
이번 글에서는 모니터링 환경을 구성해보려고 해요.
자꾸 서버가 꺼져요
이전에 진행했던 BARO 프로젝트에서 사용자의 자세를 측정하기 위한 AI 분석 서버를 따로 배포한 적이 있었어요. 당시에는 배포 주기도 다르고, 실행 특성(분석이 오래 걸려요)도 달랐기에 따로 배포했어요. 그러나, 분석 API를 여러 번 사용하면 AI 서버가 계속 종료되었어요. AI 모델의 연산은 많은 자원을 요구하는데, 당시 사용하던 서버의 사양이 부족한가? 라고 생각해서 free -m 명령어로 메모리 사용량을 확인했었고, 단순히 메모리가 부족하다고 판단해 메모리가 더 큰 서버로 바꿨던 경험이 있어요. 원활하게 실행 가능한 성능 기준 없이 일부 정보에만 의존해 자원을 늘렸다고 볼 수 있을 것 같아요.
이처럼 명확한 기준 없이 서버의 성능을 결정한다면, 아무리 좋은 코드라도, 자원 부족으로 실행에 어려움이 생기거나 사용하지 않는 자원에 불필요한 비용을 지불해야 할 위험이 있어요. 이러한 문제를 방지하기 위해서는 모니터링이 필요할 수 있어요.
모니터링?

서울지방경찰청은 모니터링 강화로 CCTV 감시를 통한 범인 검거가 지난해보다 3배 가까이 늘었다고 14일 밝혔다. 서울시내 25개 CCTV 관제센터 근무자를 전문성이 있는 경찰관으로 교체하는 등 3월부터 관제센터 기능을 '범죄억제'에서 '예방·검거'로 전환한 데 따른 것으로 분석된다. - 출처
모니터링이라는 단어는 일상생활에서도 자주 접할 수 있어요. 사용되는 분야마다 의미는 조금씩 다르지만, 대부분의 경우 잠재적인 문제를 감시하고 발생하는 상황을 관찰하는 역할을 수행해요.
애플리케이션 모니터링의 주 목적은 서비스의 안정성을 향상시키는 것이에요. 사용자가 원활한 서비스를 제공받기 위해 시스템은 항상 안정적으로 운영되어야 해요. 모니터링을 통해 애플리케이션에서 발생하는 다양한 동작을 기록하고 성능을 분석하여 최적화할 수 있으며, 실시간으로 발생하는 문제를 신속하게 파악하고 해결할 수 있어요.
Go lang 도입, 그리고 4년 간의 기록 - 변규현, 당근마켓 | GopherCon Korea 2023 (6분 52초) 컨테이너 환경에서 원치 않는 CPU Throttling을 겪고 이를 해결한 이야기를 들은 적도 있어요. 만약 모니터링이 없었다면, 이처럼 빠르게 문제로 인식하고 해결 방안을 찾을 수 없었을 거에요.
또한, 최근에 아래와 같은 포스팅들을 읽으며 모니터링의 중요성을 체감할 수 있었어요.
메트릭
메트릭(metric)은 측정 가능한 데이터를 나타내는 지표를 의미해요. 메트릭을 잘 수집하면 시스템의 현재 상태를 손쉽게 파악할 수 있으며, 성능을 분석하거나 개선점을 찾을 때 용이해요. 메트릭의 종류는 매우 다양하며, 상황에 따라 필요한 메트릭을 선택적으로 수집할 수 있어요.
다음은 일반적으로 수집하는 메트릭의 예시에요.
호스트 단위 메트릭: CPU 사용률, 메모리 사용량, 디스크 I/O 등종합 메트릭: 데이터베이스 성능, 캐시 성능 등 시스템의 특정 계층에 대한 성능 지표핵심 비즈니스 메트릭: 일별 활성 사용자 수, 수익, 재방문율 등 비즈니스 성과와 직결되는 지표
모니터링을 잘 구축해두면, 자원 부족 문제나 성능 저하를 사전에 파악하고 해결할 수 있어, 더 나은 서비스 운영이 가능해요.
맥북 활성 상태 보기
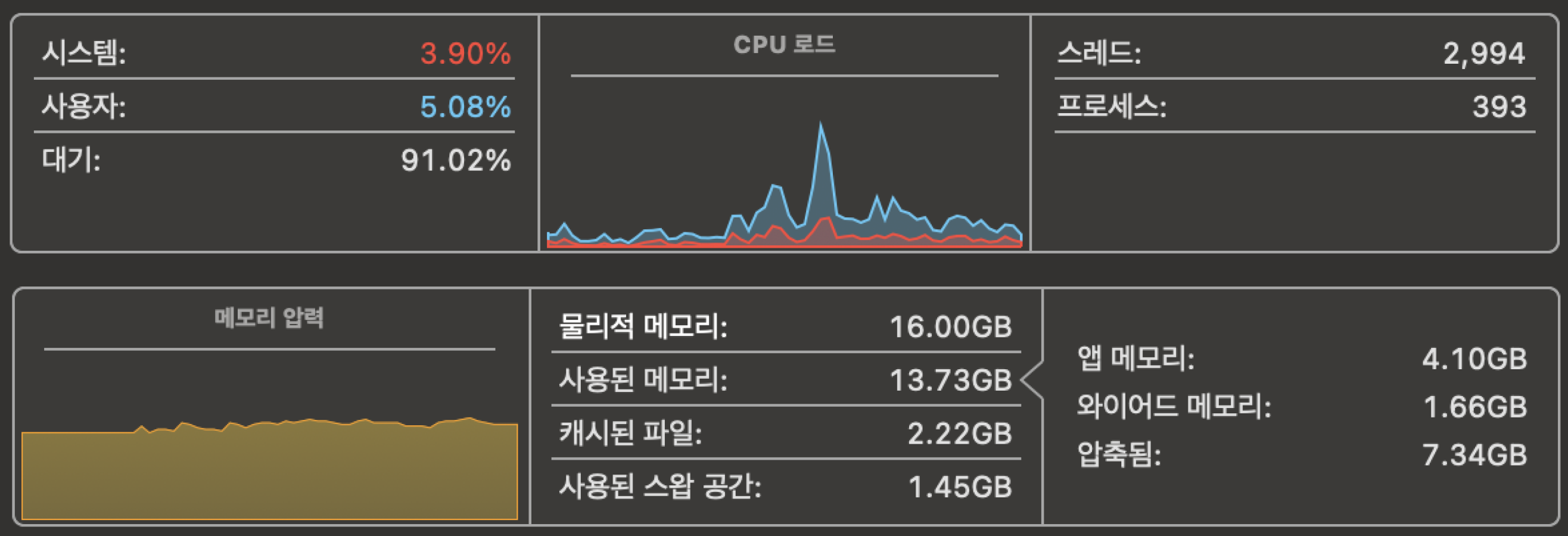
맥북의 활성 상태 보기도 모니터링 도구의 일종이며, CPU 사용량, 메모리 사용량, 디스크 활동 등을 실시간으로 확인할 수 있어요. 이런 데이터가 메트릭(metric)이에요.
