Softmax and Cross-entropy
- Softmax:
- is row of some weight matrix
- Cross-entropy:
- True probability:
- Modeled probability:
- Cross-entropy loss function over dataset :
... where- For classification, we want to minimize , which means we want to maximize probability of correct class => update
- cf) Binary cross-entropy loss:
Neural Networks
- Softmax alone is not very powerful. It only gives linear decision boundaries.
- Neural networks can learn much more complex functions and nonlinear decision boundaries.
Artificial Neuron and Neural Network
| Neuron | Neural Network |
|---|---|
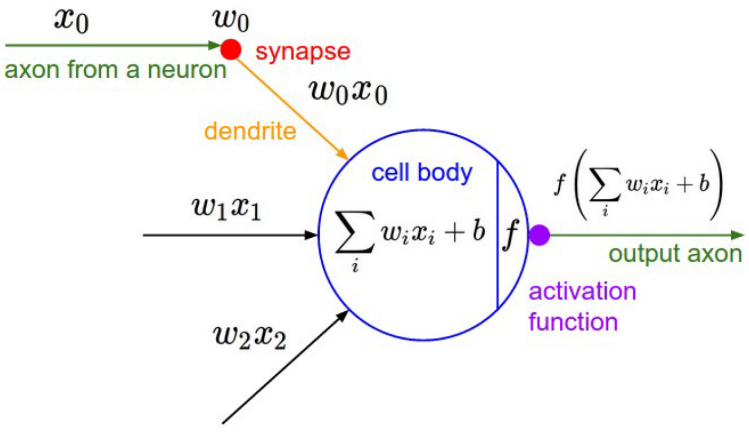 Image from: here Image from: here |  Image from: here Image from: here |
- A neuron can be a binary logistic regression unit
- nonlinear activation function (e.g. sigmoid)
- A neural network = running several logistic regressions at the same time
And feed the outputs of a layer into next layer of neurons - In matrix notation,
... ( is an input vector of a layer)
... ( is output vector from the layer, and it will be fed into next layer)
Window Classification
- In general, classifying single words is rarely done because meaning of a word depends on context
- "To sanction" can mean "to permit" or "to punish"
- "Paris" can mean "Paris, France" or "Paris Hilton"
- Window Classification: classify a word in its context window of neighboring words
- To classify a center word, take concatenation of word vectors surrounding it in a window.
- Example: Classify "Paris" in the context with window length 2:
 Image from: here
Image from: here - is now an input vector of a neural net
- Neural Network Feed-forward Computation
- Let's assume a NER location classification task (classify whether the center word is a Location or not)
- = score("museums in Paris are amazing")
-
 Image from: here
Image from: here - The middle layer learns non-linear interactions between the input word vectors
- The max-margin loss
- True window's score
- Corrupt window's score
- ... minimizing makes larger and lower
- This is not differentiable but it is continuous -> we can use SGD by computing
Matrix Calculus
Gradients
-
Given a function with 1 output and n inputs
- Gradient:
-
Given a function with m outputs and n inputs
- Jacobian: , i.e.
-
Example: Elementwise activation function
- , where
- Jacobian:
Apply to NER location neural net
-
- Break up the equation into simple pieces
- is input
- , where ,
- , where is elementwise activation function,
- , where
- Break up the equation into simple pieces
-
Partial derivatives of score
-
... by chain rule
... "" is elementwise multiplication
- ... should be matrix
...
Here we used the result already computed above
-
-
Update weights
If there is something wrong in my writing or understanding, please comment and make corrections!
[references]
1. https://youtu.be/8CWyBNX6eDo
2. https://web.stanford.edu/class/archive/cs/cs224n/cs224n.1194/slides/cs224n-2019-lecture03-neuralnets.pdf
3. https://en.wikipedia.org/wiki/Partial_derivative

Lazy Enthusiast