
풀이과정

이대로 외워라
# 초기셋팅 및 불러오기
# 초기셋팅
!pip install -r requirements.txt
# 필요모듈
import pandas as pd
# 데이터 불러오기
data = pd.read_csv('./Dataset_Dataset_04.csv')
# 데이터 확인
data.head()
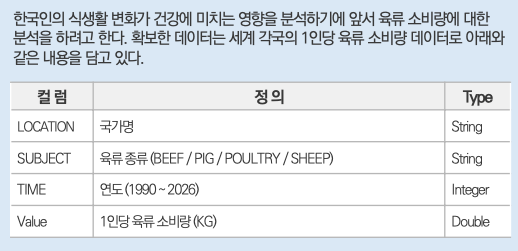
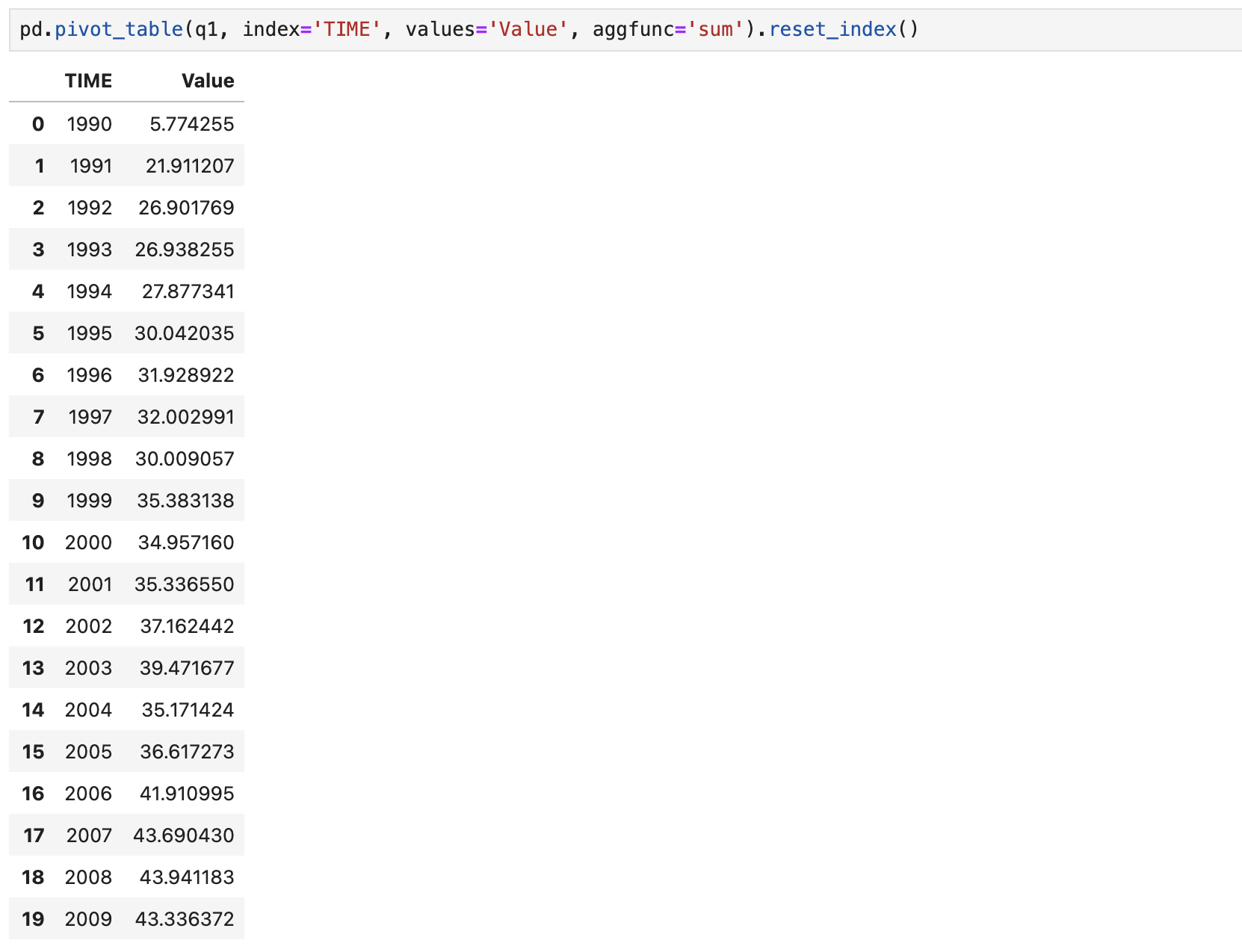
# 한국인 데이터만 추출
q1 = data[data.LOCATION == 'KOR']
