Attention
-
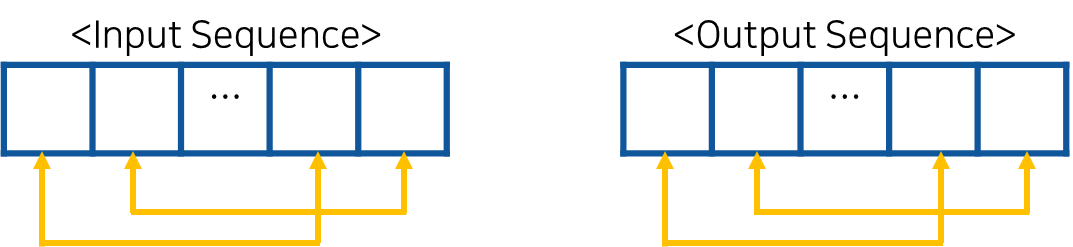
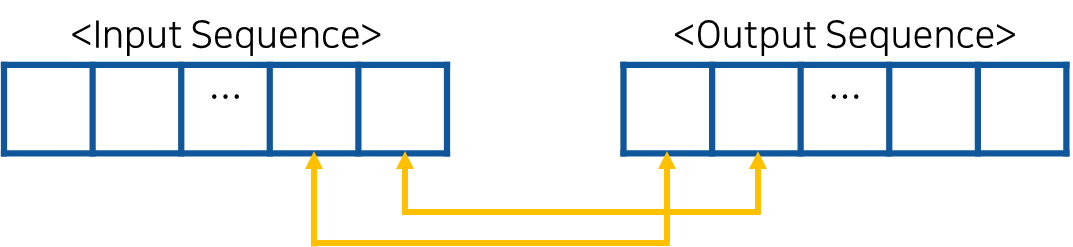
Transformer 이전에, Seq2Seq 모델에서도 Attention 자체는 사용되었다. 다만 Seq2Seq에서는 Self-Attention이 아닌 Attention을 이용해서 입력-출력 간 대응되는 단어의 관계를 파악한다. 이를 통해서 각 출력이 어떤 입력 정보를 참고했는지 알 수 있다.
-
이와 달리 Transformer에 사용된 Self-Attention은 입력과 출력 각 Sequence 내부 값 간의 대응 관계를 파악하기 위해 사용된다.
- RNN 기반의 Seq2Seq 모델은 Long term dependency를 학습하기 어렵다는 점, 순차적인 연산을 해야하기 때문에 학습이 느리다는 점, 시퀀스를 모두 입력 받은 후에 Decoding이 가능하기 때문에 병렬 연산이 불가능하다는 점 등의 단점이 있다. Transformer는 이러한 단점을 해결하기 위해 RNN을 사용하지 않고 오직 Attention mechanism만으로 입력과 출력 간 의존성을 모델링한다.
Self-Attention의 장점
Recurrent layer, Convoltuional layer와 비교했을 때 Self-Attention layer는 연산 복잡도가 작아서 연산 속도가 빠르다.
이는 문장 길이가 , 입력 단어를 표현하는 벡터 차원이 일 때 인 경우가 많기 때문이다.

위의 표에서 Self-Attention restricted는 문장의 길이가 매우 길 경우 Attention을 적용하는 neighborhood size 을 정해주는 것이다.
Transformer에서 Self-Attention
Transformer에는 총 세 가지의 Attention이 있다.
이해를 위해 Encoder 내에서 진행되는 Self-Attention을 기반으로 Attention score를 계산해 보기로 한다.
본 포스팅에서는 Transformer가 아닌 Transformer에서의 Self-Attention을 집중적으로 다룬다.
Encoder Self-Attention
가장 먼저, 입력으로 들어온 차원의 단어(토큰) 벡터들을 차원으로 선형 변환한다.
이후 Attention을 계산하기 위해 선형 변환된 단어 벡터들의 모음인 행렬을 만든다. 로, 동일한 시퀀스 내에 있는 단어들 간의 관계를 계산하기 위해 사용된다.
아래 그림은 "The weather is very nice today" 문장을 임베딩한 후 Attention을 계산하는 모습이며, 특히 "today"가 "nice"와 얼마나 관련이 있는지 구하는(query) 과정이다.
