기초통계량
함수
수량
=count()
합계
=sum()
평균
=average()
중앙값
=median()
평균>중앙값 = 시각화시, 오른쪽으로 꼬리가 긴 형태
평균<중앙값 = 시각화시, 왼쪽으로 꼬리가 긴 형태
평균=중앙값 = 시각화시, 좌우 대칭
최빈값; 가장 많은 빈도를 가지고 있는 수
=mode()
최대값
=max()
=large() (범위, k번째로 큰 값 = 1)
최소값
=min()
=small()
분산
=var.s()
분산이 클 경우, 얕고 퍼져있는 형태
분산이 적을 경우, 높고 뾰족한 형태
표준편차
=stdev.s()
분위(0~25%~50%~75%~100%)
=quanrtile.inc(범위,숫자)
숫자0 = 최대값
숫자1 = 1분위 = 25%
숫자2 = 2분위 = 50%
숫자3 = 3분위 = 75%
숫자4 = 최소값
적용
Mac에서의 단축키
Shift + 화살표 하나의 쉘 포함하여 한 칸씩 드래그
Command + 화살표 그 쉘의 끝 값으로 바로 이동
Shift + Command + 화살표 하나의 쉘 ~ 그 쉘의 끝 값까지 드래그
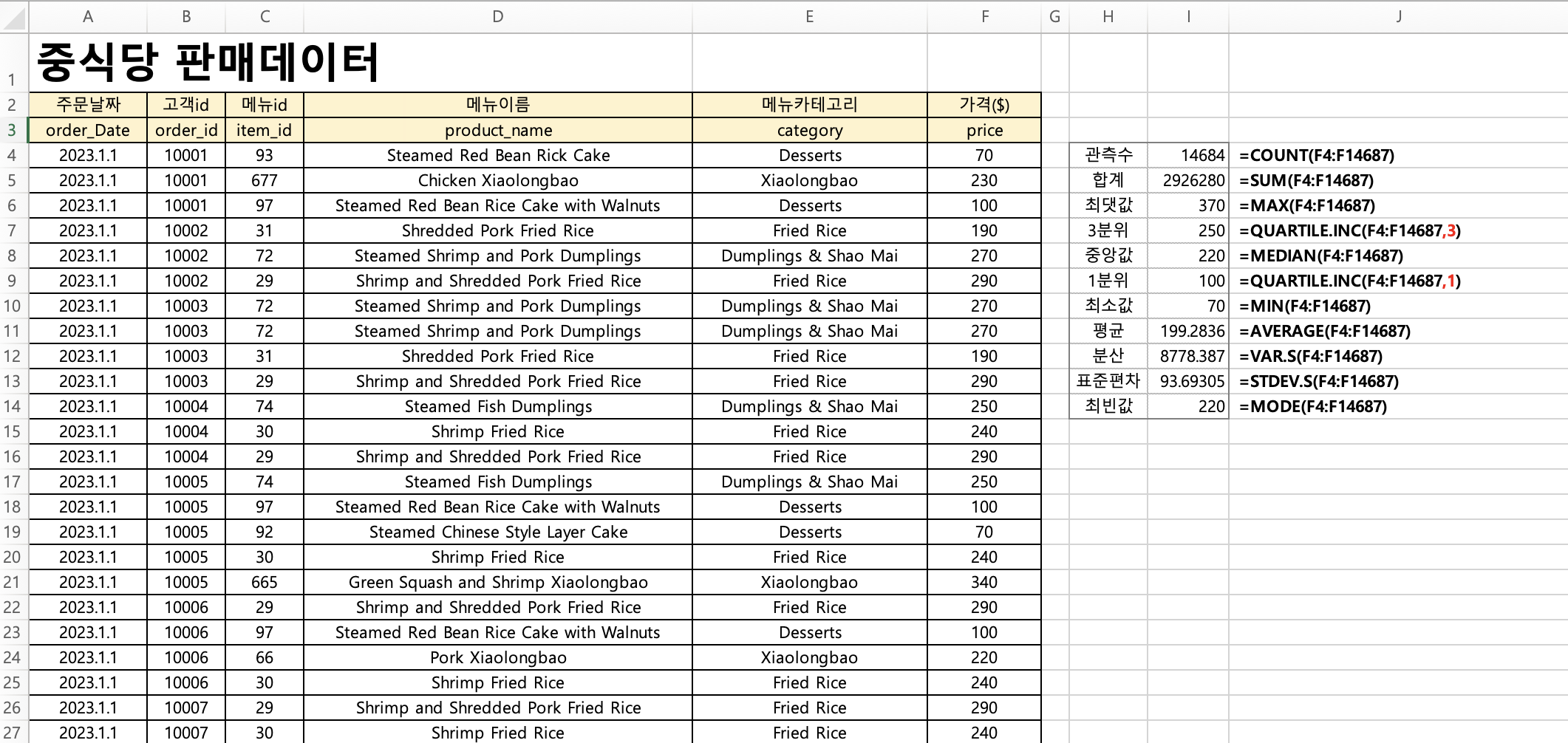
최소값 70 ~ 최대값 370이고 표준편차가 94 , 분산이 8778이면
음식메뉴의 금액 편차가 꽤 큰 것으로 보여진다.
중앙값 220 > 평균 199이면 중앙값이 평균보다 더 크기에
데이터의 분포는 왼쪽으로 꼬리가 긴 형태일것이다.
텍스트추출
함수
왼쪽부터 텍스트 추출
=left(텍스트, 갯수)
오른쪽부터 텍스트 추출
right(텍스트, 갯수)
원하는 위치부터 텍스트 추출
=mid(텍스트, 시작위치, 갯수)
텍스트 글자 수 추출
=len(텍스트)
그러니까, 테스트의 길이 length = 텍스트글자수
특정문자가 몇 번째에 있는지 찾기(순서)
=find(찾는문자, 텍스트)
텍스트 병합
=concat(텍스트1,텍스트2..)
텍스트 서식 지정
=text(값, "표시형식 코드")
표시형식 코드
"aaa" 월,화,수,목...
"#,###" 숫자 천 단위, 구분
"#,##0" 끝자리수 반드시 표기 적용
2173백혜진 --> =left(셀 위치, 4) --> 2173
2173백혜진 --> =right(셀 위치, 3) --> 백혜진
__2173__ --> =mid(셀 위치,3, 4) --> 2173
하나의텍스트를 2개로 쪼개어 분리할 수도 있습니다.
hyejinbeck@gmail.com --> =LEFT(I4,FIND("@",I4)-1) --> hyejinbeck
hyejinbeck@gmail.com --> =right(len(I4)-find("@",I4)) --> gmail.com
이렇게 되면, 사람들의 이메일주소를 통해 이메일아이디+이메일주소를 따로 추출할 수 있습니다.
날짜를 통해, 요일을 알아낼 수도 있습니다.
1993-09-23 --> =text(위치, "aaa") --> 목
1993-09-23 --> =text(위치, "aaaa") --> 목요일