Prometheus
Prometheus는 오픈 소스 모니터링 시스템으로, 서버, 애플리케이션 등 다양한 서비스의 메트릭을 수집하고 분석하는 데 사용돼요.
특히, Prometheus는 주기적으로 모니터링 대상(서버)에게 HTTP 요청을 보내서 메트릭을 가져오는 Pull 방식을 사용해요. 이는 Prometheus가 언제 데이터를 수집할지 통제할 수 있다는 장점을 가지고 있어요. Prometheus는 메트릭 수집과 저장뿐만 아니라 이를 기반으로 한 알람, 시각화, 쿼리 기능도 제공한다고 해요.
지원되는 메트릭 유형은 공식 문서에서 확인할 수 있어요.
Pull vs Push 방식
모니터링 시스템에는 Pull 방식과 Push 방식이라는 두 가지 방식이 존재해요.
Push 방식: 메트릭이 발생하는 대상이 직접 메트릭 수집 시스템으로 데이터를 보내요. 애플리케이션이 자체적으로 발생한 메트릭을 모니터링 시스템에 전달하는 방식이에요.Pull 방식: 메트릭 수집 시스템이 주기적으로 메트릭을 수집해요. Prometheus는 주기적으로 서버나 애플리케이션에 HTTP 요청을 보내 데이터를 수집해요.
Actuator
Actuator는 Spring Boot 애플리케이션의 상태를 모니터링하고 관리할 수 있는 다양한 기능을 제공하는 모듈이에요. 애플리케이션의 메트릭, 상태 확인, 환경 정보 등을 손쉽게 노출할 수 있는 엔드포인트를 제공해요.
특히, Prometheus와 같은 모니터링 시스템과 통합할 수 있게 메트릭 엔드포인트를 제공해요. 이 엔드포인트를 통해 애플리케이션 내부에서 발생하는 다양한 메트릭(예: CPU 사용량, 메모리 상태, HTTP 요청 처리 시간 등)을 Prometheus가 주기적으로 가져갈 수 있게 설정할 수 있어요.
Spring Boot에서 Actuator를 활성화하려면, spring-boot-starter-actuator 의존성을 추가하고, 메트릭 엔드포인트를 노출시키는 설정이 필요해요.
Grafana
Grafana는 Prometheus와 함께 자주 사용되는 오픈 소스 데이터 시각화 도구예요. Grafana는 Prometheus에서 수집한 메트릭 데이터를 시각화하여 대시보드 형태로 제공해요.
Grafana는 다양한 데이터 소스를 지원하며, Prometheus는 그중 하나예요. Grafana를 사용하면 실시간 데이터를 기반으로 한 대시보드를 생성하여 서버 성능, 애플리케이션 상태, 비즈니스 메트릭 등을 한 곳에서 모니터링할 수 있어요.
주요 기능
대시보드 생성: 다양한 차트, 그래프, 패널을 이용해 사용자 정의 대시보드를 만들 수 있어요.알람 설정: 특정 조건에 맞는 알람을 설정하여, 시스템 이상 발생 시 즉각적으로 알림을 받을 수 있어요.다양한 데이터 소스 지원: Prometheus 외에도 MySQL, Elasticsearch, AWS CloudWatch 등 여러 소스에서 데이터를 가져와 시각화할 수 있어요.
Grafana와 Prometheus를 연동하면, Prometheus에서 수집한 메트릭을 Grafana의 직관적인 대시보드를 통해 시각적으로 확인할 수 있어 모니터링의 효율성을 크게 높일 수 있어요.
실험
이전 글에서는 개발 서버 배포 자동화를 구축했어요. 이 서버에 모니터링을 적용할 수 있도록 유사하게 테스트해보려고 해요.
메트릭 구성
저는 포스팅을 참고하여 테스트를 진행했어요.
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'org.springframework.boot:spring-boot-starter-actuator'
implementation 'io.micrometer:micrometer-registry-prometheus'스프링 부트 애플리케이션에 웹 의존성, 메트릭 노출을 위한 Actuator와 메트릭 수집을 위한 Micrometer 의존성을 추가해요.
# application.yml
spring:
application:
name: test
management:
endpoints:
web:
exposure:
include: prometheus, health, info
metrics:
tags:
application: ${spring.application.name}application.yml에 위와 같은 설정을 추가해요.
management.endpoints.web.exposure.include : 특정 엔드포인트(prometheus, health, info)를 외부로 노출하는 설정이에요.
metrics.tags : 메트릭에 태그를 추가하여 추가적인 정보를 기록하고, 해당 태그로 메트릭을 구분할 수 있어요. 여기서는 application이라는 태그를 추가하고 spring.application.name(test)를 값으로 사용하도록 했어요.
지원되는 엔드포인트는 공식 문서에서 확인할 수 있어요.
스프링 부트 애플리케이션은 8080번 포트에서 실행되지만, 클라이언트는 Traefik에 의해 80번 포트를 통해 접근할 수 있어요.
애플리케이션 실행 후 http://localhost/actuator에 접속하면 현재 액추에이터가 제공하는 엔드포인트 목록을 확인할 수 있어요.
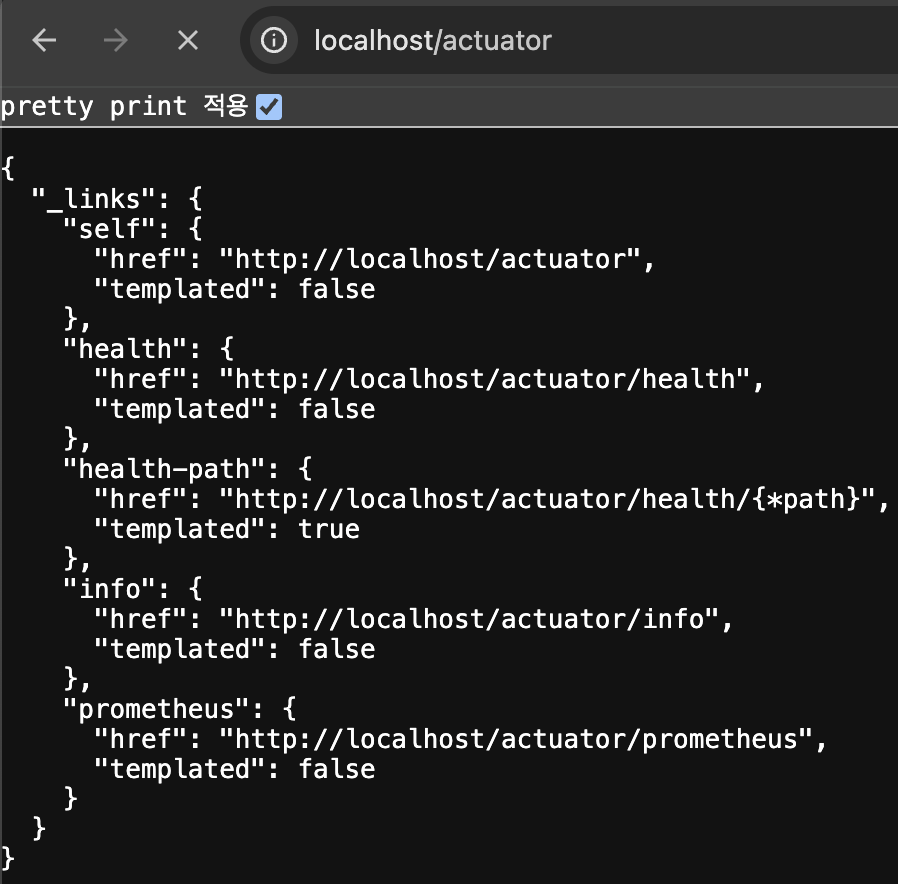
원하는 엔드포인트에 접속함으로 원하는 메트릭 데이터를 확인할 수 있어요. 프로메테우스에 메트릭을 제공하기 위한 엔드포인트인 http://localhost/actuator/prometheus 도 확인할 수 있어요.
