BART(Bidirectional Auto-Regressive Transformers)

BART란?
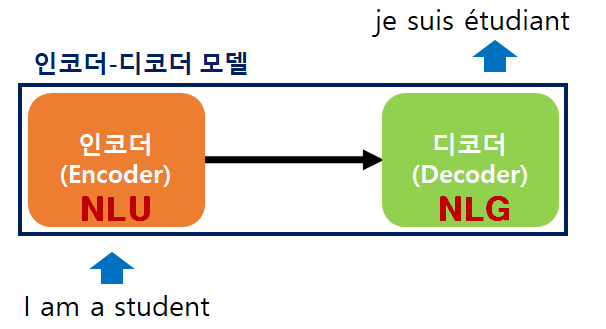
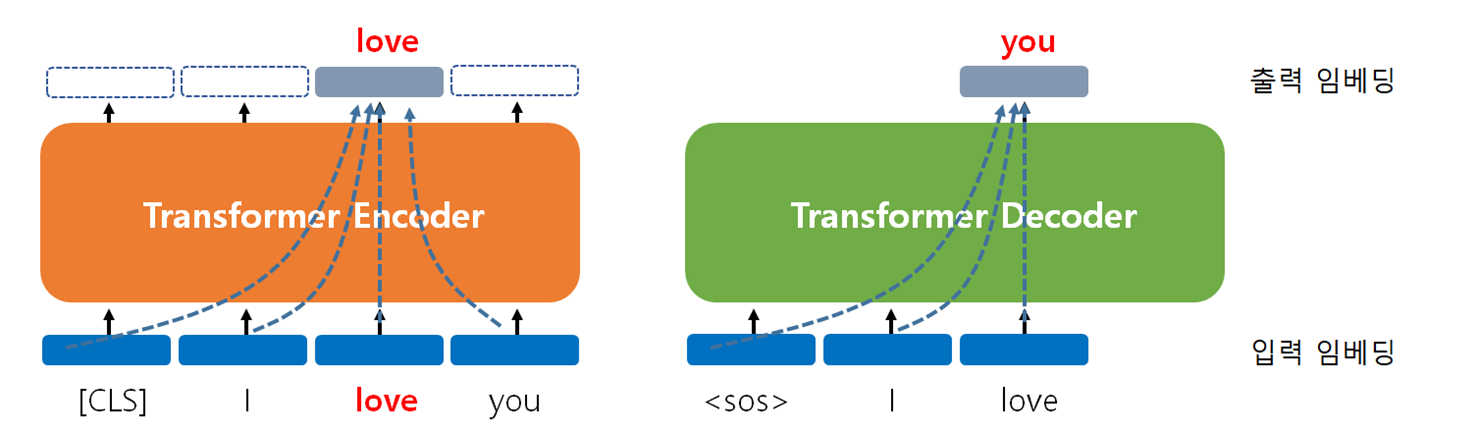
BART는 Bidirectional Auto-Regressive Transformers의 약자로 2020 페이스북 AI에서 발표한 모델이다. 인코더-디코더 구조를 가지며 자연어 이해 능력과 자연어 생성 능력을 가진 모델이다.
일반적으로 디코더 모델은 같은 크기의 인코더 모델에 비해 자연어 이해 문제에서 성능이 떨어진다.
하지만 BART는 인코더와 디코더를 둘 다 가지고 있어서 기계독해나 NLI 문제 같은 자연어 이해(Natural Language Understanding, NLU) 능력이 중요한 문제에서도 성능을 보여주었고,
요약, 챗봇, 번역과 같은 자연어 생성(Natural Language Generation, NLG) 문제에서도 같은 크기의 디코더 계열 모델 대비 뛰어난 성능을 보였다.
이는 인코더-디코더 구조의 모델에 적절한 사전학습을 진행한다면 생성 문제에서 성능 향상을 이루면서 자연어 이해 문제에 대한 성능을 떨어트리지 않을 수 있음에 의미를 둔다.
BART 사전 학습
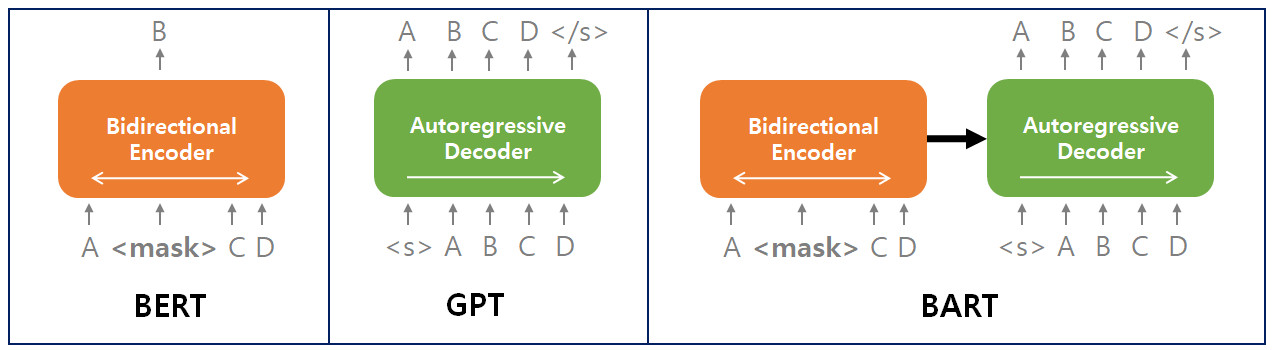
각 모델의 사전 학습 방법
- BERT : 양방향의 문맥을 반영하여 가려진 단어 맞추기
- GPT : 이전 단어들로부터 다음 단어 예측하기
- BART : 인코더에서 훼손된 문장을 디코더에서 복원하기
BART는 인코더-디코더 구조이기 때문에 인코더의 입력 문장과 디코더가 생성하는 문장의 길이가 서로 달라도 된다. 이 특징을 살려 총 5개의 사전 학습 방법을 사용한다.
