기초셋팅
############################################
# OS환경 : Mac OS
# VS coda -> Jupyter lab
############################################ 초기셋팅
import os
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib import font_manager, rc
import platform
import matplotlib
import warnings
warnings.filterwarnings('ignore')
############################################ 여기서 Matplotlib 코드를 사용하여 그래프 생성 및 표시
%matplotlib inline
############################################ 시각화 셋팅
import matplotlib.font_manager as fm
import matplotlib.pyplot as plt
## 폰트 설정 및 마이너스 부호 설정
plt.rc('font', family='NanumSquare') #나눔 글꼴로 설정
#plt.rc('font', family='Malgun Gothic') #맑은 고딕으로 설정
plt.rc('font', family='AppleGothic') #맥
plt.rcParams['axes.unicode_minus'] = False #부호
############################################ Google Maps 설치
# !pip install googlemapsdata = pd.read_csv('./learn/data20230930/서울교통공사_월별 승하차인원_20221231.csv',encoding='euc-kr')
data.info()
data.head()
data[data['고유역번호(외부역코드)']==150]
이렇게 하나의 역에 row별로 월별 승하차인원수가 정렬되어있으면 제법 어렵습니다. 피벗테이블로 coloumn별 월별 승하차인원수로 재정렬 해줍니다.
피벗테이블
# 수송연월을 기준으로 피벗 테이블 생성
pivot_data = data.pivot_table(index=['호선','고유역번호(외부역코드)', '역명'], columns='수송연월', values='승하차인원수', aggfunc='sum').reset_index()
pivot_data
중복값 확인
서울역에 1호선과 4호선이 있어 2개의 rows로 중복되듯이, 중복되는 환승역 데이터가 몇 개 있습니다.
pivot_data[pivot_data['역명']=='서울역(4)']
pivot_data[pivot_data['역명']=='서울역(1)']
정규표현식으로 역이름 수정
서울역(4), 서울역(1) ---> 서울역
이렇게 수정되게끔 정규표현식을 이용합니다.
# 역명 정제
# 방식 : 레귤러 익스프레션 Regex (정규표현식)
# 목적 : 끝에 있는 괄호(숫자) 제거
# 정규표현식 모듈 불러오기
import re
# Regular Expression 적용하여 ()괄호를 제거 후 추출
pattern_string = r'.+(?=\()'
pattern = re.compile(pattern_string)
# 제거되는지 확인 + strip()으로 공백까지 제거
pattern.match('서울역(1)').group().strip()또는
# 역명 정제 함수
def clean_station(x):
location = pattern.match(x) # (주소 입력하면, 정규표현식으로 ()제거되는 함수
if location : # 공백까지 제거해서 적용
loc = location.group().strip()
else: # ()가 없는 주소의 경우 그냥 그대로 출력되게
loc = x
return loc
# 적용되는지 확인
clean_station('서울역(1)')결과는 모두 동일하게 서울역(1)이 아닌, 서울역 이 나옵니다.

기존
pivot_data.head()
정규표현식 적용
pivot_data['역명'] = pivot_data['역명'].apply(clean_station)변경
pivot_data.head()
# 결측치 확인
pivot_data['역명'].isnull().sum()다행히 결측치 0으로 나왔습니다.
중복값 확인
# 호선에 따라 중복되는 역
pivot_data[pivot_data['역명']=='서울역']
역명을 그룹화하여 인원을 합쳐줍니다.