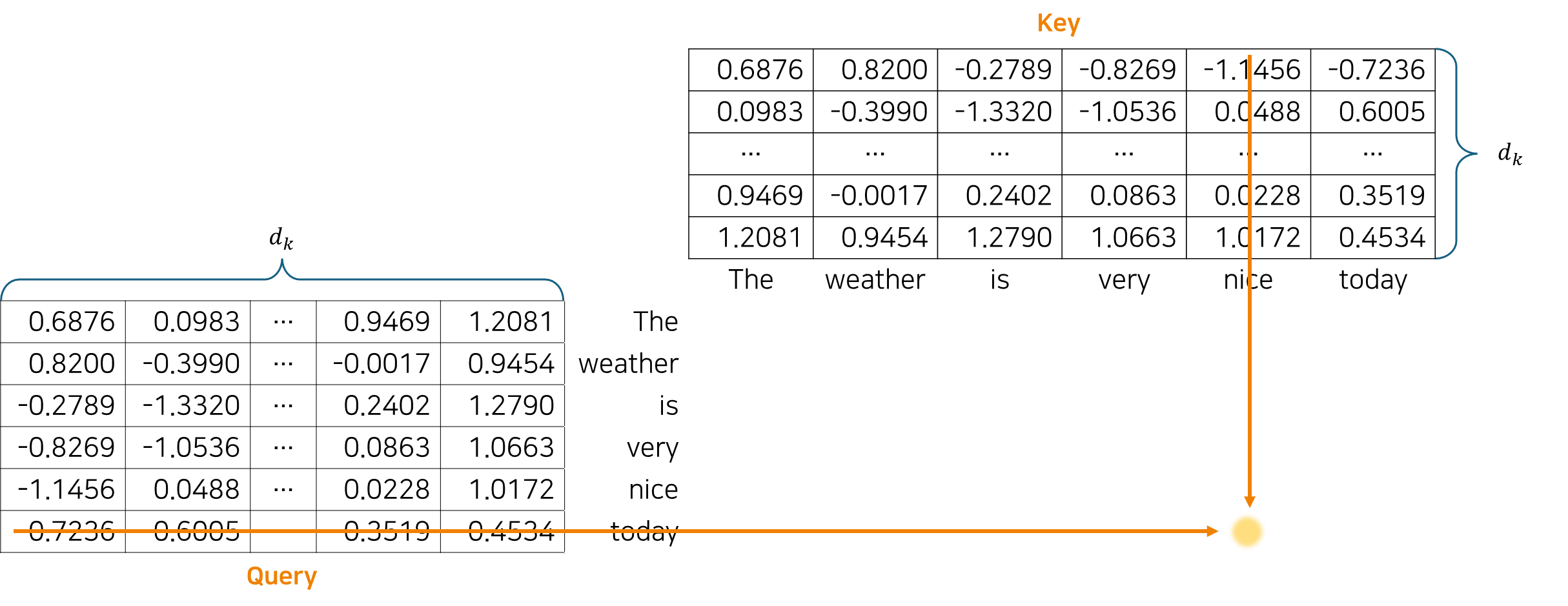
Query의 각 행(그 단어를 나타내는 벡터), Key의 각 행(그 단어를 나타내는 벡터)을 내적하여 Attention score를 계산하기 시작한다. 계산할 때에는 벡터 별로 연산하는 것이 아닌 와 를 곱하여 계산한다. 이때 additive attention이 아닌 dot-product(multiplicative) attetion을 계산하는 이유는 최적화된 행렬 곱셈 코드를 사용하여 구현하면 더 빠르고 공간 효율적이기 때문이다.
와 를 곱하여 나온 행렬 은 각 단어(토큰) 간의 연관성을 측정하는 행렬로, 한 단어가 다른 단어에 얼마나 주의를 기울여야 하는지, 즉 얼마나 Attention 해야 하는지 결정하는 기준이 된다.
