[R과 Python 다변량분석] 전세계 144개 국가에 대한 국민 행복지수와 군집분석 (표준화, 중심연결법, 계층적 군집, 덴드로그램, 적정군집의 수, k-평균 군집분석)
통계학
방통대 출석과제 30점만점 받은 기념으로 작성합니다.
R
변수별 관찰값 표준화
데이터 불러오기

표준화
군집분석 전, 표준화를 먼저 수행해야합니다.
군집분석은 거리 혹은 유사도 함수 사용하는데, 변수 단위에 영향을 받기 때문입니다.
결측값 제거
NA는 결측값을 나타냅니다. 원본데이터에 있는 결측값을 제거해준 뒤 다시 진행합니다.
다시 표준화
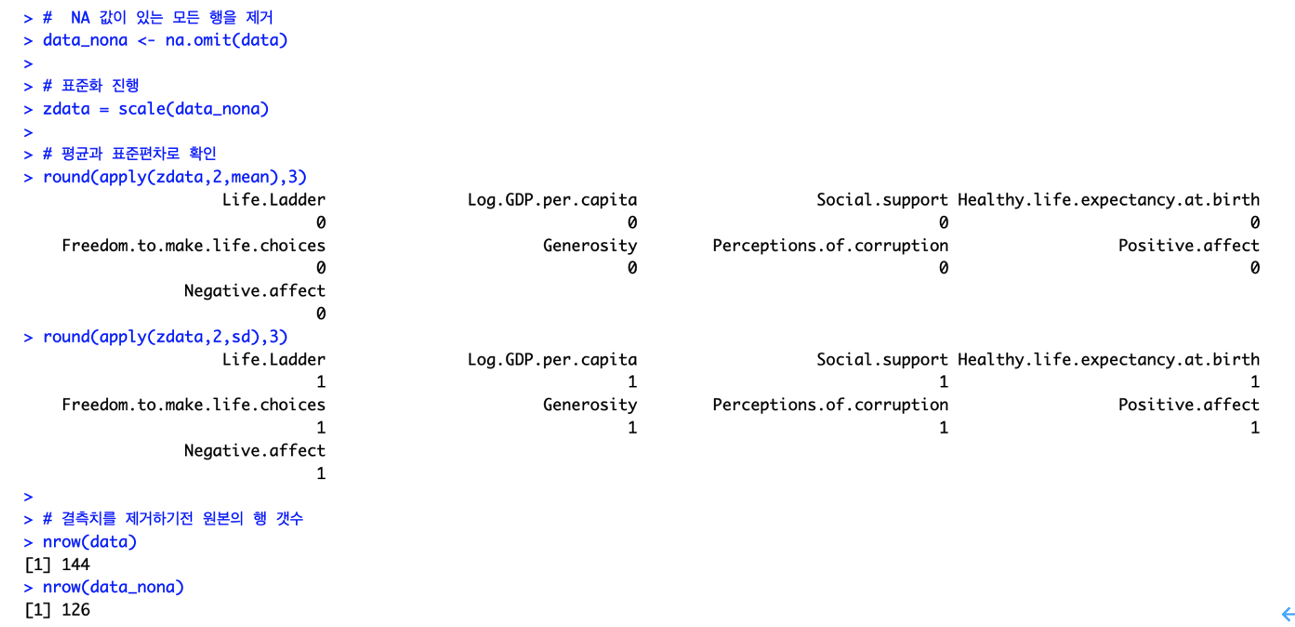
144개의 행이 있었으나, 결측치 제거 후에는 126개의 행으로 줄어들었습니다.
군집화
계층적 군집분석 수행하기 위해서는 관찰치 간 거리 계산이 필수입니다.
만약 관찰치의 총 갯수가 N개라면, 거리행렬은 N x N 크기가 됩니다.
거리행렬 계산 함수인 dis()에는 인수로 거리함수를 지정할 수 있으며 euclidean 유클리디안 거리 공식이 디폴트 인수입니다.
