패스트 캠퍼스 강의를 듣고 혼자 연습해 본 것을 기록한 것입니다.
퀴즈
한국 경마 2014년도 데이터
Quiz 1. 어떤 성별을 가진 말이 성적이 좋을까?
내 풀이
# 1. 데이터 로드
race= pd.read_csv("datas/archive/2014 p.csv", encoding="euc-kr")
horse = pd.read_csv("datas/archive/2014 s.csv", encoding="euc-kr")
# 2. 필요한 데이터만 추출
df_horse_rank = race[['ID','RANK']]
df_horse_sex= horse[['ID', 'SEX']]
# 3. 데이터 merge하고 빈 값은 0으로 채우고, 데이터 타입을 int로 변경
df_merge_result = df_horse_rank.merge(df_horse_sex, on='ID')
df_merge_result['RANK'].fillna(value=0, inplace=True)
df_merge_result = df_merge_result.astype({"RANK":'int'})
# 4. KDE를 구하기 위해 순위별 합을 구한 후 merge
df_merge_result_groupby = df_merge_result.groupby(['RANK', 'SEX']).size().reset_index(name='COUNT')
df_rank_size = df_merge_result.groupby(['RANK']).size().reset_index(name='RANK_SIZE')
df_merge_result_groupby = df_merge_result_groupby.merge(df_rank_size, on='RANK')
df_merge_result_groupby['KDE'] = df_merge_result_groupby['COUNT']/df_merge_result_groupby['RANK_SIZE']
# 5. 4번에서 만들어진 DataFrame을 Pivot 테이블로 생성
df_merge_result_groupby = df_merge_result_groupby.pivot_table(index=['RANK'], columns=['SEX'], values=['COUNT', 'KDE'], fill_value=0)
df_merge_result_groupby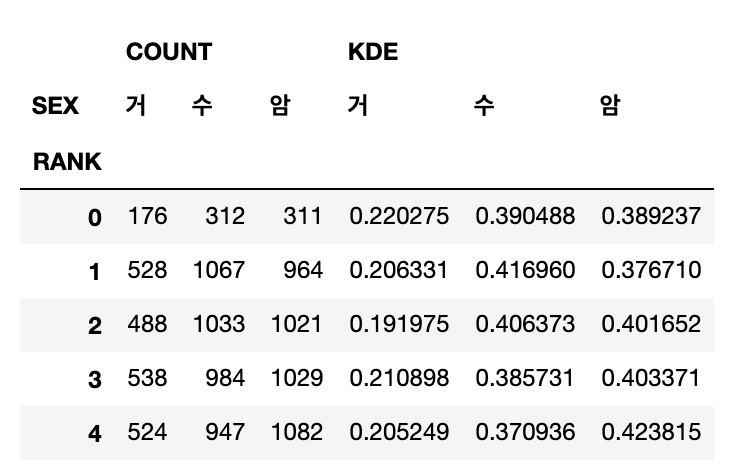
# 6. 1 ~ 5등까지의 확률데이터 추출
df_merge_result_groupby['KDE'].loc[1:5]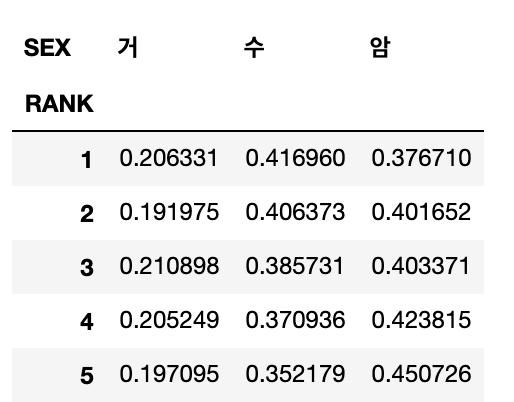
개선할 점
- 풀이
df_merged = pd.merge(race, horse) df_merged["COUNT"] = 1 df = df_merged.pivot_table("COUNT", "RANK", "SEX", aggfunc=np.sum)
순위별 성별의 합계에 대한 데이터를 구하면 되는데 내 코드는 불필요한 것이 많다. 간단하게 3줄이면 되는 코드를 5줄 넘게 쓴 것 같다.
- 풀이
# 성별에 대한 전체 데이터 count = df_merged.groupby("SEX").size() # broadcasting을 이용 확률 계산 result = df /count * 100 # 결과값을 확률 데이터로 포현하기 위해 100 곱함
나는 경기별 합계와 성별 합계를 같은 테이블로 만들고 컬럼끼리 계산하는 방식을 했는데 broadcasting은 생각도 못했다. 이렇게 간단하게 끝날 수 있다니...
⭐️ 확률 데이터로 표현하기 위해서 100을 곱해주자.
Quiz 2. 순위를 승점제로 했을때 2014년 시즌에서 말들의 성적은?
- 1등 : 3점
- 2등 : 2점
- 3등 : 1점
내 풀이
race= pd.read_csv("datas/archive/2014 p.csv", encoding="euc-kr")
# 점수 구하는 함수
import math
def convert_score(rank):
if math.isnan(rank):
return 0
temp_rank = int(rank)
if rank == 1:
return 3
elif rank == 2:
return 2
elif rank == 3:
return 1
else:
return 0
# apply 함수로 convert_score 적용
race['POINT'] = race['RANK'].apply(convert_score)
# 말 이름 별 점수 합계 구하기
result = race.groupby(['RCHOSE_NM']).sum()['POINT'].reset_index(name='POINT')
# 내림차순으로 정렬
result.sort_values('POINT', ascending=False).head().reset_index(drop=True)개선할 점
- 풀이
df_race= pd.read_csv("datas/archive/2014 p.csv", encoding="euc-kr") df_race['POINT'] = df_race['RANK'].apply( lambda rank : 4 - rank if rank <= 3 else 0 )
apply도 람다식으로 간단하게 처리할 수 있다는 것을 알았다. 매번 람다식은 생각이 안나는지...
