
진행 중인 프로젝트
보따리
어떤 순간에도 빠짐없이 챙길 수 있도록 돕는 체크리스트 및 알림 서비스입니다.
우아한테크코스에서 백엔드 4명, 안드로이드 3명으로 구성된 팀으로 서비스를 개발하고 있습니다.플레이스토어에서 보따리를 만날 수 있어요!
개요
이 글은 보따리 백엔드 팀이 느린 쿼리를 만나 데이터 기반으로 문제를 진단하고 개선한 경험을 정리한 글이에요.
혹시 아래와 같은 고민을 해보셨다면, 저희 팀의 경험이 좋은 참고자료가 될 수 있을 것 같아요.
- "성능 테스트, 일단 데이터 100만 건 넣고 실행해보면 되는 거 아닐까?"
- "수많은 쿼리 중 어떤 것부터 손대야 효율적일까?"
- "그래서 DB 튜닝이 정말 백엔드 개발자의 핵심 역량일까?"
가정 및 작업 시작 이유
보따리는 현재 초기 서비스 단계지만, 성장을 고려한 준비가 필요했어요. 서비스가 성장하면서 쿼리 성능 저하는 사용자 경험에 직접적인 영향을 주기 때문이에요.
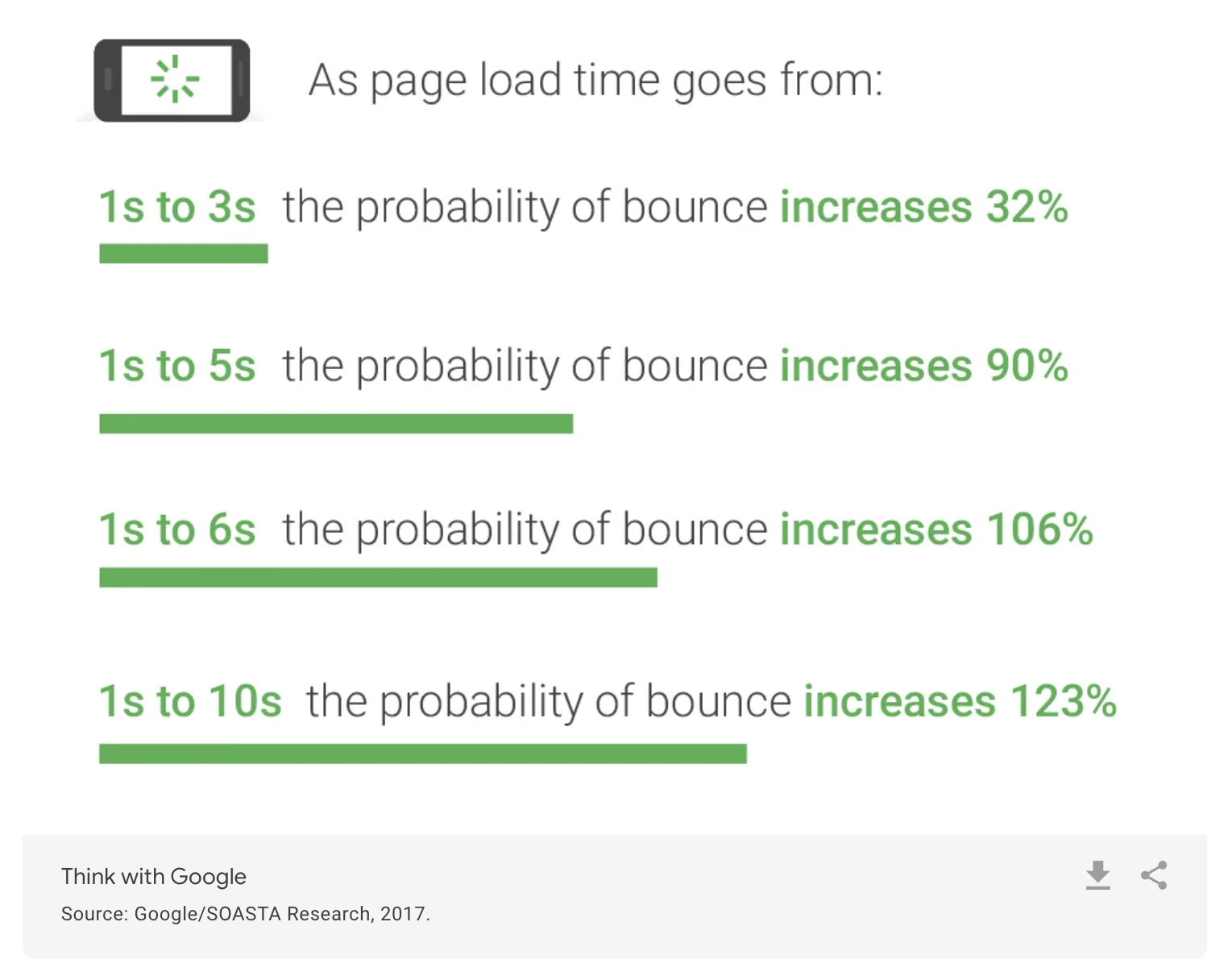
페이지 로딩 시간이 1초에서 3초로 늘어나면 이탈 확률은 32% 증가합니다. - 자료 출처
문제가 발생하기 전에 미리 성능을 점검하고 개선하기로 결정했어요.