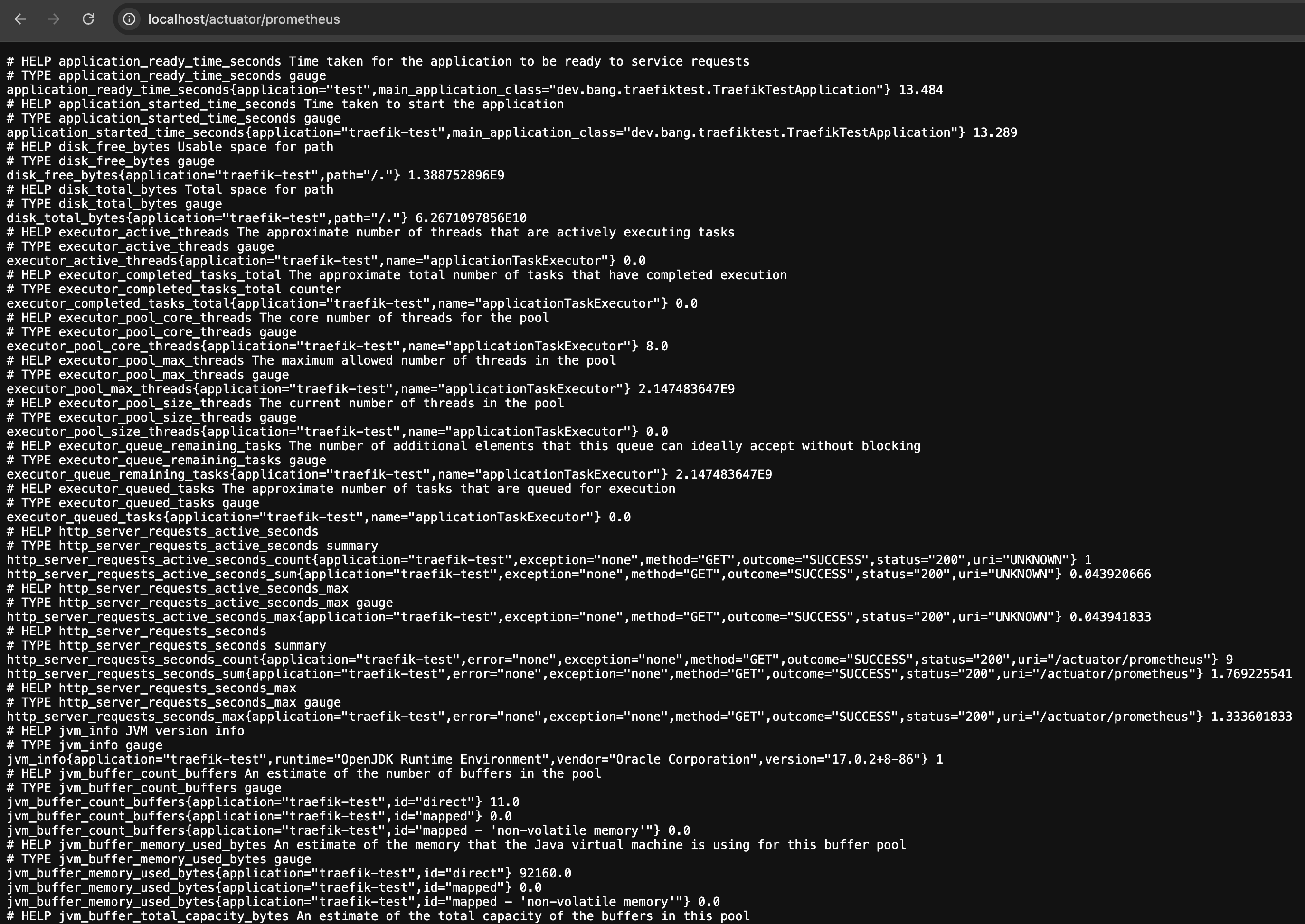
Prometheus 설정
# prometheus.yml
global:
scrape_interval: 15s # Prometheus가 메트릭을 수집하는 주기 (기본 값은 1분)
scrape_timeout: 15s # 메트릭 수집 요청이 타임아웃되기까지의 최대 시간 (기본 값은 10초)
evaluation_interval: 2m # AlertRule과 같은 규칙을 검증하는 주기 (기본 값은 1분)
external_labels: # 메트릭에 추가할 외부 레이블 정의
monitor: 'system-monitor' # 모든 메트릭에 monitor: 'system-monitor'라는 레이블이 추가
query_log_file: query_log_file.log # Prometheus의 쿼리 로그를 저장할 파일의 이름
rule_files:
- "rule.yml" # 적용할 규칙 파일의 경로
scrape_configs: # 여러 개의 스크랩 구성 정의 가능
- job_name: "prometheus" # 스크랩할 작업의 이름
static_configs:
- targets: # Prometheus 메트릭을 수집할 대상
- "prometheus:9090" # Prometheus 서버의 주소 prometheus:9090
- job_name: "springboot" # 스크랩할 작업의 이름
metrics_path: "/actuator/prometheus" # 메트릭을 수집하기 위해 Prometheus가 요청할 엔드포인트 경로
scheme: 'http'
scrape_interval: 5s # 메트릭을 수집하는 주기
static_configs:
- targets:
- "{도커 컨테이너 서비스 이름}:8080" # Spring Boot 애플리케이션이 실행되고 있는 Docker 컨테이너의 서비스실제로 아래와 같이 로그 파일이 생성돼요.