(그 외 manhattan맨하탄, minkowski 민코프스키 거리 등이 있습니다.)
거리행렬 계산하기

계층적 군집분석
중심연결법

덴드로그램
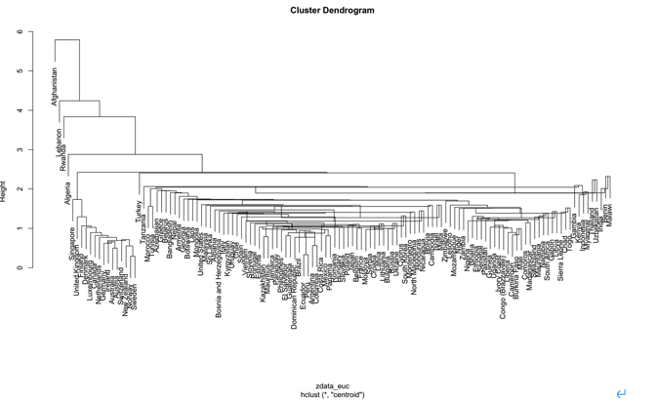
위의 덴드로그램으로 보아, 군집의 갯수는 최소 3개에서 6개 이하가 좋을 것 같습니다.
소속군집
> # 소속군집알기
> hc_cen36 = cutree(hc_cen, 3:6)
> hc_cen36k-평균 군집분석 (3개)
> # k-평균 군집분석
> kmc = k-means(zdata, centers = 3)
> kmc 소속군집 산점도

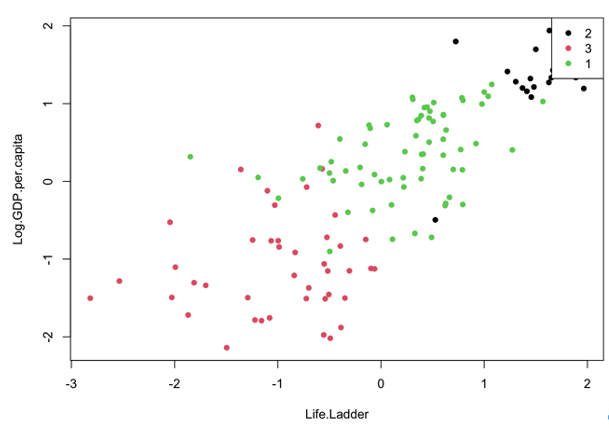
산점도행렬
k-평균 군집 데이터의 모든 변수를 그리는 산점도 행렬을 만들어보겠습니다.
> # k-평균 군집 데이터의 모든 변수를 그리기 위한 명령어
> pairs(zdata, col=kmc$cluster, pch=16, cex.labels=1.5) 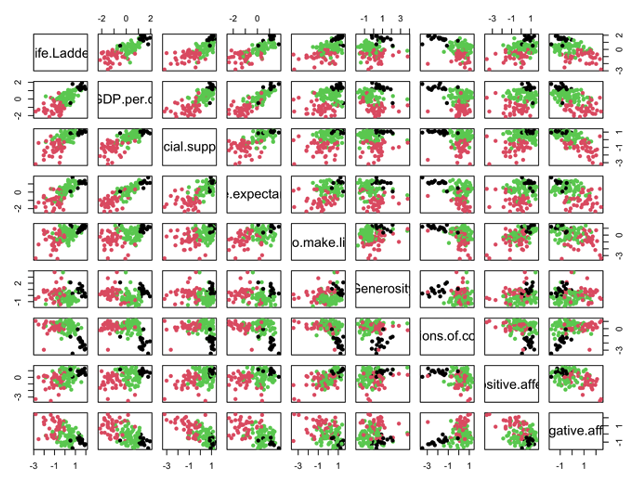
