Computer Architecture
von Neumann Architecture vs. Harvard Architecture

-
von NuemannArchitecture
EDVAC 관련 보고서에서 등장하였고 EDSAC에서 최초로 구현된 컴퓨터 구조이다. stored program 방식으로도 불리며 data와 program이 동일한 공간에 저장되고 동일한 버스를 사용한다. John von Neumann이 제안한 방식이다. -
Harvard Architecture
Mark I 컴퓨터가 채택한 방식으로 program과 data가 저장되는 memory와 bus가 분리된 것을 제외하면 von Neumann구조와 매우 유사하다. 분리된 memory와 bus를 통해 동시에 program과 data 접근이 가능하므로 von Neumann보다 빠른 성능이 가능하다는 장점을 가진다.
CPU 외부에서는 von Neumann architecture를 주로 따르며 내부에선 Havard architecture를 따른다.
Function in the Programming
Mathematics에서의 function과 약간의 차이점이 있으나 프로그래밍에서의 function은 많은 부분에서 Mathematics에서의 function과 유사하다.
수학에서 function은 특정 계산들을 resue하거나 복잡한 계산을 보다 쉽게 read할 수 있도록 하기 위해 equation을 사용하여 특정 계산 등을 f(x,y)와 같은 형태로 대체하는 것이라고 볼 수 있다.
수학적으로 엄밀한 의미의 function은 mapping이나 transform의 개념으로 설명되어진다. 다음의 url을 참고하자: 함수 간략 정리
Programming에서도 function은 재사용성과 가독성을 위해 사용된다.
- Programming에서의 function은 동의어로
procedure,subroutine등이 많이 사용된다.
특정 programming language에서는 이들을 조금 다르게 사용하기도 하지만 실제적으로 부르는 이름의 차이만 있을 뿐 개념상으로는 큰 차이 없다.
수학에서 function은 입력과 출력간의 mapping에 좀 더 초점 을 두는 반면 programming에서의 function은 입력들을 받아 출력(Programming에선 return value라고 부르는 경우가 더 많음)을 만들어내는 처리에 초점 을 더 둔다는 차이는 있다.
Programming에서의 Function
Programming에서의 function은 SW (or program)에서 특정 동작을 수행하는 일정 code들의 모임을 의미한다.
특정 동작(=특정 처리)을 수행하기 독립적으로 설계된 프로그램 코드의 묶음(or 집합)으로 정의할 수 있다.
입력 (parameter들로 정의됨) 및 그에 따른 출력(return value로 정의됨)을 가지며 이들 사이에서 입력을 바탕으로 출력을 만들기 위한 처리부분으로 구성된다.
-
Programming에서의 function은 입력이 없거나 출력이 없는 것도 가능하다. (둘 다 없을 수도 있음)
-
Programming에서 반복되는 처리들을 묶어서 function으로 만들고 해당 처리들을 각각 수행하는 방식이 아닌 이들을 묶어서 만든 function을 호출하여 수행하는 것을 권장한다.
Imperative programming language의 경우엔 function을 만드는 것이 programming에서 가장 중요한 작업 중 하나에 해당한다.
Function의 종류
built-in function
Programming language등이 기본적으로 제공하는 함수들을 가르킨다. 파일 입출력 등과 같이 많은 경우에 공통적으로 필요한 다양한 함수들이 built-in function으로 제공된다.
Progrmming을 공부한다는 것은 상당 부분이 built-in function들을 올바르게 사용하는 것을 익히는 것이기도 한다. (영어 공부에서 단어나 숙어 공부에 해당?)
custom function
프로그래머가 built-in function을 기반으로 작성한 고유의 함수들이다. 프로그래밍을 한다는 것은 많은 function을 만들어내는 작업을 포함한다.
e.g. Function 만들기
다음은 Python, JavaScript, C 에서 세제곱을 수행하는 cube함수를 정의하는 예를 보여준다.
- 모든 경우 function의 이름은
cube로 지정한다. - function의 입력은 parameter x의 값으로 주어지게 된다. function cube를 call(호출)할 때 주어지는 argument가 x의 값으로 할당된다.
- 모든 경우 출력은 x의 세제곱을 수행한 값이다.
# Python
# Function Definition
def cube(x):
tmp = x **3
return tmp
# Function Call
a = cube(3) // JavaScript
// Function Definition
function cube (x)
{
return (x * x * x);
}
// Function Call
a = cube(3);
//console.log(a)// C
// Function Definition
float cube(float x)
{
float tmp = 0.;
tmp = x*x*x;
return tmp;
}
// Function Call
float a = cube(3);Function call (함수 호출)을 instruction set으로 쪼개보기
다음은 The Secret Life of Programs의 5장에서 2번째 절의 내용 일부이다.

- 위의 구현에서는 복귀할 address를 고정된 특정 주소 (200)에 저장하기 때문에 recursive function call을 지원할 수 없다.
