Why Backpropagation
Neural Network는 Layer 여러 개로 이루어져 있기 때문에 일반적인 Gradient descent와는 다르다.
- 중첩된 Layer가 아닐 때 wt+1:=wt−lr∂w∂Loss
- Neural Network는 파라미터화 된 function의 sequence이다.
x→θ1→output1→θ2→output2→linear→⋯
- Parameters는 loss를 최소화해야 한다.
θminN1i=1∑NL(h(xi;θ)),yi)
- 이때 h(xi;θ)는 Neural network를 의미한다.
- Gradient descent를 통한 최소화는 gradient를 계산해야 한다.
θ(t+1)=θ(t)−λN1i=1∑N∇L(h(xi;θ),yi) z=h(x;θ) ∇L(h(xi;θ),yi)=∂z∂L(z,y)∂θ∂z
- ∂θ∂z는 해당 z에 미치는 θ의 영향을 의미한다.
- Backpropagation: ∂θ∂z를 계산하는 방법
Backpropagation이 있어야 Neural network 학습이 가능하다.
The Gradient of Neural Network
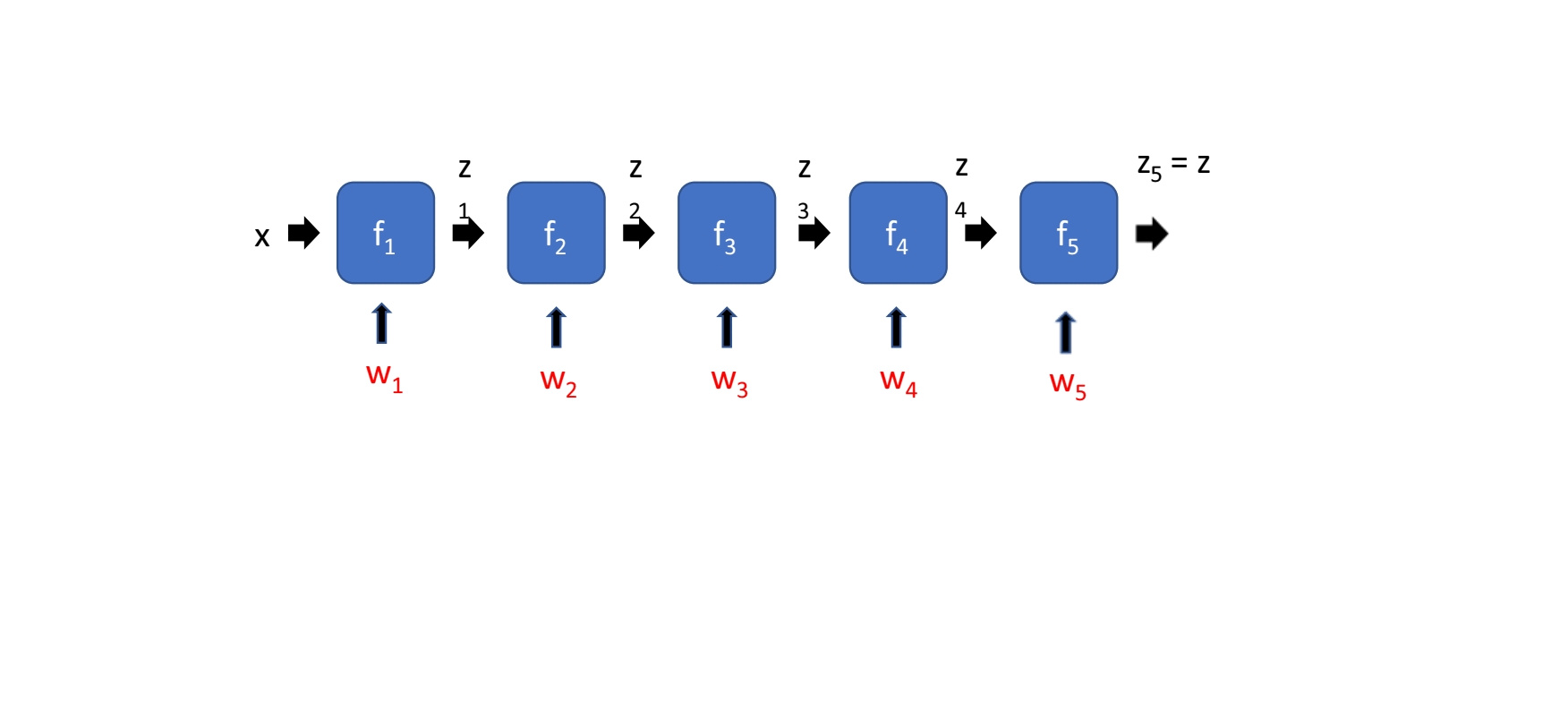