
👉 피드 포워드 신경망(인공 신경망) 공부 글 바로가기😺
NNLM이란?
피드 포워드 신경망 언어 모델(NNLM)은 신경망 언어모델의 시초이다.
과거에는 기계가 자연어를 학습하게 하는 방법으로 통계적으로 접근했으나, 인공 신경망을 사용하는 방법이 더 성능이 좋기 때문에 인공 신경망을 사용한 언어 모델들로 대체되었다.
이 글에서는 N-gram 언어 모델의 한계를 보완한 신경망 언어 모델의 시초 NNLM에 대해 알아본다.
언어 모델(Language Model)이란?
언어 모델에 대해 먼저 알아본다. 언어 모델은 언어라는 현상을 모델링하고자 단어 시퀀스(문장)에 확률을 할당(assign)하는 모델이다.
단어 시퀀스에 확률을 할당하는 이유는 확률을 통해 더 적절한 문장인지 판단하기 때문이다.
P(나는 버스를 탔다) > P(나는 버스를 태운다)
이렇게 단어 시퀀스에 확률을 할당하기 위해 보편적으로 이전 단어들을 통해 다음 단어를 예측하게 한다.
공항에 갔는데 지각을 하는 바람에 비행기를 [ ? ].
우리는 '비행기' 다음에 어떤 단어가 올지 쉽게 예상한다. 언어 모델도 비슷하다. '비행기' 앞에 어떤 단어가 나왔는지 고려하여, 후보 단어들의 확률을 예측하고 제일 높은 확률의 단어를 선택한다.
이것을 언어 모델링(Language Modeling) 이라고 한다.
N-gram 언어 모델
n-gram 언어 모델의 언어 모델링 방법은 예측할 단어의 앞 n-1개의 단어를 참고한다. 4-gram 언어 모델이면 예측할 단어 앞 3단어만 참고하고 나머지 단어는 무시한다.
이런 n-gram 언어 모델은 데이터에 의존하기 때문에, 현실에서 존재 가능한 시퀀스여도 데이터에서 관측하지 못하면 예측할 수 없다.
이런 문제를 희소 문제(sparsity problem)라고 한다.
희소 문제는 언어 모델이 단어의 의미적 유사성을 학습 할 수 있게 설계하면 해결할 수 있다.
예를 들면 데이터에 '발표 자료를 살펴보다'라는 단어 시퀀스는 존재하는데, '발표 자료를 톺아보다'라는 데이터가 없다면 톺아보다'를 예측에 고려할 수 없다.
우리는 '살펴보다'와 '톺아보다'가 비슷한 단어인 것을 알기 때문에 '냠냠하다' 보다는 '톺아보다'를 선택하겠지만, 유사도를 알지 못하는 언어 모델은 그러지 못한다.
NNLM의 언어 모델링
훈련 데이터가 준비 되었다면 단어를 인식할 수 있도록 원-핫 인코딩으로 수치화한다.
예문 : "what will the fat cat sit on"
what = [1, 0, 0, 0, 0, 0, 0]
will = [0, 1, 0, 0, 0, 0, 0]
the = [0, 0, 1, 0, 0, 0, 0]
fat = [0, 0, 0, 1, 0, 0, 0]
cat = [0, 0, 0, 0, 1, 0, 0]
sit = [0, 0, 0, 0, 0, 1, 0]
on = [0, 0, 0, 0, 0, 0, 1]이 원-핫 벡터들은 훈련을 위한 입력값과 예측을 위한 레이블이 된다.
'what will fat cat'을 입력 받아 'sit'을 예측하는 것은 'what'부터 'cat'까지의 원-핫 벡터를 입력받아서 'sit'의 원-핫 벡터를 예측하는 문제이다.
NNLM도 다음 단어를 예측할 때 n-gram 언어모델처럼 n개의 단어만 참고할 수 있다.
n이 4라고 하면 'sit'을 예측하기 위해 will, the, fat, cat 네 단어만 참고한다. 이 범위를 윈도우(window)라고 한다.
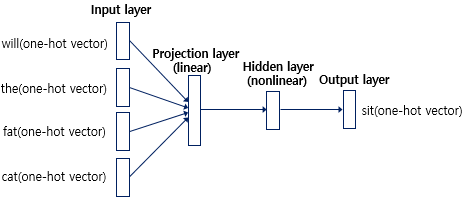
입력층(input layer)에서 will, the, fat, cat 네개의 원-핫 벡터를 입력 받으면, 다음층인 투사층(projection layer)으로 간다.