지하철역별로 승하차인원 합계
# 호선에 따라 중복되는 역 인원 합치기
new = pivot_data.groupby('역명').sum()
new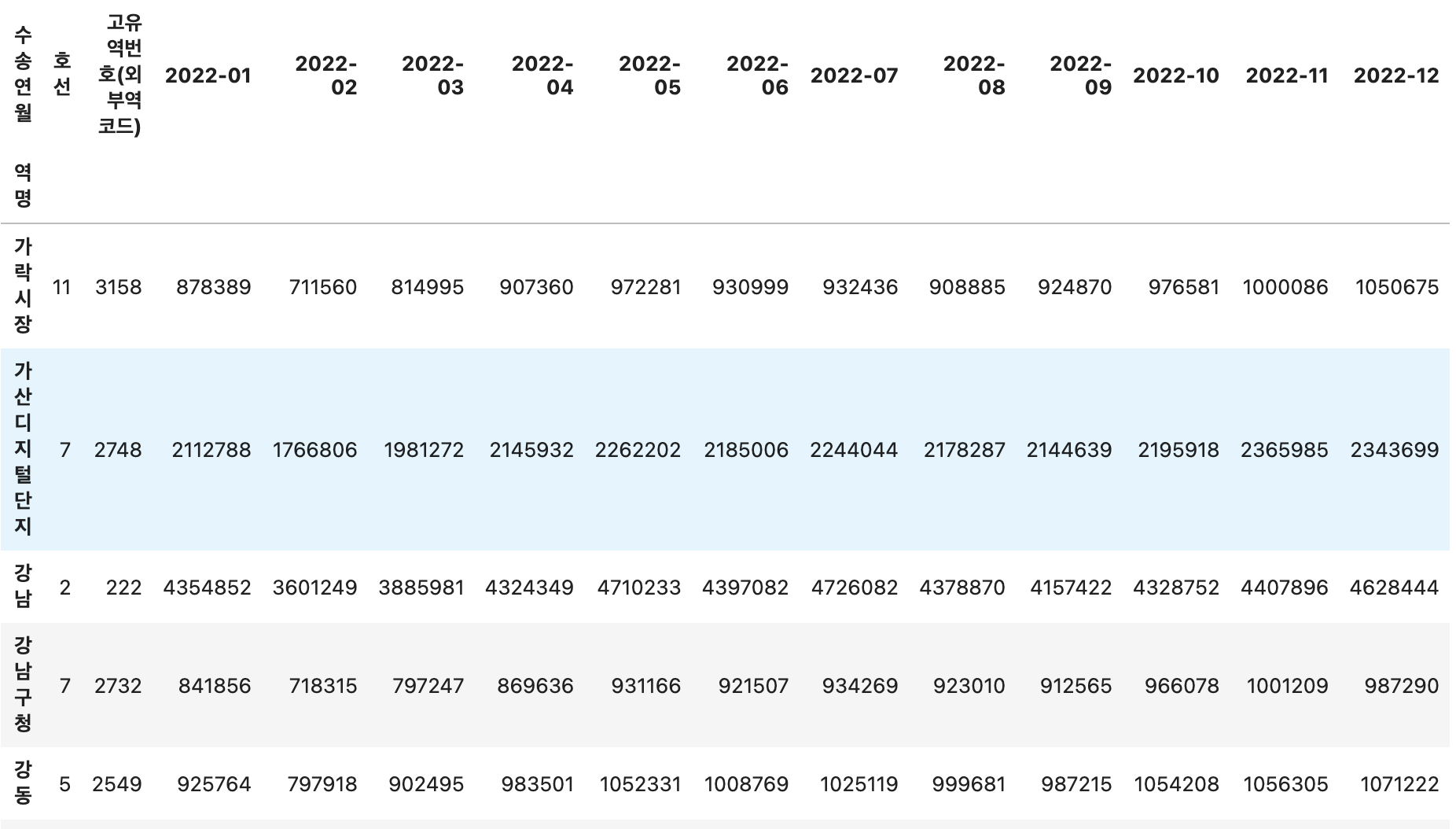
이렇게 하면, 인덱스가 별도 없어, 역명과 함께 무너집니다.
reset_index로 지정해줘야 합니다.