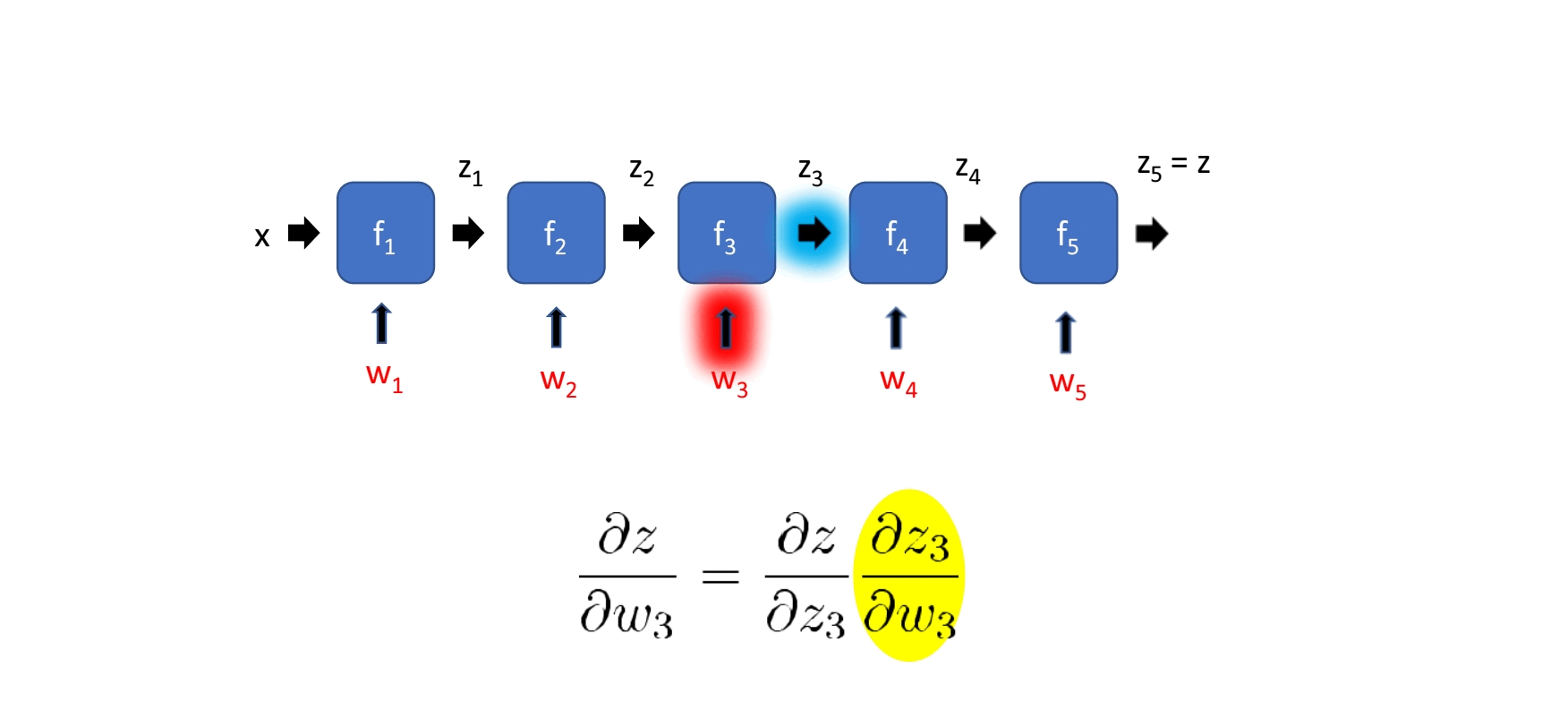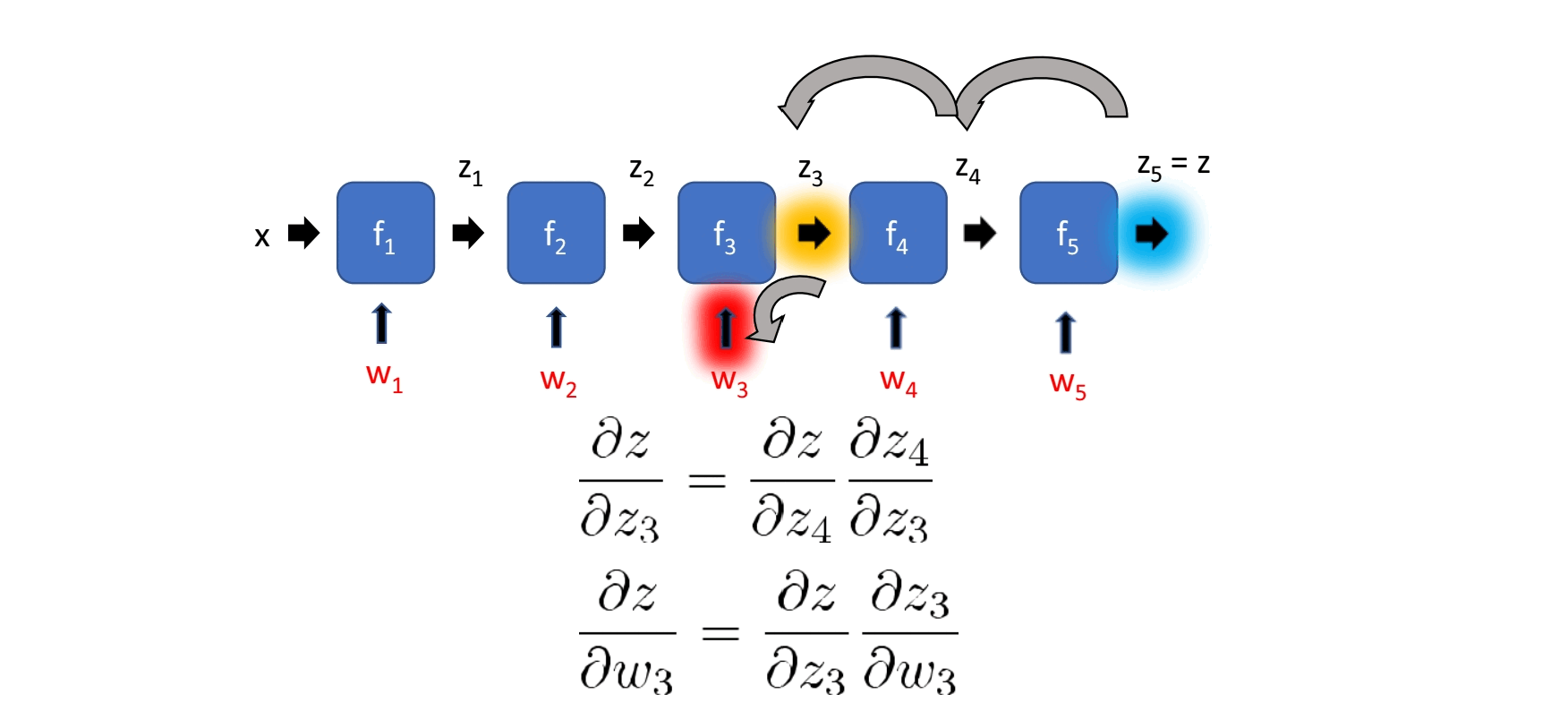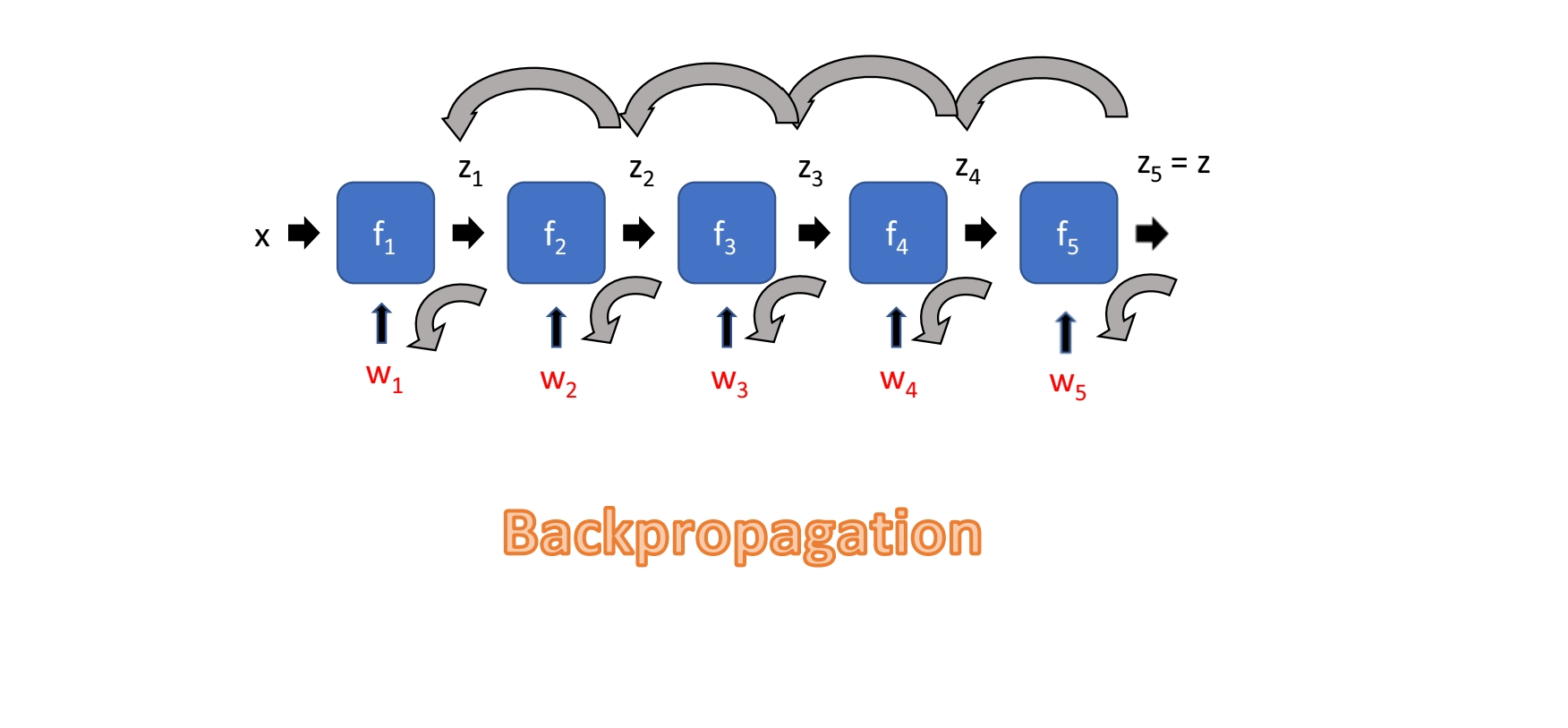
Input x에 가까워질수록 계산량이 많아진다.
- 대부분 1 이하의 값이기 때문에 update해도 큰 변화가 없다.
