✏️ 데이터베이스 (DataBase)
- 통합되어 관리되는 데이터의 집합체
- 중복된 데이터를 없애고, 자료를 구조화해 효율적인 처리를 할 수 있도록 관리
- 응용 프로그램과는 다른 별도의 미들웨어에 의해 관리
- DBMS (DataBase Management System)
📌 데이터베이스의 특징
- 사용자의 질의(query)에 대해 즉각적인 처리, 응답
- 생성, 수정, 삭제로 항상 최신 데이터 유지
- 사용자들이 원하는 데이터 동시에 공유 가능
- 사용자가 원하는 데이터를 주소가 아닌 내용에 따라 참조 가능
- 응용 프로그램과 독립되어 있으므로 데이터의 논리적 구조와 응용 프로그램은 별개로 동작
✏️ 관계형 데이터베이스 (Relational Database)
- SQL을 기반으로 함
- 테이블(table)로 이루어져 있음
- 테이블은 키(key)와 값(value)의 관계를 나타냄
- 데이터의 종속성을 관계로 표현
- 테이블이 다른 테이블들과 관계를 맺고 모여있는 집합체
- 테이블의 구조, 데이터 타입을 사전에 정의
- 테이블에 정의된 내용에 알맞은 형태의 데이터만 삽입 가능
- ex. MySQL, Oracle, SQLite, PostgresSQL, MariaDB
📌 관계형 데이터베이스의 특징
- 데이터의 분류, 정렬, 탐색 속도 빠름
- 높은 신뢰성, 데이터의 무결성 보장
- 기존에 작성된 스키마 수정 어려움
- 데이터베이스의 부하 분석 어려움
📌 관계형 데이터베이스 용어
- 열 (column)
- 유일한 이름을 가짐
- 자신만의 타입 가짐
- 필드 (field), 속성 (atrribute)라고도 불림
- 행 (row)
- 관계된 데이터의 묶음
- 튜플 (tuple), 레코드 (record)라고도 불림
- 값 (value)
- 각각의 행과 열에 대응됨
- 열의 타입에 맞는 값이어야 함
- 키 (key)
- 테이블에서 행의 식별자로 이용되는 열을 키(key) 또는 기본 키 (primary key)라고 함
- 테이블에 저장된 레코드를 고유하게 식별하는 후보 키 (candidate key) 중 데이터베이스 설계자가 지정한 속성 의미
- 기본 키 (primary key), 외래 키 (foreign key) 등이 있음
- 관계 (relationship)
- 테이블 간의 관계는 관계를 맺는 테이블의 수에 따라 다음과 같이 분류
- 테이블과 테이블 사이의 관계
- 1 : 1 관계
- 1 : N 관계
- N : N 관계
- 테이블 스스로 가지는 관계
- Self referencing 관계
- 테이블과 테이블 사이의 관계
- 이러한 관계를 나타내기 위해 외래 키 (foreign key) 사용
- 외래 키 (foreign key) : 한 테이블의 키 중 다른 테이블의 행을 식별할 수 있는 키
- 테이블 간의 관계는 관계를 맺는 테이블의 수에 따라 다음과 같이 분류
-
1️⃣ 1 : 1 관계
- 하나의 레코드가 다른 테이블의 레코드 1개와 연결된 경우
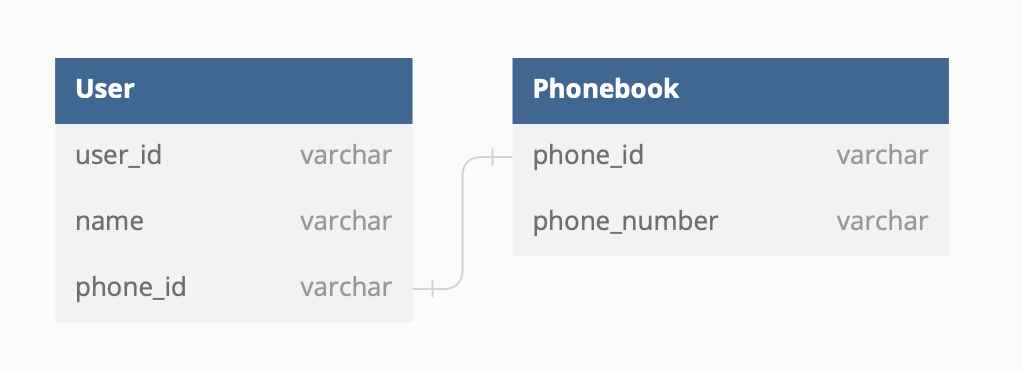
- 자주 사용 X
- 1 : 1로 나타낼 수 있는 관계라면 테이블에 직접 저장하는게 나음