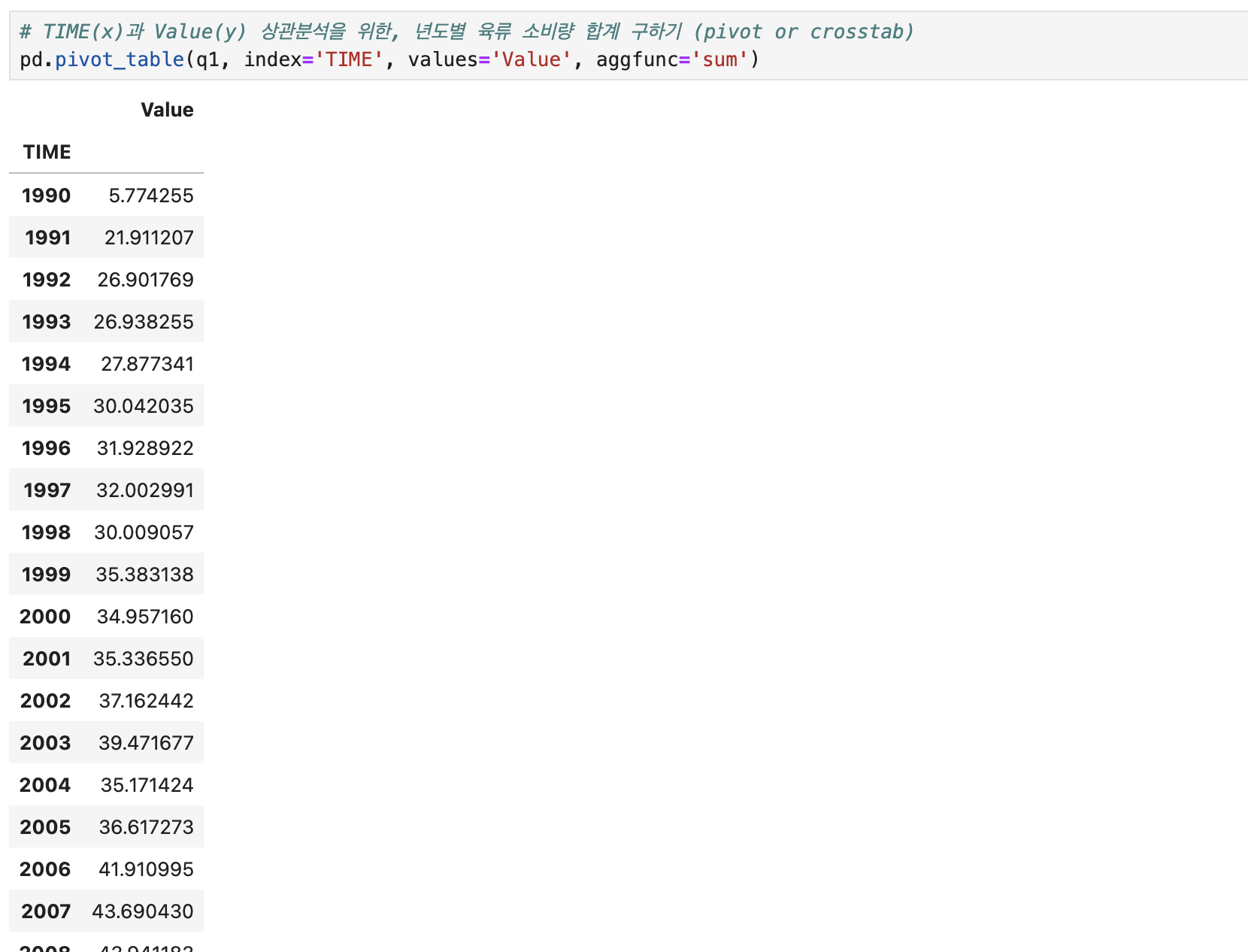
# 년도별 육류 소비량 합계 구하기 (pivot 또는 crosstab가능하며, pivot을 이용하겠다.)
q1_tab = pd.pivot_table(q1, index='TIME', values='Value', aggfunc='sum').reset_index()
q1_cro = pd.crosstab(index='TIME',column='Value',values='Value', aggfunc='sum').reset_index()
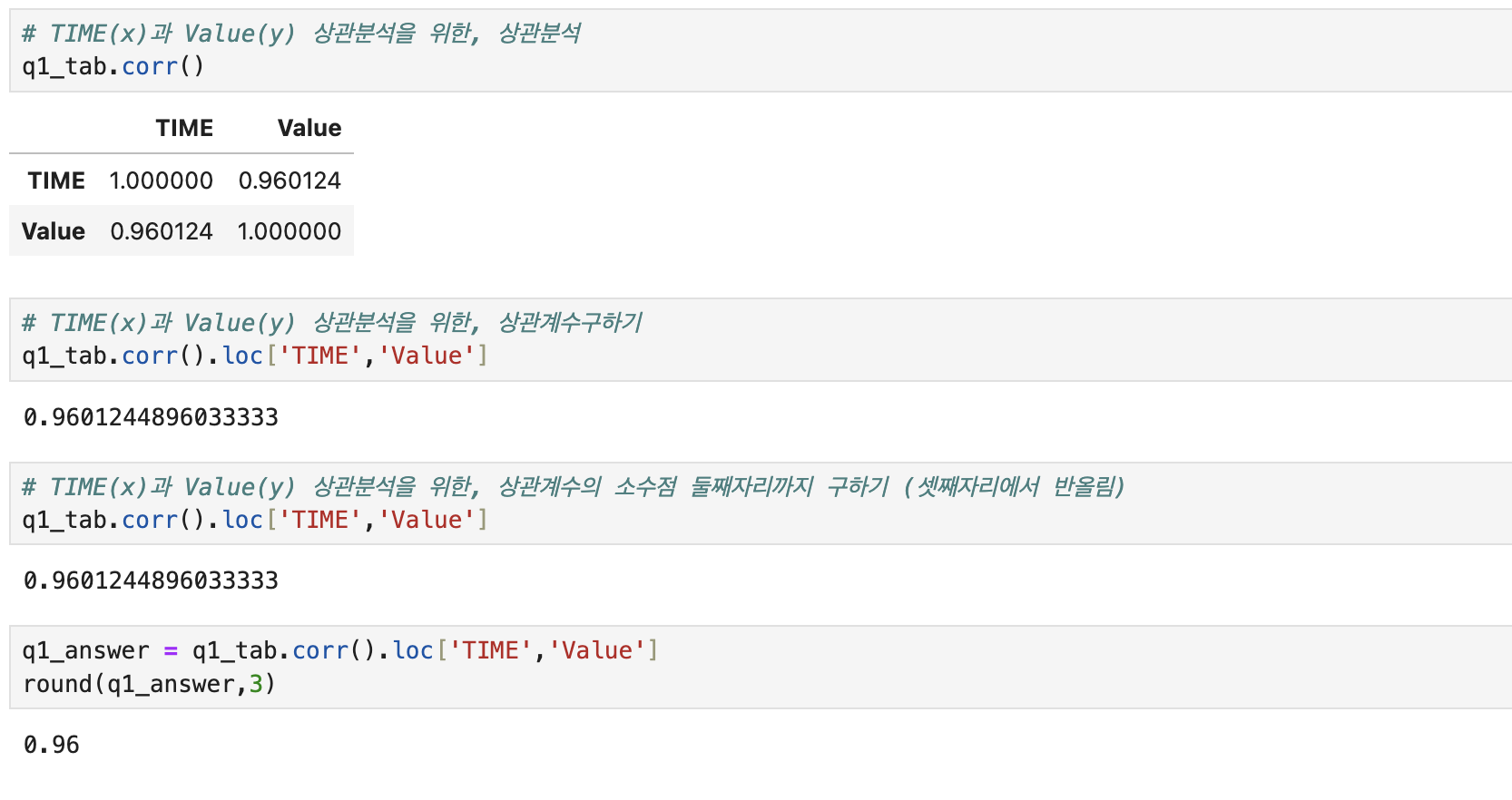