투사층은 랜덤 가중치 행렬과 연산을 하는 은닉층이지만 활성화 함수를 사용하지 않는다.
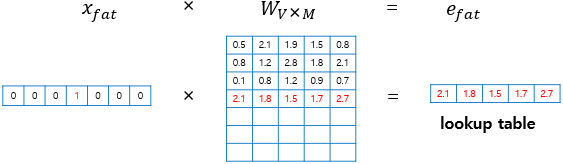
입력층 단어의 원-핫 벡터 차원(V)이 7이고, 투사층의 크기(M)가 5라면 가중치 행렬은 7 X 5 행렬이 된다.
fat의 원-핫 벡터는 3번째 인덱스 값이 1이고 나머지는 0이다. 이때 가중치 행렬()과 곱연산을 하면 가중치 행렬의 3번째 행을 그대로 가져오는 것과 같다.
그래서 이 작업을 룩업 테이블(lookup table)이라고 한다.
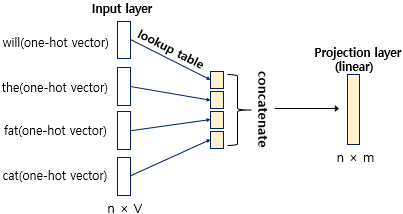
룩업 테이블 후에 원-핫 벡터들은 초기에 랜덤한 값을 가지지만 학습 과정에서 계속 값이 변경된다. 이 단어 벡터를 임베딩 벡터(embedding vector)라고 한다.
각 단어가 룩업 데이블을 통해 임베딩 벡터로 변경되고, 투사층에서 모두 이어붙여 연결된다(concatenate).
투사층의 결과는 은닉층에서 가중치가 곱해지고 편향이 더해져 활성화 함수를 통과한다.
은닉층의 결과는 출력층으로 간다. 또 다른 가중치와 곱해지고 편향을 더하고 활성화 함수를 통과한다. 이때 활성화 함수는 소프트맥스 함수를 사용한다.
활성화 함수를 통과한 벡터의 각 원소는 0과 1사이의 실수값을 가지며 총 합은 1이 되는 상태로 바뀐다. 이 벡터는 NNLM의 예측값이다.
예측값 벡터의 각 차원에서 j번째 인덱스가 가진 0과 1사이의 값은 j번째 단어가 다음 단어일 확률을 나타낸다.
이 예측 벡터는 학습을 통해 실제 정답인 원-핫 벡터의 값과 가까워져야 한다.
학습 과정에서 역전파가 이루어지면 모든 가중치 행렬이 학습되는데 이때 임베딩 벡터값도 학습된다.
따라서, 충분한 양의 데이터를 위와 같은 과정으로 학습한다면 유사한 목적으로 사용되는 단어들은 결국 비슷한 임베딩 벡터값을 갖게 된다.
그러면 예측 과정에서 훈련 데이터에 없던 단어 시퀀스라도 다음 단어로 선택할 수 있다.
정리
NNLM은 훈련 과정에서 단어를 벡터 공간에 매핑하는 방법(단어 임베딩)을 학습한다.
유사한 문맥에서 자주 등장하는 단어들은 벡터 공간에서 가까운 위치에 매핑된다.
예를 들면 "살펴보다"와 "톺아보다"는 문장에서 유사한 역할이어서 벡터 공간에서 가까운 좌표를 갖게 된다.
반대로 문맥에서 전혀 다른 의미를 가진 단어들은 서로 멀리 떨어진 벡터를 갖는다.
단어 임베딩이 문맥에서 유사한 단어를 비슷하게 학습한다는 것은 훈련 데이터에 없는 새로운 시퀀스에서도 유사한 의미를 가진 단어를 예측할 수 있도록 하는 것이다.
즉, 단어 임베딩은 NNLM이 일반화 능력을 가지도록 만드는 기초가 된다. 훈련 데이터에서 보지 못한 단어 시퀀스라도 단어 간 유사성을 통해 그 의미를 추론하여 적절한 예측이 가능해지는 것이다.
마무리
NNLM은 통계적 언어 모델의 한계를 극복하며 단어 간 유사성을 학습해 일반화 능력을 갖춘 언어 모델의 시초로 자리 잡았다. 단어를 벡터 공간에 매핑하고 문맥을 학습하는 구조는 이후 등장한 Word2Vec이나 Transformer 모델에도 큰 영향을 미친다.
다음글은 NNLM의 한계를 보완한 RNN 모델에 대한 글을 써야겠다.
아무튼 화이팅 🐛🐛
레퍼런스