- 하나의 레코드가 다른 테이블의 레코드 1개와 연결된 경우
-
2️⃣ 1 : N 관계
- 하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
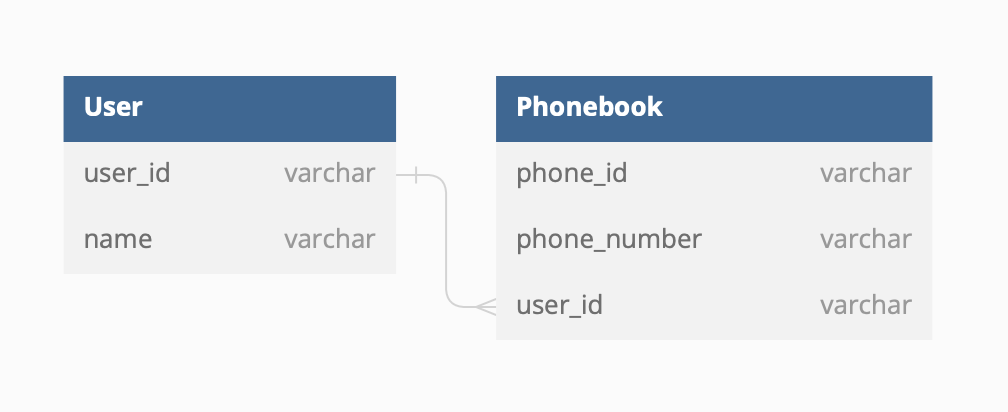
- 하나의 레코드가 서로 다른 여러 개의 레코드와 연결된 경우
-
3️⃣ N : N 관계
- 여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우

- N : N 관계를 위해 스키마를 디자인 할 때는 Join 테이블을 만들어 관리
- 여러 개의 레코드가 다른 테이블의 여러 개의 레코드와 관계가 있는 경우
-
4️⃣ Self referencing 관계
- 테이블 내에서의 관계

- 테이블 내에서의 관계
-
스키마 (schema)
- 테이블을 디자인하기 위한 청사진
- 테이블의 각 열에 대한 항목, 타입, 기본 키, 외래 키 나타내야 함
- 개체-관계 다이어그램이나 문자열로 표현
✏️ SQL
- Structured Query Language
- 데이터베이스에서 데이터를 정의, 조작, 제어하기 위해 사용하는 언어
- 주로 관계형 데이터베이스에서 사용
- 데이터의 구조가 고정되어 있어야 사용 가능
✏️ NoSQL
- 데이터가 고정되어 있지 않은 데이터베이스
- 스키마가 반드시 없는 것은 아님
- 데이터를 읽어올 때 스키마에 따라 읽어 옴
- schema on read
- ex. MongoDB, Casandra
📌 NoSQL 기반의 비관계형 데이터베이스 분류
Key-Value 타입
- 속성을 Key-Value의 쌍으로 나타내는 데이터를 배열의 형태로 저장 (Key : 속성 이름, Value : 속성에 연결되는 데이터 값)
- ex. Redis, Dynamo
문서형(document) 데이터베이스
- 데이터를 문서처럼 저장하는 데이터베이스
- JSON과 유사한 형식의 데이터를 문서화해 저장
- 각각의 문서는 하나의 속성에 대한 데이터를 가지고 있고, 컬렉션이라고 하는 그룹으로 묶어서 관리
- ex. MongoDB
Wide-Column 데이터베이스
- 데이터베이스의 열(column)에 대한 데이터를 집중적으로 관리하는 데이터베이스
- 각 열에는 key-value 형식으로 데이터가 저장
- column family라고 하는 열의 집합체 단위로 데이터를 처리 가능
- 하나의 행에 많은 열을 포함할 수 있어 유연성 높음
- 데이터 처리에 필요한 열을 유연하게 선택할 수 있어 규모가 큰 데이터 분석에 주로 사용
- ex. Cassandra, HBase
그래프 데이터베이스
- 자료구조의 그래프와 비슷한 형식으로 데이터 간의 관계를 구성하는 데이터베이스
- 노드에 속성별로 데이터를 저장
- 각 노드간 관계는 선으로 표현
- ex. Neo4J, InfiniteGraph
✏️ SQL vs NoSQL
- 데이터 저장 (Storage)
- 관계형 데이터베이스
- SQL을 이용해 테이블에 저장
- NoSQL
- key-value, document, wide-column, graph 등의 방식으로 저장
- 관계형 데이터베이스
- 스키마 (Schema)
- SQL