Python
변수별 관찰값 표준화
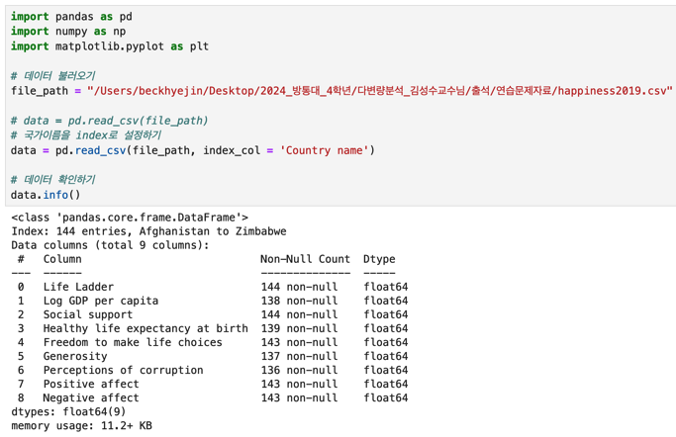
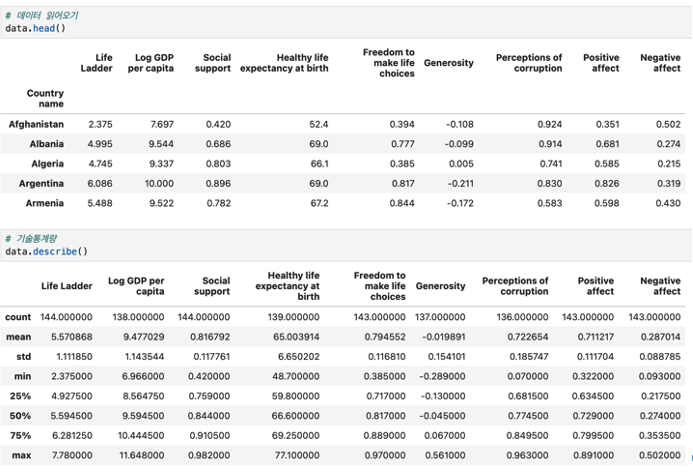
데이터 불러오기
국가명Country name 변수는 수치형이 아니기에 미리 index_col 로 인덱스화하여 불러옵니다. 이렇게 하지않고 그냥 불러올경우, 표준화 할 수가 없어 오류가 납니다.
표준화
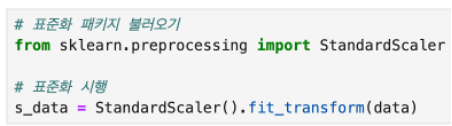
군집화 진행시 오류가 발생되었습니다.
결측값이 있어서, 제거 후 다시 진행하겠습니다.
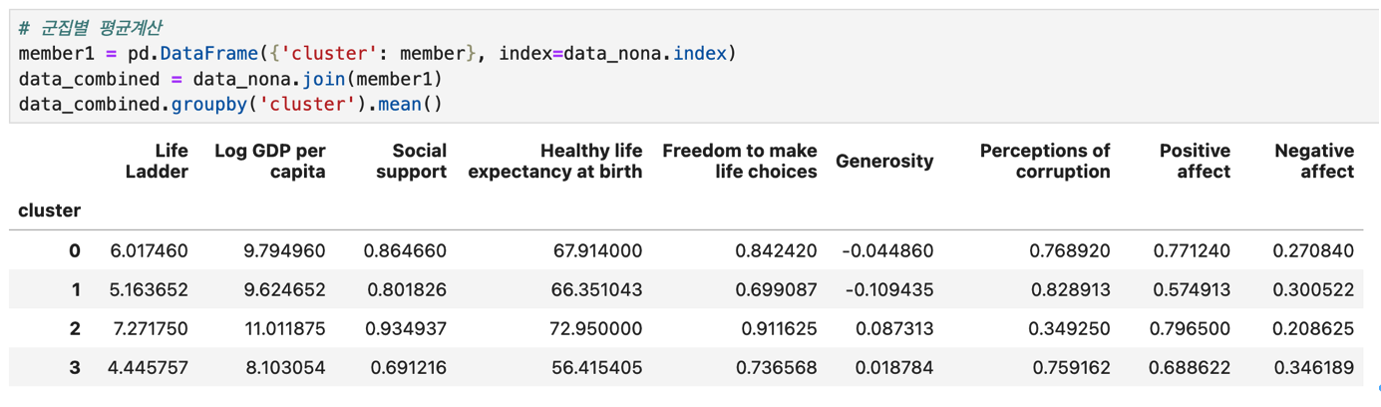
결측값 제거
# 결측값 제거
data_nona = data.dropna()
print(data_nona.shape)
print(Data.shape)
결측값 있는 18개의 행이 제거되었습니다.