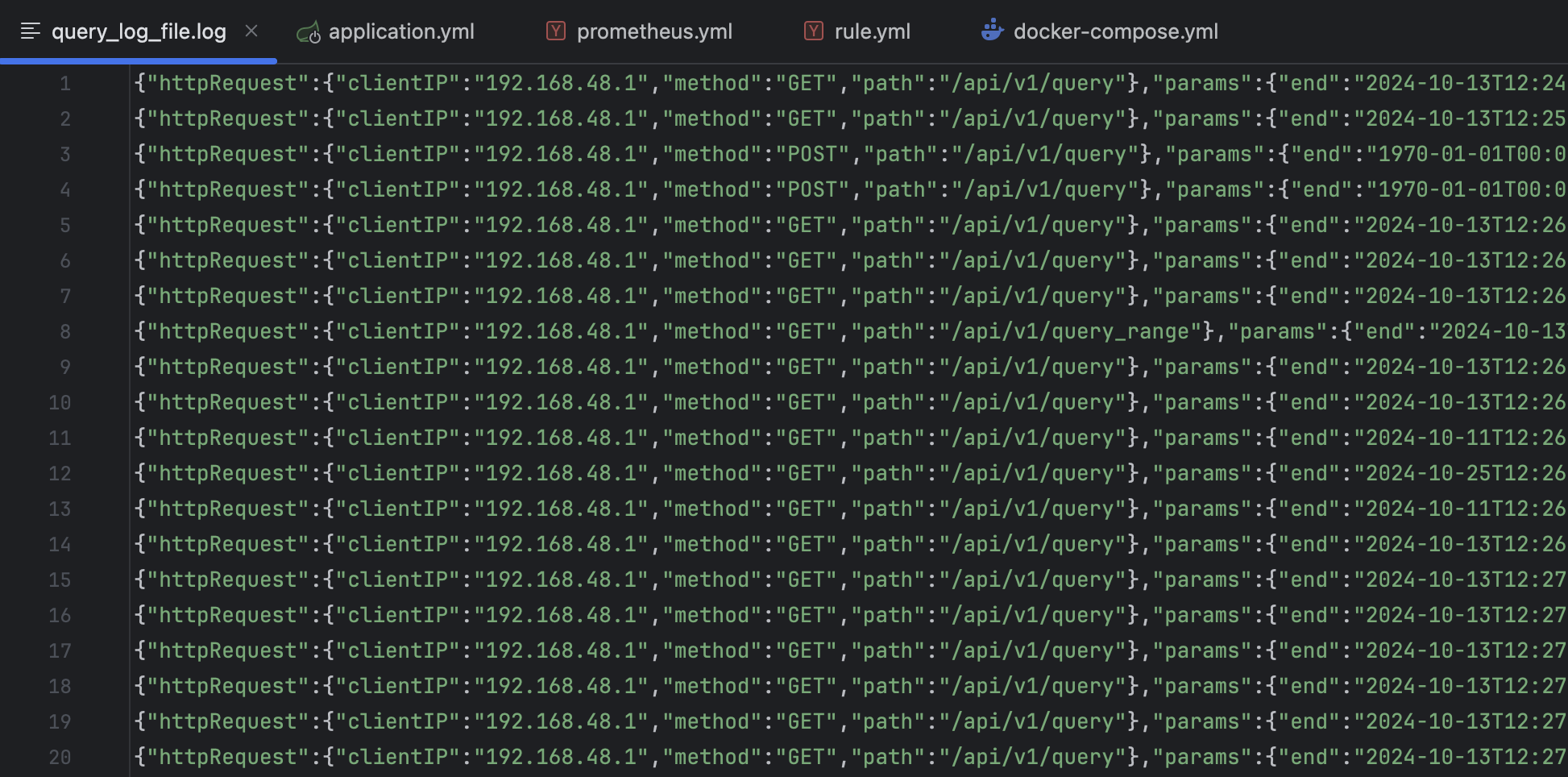
# rule.yml
groups: # 알림 규칙들을 묶는 그룹, 각 그룹은 여러 개의 규칙을 포함 가능
- name: system-monitor
rules:
# InstanceDown 알림은 인스턴스가 5분 이상 다운된 경우(up == 0) 트리거되며,
# 심각도는 page로 설정되고, 요약과 설명에는 다운된 인스턴스와 관련된 세부 정보가 포함
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
# APIHighRequestLatency 알림은
# API 요청의 중앙값 지연 시간이 1초를 초과하는 상태가 10분간 계속될 경우 트리거되며,
# 요약과 설명에는 해당 인스턴스의 지연 시간 정보를 동적으로 제공
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"이 설정 파일은 Prometheus가 두 가지 조건에 대해 알림을 발생시키도록 구성되어 있어요.
InstanceDown: 인스턴스가 5분 이상 다운된 경우 발생해요.APIHighRequestLatency: API 요청의 중앙값 지연 시간이 1초를 초과하는 상태가 10분간 계속될 경우 발생해요.
컨테이너 실행
이전 글에서 사용한 Traefik과 함께 구성했어요.
# docker-compose.yml
version: '3.9'
services:
reverse-proxy:
image: traefik:v3.1
command:
- "--api.insecure=true" # Traefik 대시보드 활성화
- "--providers.docker=true" # Docker를 프로바이더로 사용
- "--entrypoints.web.address=:80" # HTTP 트래픽을 처리하는 엔트리포인트
- "--entrypoints.traefik.address=:8080" # Traefik 대시보드 포트
- "--api.dashboard=true"
- "--log.level=INFO"
- "--accesslog=true"
ports:
- "80:80" # HTTP 트래픽 포트
- "8080:8080" # Traefik 대시보드 포트
volumes:
- "/var/run/docker.sock:/var/run/docker.sock" # Docker 소켓을 Traefik에 연결
networks:
- traefik-test
my-app:
image: "사용할 스프링 부트 애플리케이션 이미지"
networks:
- traefik-test
labels:
- "traefik.enable=true"
- "traefik.http.routers.my-app.rule=Host(`localhost`) && (PathPrefix(`/api/v1`) || PathPrefix(`/actuator`))"
- "traefik.http.services.my-app.loadbalancer.server.port=8080" # my-app 내부 포트 8080으로 라우팅
prometheus:
image: prom/prometheus:latest
container_name: prometheus
volumes:
- ./prometheus/config:/etc/prometheus
- ./prometheus/volume:/prometheus
ports:
- "9090:9090" # Prometheus 기본 웹 포트
command:
- '--web.enable-lifecycle'
- '--config.file=/etc/prometheus/prometheus.yml'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/consoles'
labels:
- "traefik.enable=true"
- "traefik.http.routers.prometheus.rule=Host(`localhost`) && PathPrefix(`/prometheus`)" # Prometheus에 대한 Traefik 라우팅 규칙
- "traefik.http.services.prometheus.loadbalancer.server.port=9090" # Prometheus 서비스 내부 포트
restart: always
networks:
- traefik-test
grafana:
image: grafana/grafana:latest
container_name: grafana
ports:
- "3000:3000" # Grafana 기본 포트
volumes:
- ./grafana/volume:/var/lib/grafana
restart: always
labels:
- "traefik.enable=true"
- "traefik.http.routers.grafana.rule=Host(`localhost`) && PathPrefix(`/grafana`)" # Grafana에 대한 Traefik 라우팅 규칙
- "traefik.http.services.grafana.loadbalancer.server.port=3000" # Grafana 서비스 내부 포트
networks:
- traefik-test
networks:
traefik-test:
driver: bridgeapplication, prometheus, grafana 컨테이너를 하나의 네트워크로 동작시키기 위한 docker-compose.yml 파일이에요.