어떻게 시작할까?
개선(改善)은 무언가를 더 낫게 만드는 것을 뜻한다.
보따리 팀에서 DB 개선을 하기 위해서는 2가지가 필요하다고 생각했어요.
- 학습
- 현재 상태 측정
학습 측면에서는 팀원 모두 데이터베이스를 개선한 경험이 많지 않아서 어느 정도 학습 후 작업하면 더 나은 선택을 할 가능성이 높아질 것 같다고 생각했고, 당연히 현재 상태를 알아야 개선을 논할 수 있으며, 지금도 문제가 아닐 가능성이 있기 때문에 측정이 필요하다고 생각했어요.
학습: 넓게보다 깊게, 필요한 부분만
성능 개선이라는 목표는 명확했지만, 막상 시작하려니 막막했어요. 인터넷이나 AI 친구들에겐 수많은 정보가 있었지만, 내용의 신뢰도나 깊이가 제각각이라 팀원 모두가 같은 지식을 공유하기 어려울 것 같았어요.
그래서 우리는 효율적인 학습과 논의를 위해 신뢰할 수 있는 단 하나의 기준을 세웠어요. 모두가 인정하는 교과서를 정하고, 그 안에서 같은 내용을 학습하자. 그래서 저희는 많은 개발자에게 DB 바이블로 여겨지는 RealMySQL 8.0을 길잡이로 삼기로 결정했어요.
선택과 집중
1, 2권 합쳐서 1,200페이지가 넘는 책을 모두 읽기엔 주어진 시간이 너무 짧다고 생각했어요. 보따리 팀의 목표는 DB 박사가 아니라, 마주친 성능 문제를 해결하는 것이었으니까요.
그래서 저희는 책의 내용 중 지금 우리에게 가장 필요한 핵심만을 선별해서 읽었어요. AI에게 우리의 문제(DB 개선)를 전달하여, 필요한 챕터만 선별했어요.
- 8장 인덱스: 느린 쿼리를 빠르게 만드는 인덱스의 원리와 활용
- 9장 옵티마이저와 힌트: 쿼리 해석과 실행 방식
- 10장 실행 계획: 쿼리 실행 과정 이해
이런 선택과 집중 덕분에 저희는 한정된 시간 안에 팀원 모두가 같은 지식 수준에서 문제에 접근하고, 해결책을 논의할 수 있게 되었던 것 같아요.
측정: 감이 아닌 데이터로 말하기
감으로 이 쿼리가 느릴 것 같다가 아니라, 200만 건 데이터 기준, 이 API는 2.5초가 걸린다처럼 정확한 데이터로 현재 상태를 측정하는 과정이 반드시 필요하다고 생각했어요.
측정을 하기 위해서는 2가지가 필요해요.
- 더미 데이터셋
- 측정 및 문제 인식 기준
더미 데이터셋은 우리가 가정하는 환경을 만들기 위해 꼭 필요하고, 어떤 결과가 문제인지에 대한 측정 및 문제 인식 기준이 필요하다고 생각했어요.
더미 데이터 만들기
더미 데이터는 양적인 측면뿐만 아니라 질적인 측면도 고려하여, 실제 운영 환경과 유사한 부하를 발생시키도록 구성했어요. (기간은 3년으로 설정)
- 실제 사용률이 높은 데이터의 비율을 높여 생성
- 특정 값(단어, 외래키 등)에 쏠림이 없도록 분포를 고려
- 서비스 로직에 맞는, 논리적으로 유효한 데이터만 삽입
예를 들어, 3년 동안 한 번도 팀에 속하지 않은 멤버도 있을 수 있고, 반대로 여러 팀에 속한 멤버도 있을 수 있겠죠.