Backpropagation for a Sequence of Functions
zi=fi(zi−1,wi)z0=xz=zn
- 각 Function을 미분할 수 있다고 가정
∂zi−1∂zi=∂zi−1∂fi(zi−1,wi) ∂wi∂zi=∂wi∂fi(zi−1,wi
- z의 gradient를 저장하기 위해 g(zi), wi의 gradient를 저장하기 위해 g(wi)를 사용한다.
g(zn)=∂zn∂z=1 g(zi−1)=∂zi∂z∂zi−1∂zi=g(zi)∂zi−1∂zi
- Parameter의 Gradient를 계산하기 위해 g(zi)를 사용한다.
g(wi)=∂zi∂z∂wi∂zi=g(zi)∂wi∂zi
Loss as a Function
Training of Nerual Network
- Sample Image and Label
- Forward: Image는 Network를 거쳐 Loss를 계산한다.
- Backward: Gradients를 계산하기 위해 Backpropagetion
- Weights를 업데이트하기 위해 Gradient 반대 방향으로 이동한다.
Computation Graphs
- 중간 output과 parameter 간의 구분 없는 임의의 예시 그래프
- 각 node에서는 두 개의 funeciot이 동작한다.
- Forward: 주어진 input에서 output을 계산한다.
- Backward: 출력에 대한 z의 도함수가 주어지면 입력에 대한 z의 도함수를 계산한다.
- 입력 a,b,c에 대한 함수 fi의 출력이 d일 때 Backward
∂d∂z→[∂a∂z,∂b∂z,∂c∂z]
Feed-Forward Networks
Network를 통해 Prediction으로 feed forward 되어 Classification이 이루어진다.
- ex) P 차원 데이터
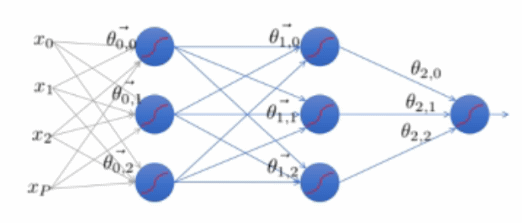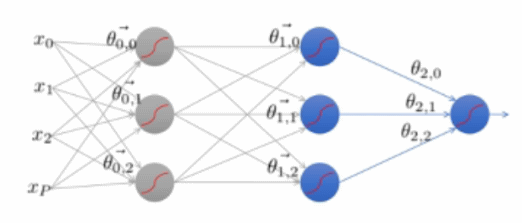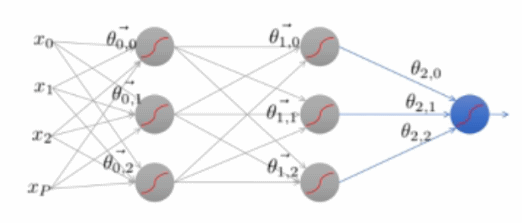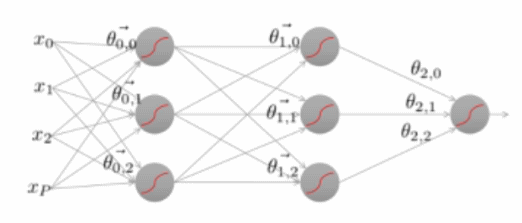
Error Backpropagation
Network 전체에서 Gradient descent 수행 과정
- Training은 마지막 레이어에서 첫번째 레이어 순서로 진행된다.
- 각 layer의 파라미터를 재정의한다.
θ={wij,wjk,wkl}
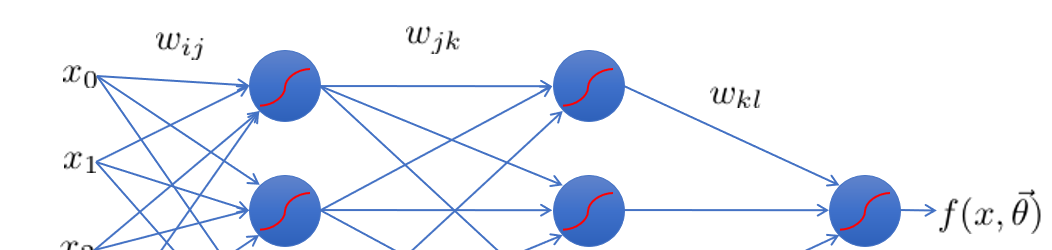
- 각 node의 입력과 출력을 구분한다.
