Intro
이미 많은 곳에서 리뷰가 굉장히 자세하게 진행된 논문이다.
Code와 함께 같이 리뷰된 글도 많아서 ViT를 이해하는데 도움이 많이 되었다.
이 리뷰는 내가 공부하면서 잘 이해가 가지 않았던 포인트 위주로 정리하고자 한다.
Study Point
https://en.wikipedia.org/wiki/Vision_transformer#/media/File:Vision_Transformer.gif
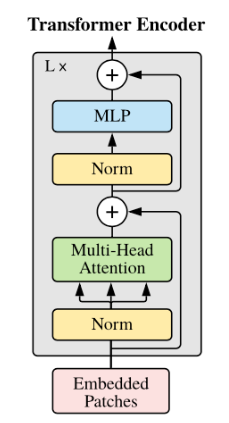
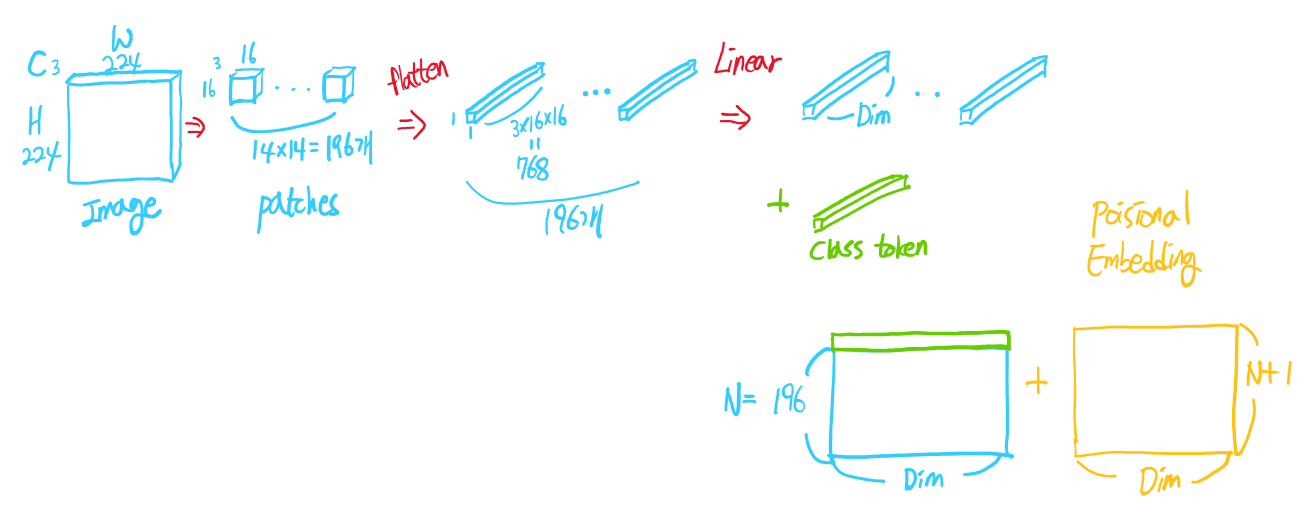
Input 이미지를 Patch단위로 나누고, class token과 positional embedding을 결합하여 Transformer encoder에 입력한다. 이를 그림으로 표현해보면 아래와 같다.