또 검색어가 전부 '여행'이라면 쿼리 측정이 왜곡되기 때문에 다양한 키워드를 섞어 넣었어요.
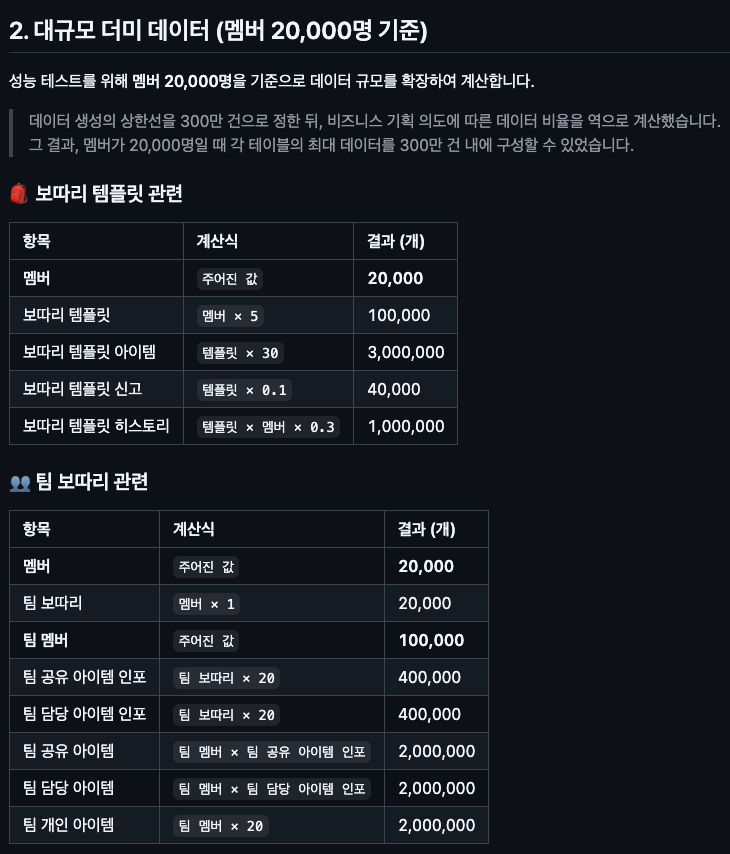
데이터는 AI를 적극적으로 활용해 만들었어요. 비즈니스 규칙과 원하는 분포를 설명하면 CSV 파일을 생성하여 MySQL에 삽입했어요.
측정 및 문제 인식 기준
JPA를 사용했기에 쿼리 로그(또는 Hibernate SQL 로그)로 실제 실행된 SQL을 확보하고, DB에서 EXPLAIN / EXPLAIN ANALYZE로 실행 계획을 확인했어요.
이때 1초 미만 또는 Full Table Scan만을 피하자는 기준을 세웠어요.
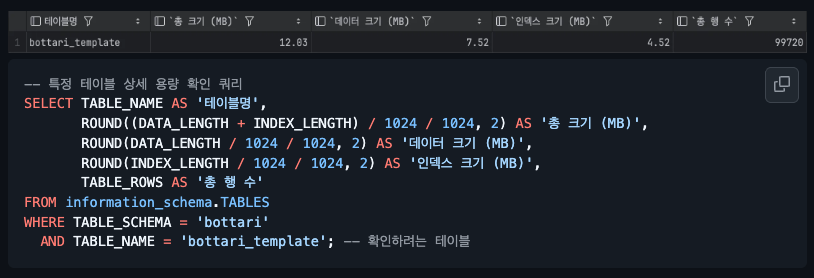
인덱스 용량 확인으로 공간적 부담을 확인해보기도 했어요.
Tip.
단순히 쿼리를 빠르게 만드는 게 최종 목표는 아니에요. 사용자에게 더 빠른 응답을 돌려주는 것이 진짜 목적이에요. (더 나은 사용자 경험) 따라서 쿼리 단위 성능만 볼 게 아니라, API 엔드포인트 전체(서비스 로직 포함) 응답 시간까지 함께 점검해야 해요.
예를 들어, 엔드포인트 전체가 1초 안에 끝나야 한다면, 쿼리 단계에서는 더 타이트한 기준을 적용하는 게 안전할 것 같아요.