Prometheus 컨테이너
정상적으로 실행되었다면, http://localhost:9090 에 접속하여 위와 같은 화면을 볼 수 있어요.
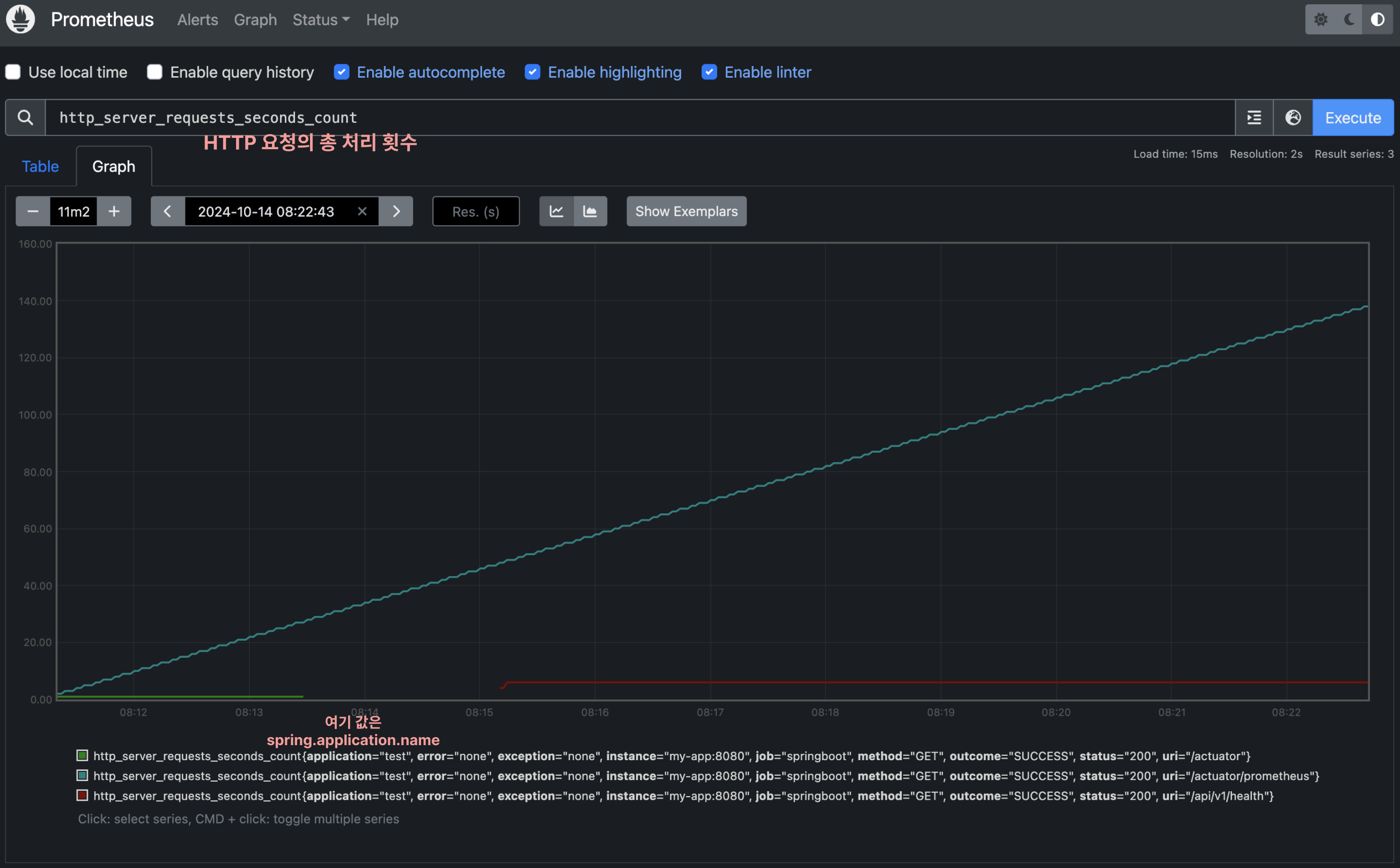
http_server_requests_seconds_count로 HTTP 요청의 총 처리 횟수를 알 수 있어요. 다른 메트릭 정보는 검색을 통해 금방 찾을 수 있어요!
이처럼 Prometheus에서도 메트릭 데이터를 그래프로 시각화할 수 있지만, Grafana를 통해 더욱 효과적으로 시각화할 수 있어요.
Grafana 컨테이너
http://localhost:3000에서 동작하고 있는 그라파나에 접속하면 로그인 화면을 볼 수 있어요. 초기 아이디와 비밀번호는 admin으로 설정되어 있어요.
로그인 하면 위와 같은 화면을 볼 수 있는데, 우리가 원하는 메트릭 시각화를 위해 두 가지 설정이 필요해요.
