Adversarial Attack
머신러닝 시스템을 속이기 위해 데이터를 의도적으로 변형(adversarial example)하여 시스템을 공격하는 것
- Adversarial Learning: 적대적 환경에서 adversarial example이 들어왔을 때 어떤 부분이 머신러닝 시스템에서 취약한가에 대하여 이해함과 동시에 방어하기 위한 연구
- ex) 스팸 메일을 필터링하는 과정
- 스팸 메일로 분류되는 것을 피하기 위해 "광고" 대신 "광--고"로 대체하는 것
- 이때 "광--고"는 adversarial example
- "광--고"를 포함하여 재학습하는 것이 adversarial learning
- 스팸 메일로 분류되는 것을 피하기 위해 "광고" 대신 "광--고"로 대체하는 것
- ex) 지문 위변조 liveness detection
- liveness detection: 실제 사람을 감지하는 기술
Adversarial Attack 의미
- 학습된 Hypothesis가 있을 때 경계선 근방 감시영역의 데이터로 모델을 속이는 것
- 감시영역 Data augmentation을 통해 데이터를 늘려 contrastive learning을 거쳐 adversarial learning을 한다.
- 데이터 공간의 Hypothesis가 부드러운 곡선일 경우 attack을 막기 좋다.
- Hypothesis에 첨점이 있는 날카로운 형태라면 정규화가 충분하지 않은 Overfitting 상태이다. 따라서 적대적 공격을 방어하기 어렵다.
Deep Learning 이전의 적대적 공격
- 적대적 공격은 딥러닝 시대 이전에도 존재하였다.
- 전통적인 머신 러닝 방법을 이용하여 공격하고 방어하였다.
- 딥러닝 이전에 적대적 공격 관련 연구가 활발하지 않았던 이유
- 실제 활용할 수 있는 분야가 매우 제한적이다.
- 인공지능 및 머신러닝 분야가 활발해진 이후에 적대적 공격과 관련된 연구 분야가 활발해질 수 있다.
Deep Learning 시대의 적대적 공격
- 적대적 공격 및 방어와 관련된 연구가 매우 중요하고 인기있는 연구분야로 자리잡고 있다.
- 많은 CNN 기반의 딥러닝 기술들이 우리 삶의 여러 분야에 활용되고 있다.
- 얼굴 인식 및 지문 인식
- Financial 분야에서의 보안 문제가 매우 중요하게 다루어지고 있다.
- 적대적 공격 발전
- 적대적 공격자는 딥러닝 알고리즘을 회피하기 위한 전략이나 패턴을 개발한다.
- 공격 방어자는 회피 전략에 대한 대응책을 마련하고 이에 대한 모델을 강화할 전략을 마련한다.
기본적 구조
- Adversarial Sample, Adversarial Example
- 육안으로 보기에는 데이터의 분포와 매우 유사한 특성을 가지고 있지만 인식을 속이거나 인식에 악영향을 미치는 sample
- 정상적인 영상과 매우 유사하지만 의도적으로 잡음을 섞어서 기계학습 시스템을 교란시키거나 속이기 위한 데이터
- ex) Fat Panda Image + Noise 7% = Capuchin
- 잡음을 섞어 Hypothesis를 넘어간 경우
- Non-targeted Attack(General Attack)
- Adversarial image를 잘못 인식하도록 딥러닝 모델 등을 강제화하는 방법
- 영상을 오염시켜 잘못 분류하게 하는 방법
- Targeted Attack
- 원래 영상에 대한 클래스 대신 다른 클래스로 인식하는 모델을 만드는 방법
- Class
A의 이미지를C로 지정해서 변형한다. - 원래의 clean image를 잘못 분류하게 모델을 만드는 방법
설명 가능한 인공지능이 필요한 이유
- Black-box Attacks
- 적대적 공격이 모델에서 어떻게 작동하고 있는지 전혀 모르는 경우
- Semi-black-box Attacks
- 모델에서 적대적 공격이 일어나는 것에 대하여 제한적으로 알고 있으나 파라미터 등에 대한 이해가 부족한 경우
- White-box Attacks
- 모델에서 적대적 공격에 대한 정보를 완전히 알고 있을 때
- 공격과 방어를 잘하기 위한 방법
CNN 중심 적대적 공격
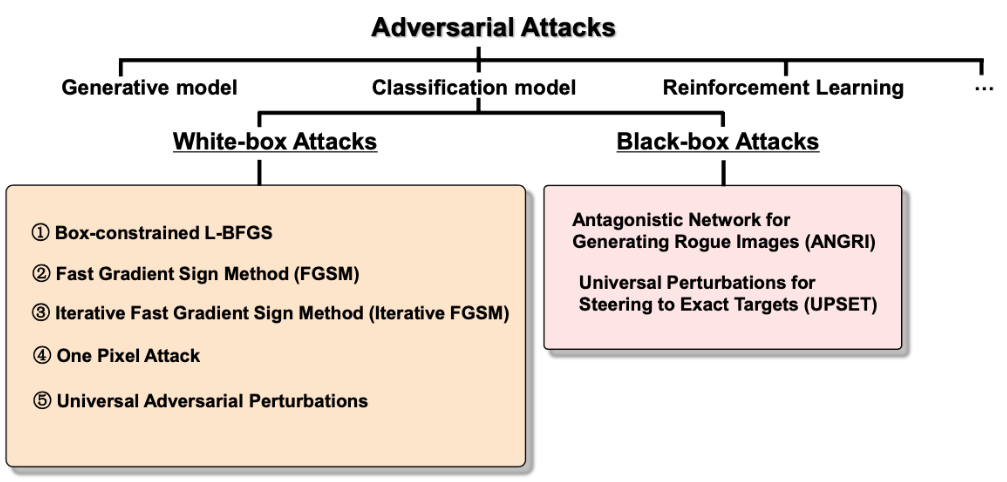
- Box-constrained L-BFGS
- Broyden-Fletcher-Goldfarb-Shanno algorithm
- 제한된 메모리 환경에서의 최적화 문제를 해결하기 위한 알고리즘
- Non-linear 최적화 문제를 해결하기 위한 반복적 방법의 하나이다.