개선
측정 결과
실제 쿼리, 실행 계획 등을 나열하고 팀원들과 함께 문제가 되는 쿼리를 식별했어요. 정리한 문서
모든 쿼리를 (정성껏) 테스트할 필요가 있을까?
현재는 모든 쿼리를 나열하고 같은 기준으로 테스트를 진행했어요. 그러나 항상 모든 쿼리를 테스트해야 할까요? 데이터베이스 테이블은 엄청나게 쌓이지 않을 경우도 있어요. 예를 들어, 시,군,도 정보를 가지는 테이블이라면 한계치가 정해져 있을 것 같아요. 이 경우 대규모 데이터를 고려해야 할까요? 그렇지 않을 것 같아요. 도메인에 대한 이해가 더 빠르고 정확한 병목 지점 찾는 것에 도움이 될 것 같아요.
대표 개선 사례 (검색 쿼리)
모두의 보따리 기능에서는 사용자들이 만든 보따리를 검색하거나 가져갈 수 있어요.
해당 검색 쿼리를 점검하는 과정에서 성능 저하의 주요 원인을 발견했어요.
기존 쿼리
-- 보따리 템플릿을 제목으로 검색하고 멤버 정보와 함께 조회하는 쿼리
SELECT
bt.id,
bt.created_at,
bt.deleted_at,
m.id,
m.deleted_at,
m.name,
m.ssaid,
bt.taken_count,
bt.title
FROM bottari_template AS bt
JOIN member AS m
ON m.id = bt.member_id
AND m.deleted_at IS NULL
WHERE bt.deleted_at IS NULL
AND bt.title LIKE CONCAT('%', '검색어', '%') ESCAPE ''
ORDER BY
bt.created_at DESC;실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | m1_0 | null | ALL | PRIMARY | null | null | null | 20096 | 10 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | bt1_0 | null | ref | FKektixs1dwkvv5sftpy5ldqlpw | FKektixs1dwkvv5sftpy5ldqlpw | 9 | bottari.m1_0.id | 5 | 1.11 | Using where |
-> Sort: bt1_0.created_at DESC (actual time=1391..1391 rows=0 loops=1)
-> Stream results (cost=7403 rows=117) (actual time=1391..1391 rows=0 loops=1)
-> Nested loop inner join (cost=7403 rows=117) (actual time=1391..1391 rows=0 loops=1)
-> Filter: (m1_0.deleted_at is null) (cost=2064 rows=2010) (actual time=0.0489..109 rows=18054 loops=1)
-> Table scan on m1_0 (cost=2064 rows=20096) (actual time=0.0481..107 rows=20001 loops=1)
-> Filter: ((bt1_0.deleted_at is null) and (bt1_0.title like <cache>(concat('%','검색어','%')) escape '')) (cost=2.13 rows=0.0581) (actual time=0.0708..0.0708 rows=0 loops=18054)
-> Index lookup on bt1_0 using FKektixs1dwkvv5sftpy5ldqlpw (member_id = m1_0.id) (cost=2.13 rows=5.23) (actual time=0.0551..0.0696 rows=5.01 loops=18054)- 10만 건 데이터 기준 1.391초 소요
- 실행 계획에서
ALL(Full Table Scan) 발생 - 비효율적인 조인 순서 → 불필요한
임시 테이블 생성(Using temporary)및파일 소트(Using filesort)발생
처음 세운 기준(1초 미만 응답)에 맞지 않을 뿐만 아니라, 앞으로 데이터가 계속 늘어날 도메인이었기 때문에 반드시 개선해야 할 쿼리였어요.
개선 1: 커서 기반 페이징(No-Offset)으로 불필요한 조회 제거
📌 개선 요약: 불필요한 데이터 조회 제거 → 실행 시간 77% 단축 (1.391초 → 0.319초)
기존 쿼리는 검색 조건에 맞는 모든 결과를 한 번에 가져오는 방식이었어요.
결과가 수만 건 이상일 경우 애플리케이션 메모리를 과도하게 점유하거나, 다음 페이지를 보지 않아도 데이터를 불러오는 문제가 있었죠. 특히 OFFSET 기반 페이징은 페이지가 뒤로 갈수록 성능이 급격히 떨어지는 한계가 있었어요.
이를 해결하기 위해 커서 기반 페이징(No-Offset)을 도입했어요. 마지막으로 조회한 데이터를 기준점(cursor)으로 삼아, 필요한 n건만 가져오도록 쿼리를 수정했어요.