# TIME과 Value의 상관분석
q1_tab.corr()
# TIME과 Value의 상관계수구하기
q1_tab.corr().loc['TIME','Value']
# 상관계수 소수점 셋째자리에서 반올림해서 둘째자리까지 구하기
round(q1_tab.corr().loc['TIME','Value'], 3)
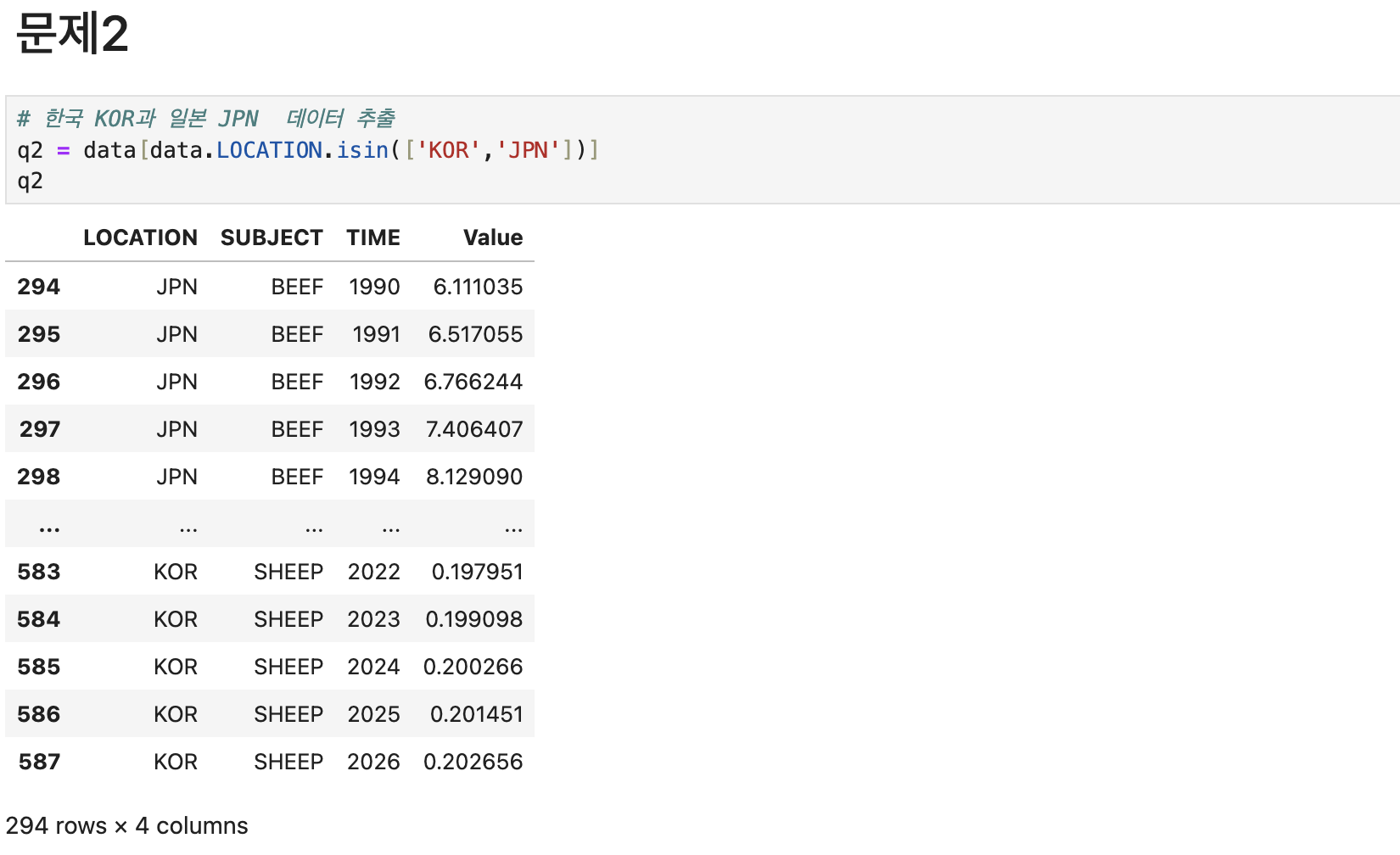
# 한국과 일본 데이터만 추출
q2 = data[data.LOCATION.isin(['KOR','JPN'])]