- 라는 파라미터로 된 네트워크 , 그리고 sample 와 label
- 공격자는 가 target label 로 분류되기를 원한다.
- : 최소한의 noise(pertubation)
: 를 로 분류하기 위한(경계선 넘기)- Targeted Attack
- Optimization:
- 하나의 데이터에 대해 target 방향으로 움직이기 위한 Loss function
- Multi-step precedure
- 최적화 알고리즘을 풀어 최적의 adversarial을 만드는 데 있어 많은 시간(몇분)이 걸린다.
- Transferability: 하나의 모델에 대한 적대적 공격에 활용된 sample은 다른 모델에서 적용될 수 있다.
- Fast Gradient Sign Method(FGSM)
- Single-step and Fast
- Linear perturbation을 이용하여 손쉽게 적대적 공격 모델을 만들 수 있다.
- Binary Classification의 부호를 바꾸어 Attack하는 것
- Pertubation
- 은 0.1 또는 0.007 같은 작은 상수
- 데이터를 Hypothesis로부터 멀리 떨어뜨리기 때문에 매우 공격적이다.
- Iterative Fast Gradient Sign Method
- FGSM의 강화된 모델
- 현재 적대적 이미지:
- 반복적으로 만드는 다음 이미지:
- : step size
- : 이미지를 많이 바꾸지 않기 위한 역할
픽셀 강도를 잘라낸다. - : 이미지가 모델에 어떻게 보이는지 판단 후 업데이트 방향 결정
- 적대적 이미지를 조금씩 바꾸어, 사람이 보기에 거의 변하지 않은 것 같지만 컴퓨터가 틀리게 인식하게 만드는 과정
- One Pixel Attack
- 주어진 영상에서 하나의 픽셀 정보만 바꾸어 class 정보를 바꾸는 공격
- 영상으로부터 여러번 반복을 통해서 class 정보를 바꾸기 쉬운 후보 pixel을 찾고 인식 성능을 최저로 낮추어 다른 class로 바꾸도록 영상 pixel의 intensity(강도)를 변화한다.
- ex) 비행기 이미지를 강아지로 인식하게 공격
- 비행기를 인식할 때 가장 중요한 요소를 공격한다.
- ex) 고양이 이미지에서 코에 점을 찍으면 강아지로 인식한다.
- ex) 강아지 이미지에서 눈 밑에 점을 찍으면 고양이로 인식한다.
- Universal Adversarial Perturbations
- 기존의 알고리즘들은 각 영상에 맞는 pertubation이 존재했으나 모든 영상에 적용 가능한 pertubation을 찾고자 하는 연구가 진행되었다.
- 어떠한 영상이 들어와도 원하는 class의 정보를 바꾸어 다른 class로 잘못 인식되게 만들 수 있다.
- 모든 영상에 대해 적용되는 adversarial attack에 대하여 적분하여 적대적 공격 예제로 활용된다.
- Non-target Attack
- 기존의 알고리즘들은 각 영상에 맞는 pertubation이 존재했으나 모든 영상에 적용 가능한 pertubation을 찾고자 하는 연구가 진행되었다.
Adversarial patch
Image patch를 clean 이미지에 덧붙여 공격하는 것
- patch와 같은 noise의 형태가 매우 다양하다.
- 사회에 많은 문제가 발생할 수 있다.
- Stop 표지판에 간단한 patch만으로 주행 표지판으로 잘못 인식할 수 있다.