다시 표준화

군집화
중심연결법
# 군집분석 패키지 불러오기
import scipy.cluster.hierarchy as sch
# 계층적 군집분석 : 중심연결법
clink = sch.linkage(s_data, 'centroid') 덴드로그램
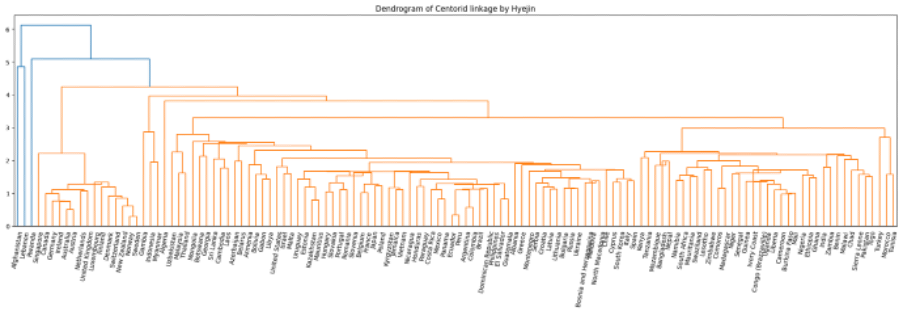
육안상으로는 4개의 군집이 적절하다고 보여집니다.
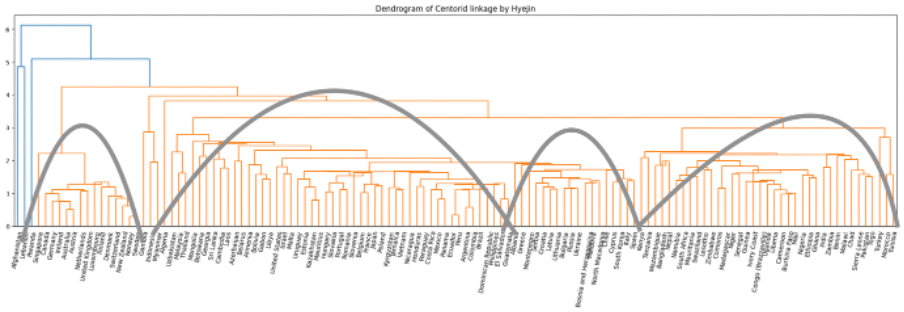
소속군집

계층적 군집분석 결과에 해당하는 소속 군집을 구해보겠습니다.
오류메세지를 보니 버전이 바뀌어 affinity 보다는 metric 로 사용하라고 합니다.
단어만 바꾸어 다시 진행해보겠습니다.