- 고정된 형식의 스키마 필요
- 처리하려는 데이터 속성별로 열(column)에 대한 정보를 미리 정해두어야 함
- NoSQL
- 관계형 데이터베이스보다 동적으로 스키마 형태 관리 가능
- 행을 추가할 때 즉시 새로운 열 추가 가능
- 개별 속성에 대해서 모든 열에 대한 데이터를 반드시 입력하지 않아도 됨
- SQL
- 쿼리 (Querying)
- 관계형 데이터베이스
- 테이블의 형식과 테이블간의 관계에 맞춰 데이터 요청
- SQL과 같은 구조화된 쿼리 언어 사용
- 비관계형 데이터베이스
- 쿼리는 데이터 그룹 자체를 조회하는 것에 초점
- 구조화되지 않은 쿼리 언어(UnQL, Unstructured Query Language)로도 데이터 요청 가능
- 관계형 데이터베이스
- 확장성 (Scalability)
- 관계형 데이터베이스
- 수직적으로 확장
- 높은 메모리, CPU를 사용하는 확장
- 여러 서버에 걸쳐서 데이터베이스 관계를 정의할 수 있지만 복잡하고 많은 시간 소모
- NoSQL로 구성된 데이터베이스
- 수평적으로 확장
- 보다 값싼 서버 증설
- 클라우드 서비스 이용하는 확장이라고도 함
- 많은 트래픽을 보다 편리하게 처리 가능
- 상대적으로 저렴
- 관계형 데이터베이스
📌 언제 사용❓
SQL 기반의 관계형 데이터베이스
- 데이터베이스의 ACID 성질을 준수해야 하는 경우
- 전자 상거래를 비롯한 모든 금융 서비스를 위한 스프트웨어 개발
- 소프트웨어에 사용되는 데이터가 구조적이고 일관적인 경우
NoSQL 기반의 비관계형 데이터베이스
- 데이터의 구조가 거의 또는 전혀 없는 대용량의 데이터를 저장하는 경우
- 대부분의 NoSQL 데이터베이스는 저장 가능한 데이터 유형 제한 X
- 클라우드 컴퓨팅 및 저장공간을 최대한 활용하는 경우
- 빠르게 서비스를 구축하는 과정에서 데이터 구조를 자주 업데이트 하는 경우
- NoSQL 데이터베이스는 스키마를 미리 준비할 필요 X → 빠른 개발 과정에 유리
✏️ 쿼리 (Query)
- Query : 질의문
- 저장되어 있는 데이터를 필터링하기 위한 질의문으로 볼 수 있음
- 데이터베이스에 쿼리를 보내 원하는 데이터를 가져오거나 삽입 가능
✏️ 트랜잭션 (Transaction)
- 여러 개의 작업을 하나로 묶은 실행 유닛
- 각 트랜잭션은 하나의 특정 작업으로 시작해 묶여 있는 모든 작업을 다 완료해야 정상적으료 종료
- 트랜잭션에 속한 여러 작업 중 하나라도 실패하면 트랜잭션에 속한 모든 작업을 실패한 것으로 간주
- ACID 특성 가짐
📌 ACID
- 데이터베이스 내에서 일어나는 하나의 트랜잭션의 안정성을 보장하기 위해 필요한 성질
Atomicity (원자성)
- 하나의 트랜잭션에 속해있는 모든 작업이 전부 성공하거나 전부 실패해 결과를 예측할 수 있어야 함
Consistency (일관성)
- 하나의 트랜잭션 이전과 이후, 데이터베이스의 상태는 이전과 같이 유효해야 함
Isolation (격리성)
- 모든 트랜잭션은 다른 트랜잭션으로부터 독립되어야 함
Durability (지속성)
- 하나의 트랜잭션이 성공적으로 수행되었다면, 해당 트랜잭션에 대한 로그가 남아야 함

공부중 📚