- 데이터 소스 추가
- 대시보드 생성
데이터 소스 추가
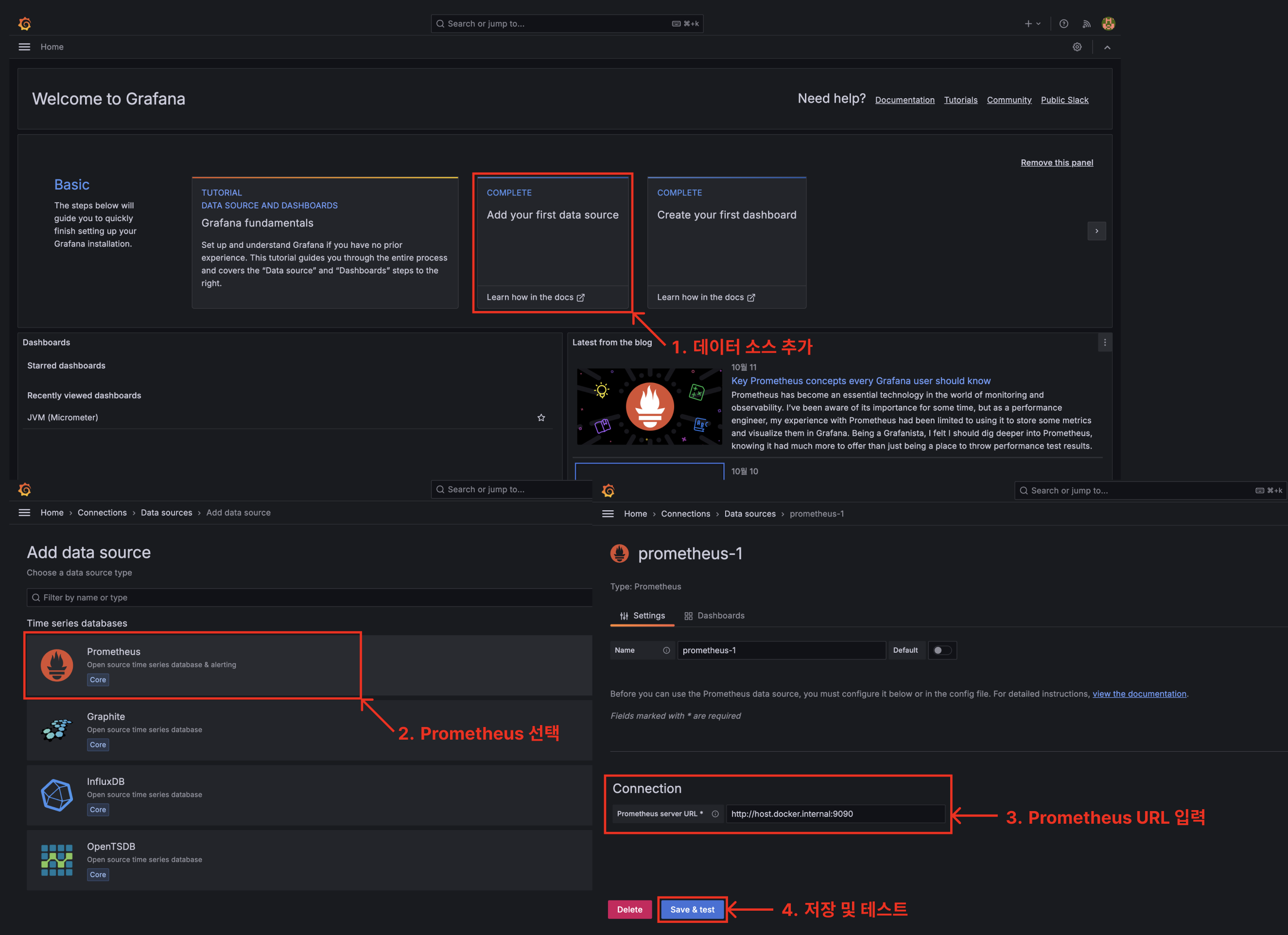
URL을 보면 host.docker.internal이라는 호스트명을 사용하고 있어요. 이는 컨테이너 내부에서 호스트 머신의 IP 주소를 가리키는 특별한 호스트명이에요. 컨테이너 내부에서 host.docker.internal을 사용하면 호스트 머신의 IP 주소로 변환해줘요.
짤막한 도커 지식
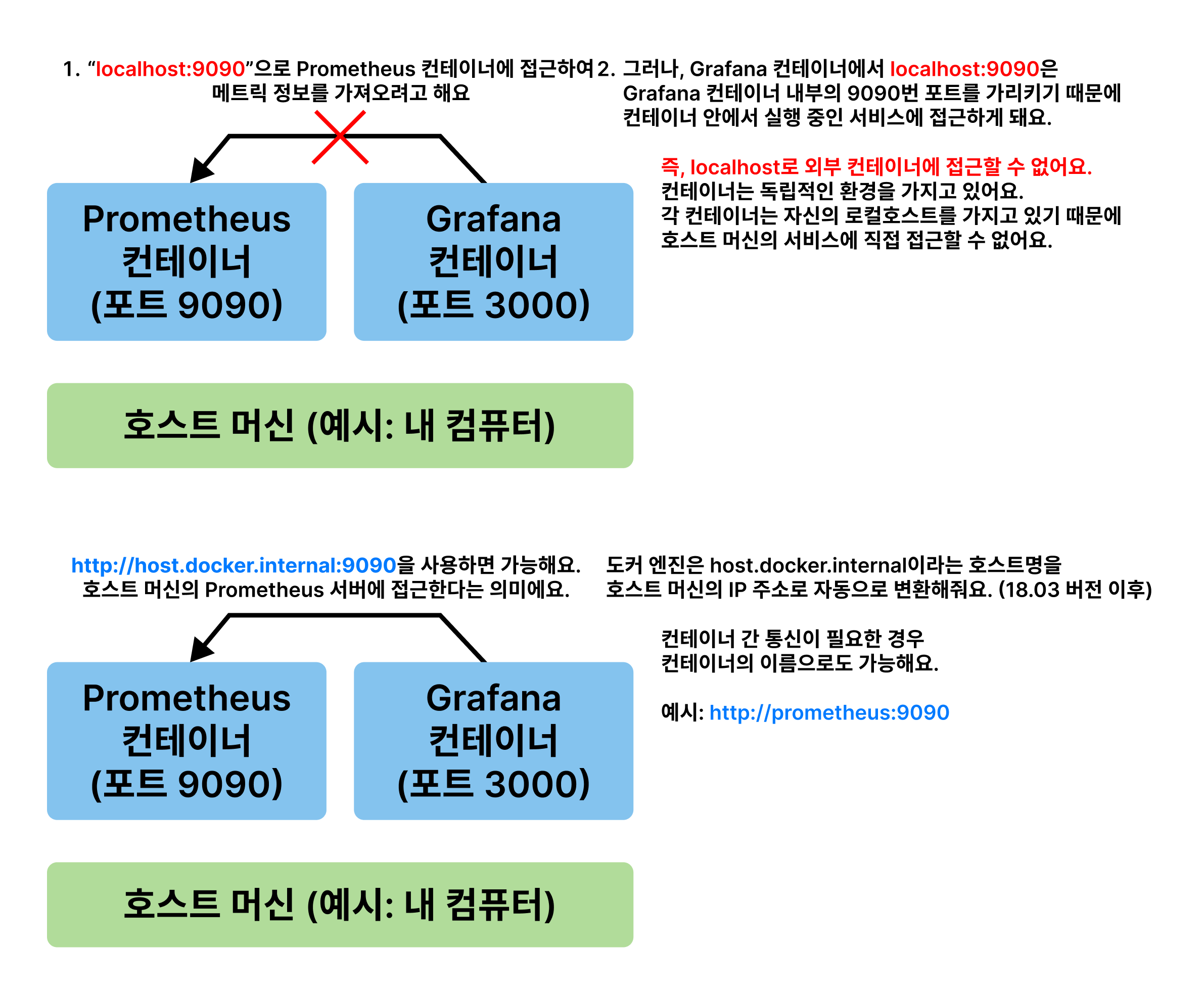
도커 컨테이너를 실행하고 있는 내 컴퓨터 입장에서 Prometheus는 localhost:9090, Grafana는 localhost:3000에서 실행되고 있어요. 하지만, Grafana 컨테이너 입장에서는 localhost가 컨테이너 내부(자기 자신)가 되기 때문에 localhost:9090으로 외부에 있는 Prometheus 컨테이너에 접근할 수 없어요. 따라서 컨테이너 내부에서 호스트에 접근하기 위해 host.docker.internal을 사용해요.