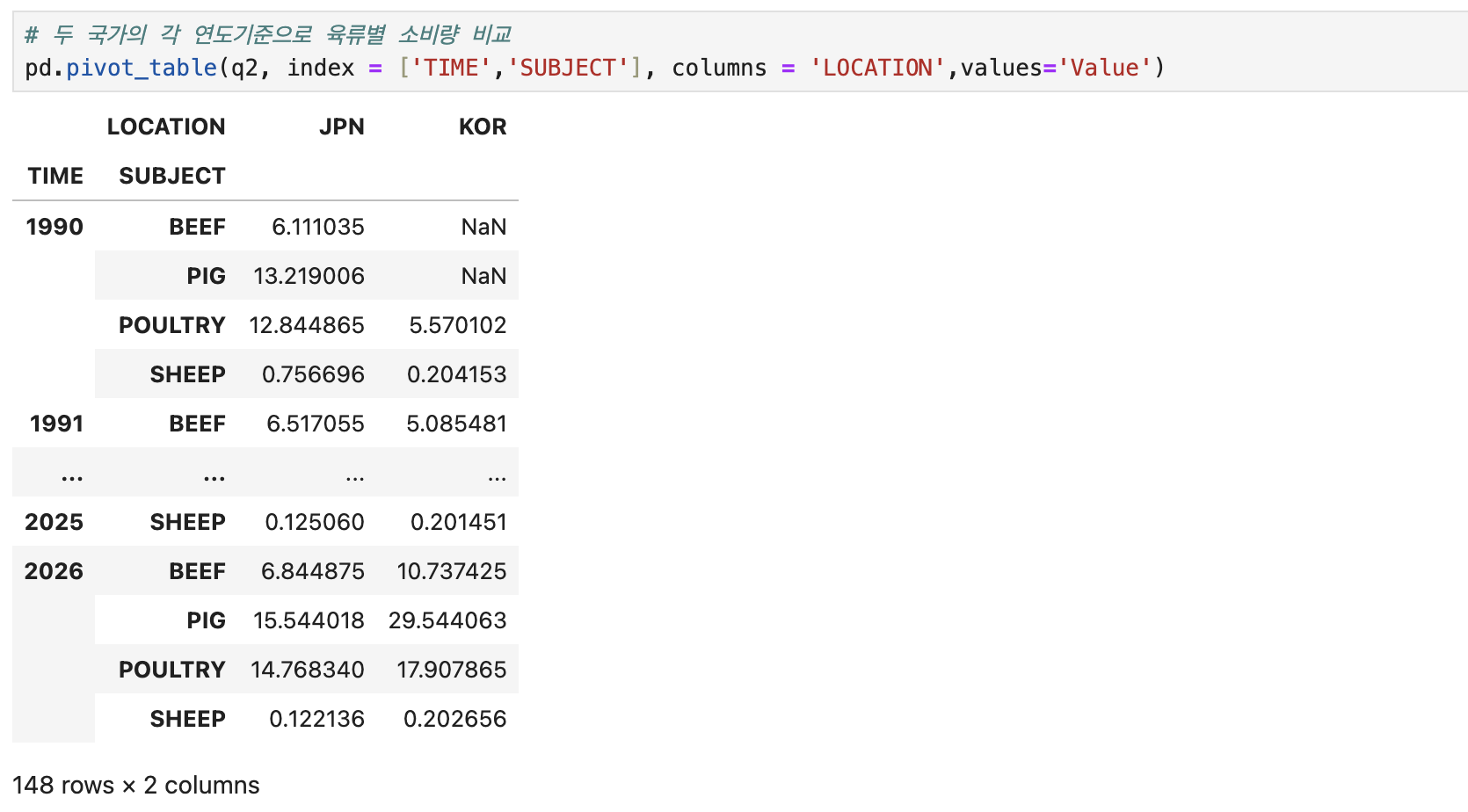
# 두 국가의 각 연도기준으로 육류별 소비량 비교
pd.pivot_table(q2, index = ['TIME','SUBJECT'], columns = 'LOCATION',values='Value')
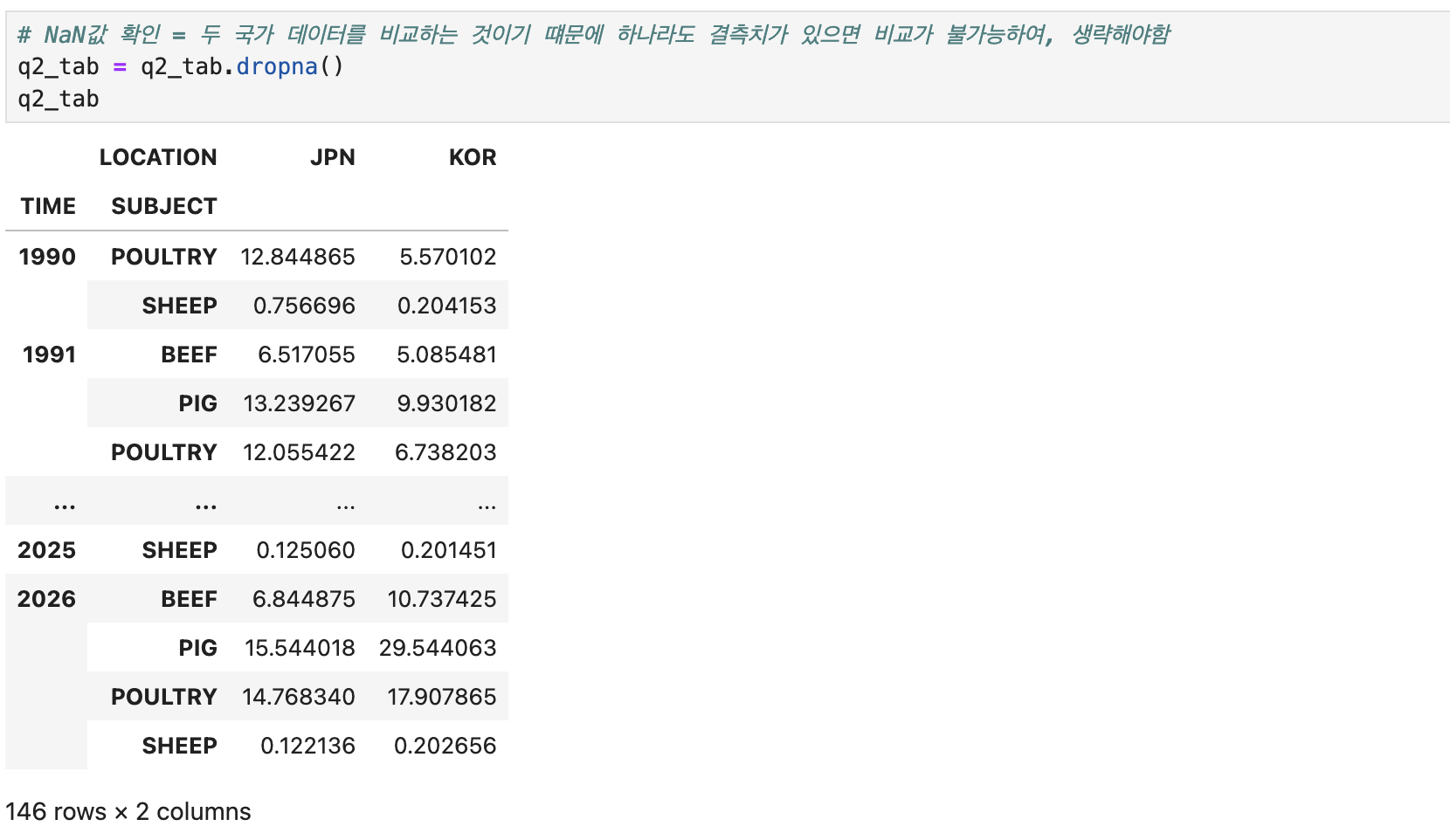
# NaN값 확인 = 두 국가 데이터를 비교하는 것이기 떄문에 하나라도 결측치가 있으면 비교가 불가능하여, 생략해야함
q2_tab = q2_tab.dropna()
# 대응표본t검정 함수
from scipy.stats import ttest_rel
