
RNNLM이란?
RNN 언어 모델은 말 그대로 RNN으로 만든 언어 모델로 RNNLM이라고 한다.
과거의 통계적 언어 모델 n-gram 언어 모델과 NNLM은 고정된 개수의 단어만을 입력으로 받는다는 한계가 있었다. 하지만 시점이라는 개념이 도입된 RNN으로 언어 모델을 만들면 입력의 길이를 고정하지 않을 수 있다.
RNNLM의 언어 모델링
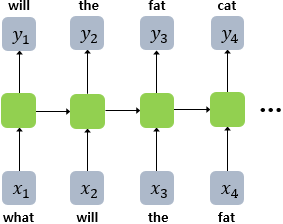
RNNLM의 훈련과정은 이전 시점의 예측 결과를 다음 시점의 입력에 넣으면서 예측하는 것이 아니다.
예문 : "what will the fat cat sit on"
위 예문을 학습한다면 "what will the fat cat sit on"을 모델의 입력으로 넣고 "will the fat cat sit on"을 예측하도록 훈련한다.
이런 훈련 기법을 교사 강요(teacher forcing)라고 한다.
교사 강요는 모델이 t시점에서 예측한 값을 다음 시점에 입력으로 사용하지 않고, t시점의 레이블 즉 정답을 다음 시점의 입력으로 사용한다.
훈련 과정에서 이전 시점의 출력을 다음 시점의 입력으로 사용하면서 훈련 시킬 수 있지만, 한 본 잘못 예측하기 시작하면 뒤의 예측까지 영향을 미치기 때문에 교사 강요를 사용하는 것이 빠르고 효과적이다.
RNNLM은 예측 과정에서 이전 시점의 출력이 현재 시점의 입력이 된다.
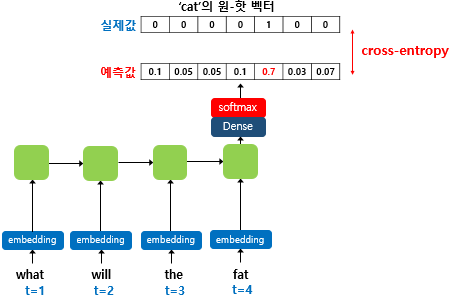
훈련 과정 출력층에서 활성화 함수로 소프트맥스 함수를 사용한다. 그리고 손실 함수로는 크로스 엔트로피 함수를 사묭한다.
RNNLM 구조
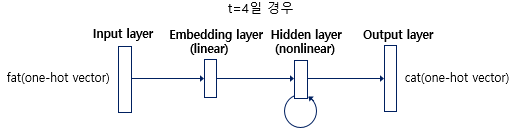
RNNLM은 그림과 같이 총 4개의 층으로 구성된다. 현재 시점 t는 4라고 가정한다. t가 4이기 떄문에 네번쨰 입력 단어인 fat의 원-핫 벡터가 입력된다.
출력층에서는 예측해야 되는 정답 다섯번쨰 입력 단어 cat의 원-핫 벡터는 모델이 실제 예측한 값의 오차를 구하기 위해 사용된다. 이 오차를 줄이며 가중치를 업데이트하는 과정이 훈련이다.
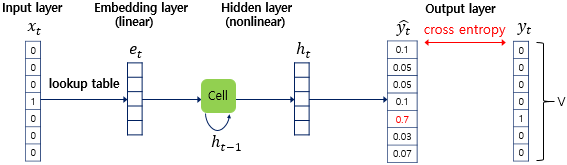
현 시점의 입력값이자 네번째 입력 단어인 cat의 원-핫 벡터 는 임베딩 층을 지난다. 임베딩 층은 룩업 테이블을 수행하는 투사층이다.
투사층을 지나면 임베딩 벡터가 된다. 룩업 테이블에 대한 자세한 내용은 이 글의 NNLM 언어 모델링 부분에 정리해놓았다.
다음은 은닉층이다. 임베딩 층을 지나 임베딩 벡터가 되면 이전 시점의 은닉 상태와 함께 현재 시점의 은닉 상태를 계산한다.
마지막으로 출력층은 활성화 함수로 소프트맥스 함수를 사용한다. V(단어 집합 크기)차원의 벡터는 활성화 함수를 지나면서 각 원소가 0과 1사이의 값을 가지며 총 합은 1이 되는 상태로 변한다. 이 값은 예측값이다.
다음으로 실제 정답 단어의 원-핫 벡터와 예측값의 오차를 줄이기 위해 손실 함수로 cross-entropy 함수를 사용한다. 마지막으로 역전파가 이루어지며 가중치 행렬들과 임베딩 벡터값들이 학습된다.
정리
RNNLM은 순환 신경망(RNN)을 기반으로 한 언어 모델로, 입력 길이에 제약이 없다는 점에서 n-gram 및 NNLM의 한계를 극복한다.
훈련 과정에서 교사 강요(Teacher Forcing) 기법을 사용하여 모델이 이전 시점의 출력을 다음 시점 입력으로 사용하지 않고, 정답 데이터를 입력으로 사용해 빠르고 안정적으로 학습한다.
마무리
RNNLM도 정리했으니.. 다음 글은 워드 임베딩이나 시퀀스투시퀀스 글로 돌아와야겠다 🐛🐛 다들 화이팅 😺😺
레퍼런스
