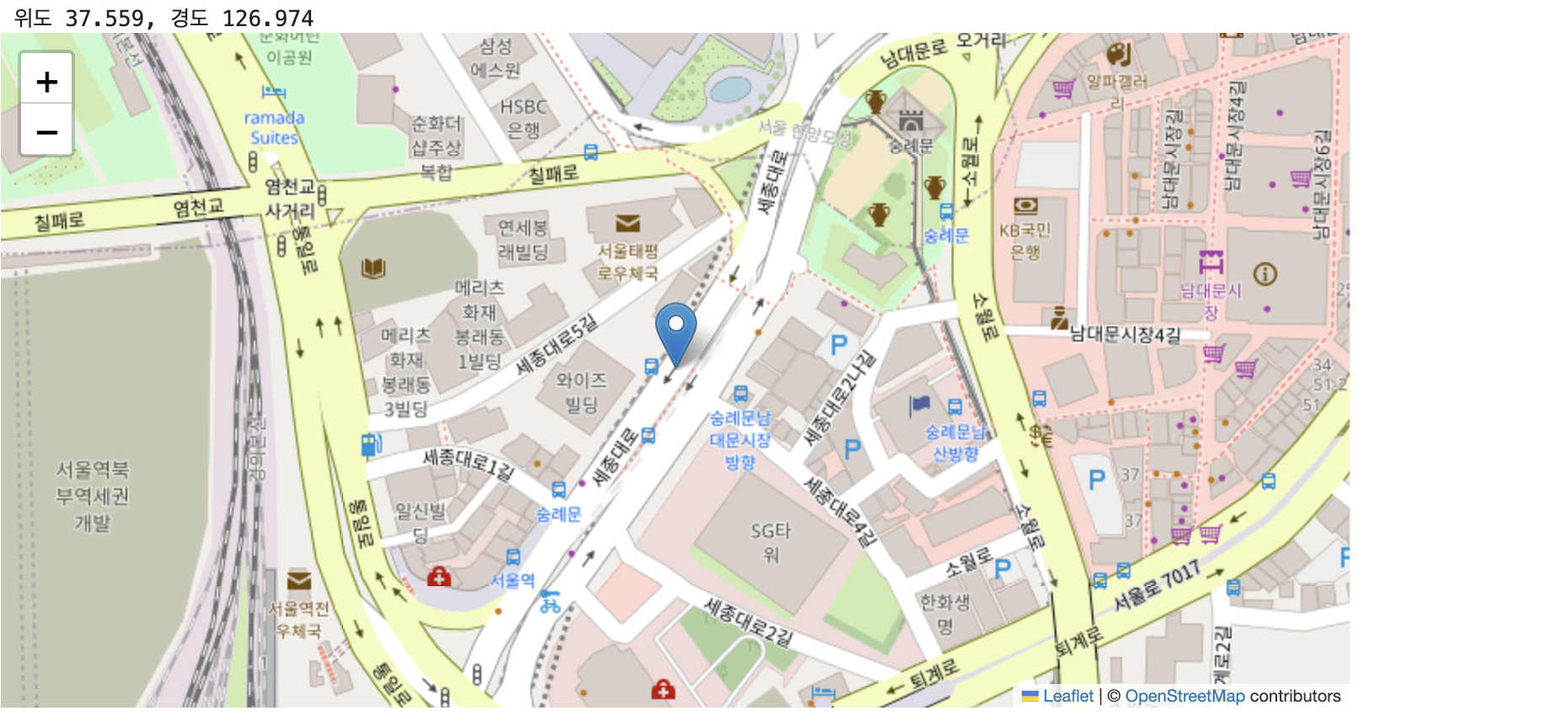
정확한 위치가 아니긴 하나, 이정도는 어쩔수 없는 것 같습니다.
도로명주소가 아닌, 지번주소로 발췌 진행
정규표현식으로 주소데이터 정제
정규(표현)식 이란 ,
특정한 규칙을 가진 문자열의 집합을 표현하는데, 사용하는 형식 언어
Regular Expression = Regex 혹은 Regexp 라고도 불림.비밀번호 정규식, 핸드폰번호 정규식, 이메일주소 추출 정규식 등등
구글링 해보면, 이미 다른 사람들이 만들어 놓은 정규표현식들이 많음.