# 대응표본t검정 진행
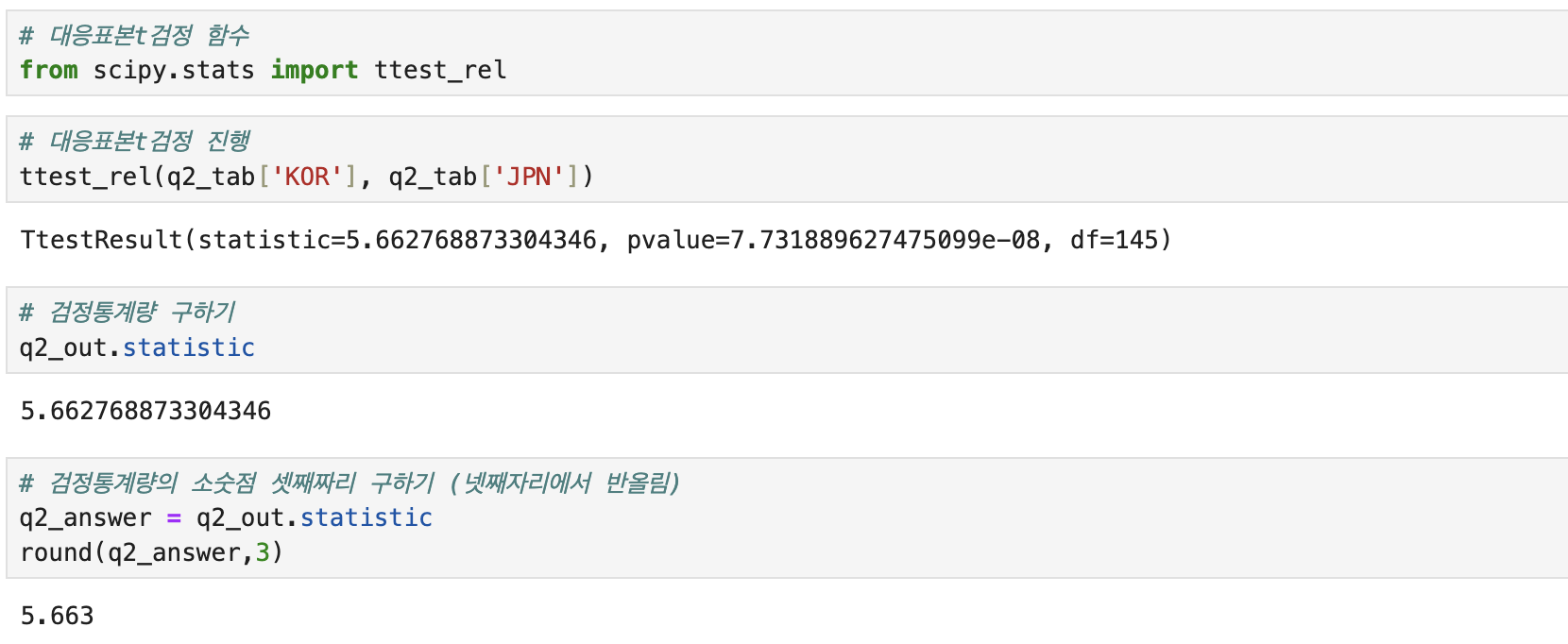
ttest_rel(q2_tab['KOR'], q2_tab['JPN'])
# 검정통계량 구하기
q2_out.statistic
# 검정통계량의 소숫점 셋째짜리 구하기 (넷째자리에서 반올림)
q2_answer = q2_out.statistic
round(q2_answer,3)
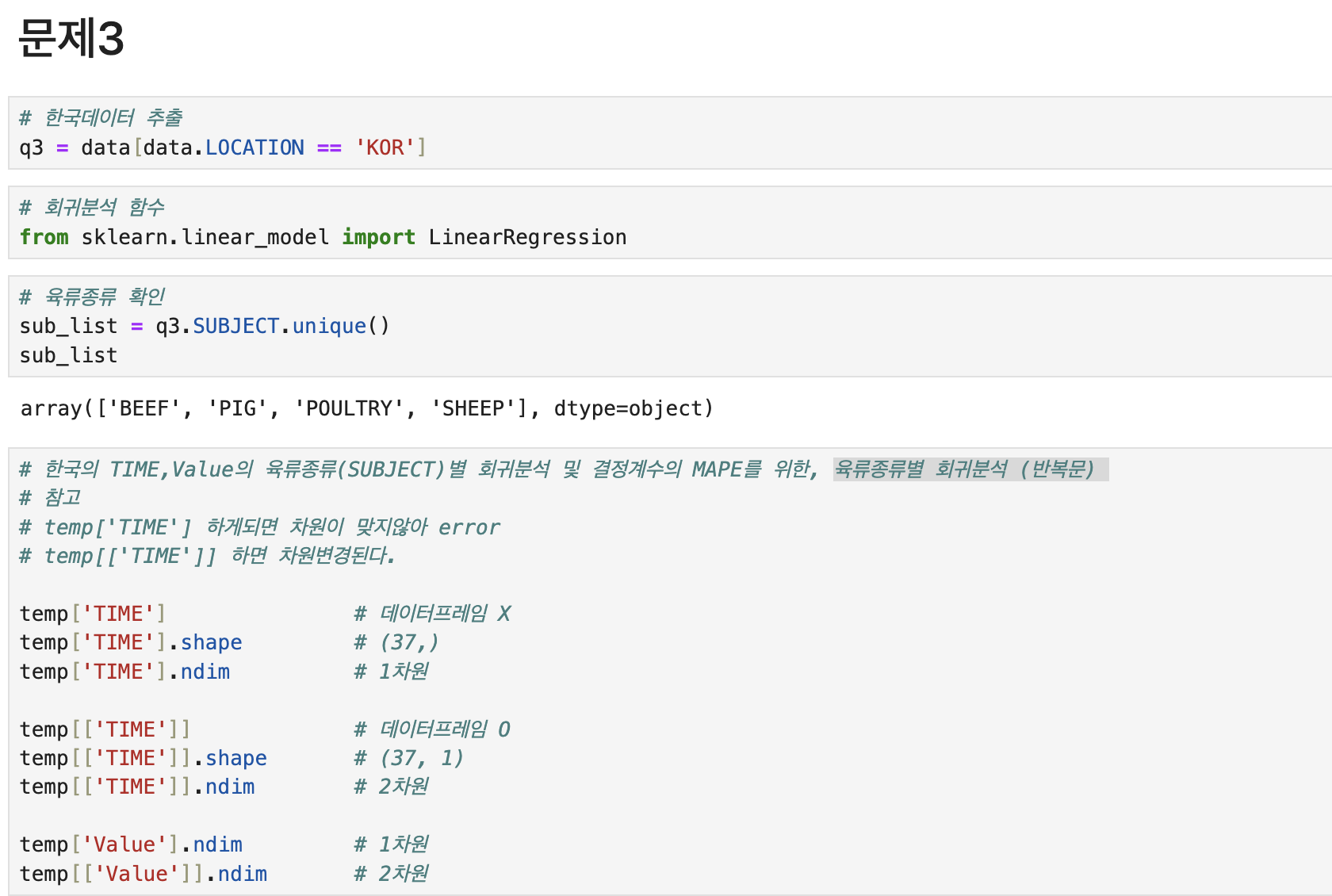
# 한국데이터 추출
q3 = data[data.LOCATION == 'KOR']