- 잡음과 비슷한 소리만으로 잘못된 명령을 내릴 수 있다.
- 잘못된 상품을 인식하여 사용자가 원하지 않는 상품을 거래할 수 있다.
Semantic Segmentation에 대한 적대적 공격
- 자율주행자동차 환경에 치명적이다.
논의사항
- Adversarial attack의 특징
- Small perbutation: 아주 작은 잡음을 주입하여도 성능에 영향을 미친다.
- 잡음을 막기 위해 denoising을 하기도 한다.
- High confidence: 작은 잡음을 통해 다른 class로 오인식되어도 오인식된 class의 신뢰도가 매우 높기 때문에(FGSM) adversarial example인지 확인하기 어렵다.
- Transferability: 특정 네트워크에만 적용되는 것이 아니라 모든 네트워크에 적용 가능하다.
- Small perbutation: 아주 작은 잡음을 주입하여도 성능에 영향을 미친다.
- Adversarial attack의 유형
Hypothesis가 어떻게 생겼는지 알아야 attack 가능하다.- 다양한 형태로 존재하고 있으나 아직 알려진 사항은 많지 않기 때문에 다양한 공격 유형에 대한 연구가 필요하다.
- 지금까지 대부분 classification 연구가 집중되었으나, generative model이나 reinforcement learning에도 존재할 것으로 예상된다.
- 설명가능한 인공지능 및 네트워크에 대한 이해에 긍정적인 영향을 줄 수 있다.
- 다양한 adversarial attack 알고리즘과 tool
- 우리나라에서도 CV, AI, 보안 연구자들의 연구가 이루어지고 있다.
방어 방법
- Adversarial Training
- Adversarial example을 포함해서 훈련하여 오인식되는 것을 방지하는 방법
- 얼마나 많은 적대적 example이 있는지 모르기 때문에 궁극적인 해결방안이 될 수 없다.
- 테스트 과정에서 adversarial example이 존재할 때 어떻게하면 모델을 일반화하여 적용하고 모델을 향상시킬 것인가에 대한 연구 - 자율성장 인공지능
- Defensive distillation
- 훈련을 통해 모델의 decision hypothesis를 부드럽게 만들어 한쪽 방향으로 너무 치우치지 않게 조절한다.
윤리적 인공지능
트롤리 딜레마
원칙과 효율성에 대한 딜레마
ex) 자율주행 자동차 브레이크 고장
- 브레이크 고장 시 노인을 구할 것인가 초등학생을 구할 것인가
- 이는 도덕적 표현에서 그치지 않고 알고리즘화 되어 컴퓨터로 표현할 수 있어야 한다.
- 지역, 종교 등에 따라 윤리적 관점이 다르기 때문에 표준을 정할 수 없다.
- 사회를 구성하는 모든 사람이 동의하는 수준에서 인공지능 기술이 들어와야 한다.
다양한 인공지능 윤리 사례
- 인공, 적성, 성격, 성별, 나이, 가정형편 등을 기초로 하는 인공지능 기술이 사회적 윤리에 맞지 않는 결과를 내놓은 사례가 발생하면서 인공지능이 불평들을 초래할 수 있다.
- 흑인이 온도계를 들고 있는 이미지를 총을 든 범죄자로 해석
- 똑같은 사진에서 흑인의 팔을 흰색으로 바꾸면 온도계를 들 일반인으로 해석
- 흑인이 범죄자가 많다는 인식이 인공지능 판단에 반영
- 구글 인공지능 윤리학자 해고
- 구글의 인공지능 시스템 언어는 차별적인 결과를 낳을 잠재성이 있다.
- 대형 인공지능 모델 훈련은 많은 전력 소비가 필요하고 성능에 비해 기후 변화에 영향을 미친다.
- User Centric AI - 개인 맞춤형 AI
- 대용량의 서버에서 학습 후 단말기에 제공하는 과정에서 적대적 공격이나 해킹이 발생할 수 있다.
- Edge AI: 제한된 환경에서 학습과 테스트하기 때문에 모델이 복잡하면 안 된다.
- On Device AI와 같이 HW의 발전이 더 필요해졌다.
윤리적 인공지능의 필요성
- 인공지능이 인간 생활에 밀접하게 적용되는 과정에서 예상하지 못한 다양한 윤리적 문제가 발생한다.
- 인공지능의 특성상 사람이 완벽하게 메커니즘을 이해하거나 검증할 수 없다.
- 데이터 편향으로 인한 프라이버시 침해, 공정성과 차별, 투명성, 설명 가능성, 책임성
- 데이터를 소유하고 통제하는 주체들에 의해 데이터를 제공하는 개인의 정보가 과도하게 원치 않는 목적에 활용되거나 식별될 수 있다.
- 소수의 그룹에 의하여 독점될 수 있다.

Hi, there 👋