주소 끝부분 괄호 안에 (00동) 을 제거하기 위해, 정규표현식 사용
station_list = list(data['지번주소'])
station_list
# 주소 데이터 정제
# 방식 : 레귤러 익스프레션 Regex (정규표현식)
# 목적 : 끝에 있는 괄호(00동) 제거
# 정규표현식 모듈 불러오기
import re
# Regular Expression 적용하여 ()괄호를 제거 후 추출
pattern_string = r'.+(?=\()'
pattern = re.compile(pattern_string)
# 제거되는지 확인 + strip()으로 공백까지 제거
pattern.match('서울특별시 중구 세종대로 지하2(남대문로 5가)').group().strip()
정규표현식으로 주소데이터 정제하는 함수
# 주소데이터 정제 함수
def clean_address(x):
location = pattern.match(x) # (주소 입력하면, 정규표현식으로 ()제거되는 함수
if location : # 공백까지 제거해서 적용
loc = location.group().strip()
else: # ()가 없는 주소의 경우 그냥 그대로 출력되게
loc = x
return loc
# 적용되는지 확인
clean_address('서울특별시 중구 세종대로 지하2(남대문로 5가)')
기존데이터 확인
data.head()
주소 정제하는 함수 적용해서 컬럼 추가
data['주소'] = data['지번주소'].apply(clean_address)변경데이터 확인
data.head()
위/경도 추출
함수 생성
def geocode(x):
results = maps. geocode(x)
if len(results) > 0 : # 뭔가 찾았으면!
result = results[0] # 저쟝하고,,,, 출력!
return result['geometry']['location']['lat'],result['geometry']['location']['lng']