# 회귀분석 함수
from sklearn.linear_model import LinearRegression
# 육류종류 확인
sub_list = q3.SUBJECT.unique()
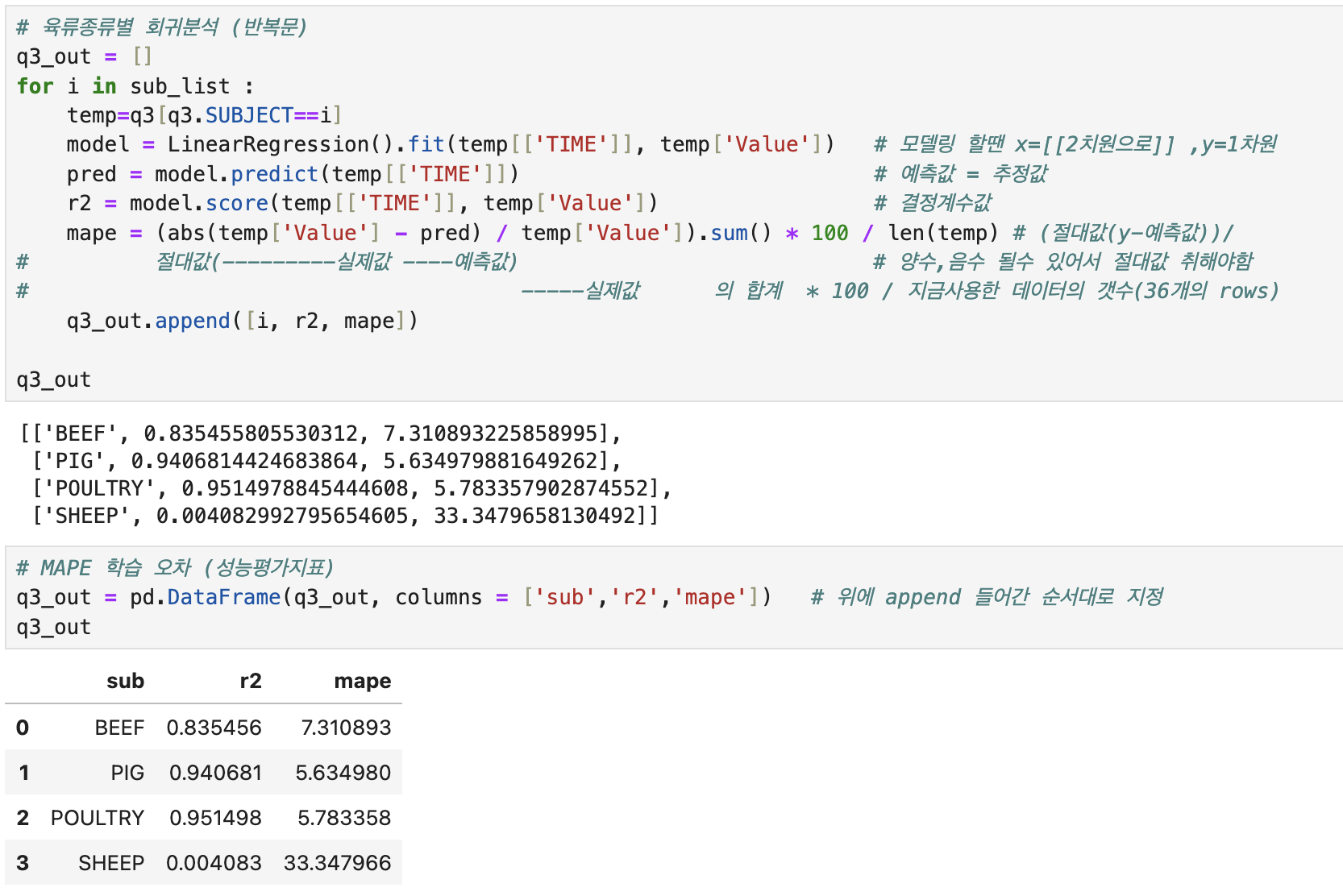
# 육류종류별 회귀분석 (반복문)
q3_out = []
for i in sub_list :
temp=q3[q3.SUBJECT==i]
model = LinearRegression().fit(temp[['TIME']], temp['Value']) # 모델링 할땐 x=[[2치원으로]] ,y=1차원