-- 커서 기반 + 최신순 쿼리
SELECT
bt.id,
bt.created_at,
bt.deleted_at,
m.id,
m.deleted_at,
m.name,
m.ssaid,
bt.taken_count,
bt.title
FROM
bottari_template AS bt
JOIN
member AS m
ON m.id = bt.member_id AND m.deleted_at IS NULL
WHERE
bt.deleted_at IS NULL
AND bt.title LIKE CONCAT('%', '해외 여행', '%') ESCAPE ''
AND (
bt.created_at < '2025-09-01 10:00:00' -- 마지막으로 본 아이템의 생성 시간
OR (
bt.created_at = '2025-09-01 10:00:00'
AND bt.id < 10000 -- 생성 시간이 같다면 ID로 순서 보장
)
)
ORDER BY
bt.created_at DESC,
bt.id DESC
LIMIT
10; -- 필요한 만큼만 조회실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | m1_0 | null | ALL | PRIMARY | null | null | null | 20095 | 10 | Using where; Using temporary; Using filesort |
| 1 | SIMPLE | bt1_0 | null | ref | PRIMARY,FKektixs1dwkvv5sftpy5ldqlpw | FKektixs1dwkvv5sftpy5ldqlpw | 9 | bottari.m1_0.id | 5 | 0.93 | Using where |
-> Limit: 10 row(s) (actual time=319..319 rows=10 loops=1)
-> Sort: bt1_0.created_at DESC, bt1_0.id DESC, limit input to 10 row(s) per chunk (actual time=319..319 rows=10 loops=1)
-> Stream results (cost=5844 rows=100) (actual time=0.319..318 rows=2039 loops=1)
-> Nested loop inner join (cost=5844 rows=100) (actual time=0.313..316 rows=2039 loops=1)
-> Filter: (m1_0.deleted_at is null) (cost=2050 rows=2010) (actual time=0.0514..11.7 rows=18054 loops=1)
-> Table scan on m1_0 (cost=2050 rows=20095) (actual time=0.0503..9.83 rows=20001 loops=1)
-> Filter: ((bt1_0.deleted_at is null) and (bt1_0.title like <cache>(concat('%','해외 여행','%')) escape '') and ((bt1_0.created_at < TIMESTAMP'2025-09-01 10:00:00') or ((bt1_0.created_at = TIMESTAMP'2025-09-01 10:00:00') and (bt1_0.id < 10000)))) (cost=1.35 rows=0.05) (actual time=0.0162..0.0167 rows=0.113 loops=18054)
-> Index lookup on bt1_0 using FKektixs1dwkvv5sftpy5ldqlpw (member_id = m1_0.id) (cost=1.35 rows=5.39) (actual time=0.0119..0.0155 rows=5.01 loops=18054)페이징 처리는 애플리케이션의 안정성을 확보하고 불필요한 부하를 줄이는 필수적인 1차 개선이었어요.
filesort 및 temporary table의 대상이 전체 결과에서 10건으로 크게 줄어들어 실행 시간이 레코드 10만 건 기준 1.391초 → 0.319초로 약 77% 개선되었어요.
개선 2: LIKE 대신 Full-Text Index 도입
📌 개선 요약: LIKE Full Scan 제거, 인덱스 기반 검색으로 전환 → 실행 시간 95.4% 추가 개선 (0.319초 → 0.0147초)
커서 기반 페이징을 적용했음에도, 검색 결과가 적거나 없을 때는 여전히 테이블을 광범위하게 스캔해야 했어요. 100만 건 기준, 검색 결과가 없는 경우 최대 1.8초까지 걸렸어요.
# 100만 건 기준 검색 결과가 없는 경우의 실행 계획
-> Limit: 10 row(s) (cost=110599 rows=10) (actual time=1811..1811 rows=0 loops=1)
-> ....LIKE 검색의 구조적 한계를 극복하고자 Full-Text Index를 도입했어요. N-gram 파서는 형태소 분석기처럼 문법을 이해하지는 않지만, 글자를 N개 단위로 잘라 인덱싱하기 때문에 띄어쓰기나 단어 변형에 강해요. 덕분에 복잡한 설정 없이도 LIKE '%키워드%' 방식보다 성능과 검색 정확도를 개선할 수 있었어요.
특히 한글은 조사나 어미가 단어에 직접 붙어 형태가 자주 바뀌기 때문에('보따리' vs '보따리를'), 어디까지가 한 단어인지 구분하기 까다로운 편이에요. N-gram은 이러한 문법적 고민 없이 모든 글자를 분해하므로, 사용자가 어떤 검색어를 입력하든 일관된 결과를 제공하는 실용적인 해결책이라고 판단했어요.