else:
return np.nan
위의 함수를 적용했더니 위도와 경도가 별도 추출된다.
컬럼 생성
data['위경도'] = data['주소'].apply(geocode)
data.head()적용되는데 다소 시간이 소요될 수 있습니다.

결측치 확인
# 새 컬럼에 결측치 확인
data.isnull().sum()
data[data['위경도'].isnull()]
엥? 결측치가 1개 있습니다.;;;
data[data['위경도'].isnull()]
수동으로 검색하니, 위경도가 정상적으로 출력됩니다.
geocode('뚝섬역') 우선 결측치가 1개니까, 그냥 수동으로 대체값을 입력합니다.
# 결측치가 있는 특정 행의 인덱스를 지정
null_19_row = 19
# 수동으로 입력한 위경도 값을 해당 행에 적용
data.at[null_19_row, '위경도'] = (37.547206, 127.047405)
# 결측치 없음 확인
data[data['위경도'].isnull()]
이제 결측치가 없는 깨끗한 상황입니다.
위도, 경도 별도 추출
data['lat'] = data['위경도'].str[0]
data['lng'] = data['위경도'].str[1]
data.head()
필요 컬럼만
data[['호선','역명','lat','lng','주소','역전화번호']]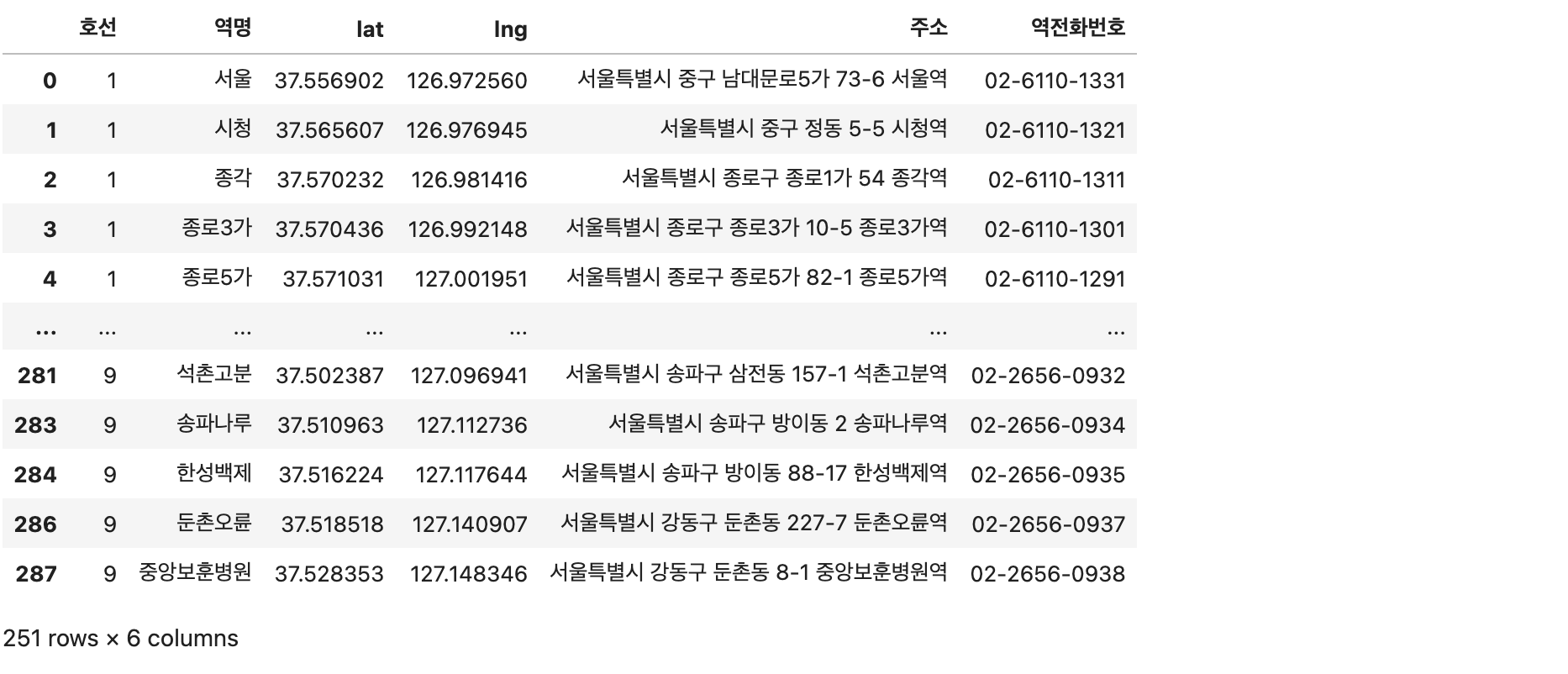
csv파일로 저장
data[['호선','역명','lat','lng','주소','역전화번호']].to_csv('seoul_station_geocode.csv', index=False)# 저장된 파일 불러와서 확인
check = pd.read_csv('seoul_station_geocode.csv')
check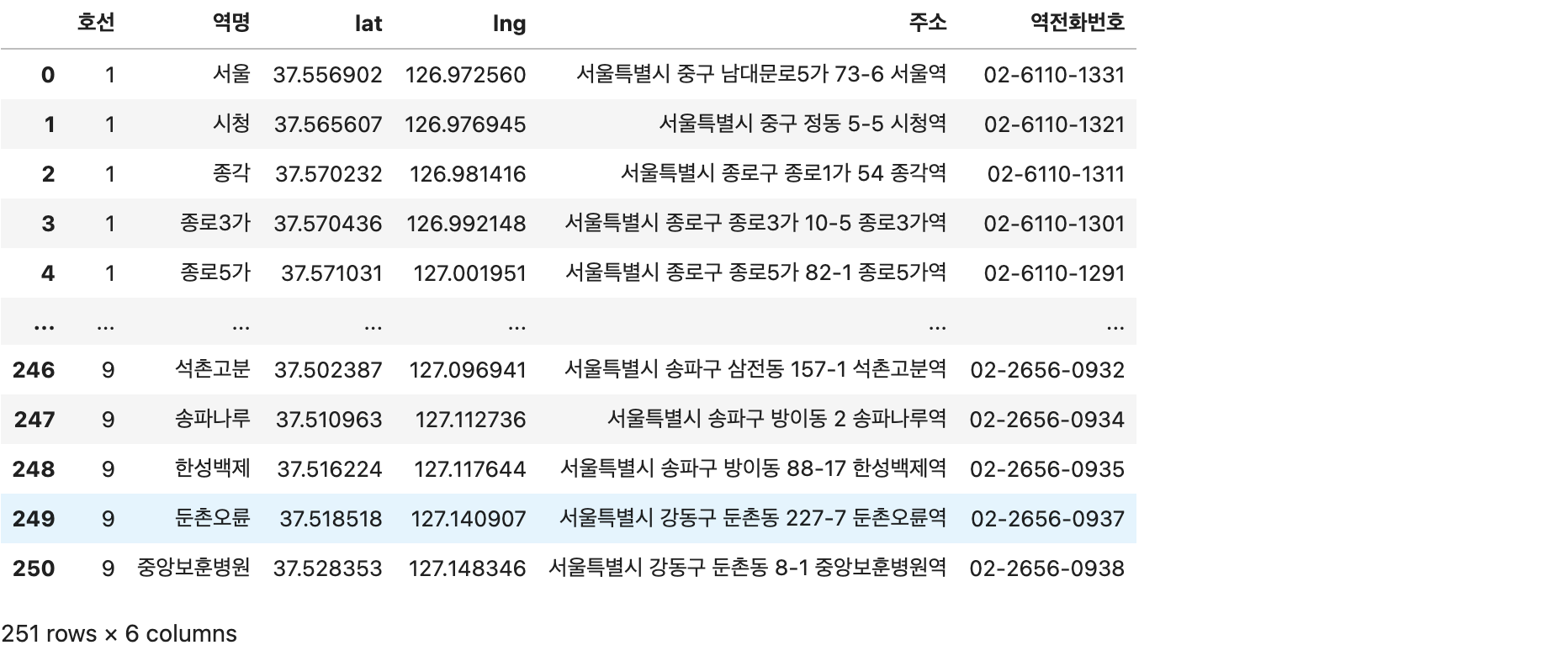

데이터기반 스토리텔링을 통해 인사이트를 얻습니다.