- Token Masking
- Text Infilling
- Sentence Permutation
- Document Rotation
- Token Deletion
사전 학습 방법들은 기본적으로 인코더에 고의적으로 훼손된 문장을 넣고 디코더에서 원본 문장으로 복원하게 하는 방법으로 언어에 대한 이해를 높이는데에 초점을 맞춘다.
Token Masking
토큰 마스킹은 입력 문장에서 임의의 단어 하나를 마스킹하여 훼손시키고 디코더에서 원래 문장으로 예측 복원하도록 학습하는 방식이다.
인코더 입력과 디코더의 레이블
- 인코더 입력(변형된 문장):
"The children played <mask> outside until it got dark." - 디코더의 레이블(원본 문장):
"The children played soccer outside until it got dark."
기본적으로 트랜스포머 디코더는 한 단어씩 생성한다. <s>는 문장의 시작, </s>는 문장의 끝을 나타내는 신호이다.
학습 과정에서 단어를 한개씩 생성하며 중간에 마스킹된 단어도 예측한다. 마지막에는 문장 종료 토큰을 생성하며 문장이 완료되었음을 알린다.
| 단계 | 디코더 입력 | 디코더 레이블 | 비고 |
|---|---|---|---|
| 1 | <s> The | ||
| 2 | <s> The children | ||
| 3 | <s> The children played | ||
| 4 | <s> The children played soccer | 마스크된 단어를 예측 | |
| 5 | <s> The children played soccer outside | ||
| 6 | <s> The children played soccer outside until | ||
| 7 | <s> The children played soccer outside until it | ||
| 8 | <s> The children played soccer outside until it got | ||
| 9 | <s> The children played soccer outside until it got dark | ||
| 10 | <s> The children played soccer outside until it got dark </s> | 문장 종료 |
이 과정을 통해 마스킹 된 단어를 예측하고 전체 문장의 구조와 흐름을 이해하고 재구성하는 느ㅇ력을 얻는다. 또한 문장의 시작과 끝을 인식하는 능력도 학습한다.
Text Infilling
텍스트 인필링은 입력 문장에서 하나 이상의 연속된 단어를 마스킹하여 훼손시키고 디코더가 복원하게하며 학습시킨다.
모델은 이를 통해 문맥에서 빠진 부분을 채우는 능력을 개발하고 복합적인 문맥 이해와 언어적 예측 능력을 향상시킨다.
인코더 입력과 디코더의 레이블
- 인코더 입력(변형된 문장):
"He goes <mask> to the gym." - 디코더의 레이블(원본 문장):
"He goes to school and then to the gym."
학습 과정에서 단어를 한개씩 생성하며 중간에 마스킹 된 여러 단어를 연속적으로 예측해야한다.
이 과정에서 마스킹된 여러 단어들을 예측하는 능력과 전체 문장 구조의 흐름을 이해하고 재구성하는 능력을 얻는다. 또한 문장의 시작과 끝을 인식하는 능력도 학습한다.
Sentence Permutation
문장 순서 바꾸기는 여러 문장으로 구성된 텍스트의 문장 순서를 무작위로 섞고 디코더가 원래 문장 순서를 예측 복원하도록 학습한다.
이를 통해 문서 내에서 문장 간에 논리적 연결과 전체적인 흐름을 이해하고 올바른 순서로 재배열하는 능력을 개발한다.
인코더 입력과 디코더의 레이블
인코더 입력(순서가 섞인 문장들): "They went to the cinema. He met his friend. He left the house."
디코더의 레이블(원래 순서의 문장들): "He left the house. He met his friend. They went to the cinema."
Document Rotation
문서 회전은 전체 문서의 일부를 잘라내서 그 부분을 문서의 시작으로 설정한다. 디코더는 재배열된 문서를 원래의 순서대로 복원하도록 학습된다.
이를 통해 모델이 문서 전체의 구조를 이해하고 시작, 중간, 끝 부분을 판단하는 능력을 개발한다. 올바른 순서를 예측하며 전체 문서의 구조와 흐름을 이해하고 재구성하는 능력을 얻는다.
Token Deletion
토큰 삭제는 입력 문장에서 무작위로 토큰을 삭제한다. 디코더는 원래대로 복구하도록 학습된다.
이를 통해 모델은 문맥을 이해하고 누락된 정보를 추론하는 능력을 개발한다.
삭제된 토큰 위치에 mask 토큰을 넣지 않고 완전히 삭제한다.
인코더 입력과 디코더의 레이블
인코더 입력(토큰이 삭제된 문장): "The cat on the mat."
디코더의 레이블(원래 문장): "The cat sat on the mat."
삭제된 토큰의 위치정보를 제공하지 않기 때문에 더 어려운 과제라고 할 수 있으며 강력한 문맥 추론 능력과 누락된 정보 복원 능력을 개발한다.
정리
BART는 인코더-디코더 구조를 가진 트랜스포머 기반의 언어 모델이다.
이 모델은 입력 문장을 손상시키고 이를 복원하도록 학습하며 다양한 자연어 처리 작업에 성능을 보인다. 총 5개의 사전 학습 방법으로 복잡한 문맥을 이해하고 복원하는데 특화되어 있다.
BERT와 GPT의 강점을 결합한 형태로 인코더는 입력 문맥을 깊게 이해하고 디코더는 자연스러운 문장을 생성한다. 이를 통해 텍스트 요약, 번역, 질의응답 등 다방면에서 활용될 수 있다.
마무리
레퍼런스