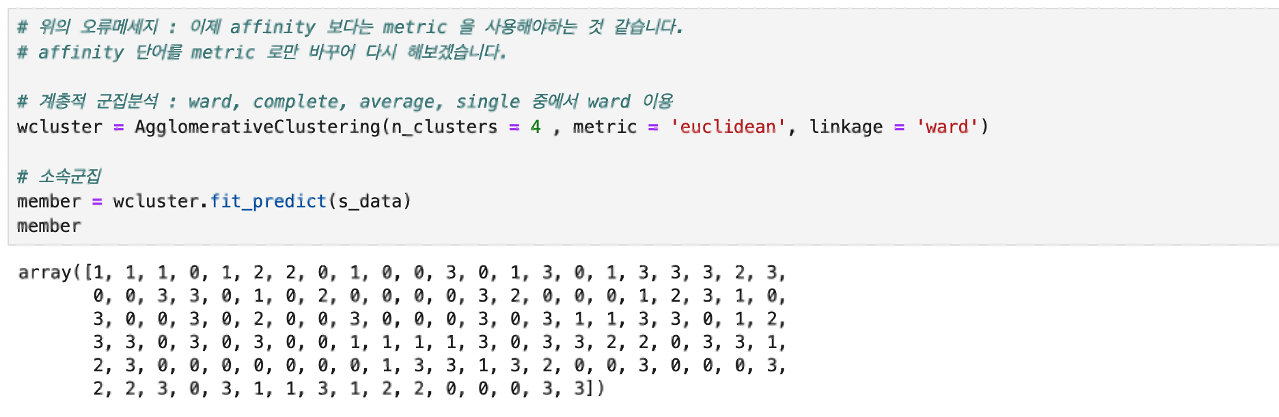
군집별 평균계산
k-평균 군집분석 (3)
다시 결측값을 제거한 데이터로 돌아가서, 표준화 및 k-평균 군집분석을 진행합니다.
오류메세지를 보니 해당 버전에서는 ‘n_init’ 매개변수의 기본값이 10에서 ‘auto’로 변경될거라고 합니다. 일단 별도로 수정하지 않고 그냥 다음 단계로 넘어가겠습니다.
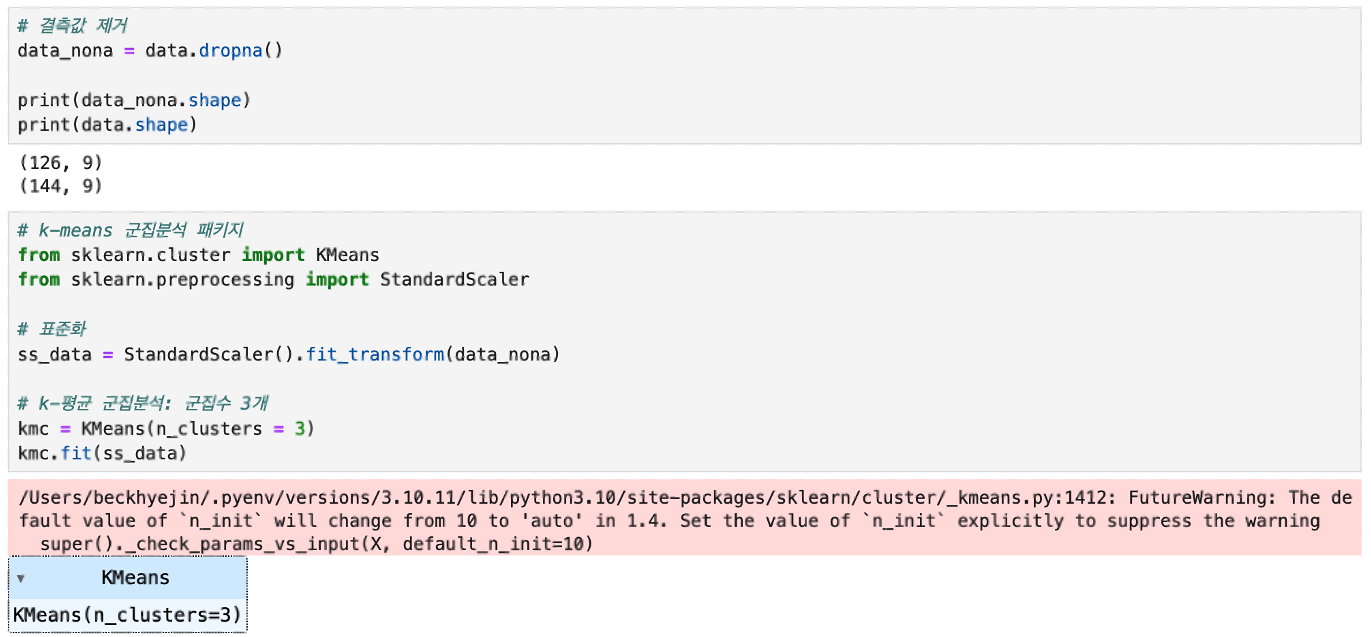
군집 중심과 소속군집
산점도

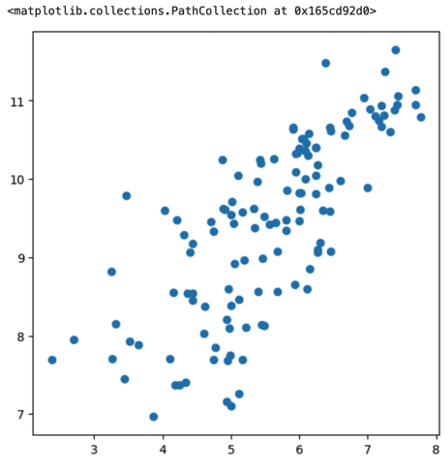
소속 군집 산점도에는 결측값을 제거한 ‘세계행복보고서’데이터의 첫번째 변수인 ‘Life Ladder’ 와 두번째 변수인 ‘Log GDP per capita’ 과의 산점도를 보여주고 있습니다.