pred = model.predict(temp[['TIME']]) # 예측값 = 추정값
r2 = model.score(temp[['TIME']], temp['Value']) # 결정계수값
mape = (abs(temp['Value'] - pred) / temp['Value']).sum() * 100 / len(temp) # (절대값(y-예측값))/
# 절대값(---------실제값 ----예측값) # 양수,음수 될수 있어서 절대값 취해야함
# -----실제값 의 합계 * 100 / 지금사용한 데이터의 갯수(36개의 rows)
q3_out.append([i, r2, mape])
q3_out
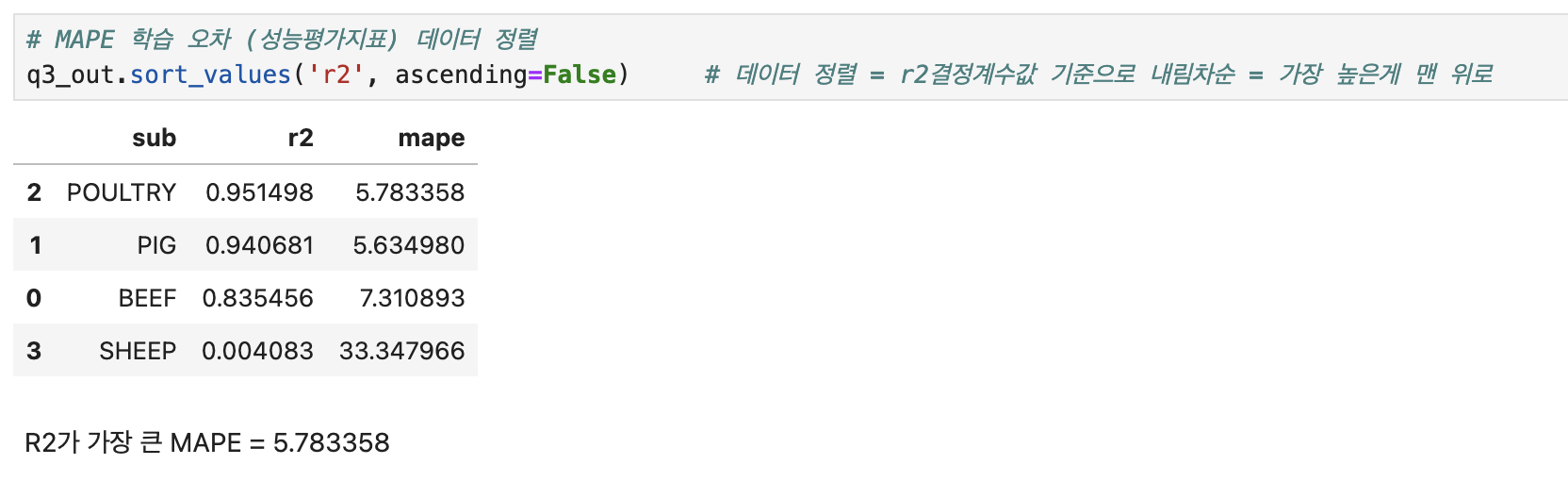
# MAPE 학습 오차 (성능평가지표)
q3_out = pd.DataFrame(q3_out, columns = ['sub','r2','mape']) # 위에 append 들어간 순서대로 지정
# MAPE 학습 오차 (성능평가지표) 데이터 정렬
q3_out.sort_values('r2', ascending=False)
# 데이터 정렬 = r2결정계수값 기준으로 내림차순 = 가장 높은게 맨 위로

데이터기반 스토리텔링을 통해 인사이트를 얻습니다.