Image Classification
Image classification은 visual 관련 task 중 가장 단순한 task로, 주어진 이미지가 강아지 사진인지, 고양이 사진인지 label을 예측하는 것이다. 하지만 컴퓨터는 이미지를 숫자로 다루기 때문에 challenge가 존재한다.
Semantic Gap의 문제
일반적으로 이미지는 크기의 3차원 tensor이며, 각 픽셀은 사이의 정수로 표현된다. 가지의 정수와 고차원 의미 간의 간극이 존재한다.
동일한 개체에 대한 사진이더라도 각도, 조명, 배경에 따라 픽셀은 완전히 다르게 나타난다.
Data-Driven Approach
분류기를 학습할 때 다음과 같은 pipeline을 따라 진행된다.
- (Image, Labels) 데이터셋을 수집한다.
- 분류기를 학습하기 위해 머신러닝을 사용한다.
- 테스트 이미지를 이용하여 분류기를 평가한다.
가장 흔히 사용되는 분류기로는 Nearest Neighbor Classifier, Linear Classifier가 있다.
Nearest Neighbor Classifier
- Train & Test
- Train: 학습을 위한 이미지를 저장한다. 이외의 별도의 학습 과정은 없다.
학습의 복잡도는 로, 매우 효율적이다. 하지만 분류기에서 중요한 것은 test의 속도이므로 훈련 시간이 긴 것은 문제되지 않는다. - Test: Train set에서 가장 유사한 image의 label로 예측한다.
모든 test sample과 전부 비교해야 하므로 복잡도는 이며 훈련 과정에 비해 매우 오래 걸리며 비효율적이다. - NN 방식은 훈련 데이터를 저장하고, 가장 가까운 예시를 기반으로 예측하는 분류기이다.
- Train: 학습을 위한 이미지를 저장한다. 이외의 별도의 학습 과정은 없다.
- 거리 측정 방식
유사도 측정 방식 L1 distance, L2 distance 두 가지를 가장 흔히 사용한다. 유사도 측정 방식은 정확도에 큰 영향을 주는 hyper-parameter이다. Hyper-parameter는 학습해야 하는 것이 아닌 찾아야 하는 알고리즘과 관련된 것을 의미한다.- L1(Manhattan) Distance:
같은 위치에 있는 픽셀 값의 차이를 합하여 유사도로 사용한다. 다를수록 차이가 커지므로 값이 작을수록 두 이미지 과 는 유사하다. - L2(Euclidean) Distance:
- L1(Manhattan) Distance:
k-Nearest Neighbor Classifier
k-Nearest Neighbor 알고리즘은 데이터 포인트 주변의 개 이웃을 기준으로 다수결 투표를 통해 label을 예측하는 방식이다. 이때 값의 선택에 따라 분류기의 성능과 decision boundary가 크게 달라질 수 있다.
- Decision Boundary의 변화: NN vs k-NN
인 NN일 경우에는 decision boundary가 매우 불규칙하며, 훈련 데이터 하나하나에 매우 민감하게 반응하는 overffing 상태(unstable decision boundary)와 같다. 반면, 일 경우에는 보다 부드러운 경계(smooth decision boundary)가 형성되어 노이즈에도 더 안정적으로 대응할 수 있다.
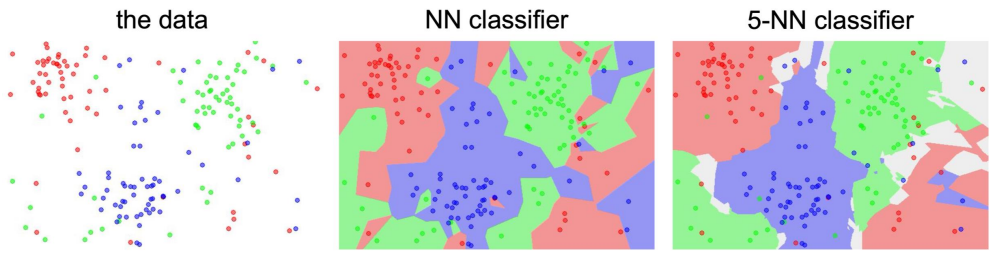
- 훈련 데이터에 대한 정확도
인 NN-Classifier는 각 train sample을 분류할 때, 자기 자신을 가장 가까운 이웃으로 선택하게 된다. 따라서 training accuracy는 100%이다. 반면, test accuracy는 매우 저조하다. 이는 훈련 데이터에 대해 overfitting이 발생한다는 의미이기도 한다.