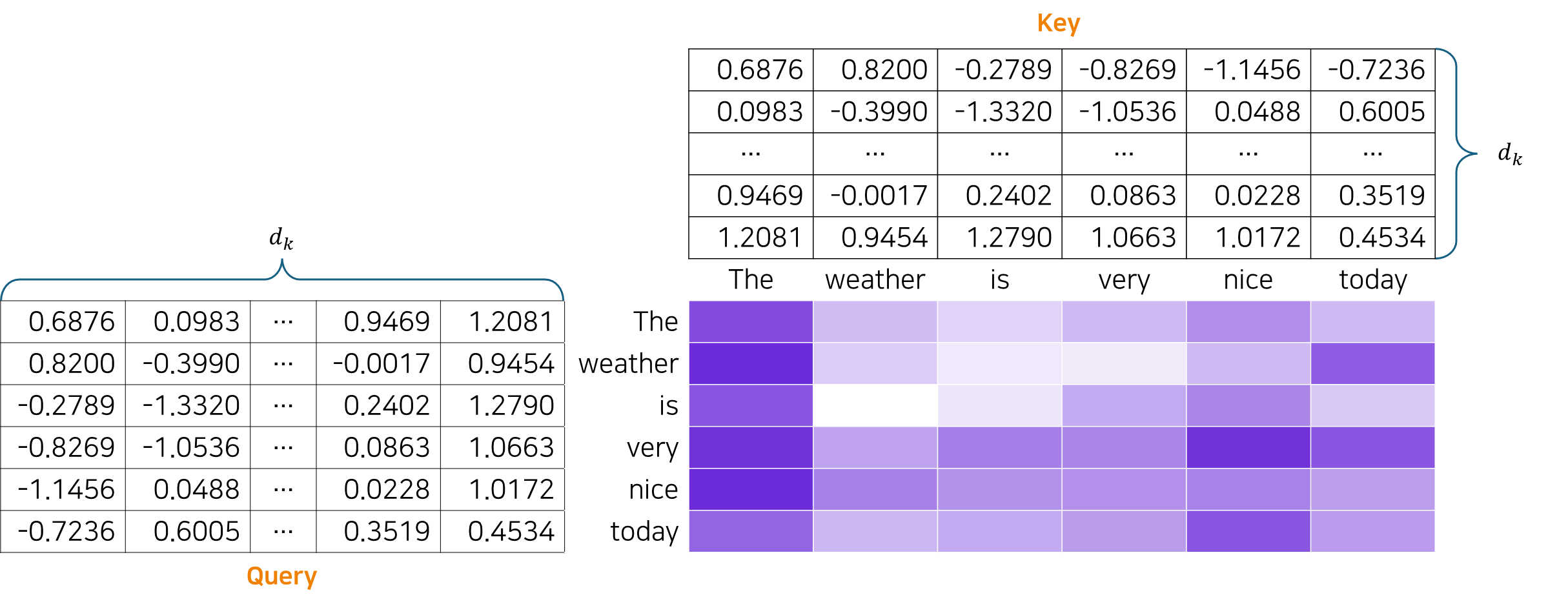
연관성을 나타내는 행렬에 Softmax를 적용하면 각 단어가 다른 단어와 얼마나 중요한지 나타내는 확률 값이 된다.
지금까지 정리하면 가장 처음 문장을 입력받아 임베딩한 후 차원으로 변환하여 내적을 계산하고 Softmax를 적용했다. 그런데 만약 가 매우 크다면 내적한 값이 또는으로 발산하고, softmax를 적용했을 때 0이나 1로 수렴하지 않을까?
이 문제를 해결하기 위해 Softmax 함수에 넣기 전에 scaling을 해주어야 한다.
벡터 와 의 평균이 0이고 분산이 1인 정귝 분포를 따른다고 할 때 의 평균은 0, 분산은 이다. 따라서 표준편차를 일정하게 유지하려면 로 나누는 게 적절하다.

출처: https://www.tensorflow.org/text/tutorials/transformer?hl=ko
이제 이 확률 값을 초기에 단어들을 나타내던 벡터들의 모음에 곱하면 된다. 이때 사용되는 것이 행렬이다.
- Query: 지금 집중해야 할 단어가 무엇인지 Key에게 하나씩 물어본다.
- Key: 지금 가지고 있는 정보가 Query에 얼마나 도움이 될지 판단한다.
- Value: 계산된 점수를 기반으로 최종적으로 전달할 정보를 조절하여 Attention Score가 결정된다.
그렇다면 Multi-Head란 무엇일까.
Attention을 거치면 Context Vector가 도출된다. 이때 Head가 여러 개라면 명사에 집중한 Context Vector, 형용사에 집중한 Context Vector, 사람에 집중한 Context Vector, 행위에 집중한 Context Vector 등 다양한 맥락을 파악할 수 있다.
본 논문에서는 로 설정한다. 이를 통해 초기에 차원이었던 단어 벡터를 단일 Head로 연산하는 것과 동일한 연산량으로 8가지의 맥락을 파악할 수 있다.
