문제 상황
새로 만드는 프로젝트는 레거시 DB의 이상한 테이블 구조에 커플링되지 않도록 뷰를 만들었다. 참고로 뷰는 select 쿼리를 저장해서 뷰에 접근할 때마다 해당 쿼리를 실행시키는 방식으로 작동한다. 그런데 뷰를 만들때 사용했던 select 쿼리보다 뷰를 조회하는 것이 훨씬 오래 걸리는 이상한 현상이 생겼다. select문은 6초 정도 후에 쿼리가 끝나는데 뷰 조회는 몇십분이 걸렸다. 때문에 API 성능이 저하되는 것은 물론이고, 뷰를 조회하는 쿼리 때문에 lock wait time out도 자꾸 발생하게 되었다. 문제가 된 쿼리는 다음과 같다.
select distinct s.USER_NO as USER_NO,
sg.PRODUCT_NO as PRODUCT_NO,
s.ORDER_NO as ORDER_ID,
sda.DELIVERY_DATE as DELIVERED_AT,
sdag.QTY as QTY,
from SELL_DELIY_ADDR sda
inner join SELL_DELIY_ADDR_GOODS sdag on sda.SELL_DADDR_NO = sdag.SELL_DADDR_NO
inner join SELL_GOODS sg on sg.SELL_NO = sdag.SELL_NO
inner join SELL s on sg.SELL_NO = s.SELL_NO
where sda.STATUS_CD = 'delivery_end'
and sg.PRICE > 0
order by ORDER_ID desc;회사에서 사용하는 쿼리이기 때문에 단순화 시켰지만, 실제로는 이보다 join하는 테이블도 많고 더 복잡했다. 주목해야 할 부분은 distinct 키워드이다.
분석
뷰를 구성한 위의 select 쿼리와 뷰를 조회하는 쿼리(select * from {VIEW TABLE})의 플랜을 보았다.
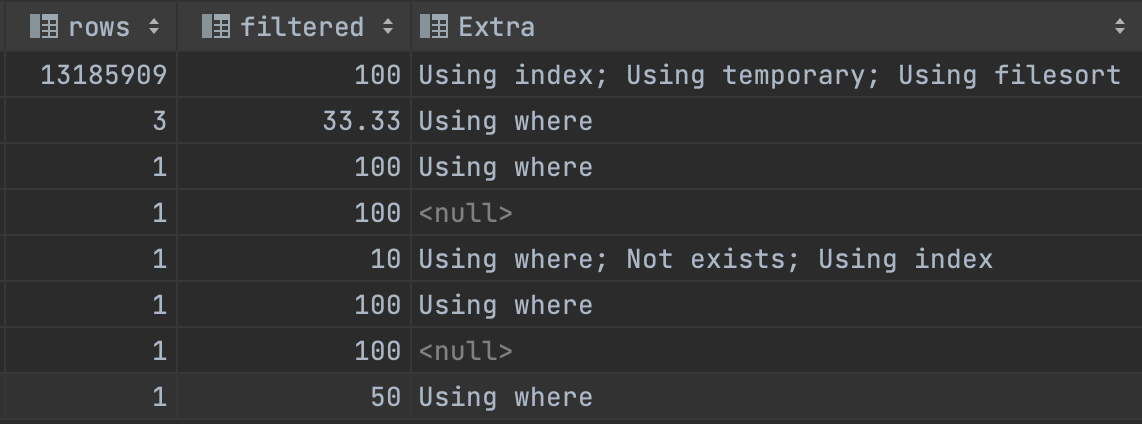
select 쿼리 플랜
뷰 조회 쿼리 플랜
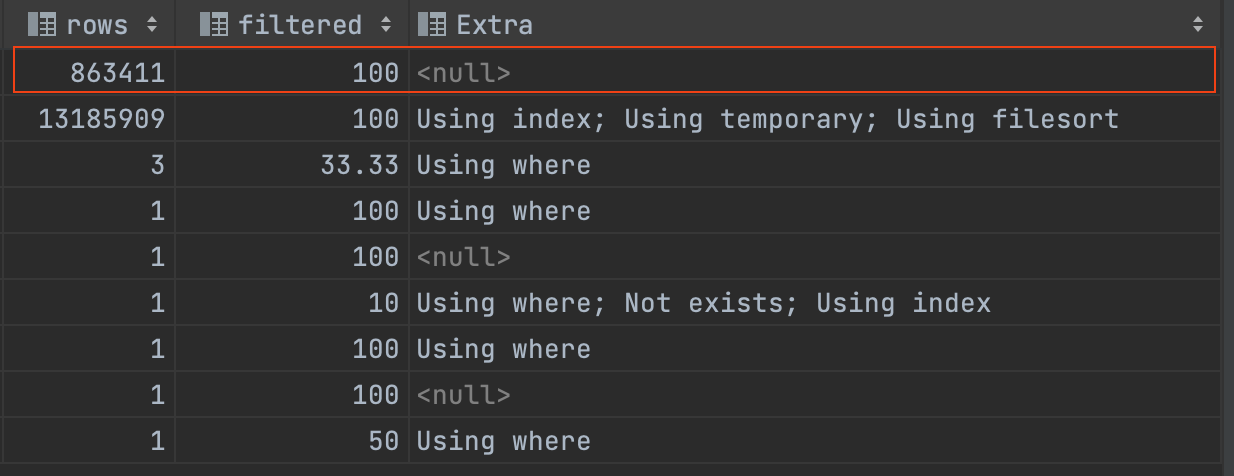