추가적으로 http://prometheus:9090와 같이 Prometheus 컨테이너의 이름을 통해서도 컨테이너 내부에서 외부 컨테이너에 접근이 가능해요.
대시보드 생성
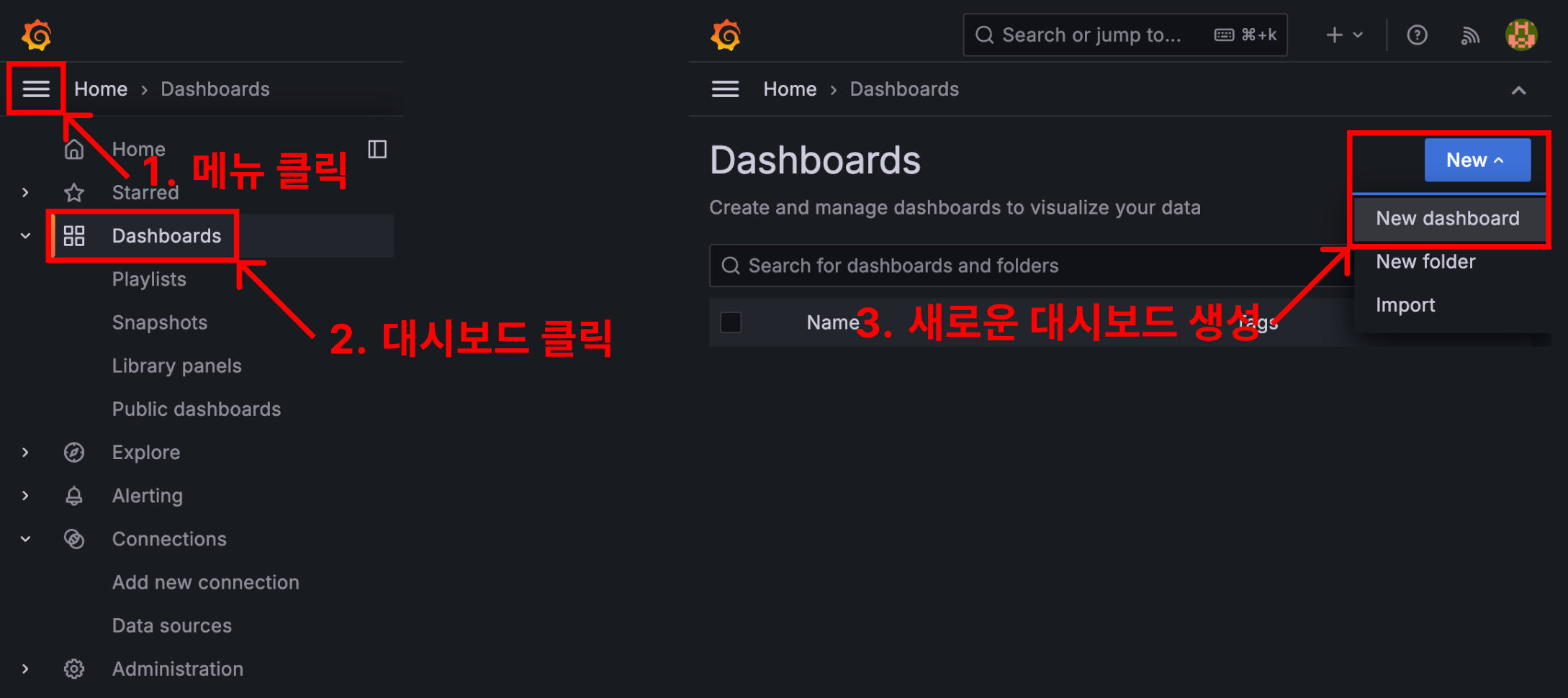
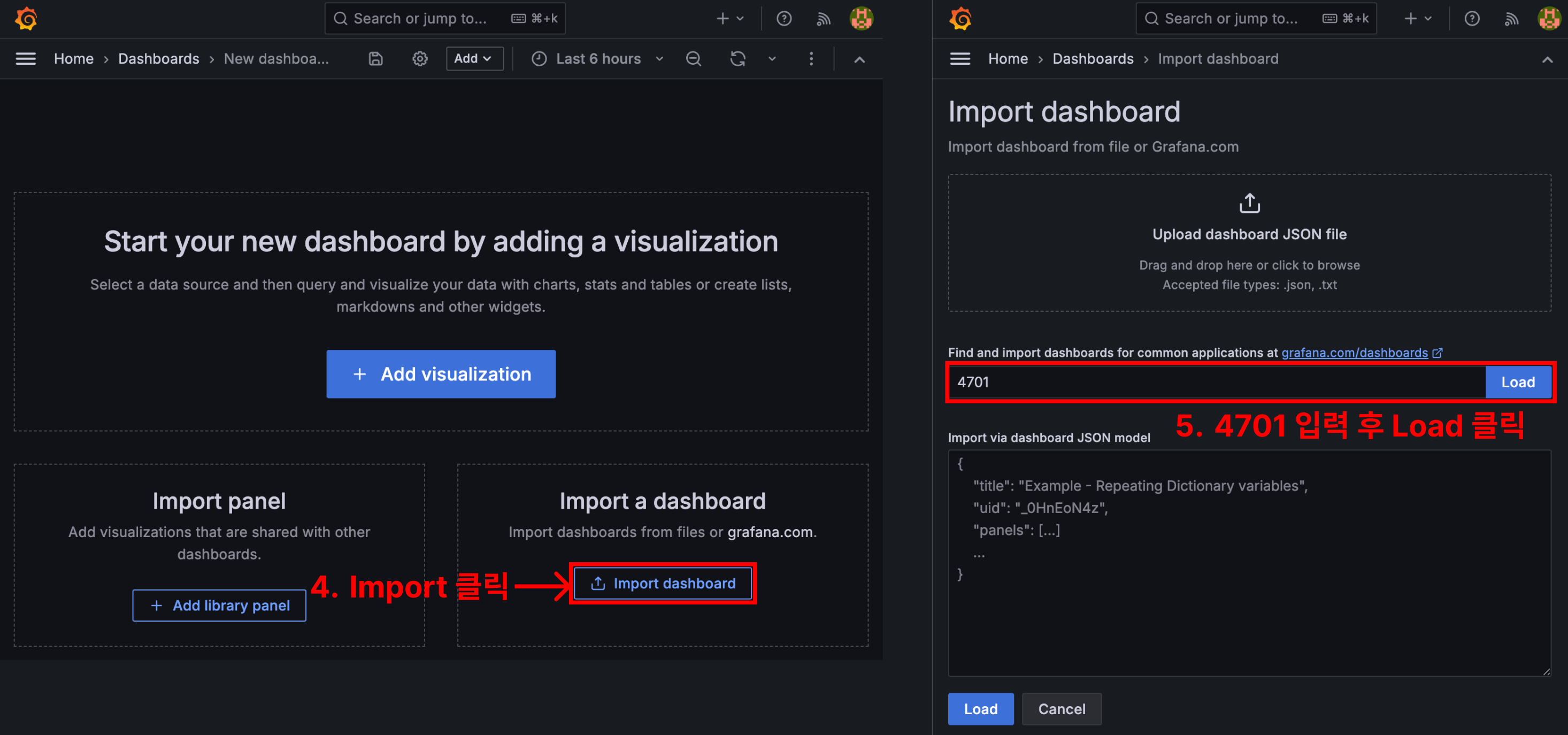
대시보드를 직접 만들어서 커스텀하는 방법도 있지만, 누군가 잘 만들어둔 대시보드를 Import 하는 방법도 있어요.