Decoder Masked Self-Attention
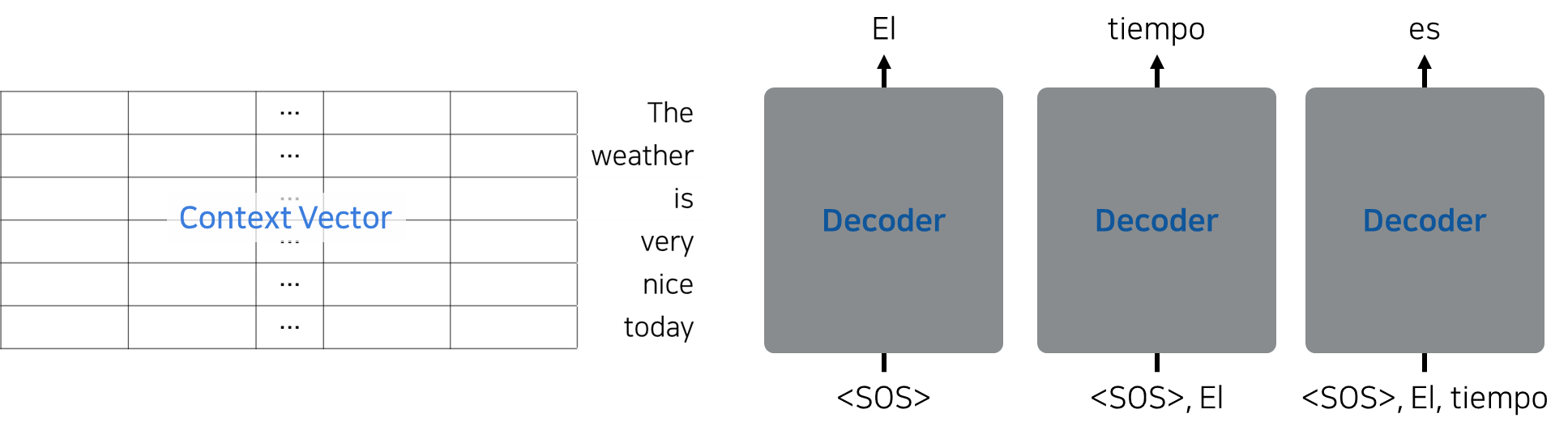
위의 그림처럼, Transformer의 Decoder에서는 다음에 이어질 단어의 예측이 연속적으로 이루어진다.
따라서 번째 단어까지 예측을 완료하고 번째 단어를 예측할 때 Decoder는 을 포함한 이후 단어와의 유사도, attention을 계산하면 안 된다.
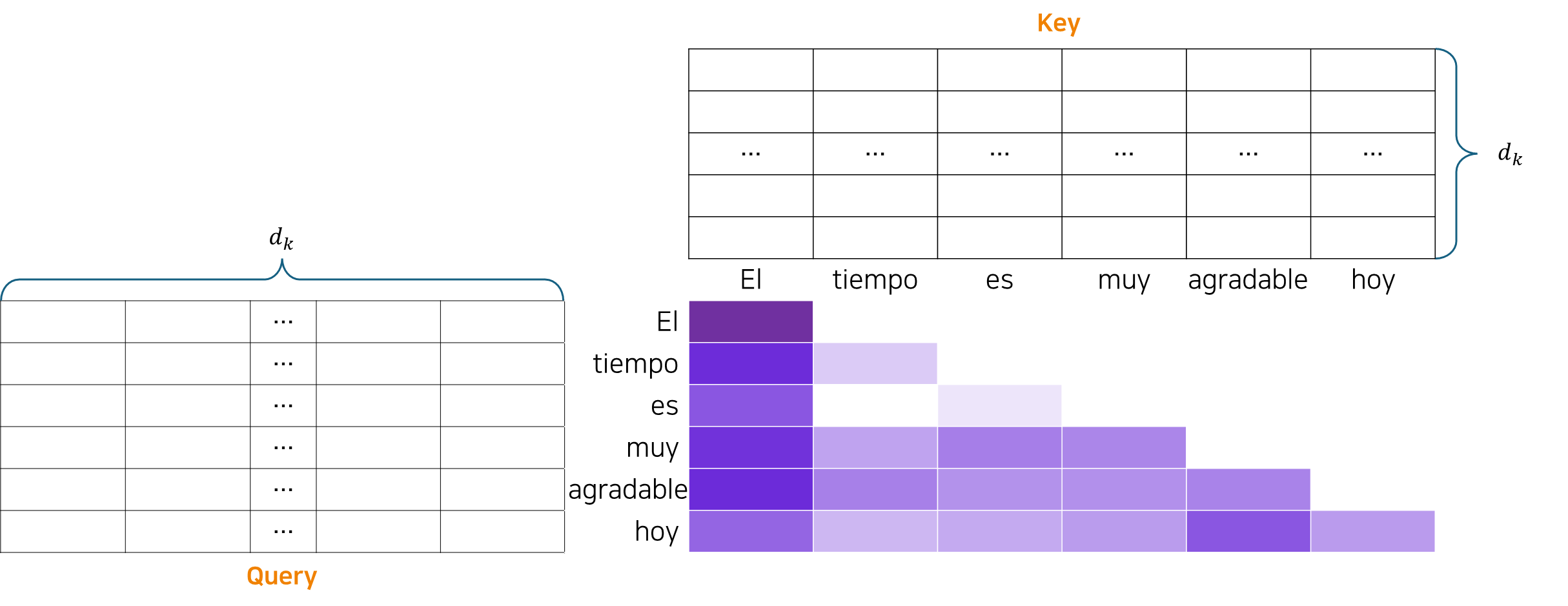
이를 위해 Mask를 적용해야 한다. 구체적인 방법은 대각행렬을 기준으로 오른쪽 위의 position에 를 곱하는 것이다. 그러면 위의 그림처럼 Softmax 함수 적용 시에 0(흰색 cell)이 된다.