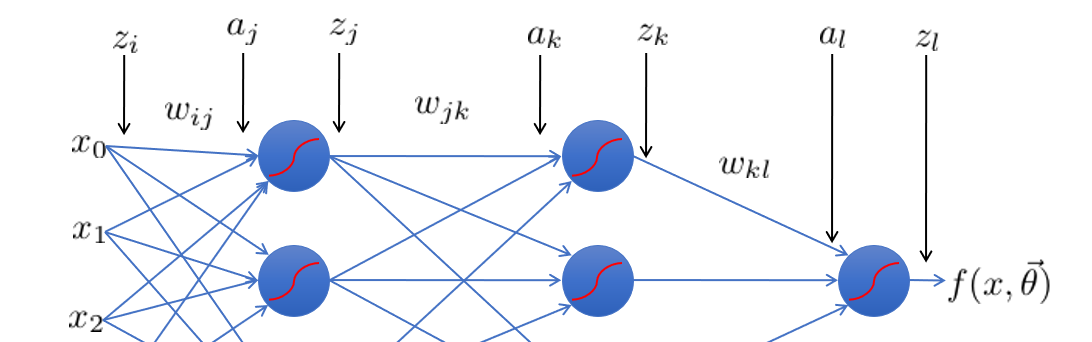
- zt는 각 layer의 연산 결과에 non-linear activateion function을 적용한 결과이다.
G(aj)=zj
-
Linear Combination
aj=i∑Pwijziak=j∑wjkzjal=l∑wklzkzj=g(aj)zk=g(ak)zl=g(al)
-
실제 값과 예측 값의 차이 계산 - Empirical Risk Function
R(θ)=N1n=0∑NL(yn−f(xn))=N1n=0∑N21(yn−f(xn))
R(θ)=N1n=0∑N21(yn−g(k∑wklg(j∑wjkg(i∑wijxn,i))))2
-
마지막 layer의 weight 최적화
N은 데이터의 수를 의미하며, 모든 데이터를 활용하여 gradient를 계산해야 한다.
- Calculus chain rule
∂wkl∂R=N1n∑[∂al,n∂Ln][∂wkl∂al,n] 가중치 w는 데이터의 수와 무관하기 때문에 n index가 없다.
- 함수 전개
∂wkl∂R=N1n∑[∂al,n∂21(yn−g(al,n))2][∂wkl∂zk,nwkl]
- 미분 계산
∂wkl∂R=N1n∑[−(yn−zl,n)g′(al,n)]zk,n
- 식 요약
∂wkl∂R=N1n∑δl,nzk,n
-
마지막 hidden layer의 weight 최적화
- Calculus chain rule
∂wjk∂R=N1n∑[∂ak,n∂Ln][∂wjk∂ak,n]
- Multivariate Chain rule
∂wjk∂R=N1n∑[l∑∂al,n∂Ln∂ak,n∂al,n][∂wjk∂ak,n]
- 치환
∂wjk∂R=N1n∑[l∑δl∂ak,n∂al,n][zj,n]
- 미분 계산
∂wjk∂R=N1n∑[l∑δlwklg′(ak,n)][zj,n]
- 식 요약
∂wjk∂R=N1n∑[δk,n][zj,n]
-
남은 이전 layers에 대해 반복한다.
∂wij∂R=N1n∑[δj,n][zi,n]
-
각 parameter에 대해 gradient를 계산했으므로 parameter를 업데이트 한다.
wijt+1=wijt−ηwij∂Rwjkt+1=wjkt−ηwjk∂Rwklt+1=wklt−ηwkl∂R
Summary
- Error backprop은 Multivariate Chain을 해결하고 각 구성요소에 대한 gradient를 개별적으로 해결한다.
- 각 layer의 target values는 다음 layer에서 부터 온다.
- Error backprop은 network에서 뒤로 error를 전달한다.