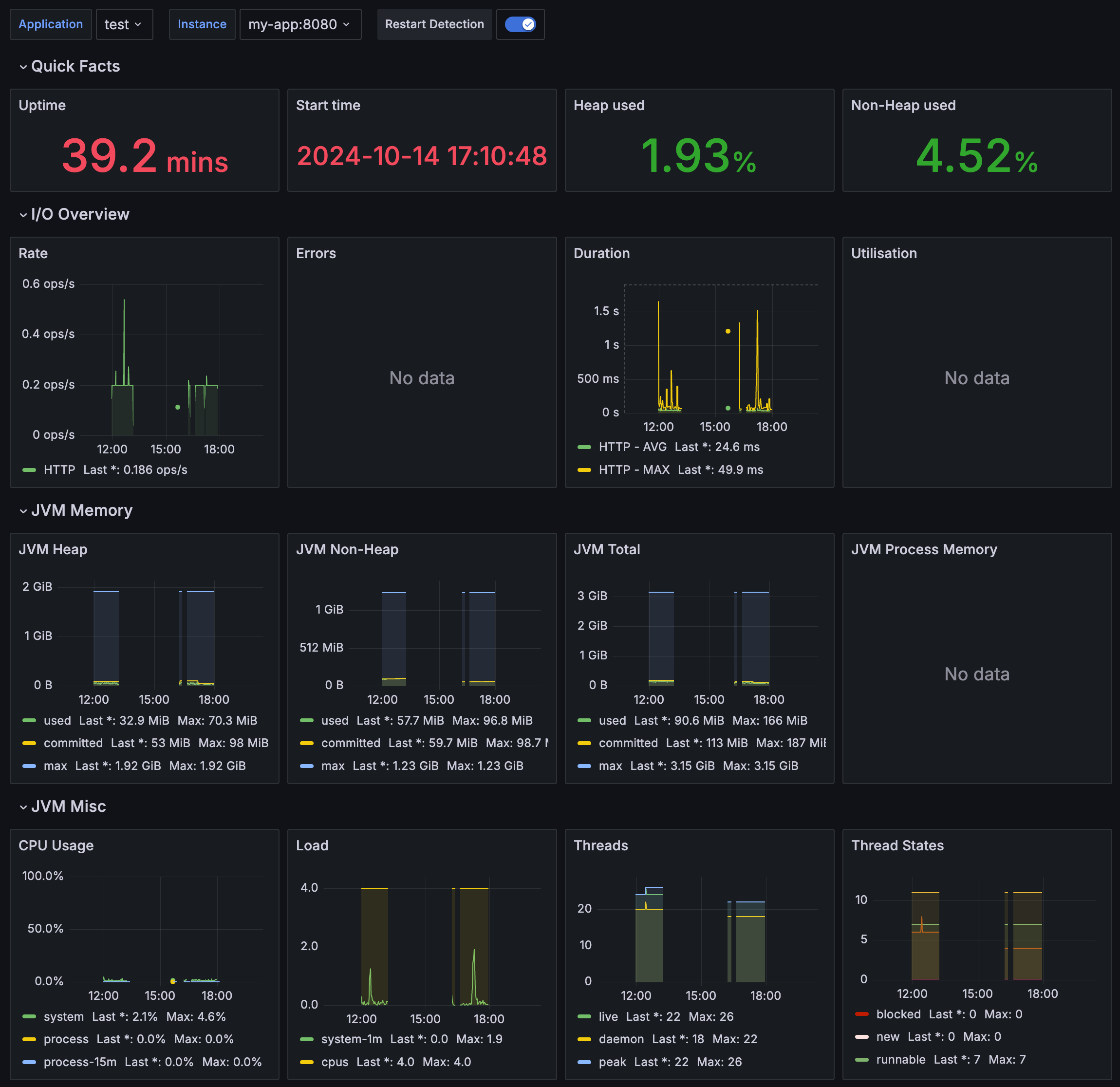
4701은 스프링 부트 메트릭을 보여주는 유명한 대시보드의 ID에요. 대시보드를 통해 I/O, JVM Memory, CPU, GC, Thread 등의 메트릭 데이터를 시각화해서 볼 수 있어요.
마무리
이번 글에서는 Prometheus와 Grafana를 활용하여 모니터링 환경을 구성하는 방법을 알아봤어요. (근데 이제 Traefik을 곁들인...)
보기 좋은 모니터링 환경을 구성하는 것보다 각 메트릭의 의미와 상관관계를 이해하고 우선순위 및 대응 프로세스를 정해두는 것이 더 중요할 것 같아요. 단순히 메트릭 정보를 알고 있다고 해서 좋은 서비스가 되는 것은 아니기 때문이에요.
아래는 더 고민해 볼 내용이에요.
- 수집된 메트릭을 어떻게 보관할 것인가?
계속 쌓아두다 보면 유의미한 정보로 발전할 수 있지 않을까요?
예를 들어, 주기적으로 데이터베이스에 저장하거나 로그 파일을 다른 곳에 백업해 두는 것도 도움이 될 것 같아요. - 모니터링 구성을 위한 추가적인 인스턴스?
같은 인스턴스에서 실행될 경우, 해당 인스턴스에 문제가 발생하면 모니터링 서버도 함께 종료될 수 있으며, 이는 신속한 대응이 어려워질 수 있을 것 같아요. - 신속한 대응을 위해 알림 설정도 가능해요.
예를 들어, Slack과 같은 툴을 활용해 중요한 이벤트를 즉시 받아볼 수 있어요.
긴 글 읽어주셔서 감사합니다.
참고 자료

너무 유익해요!