Thumbnail image
Word2vec
Review
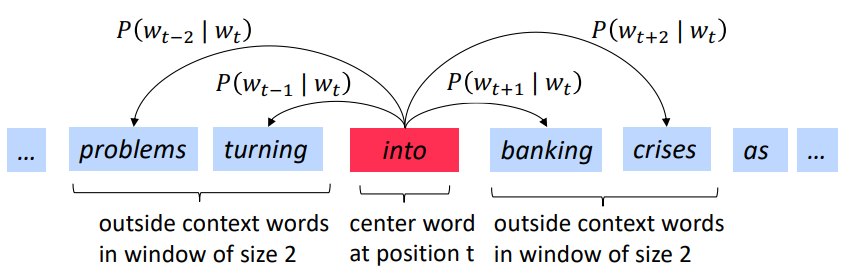
- Iterate through each word of the whole corpus
- Predict surrounding words using word vectors
- Calculate and
- Update so you can predict well
- Each row of is a word vector!
Note: You can use or instead of , or use for centre words and for context words if it is possible.
Q. How to avoid too much weight on the high frquency words(like 'the', 'of', 'and')?
A. Discard the first biggest component of word vector! It contains information of frequency.
Stochastic Gradient Descent
- Problem: is very expensive to compute
- Stochastic Gradient Descent(SGD): Repeatedly sample windows, and update after each one!
While True:
window = sample_window(corpus)
theta_grad = evaluate_gradient(J, window, theta)
theta = theta - alpha * theta_gradNegative Sampling
- Problem:
... normalization factor (demoninator) is too computationally expensive. - Negative Sampling: Calculate the probability above with randomly selected negative(noise) pairs.
- is real outside words
- is random neg-samples
- is number of neg-samples (10-20 would be fine)
- Maximize probability that real outside word appears.
Minimize probability that random words appear around centre word.
- : Sampling Probability (distribution)
- : unigram distribution
- 3/4 power ⇒ common word ↓, rare word ↑ (This number determined heuristically)
GloVe
Word-document co-occurrence matrix
-
Word-document co-occurrence matrix will give general topics leading to "Latent Semantic Analysis"
-
Example of simple co-occurrence matrix:
I like deep learning.
I like NLP.
I enjoy flying. -
counts I like enjoy deep learning NLP flying . I 0 2 1 0 0 0 0 0 like 2 0 0 1 0 1 0 0 enjoy 1 0 0 0 0 0 1 0 deep 0 1 0 0 1 0 0 0 learning 0 0 0 1 0 0 0 1 NLP 0 1 0 0 0 0 0 1 flying 0 0 1 0 0 0 0 1 . 0 0 0 0 1 1 1 0 -
Problems with simple co-occurrence vectors:
1) Increase in size with vocabulary
2) Very high dimensional, requires a lot of storage
3) Sparsity issues with vectors
⇒ Naive solution: Singular Vector Decomposition (SVD)
⇒ Better solution: GloVe
Count-based vs Direct-prediction
-
The methods of word representation can be categorized as "Count-based" or "Direct-prediction"
-
Count-based Direct-prediction - LSA, HAL
- COALS, Hellinger-PCA- Word2vec (Skip-gram, CBOW)
- NNLM, HLBL, RNNAdvantages:
- Fast training
- Efficient usage of statisticsAdvantages:
- Generate improved performance on other tasks
- Can capture complex patterns beyond word similarityDisadvantages:
- Primarily used to capture word similarity
- Disproportionate importance given to large countsDisadvantages:
- Scales with corpus size
- Inefficient usage of statistics -
In other words, count-based methods can capture characteristics of the document because these methods receive whole corpus as an input, while the direct-prediction methods outperform in representing the syntactic and symantic features of a word.
Glove
-
Glove is designed to combine the advantages of both count-based and direct-prediction.
-
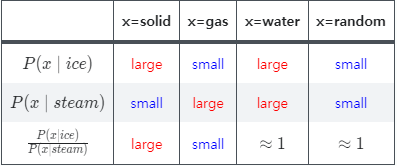
Insight: Ratio of co-occurrence probabilities can encode meaning components.
-
x=solid x=gas x=water x=random large small large small small large large small large small -
"Ratio" makes both-related words (water) or un-related words (fashion) to be close to 1.
Q. How can we capture ratios of co-occurrence probabilities as linear meaning components in a word vector space?
A. Log-bilinear model!
-
Log-bilinear Model ... (What is bilinear?)
- co-occurrence prob.
- ratio of co-occurrence prob.
- is some mapping
- We want to represent the information present in .
Thus,- Consider this: when , we want to be determined solely by word .
- As is a scalar, should also be a scalar.
Thus,- While F could be taken to be a complicated function parameterized by, e.g., a neural network, doing so would obfuscate the linear structure we are trying to capture.
- The distinction between a word and a context word is arbitrary and we are free to exchange the two roles.
Thus,
which means, and - We require that be a homomorphism between the groups and .
This simply means that we want:
Thus, , and - Finally we get log-bilinear model:
And from this, we also get:
-
Cost Function of GloVe
- is some special function that is designed to capping the effect of very common words.
- Note: and is introduced to obtain symmetricity between word and
- For more details, check the original GloVe paper.
-
vs Word2vec
Someone's opinion: stackoverflow
If there is something wrong in my writing or understanding, please comment and make corrections!
[references]
1. https://youtu.be/kEMJRjEdNzM
2. https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture02-wordvecs2.pdf
3. https://aclanthology.org/D14-1162/
4. https://qr.ae/pGPB2h
5. https://youtu.be/cYzp5IWqCsg
6. https://stackoverflow.com/questions/56071689/whats-the-major-difference-between-glove-and-word2vec