-- Full-Text Index를 사용하도록 개선된 쿼리
SELECT
bt.id,
bt.created_at,
bt.deleted_at,
m.id,
m.deleted_at,
m.name,
m.ssaid,
bt.taken_count,
bt.title
FROM
bottari_template AS bt
JOIN
member AS m
ON m.id = bt.member_id AND m.deleted_at IS NULL
WHERE
bt.deleted_at IS NULL
AND MATCH(bt.title) AGAINST('+해외 +여행' IN BOOLEAN MODE) -- 해외 and 여행
AND (
bt.taken_count < 3000
OR (
bt.taken_count = 3000
AND bt.id < 10000
)
)
ORDER BY
bt.taken_count DESC,
bt.id DESC
LIMIT
10;실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | bt1_0 | null | fulltext | PRIMARY,FKektixs1dwkvv5sftpy5ldqlpw,idx_template_title | idx_template_title | 0 | const | 1 | 5 | Using where; Ft_hints: no_ranking; Using filesort |
| 1 | SIMPLE | m1_0 | null | eq_ref | PRIMARY | PRIMARY | 8 | bottari.bt1_0.member_id | 1 | 10 | Using where |
-> Limit: 10 row(s) (cost=0.368 rows=0.1) (actual time=14.6..14.7 rows=10 loops=1)
-> Nested loop inner join (cost=0.368 rows=0.1) (actual time=14.6..14.7 rows=10 loops=1)
-> Sort row IDs: bt1_0.taken_count DESC, bt1_0.id DESC (cost=0.255 rows=1) (actual time=14.6..14.7 rows=10 loops=1)
-> Filter: ((bt1_0.deleted_at is null) and (match bt1_0.title against ('+해외 +여행' in boolean mode)) and ((bt1_0.taken_count < 3000) or ((bt1_0.taken_count = 3000) and (bt1_0.id < 10000))) and (bt1_0.member_id is not null)) (cost=0.255 rows=1) (actual time=0.539..11.3 rows=2257 loops=1)
-> Full-text index search on bt1_0 using idx_template_title (title = '+해외 +여행') (cost=0.255 rows=1) (actual time=0.535..10.9 rows=2505 loops=1)
-> Filter: (m1_0.deleted_at is null) (cost=0.45 rows=0.1) (actual time=0.00468..0.00478 rows=1 loops=10)
-> Single-row index lookup on m1_0 using PRIMARY (id = bt1_0.member_id) (cost=0.45 rows=1) (actual time=0.00444..0.00447 rows=1 loops=10)LIKE 절의 Full Scan이 사라지고 인덱스 기반의 빠른 검색이 가능해졌어요. 0.319 -> 0.0147초 (개선 1 대비) 약 95.4% 또한 검색 결과 유무와 관계없이 일관되게 빠른 성능을 확보하게 되었어요.
전문 검색 인덱스 추가 과정
-- 전문 검색 인덱스 추가 방법
CREATE FULLTEXT INDEX idx_template_title
ON bottari_template(title)
WITH PARSER ngram;Full-Text Index를 추가할 경우 데이터 10만 건(8.5MB) 기준 인덱스 크기가 2.52 → 7.03 MB로 증가 약 2.79배 증가하지만, 현재 인프라에서 부담되는 정도가 아니며, 명확한 한계가 보이는 방법보다는 낫다고 판단했습니다.
ngram = 1
-- mysql 설정값 변경 필요
ngram_token_size=1한 글자 검색까지 지원하여 사용자 경험을 극대화하기 위해 ngram_token_size=1로 설정했어요. title 컬럼의 최대 길이가 15자로 짧고, 조회(Read) 비율이 압도적으로 높다고 판단하여 인덱스 크기 증가나 쓰기 성능 저하의 부담보다 조회 성능 개선의 이점이 훨씬 크다고 판단했어요.
개선 3: STRAIGHT_JOIN으로 옵티마이저 실행 계획 보정
📌 개선 요약: 검색어 유무와 관계없이 안정적인 실행 계획 확보 → 실행 시간 99.3% 추가 개선 (0.0147초 → 0.000106초)
전문 검색 인덱스를 도입하여 검색어 입력 시의 성능은 개선되었으나, 새로운 문제가 발생했어요.
검색어가 비어있을 경우 전체 템플릿 목록을 조회해야 하는데, MATCH(...) AGAINST('')는 결과를 반환하지 않아요.