X에는 Life Ladder변수를, y에는 나머지 변수들을 각각 넣어 산점도를 보겠습니다.
산점도 비교
plt.ylabel('y에 각각 넣는 변수이름', fontsize=14) 해당 코드를 추가합니다.
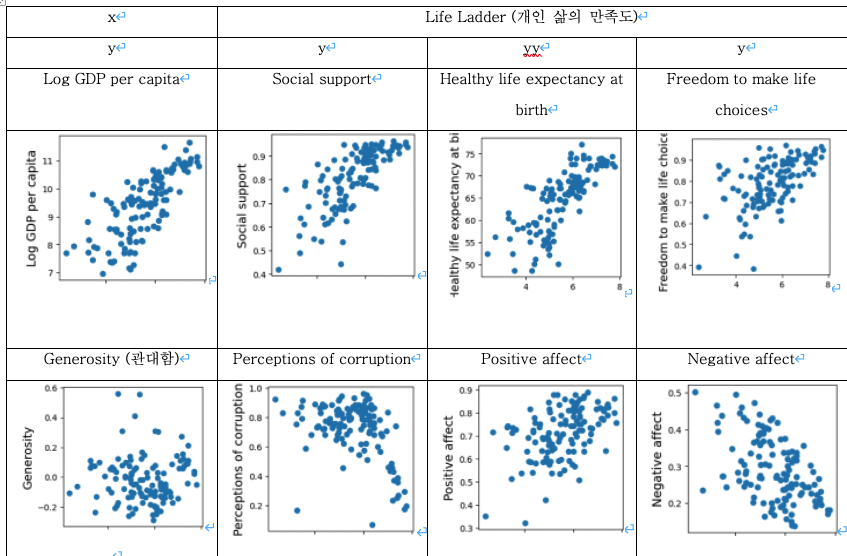
삶의 만족도를 측정하는 Life Ladder와
양의 상관관계를 가지고 있는 변수는
Log GDP per capita, Social support, Healthy life expectancy at birth, Freedom to make life choices, Positive affect 라고 볼 수 있으며
음의 상관관계로는 Perceptions of corruption, Negative affect 입니다.
상관없는 변수는 Generosity 로 보여집니다.