인 경우에 training accuracy는 낮은 반면 test accuracy는 높다. 최적의 는 validation set을 통해 찾는 것이 중요하다.
Finding Hyper-parameters
k-NN 알고리즘에서 값이나 거리 측정 방식은 모델이 직접 학습하는 값이 아니라, 사용자가 미리 정해줘야 하는 값, 즉 Hyper-parameter이다. 값을 결정하기 위해 검증용 데이터를 활용해서 실험적으로 찾아야 한다.
- 단순히 데이터를 훈련/검증/테스트로 나누는 것도 좋지만, 데이터가 적을 경우 이렇게 나누면 검증용 데이터가 부족해질 수 있다. 이럴 때 사용하는 것이 k-Fold Cross Validation이다.
- 가지고 있는 데이터를 5개의 동일한 크기의 조각(fold)으로 나눈다고 가정해보면, 1개는 검증용, 나머지는 학습용으로 사용한다. 이 과정을 총 5번 반복하면서, 매번 다른 fold를 검증용으로 설정한다.
- 각 반복에서 얻은 정확도를 평균 내서 하이퍼파라미터별 평가 점수로 사용한다.
- 이 과정을 거치면 최적의 를 선택할 수 있게 된다.
Curse of Dimensionality
k-NN 분류기를 사용할 때, 이미지 간의 거리를 계산할 기준으로 픽셀 값 자체를 쓰지는 않는다. 같은 개체여도 픽셀 단위에서 약간씩만 달라도, 실제로는 전혀 다른 이미지이고, 이런 작은 차이가 거리 계산에서 큰 영향을 미치기 때문이다. 즉, 픽셀 거리만으로는 유의미한 유사도를 측정하기 어렵다.
1차원 데이터의 경우 필요한 포인트 수가 라면, 2차원의 경우 , 3차원이면 개의 포인트가 필요하다. 이처럼 차원이 높아질수록 불필요한 정보도 포함되어 유의미한 정보를 찾는 게 더 어려워진다.
이러한 이유로, 대부분의 이미지 분류 문제에서는 feature extraction을 먼저 수행한 다음에 k-NN을 적용하거나, 아예 딥러닝 기반의 분류 모델을 사용하게 된다.
Linear Classifier
Linear Layer는 보통 Deep Neural Networks의 가장 마지막에 MLP head, Fully Connected Layer와 같은 이름으로 존재한다.
Parametric Approach
입력된 이미지 의 크기가 일 때, 3072개의 픽셀 값들은 사이의 실수로 표현된다.
분류기의 parameter가 로 표현된다면, 분류기는 다음과 같이 표현할 수 있다.
- 학습해야 하는 parameters: 총 30730개
Linear Classifier의 기하학적 해석
이미지는 단순 픽셀 배열처럼 보일 수 있지만, 컴퓨터는 이를 하나의 코차원 벡터로 이해한다. 예를 들어 크기의 컬러 이미지는 총 3072 차원의 벡터 공간에 존재하게 된다.
이런 고차원 공간에서, Linear Classifier는 각 클래스를 hyperplane을 기준으로 나누어 분류한다. 이 평면의 방향과 위치는 학습된 가중치 에 의해 결정된다.
Linear Classifier는 각 클래스마다 decision boundary를 가진다. 각 선은 클래스의 분류기이며, 이 선을 기준으로 어느 쪽에 위치하는지에 따라 해당 클래스인지 판별한다.
- Linear Classifier는 복잡한 비선형 경계를 표현하지 못하므로, 모든 경우에 효과적이지는 않다. 하지만 빠르고 해석이 쉽다는 장점이 있다.
Loss Function
Loss Function은 현재 분류기가 얼마나 낮은 성능을 보이는지 숫자로 표현하는 함수이다.
세 가지 클래스, 세 가지 샘플이 있을 때 손실 함수를 계산하는 과정은 다음과 같다.
- Multiclass SVM loss

- 정답 클래스는 최댓값으로 예측해야 한다. 고양이 이미지의 경우 cat에 해당하는 점수가, 자동차 이미지의 경우 car에 해당하는 점수가 가장 커야 한다. 고양이 이미지이면 car, frog에 대한 점수는 낮을수록 좋다.