그래서 아래와 같이 OR 조건을 추가했어요.
WHERE ... AND ('검색어' = '' OR MATCH(bt1_0.title) AGAINST('검색어' IN BOOLEAN MODE))하지만 이 OR 조건은 검색어가 비어있을 때, 옵티마이저는 '' = '' 조건이 항상 TRUE라는 이유로 Full-Text Index를 무시하고 member 테이블을 Full Scan하는 과거의 비효율적인 실행 계획을 선택하게 되었어요.
실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | bt1_0 | null | ALL | PRIMARY,FKektixs1dwkvv5sftpy5ldqlpw | null | null | null | 99719 | 13.55 | Using where; Using filesort |
| 1 | SIMPLE | m1_0 | null | eq_ref | PRIMARY | PRIMARY | 8 | bottari.bt1_0.member_id | 1 | 10 | Using where |
-> Limit: 10 row(s) (actual time=783..783 rows=10 loops=1)
...CREATE INDEX idx_created_at_id ON bottari_template(created_at DESC, id DESC);
CREATE INDEX idx_taken_count_id on bottari_template(taken_count desc, id desc );SELECT STRAIGHT_JOIN -- STRAIGHT_JOIN 추가
bt1_0.id,
bt1_0.created_at,
...idx_created_at_id와 idx_taken_count_id 인덱스를 생성하고, 옵티마이저의 비합리적인 조인 순서를 조정하기 위해 STRAIGHT_JOIN을 사용했습니다.
STRAIGHT_JOIN은 FROM 절 순서(bottari_template -> member)대로 조인을 수행하게 하여, 옵티마이저의 비합리적인 선택을 피할 수 있었어요.
실행 계획
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | bt1_0 | null | index | PRIMARY,FKektixs1dwkvv5sftpy5ldqlpw,idx_created_at_id | idx_created_at_id | 17 | null | 99 | 13.55 | Using where |
| 1 | SIMPLE | m1_0 | null | eq_ref | PRIMARY | PRIMARY | 8 | bottari.bt1_0.member_id | 1 | 10 | Using where |
-> Limit: 10 row(s) (cost=3334 rows=1.34) (actual time=0.0449..0.106 rows=10 loops=1)
...STRAIGHT_JOIN 사용 시 주의사항
STRAIGHT_JOIN은 강력하지만, 다음과 같은 상황에서는 오히려 성능이 악화될 수 있어요.
- 데이터 분포 변화: bottari_template의 데이터가 member보다 훨씬 많아지는 경우
- 조회 패턴 변화: 특정 member_id에 데이터가 쏠리는 경우
- 버전 변경: 특정 버전에서 달라지는 경우
따라서 정기적으로 실행 계획을 확인해야 해요.
개선 결과
모두의 보따리 조회(검색) 기능을 10만 건 기준 실행 시간 1.391초 → 0.000106초 로 개선할 수 있었어요.
- 페이징 도입으로 불필요한 데이터 조회 제거
- Full-Text Index로 검색 성능 개선
- 필요한 인덱스 추가 및 STRAIGHT_JOIN 활용으로 검색어 유무에 따른 실행 계획 안정화
- 테스트 환경, 더미 데이터 구성 방법, 개선 근거 및 기준 등을 문서로 작성
개선 과정 요약
| 단계 | 실행 시간 | 주요 개선 포인트 |
|---|---|---|
| 기존 | 1.391초 | Full Table Scan, Filesort |
| 개선1 | 0.319초 | 커서 기반 페이징 |
| 개선2 | 0.0147초 | Full-Text Index |
| 개선3 | 0.000106초 | STRAIGHT_JOIN, 인덱스 보정 |
과정 중 궁금했던 부분
테스트 환경은 프로덕션과 일치해야 할까?
이상적으로는 프로덕션과 동일한 환경에서 테스트하는 것이 가장 좋아요.
하지만 비용과 운영 복잡성을 고려하면, 완벽하게 복제하는 건 현실적으로 쉽지 않아요.
그래도 아래 요소들을 맞춰주면 테스트 신뢰도를 크게 높일 수 있어요.
- DB 버전 및 핵심 설정: MySQL 버전뿐만 아니라
innodb_buffer_pool_size,optimizer_switch같은 성능 관련 설정은 반드시 일치시키는 게 좋아요. - 데이터 분포와 양: 단순히 데이터 양뿐 아니라, 실제 서비스와 유사한 분포(Skew)를 갖춰야 옵티마이저가 비슷한 실행 계획을 선택해요.