뷰를 조회할 때는 <drived2> 라는 이름의 새로운 테이블이 생겼다. row수도 매우 많고, 캡처에는 잘렸지만 풀스캔 되고 있었다. 이 테이블이 문제의 원인인 것이 자명했다.
원인
뷰가 처리되는 알고리즘에 문제가 있었다. MySQL이 뷰를 처리하는 알고리즘은 세가지가 있다. 바로 MERGE, TEMPTABLE, UNDEFINED이다.
- MERGE: 뷰를 참조하는 문과 뷰를 정의하는 문이 병합된다.
- TEMPTABLE: 뷰의 결과가 임시 테이블에서 파생되어 문을 실행하는데 사용한다.
- UNDEFINED: MySQL이 알고리즘을 선택한다. 보통 MERGE가 더 효율적이기 때문에 가능하다면 TEMPTABLE보다 MERGE를 선호한다.
TEMPTABLE 알고리즘으로 뷰가 처리되면 위 캡처와 같이 뷰 조회 플랜에 파생 테이블이 나타나게 된다.
특정 뷰에 사용되는 알고리즘은 show create view {view_name} 쿼리로 알 수 있다. 문제가 되었던 뷰의 알고리즘은 UNDEFINED였다.
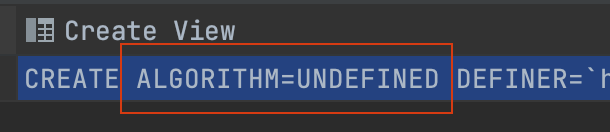
UNDEFINED일 땐 MERGE를 선호한다고 했는데 왜 TEMPTABLE 알고리즘으로 실행됐을까? 범인은 distinct였다. 쿼리 문에 다음과 같은 것들을 사용하면 MERGE 알고리즘을 사용할 수 없다.(참고)
- Aggregate functions (SUM(), MIN(), MAX(), COUNT(), and so forth)
- DISTINCT
- GROUP BY
- HAVING
- LIMIT
- UNION or UNION ALL
- Subqueries in the select list
- Assignments to user variables
- Refererences only to literal values
나의 경우 select문에 distinct가 사용되었기 때문에 뷰가 TEMPTABLE 알고리즘로 처리된 것이다. 뷰 정의문에서는 distinct를 지우고, 뷰를 select 할때 distinct를 사용하면 성능을 개선할 수 있다.
참고

혜민님 최고!