- Query: 지금까지 본 단어들 중에서 어느 단어에 집중해야 하는지 Key에 묻는다.
Encoder-Decoder Attention
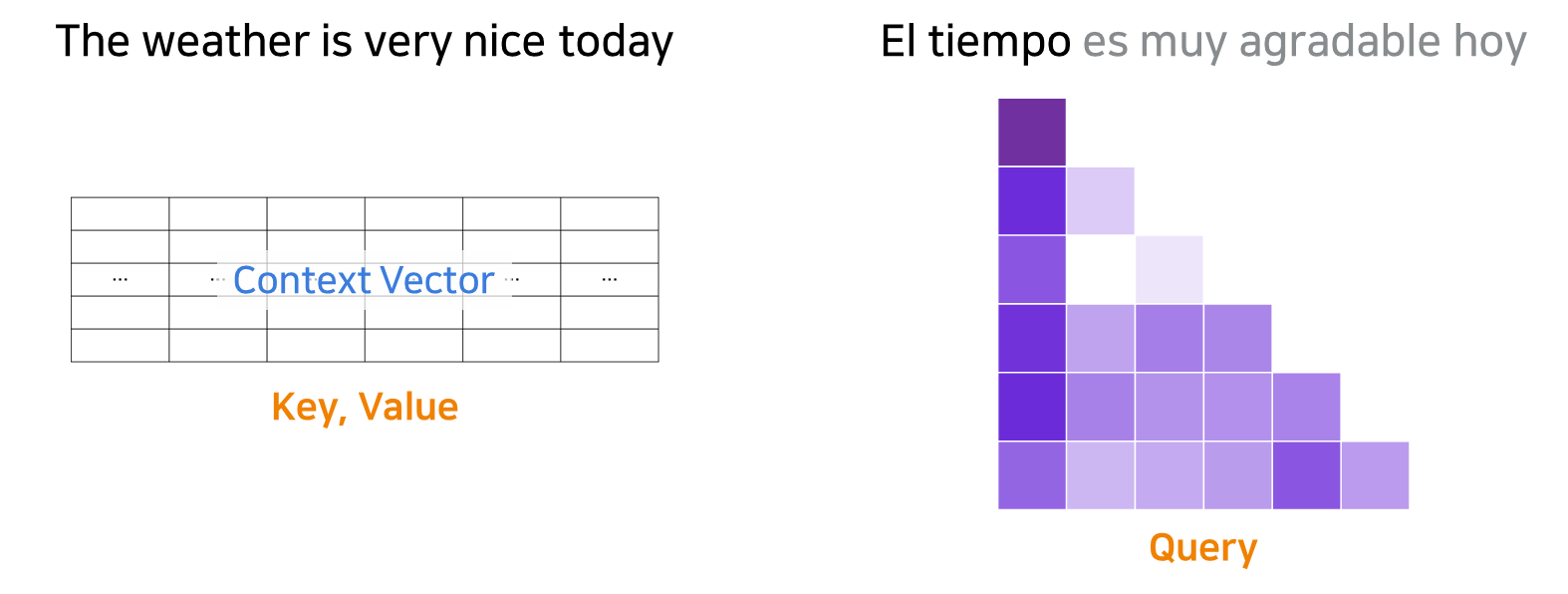
가장 처음 입력된 문장은 Encoder를 통해 Context Vector로 고정되었고, Decoder에서 한 단어씩 예측할 때마다 Attention을 거친다. 이는 앞에서 구한 맥락을 기반으로 다음에 나올 단어를 결정하는 과정이다.
- Query: 현재까지 예측한 단어가 원래 문장의 어느 부분에 집중해야 하는지 Key에 묻는다.