- 인프라 사양의 비율: CPU, RAM, Disk를 동일하게 맞추는 게 이상적이에요.
어렵다면 최소한 로컬 PC처럼 프로덕션과 극단적으로 다른 환경은 피하고, 그 결과는경향성확인 용도로만 보는 게 좋아요.
더미 데이터는 어떻게 구성할까?
저희는 두 가지 방식을 고민했고, 최종적으로 AI를 활용한 CSV Bulk Insert를 선택했어요.
1. AI 활용 CSV + Bulk Insert (선택한 방식)
- 수백만 건의 데이터를 가장 빠르게 적재할 수 있었어요.
- AI가 생성한 다양한 텍스트 덕분에 실제 사용자처럼 보이는 데이터도 쉽게 확보할 수 있었어요.
단점은 애플리케이션 로직을 거치지 않다 보니, 비즈니스 규칙을 위반하는 '더러운 데이터'가 생길 수 있다는 점이에요.
(예: 이미 탈퇴한 회원이 팀 보따리에 소속되는 경우)
2. 서비스 로직(API) 호출로 적재
- 실제 서비스 API나 서비스 메서드를 호출하기 때문에, 항상 비즈니스적으로 유효한 데이터가 생성돼요.
- 실제 사용자와 가장 유사한 방식으로 데이터가 쌓이기 때문에 테스트 결과의 신뢰도가 높아져요.
하지만 이 방식은 애플리케이션 로직과 DB 트랜잭션을 모두 거치기 때문에, 대량 데이터를 생성할 때는 시간이 매우 오래 걸린다는 단점이 있어요.
서비스는 천천히 클 텐데, 항상 미리 이렇게 튜닝해야 할까?
“섣부른 최적화는 팀의 생산성을 떨어뜨린다”는 말을 많이 들었어요.
그래서 고민도 많이 하고, 질문도 많이 해본 끝에 이렇게 정리했어요.
즉, ‘나중에 문제가 생겼을 때 수정 비용이 큰가?’를 기준으로 판단하면 된다고 생각해요.
미리 최적화를 고려해야 하는 경우
- 서비스의 핵심 기능: 성패를 좌우하는 기능이라면 시간을 투자할 만해요.
- 트래픽 급증이 예상되는 경우: 대형 플랫폼에 출시되거나, 한번에 많은 사용자가 몰릴 수 있는 기능일 때 (예: 카카오 신규 앱, 스레드 출시 시점)
나중에 대응해도 괜찮은 경우
- 어드민 페이지나 사용 빈도가 낮은 비핵심 기능
- 초기 MVP 단계에서 사용자 반응을 먼저 확인해야 하는 기능
결론: 도메인 이해의 중요성
이번 DB 성능 개선을 통해 사용자에게 쾌적한 경험을 제공할 수 있게 되었어요.
그러나 이번 작업의 진짜 가치는 단순히 SQL 튜닝 기술을 배운 것이 아니라, "어떤 쿼리부터 개선해야 하는가?"라는 질문에 접근하는 방법을 배운 것 같아요.
인터넷에는 수많은 DB 최적화 기법들이 있지만, 어떤 기법을 언제 적용할지는 결국 서비스를 가장 잘 이해하고 있는 우리가 판단해야 했어요.
- 어떤 기능이 사용자에게 핵심인가?
- 어떤 테이블의 데이터가 빠르게 증가하는가?
- 사용자들은 실제로 어떻게 검색하는가?
백엔드 개발자로서 도메인을 깊이 이해할수록, 이런 질문들에 더 명확히 답할 수 있을 것이고, 수많은 쿼리 중에서 진짜 병목을 빠르게 찾고 적절한 해결책을 선택할 수 있을 것 같아요.
남은 과제
현재는 단일 요청 속도에 집중했지만, 실제 서비스에서는 다음 단계가 필요해요.
- 부하 테스트: 동시 사용자 환경에서의 처리량 검증
- 동시성 제어: 락 경합, 데드락 등 실제 환경 이슈 해결
- 지속적 모니터링: 데이터 증가에 따른 성능 변화 추적
DB 성능 개선은 한 번에 끝나는 게 아니라,
서비스와 함께 계속 발전시켜야 하는 여정이라는 걸 깨달았어요.
긴 글 읽어주셔서 감사합니다.




쿼리문으로 이렇게 할 수 있다니 정말 유익하네요!