Image : [Channel, Height, Width] = [3, 224, 224]
Patch : [3, 16, 16]
Patch 갯수 : N = 196
최종 Embedded patch shape : [ N+1, Dim ]
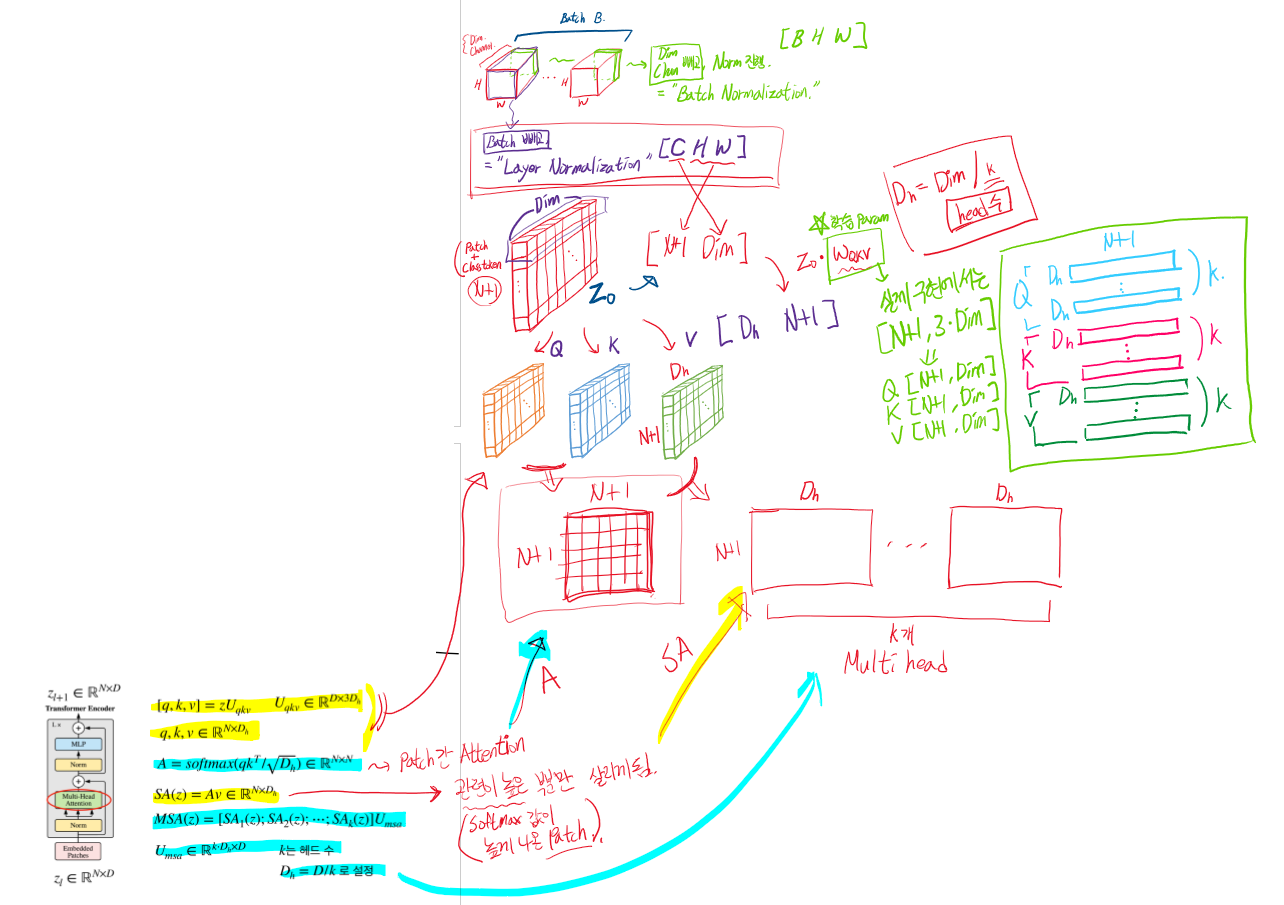
Layer Normalization은 Dim 차원에서 진행한다. (Batch Normalization과 다르다!)
이후 ViT Encoder에서 (Norm->Multi-Head Attention)이 동일하게 복사되는 것처럼 보이지만 Q, K, V는 값이 다 다르다.(이 부분이 특히 헷갈렸다.) 즉, Query, Key, Value로 나누어질 때, Linear로 학습 weight가 있다.
논문 속 Attention 결과들

{kind=link}
I felt that...
Paper with code 에서 보면 ViT base 논문들이 Detection 분야를 포함하여 SOTA 성능을 보여주고 있다. 나온지 불과 2년 만에 정말 많은 ViT 변형 모델들이 쏟아져 나오고 있어 부지런히 따라가야 할 것 같다.
References