- 고양이 이미지:
- 자동차 이미지:
- 개구리 이미지:
- 정답 클래스의 점수가 다른 클래스의 점수보다 1 이상 크면 손실은 0이다.
- 반대로, 정답 클래스의 점수가 다른 클래스의 점수보다 낮다면 두 점수의 차이에 1을 더한 값이 손실이 된다.
- 즉, 손실이 없기 위해서는 GT 값이 다른 클래스의 점수보다 1 이상 커야한다.
- 손실함수 해석
- 를 포함하게 되면 값은 무조건 1이 된다. 상수로 고정된 값은 무의미하므로 summation 계산 시 인 경우는 제외한다.
- 자동차 이미지에서 car 예측 점수가 0.5만큼 감소했을 때 으로 동일하다. 자동차 이미지에서 car 예측 점수가 0.5로 감소했을 때 으로 증가한다.
- SVM loss의 최솟값은 0, 최댓값은 이다.
- 개의 샘플과 개의 클래스가 있을 때 Parameter 가 0에 매우 가깝게 초기화 되었다면, 모든 예측값들은 0에 수렴한다.
- Softmax Classifier(Multinomial Logistic Regression)
- 계산된 점수들은 각 클래스에 대해 probabilities를 의미한다. (모든 확률의 합은 1, 모든 확률값은 Non-negative)
- 주어진 이미지 에 대해 클래스 일 확률은
- Log likelihood 최대화를 거쳐 정답인 클래스에 대해 확률값이 가장 커지게 학습해야 한다.
- KL Divergence는 두 확률 분포 간의 차이를 수치적으로 나타내는 방법이다. 실제 정답 분포(정답 라벨의 one-hot 벡터)가 이고 모델이 예측한 분포(softmax 값)가 일 때 다음과 같이 표현된다.이 값이 작을수록 모델의 예측이 실제 분포에 가깝다는 뜻이다.
전개하면 entropy(상수)에서 cross entropy를 뺄셈하는 것과 같다. 따라서 을 최소화하기 위해서 CE 값을 최소화하면 된다. - 고양이 이미지에 대해 Loss 계산 과정은 다음과 같다.
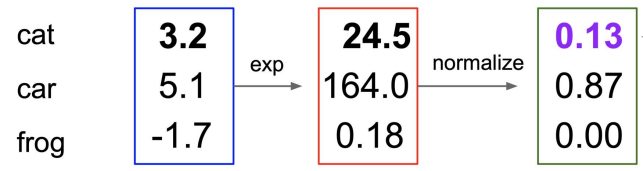
계산된 probabilities는 이고 cat 클래스에 대해 loss를 계산하면 이다. - 손실함수 해석
- Softmax loss의 최솟값은 0, 최댓값은 이다.
- 개의 클래스가 있을 때 Parameter가 모두 비슷하게 초기화되어 있다면, 모든 예측값 이므로 이다.
- Softmax loss의 최솟값은 0, 최댓값은 이다.
- 동일한 linear classifier에서 SVM vs Softmax
SVM은 Softmax에서 를 적용하기 전 logit 값을 이용해서 loss를 계산한다.
Weight Regularization
Overfitting을 막기 위해서 regularization을 해주어야 한다.
Loss function은 Data loss와 Regularization term으로 구성된다.
Overfitting
Train accuracy에 지나치게 과적합되어 train accuracy는 매우 높지만, test accuracy가 낮은 현상을 말한다. Overfitting 현상은 모델을 단순하게 만들어서 해결할 수 있다.
가장 흔히 사용되는 정규화 기법으로는 L1 regularization, L2 regularization, Elastic net이 있다.
- L1 regularization
- L1은 가중치를 희소하게 만드는 성질이 있다. 많은 가중치를 0으로 만들게 된다.
- L2 regularization
- 모든 가중치 요소들의 제곱 합이 작을수록 정규화 손실도 작아진다. 다시 말해, L2는 가중치를 여러 항목에 고르게 분산시키는 역할을 한다. 하나의 가중치 값만 지나치게 커지는 것을 방지하고 더 안정적인 학습을 유도한다. Outlier를 완화하고 싶다면 L2 regularization이 적절하다.
- Elastic net
More complex
Dropout, Betch normalization, Stochastic depth 등의 방법을 통해 정규화를 적용할 수 있다.