# 호선에 따라 중복되는 역 인원 합치기
new = pivot_data.groupby('역명').sum().reset_index()
new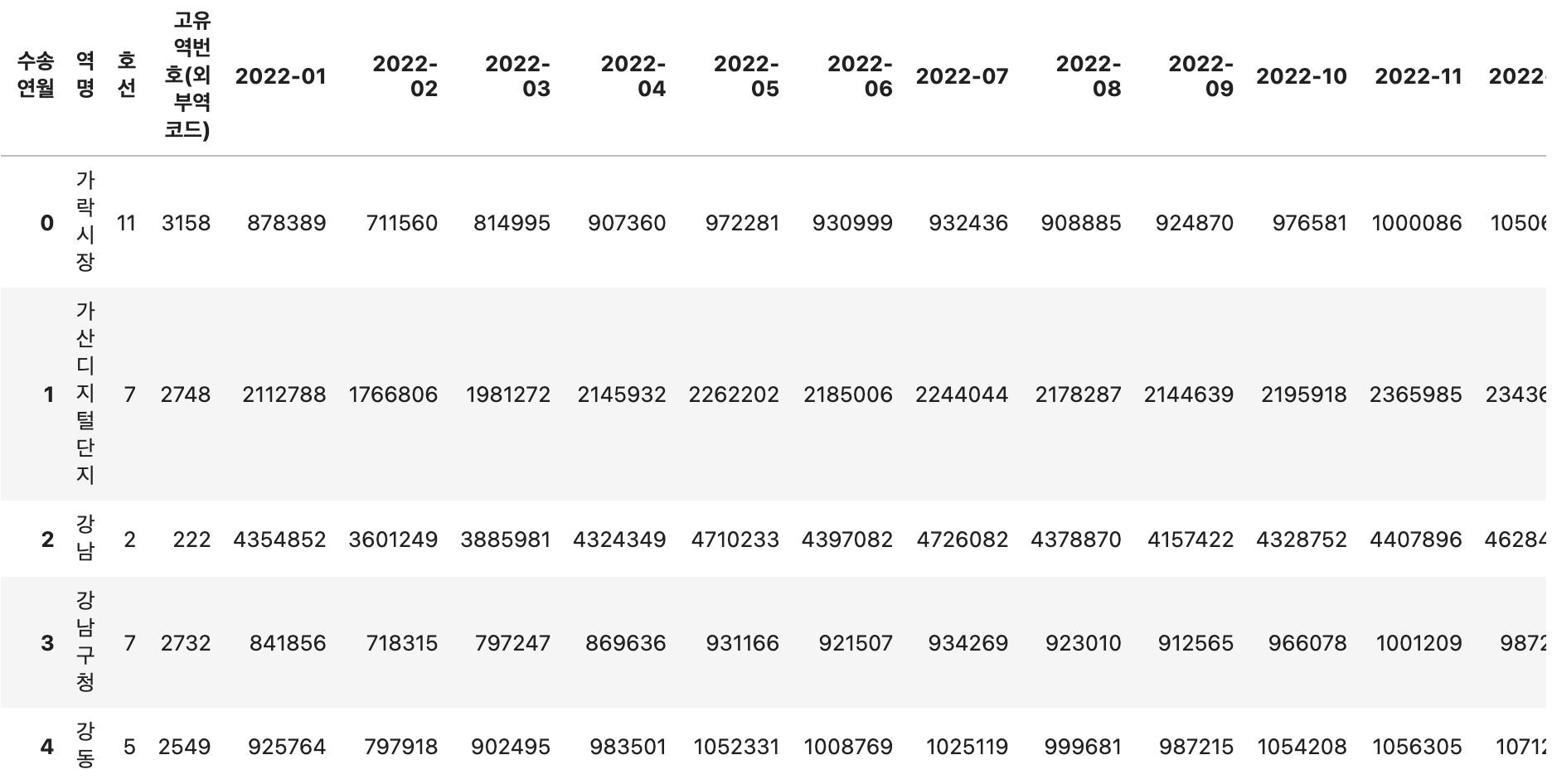
중복역 묶어준게 잘 합쳐졌는지 확인
# 중복역 합치기 확인
new[new['역명']=='서울역']
다행히 1개의 row로 합쳐졌습니다.
그중 필요 없는 컬럼 삭제
# 필요없는 컬럼 제거
new = new.drop(['고유역번호(외부역코드)','호선'], axis=1)
new
월별 지하철역 승하차인원 확인
new[new['역명']=='고속터미널']
new[new['역명']=='서울역']

데이터기반 스토리텔링을 통해 인사이트를 얻습니다.