- Function call은 stack에 argument들과 return address를 저장하기 때문에 추가적인 부하가 발생한다.
- 하지만, 이를 없앤다고 function을 사용하지 않을 경우 program code자체에 중복되는 코드가 너무 많아져 버그에 취약해지고 가독성을 잃게 되므로 가급적 중복되는 처리는 function으로 만들어서 사용해야 한다.
Function call과 stack.
프로그램이 수행될 때 function call이 이루어지면 function이 저장되어 있는 memory의 address로 PC가 가르킴에 따라 수행되는 주소의 분기(branching)가 이루어진다.
function의 수행이 끝나면 function call이 이루어진 다음 주소로 돌아와야 하기 때문에 해당 address가 저장되어야 한다. 이 돌아올 address 및 function에서 사용할 local variables( parameters 포함)은 stack에 저장되게 된다.
이같이 stack에 저장된 데이터들의 모음 을 Stack Frame이라고 부른다.
- function(=subroutine)으로 전달하는 parameters (이들의 값은 호출 시 사용된 argument임)
- local variables (C언어)
- 복귀 주소
data structure
Stack은 자료구조의 하나로서 FILO (First-In-Last-Out, LIFO 와 같은 의미)로 동작한다.
많은 경우 접시 쌓기를 예로 사용하여 First-In-Last-Out (FILO), Last-In-First-Out (LIFO)를 설명한다.
- Stack에 저장되는 데이터 단위를 element(요소)라고 하며
- 새로운 element가 Stack에 추가되는 것을 Push (데이터 삽입)라고 부르고
- 현재 stack에서 element를 빼내는 동작을 Pop (데이터 삭제)이라고 부른다.
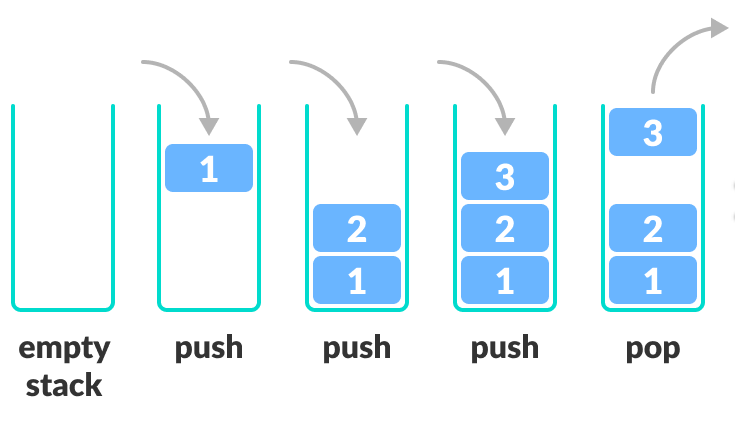
Stack을 class로 구현시 push와 pop은 method들로 구현된다.
참고로 Python에서의 list를 stack처럼 사용한다면 append 를 push로 사용하고 pop은 list에서 제공하는 pop 을 그대로 사용하면 된다.
Function calls, memory allocation 등에서 기본적으로 사용되기 때문에 대부분의 CPU들은 instruction set에서 stack 을 위한 instruction을 따로 제공하며 HW적으로 구현하고 있다.
SW적으로는 expression evaluation이나 programming에서 "중가로 (curly bracket)" 등을 열고 닫았는지 체크하거나, Reverse Polish Notation (RPN)의 구현 등에서 자주 사용된다.
Recursive call
Recursive call의 경우 특정 함수가 내부에서 자기자신을 다시 호출하는 것을 가르킨다.
다음과 같은 재귀적인 수식을 있는 그대로 작성하게 해준다는 장점은 있지만, 속도의 측면에서는 그리 환영받지는 못한다 (너무 느림)
를 정의하는데에 같은 함수가 사용되는 경우를 recursive call로 작성하면 매우 직관적인 구현이 가능하다.
대표적인 예로 Fibonacci sequence를 들 수 있다.
Python 구현 : Recursive call 이용한 경우
def fibonacci_recur(num):
ret = -1
if num <0:
print('ERROR: negative is not supported')
elif num <=1 :
ret = num
elif num == 2:
ret = 1
else:
ret = fibonacci_recur(num-1) + fibonacci_recur(num-2)
return ret
for i in range(0,10,1):
# print(i)
print(fibonacci_recur(i), end=",")
print('\n')Python 구현 : while 문을 이용한 경우
def fibonacci_loop(num):
if num == 0 or num == 1:
return num
elif num == 2:
return 1
else:
length = num - 2
first = 1
second = 1
while length > 0:
tmp = second
second = first + second
first = tmp
length -=1
return second
for i in range(1,10,1):
# print(i)
print(fibonacci_loop(i), end=",")
print('\n')사실 while문을 이용한 경우 fibonacci_loop 함수 내에서 수열을 출력하도록 수정하면 훨씬 효과적으로 피보나치 수열을 출력할 수 있다. (위의 경우 fibonacci_loop에서는 수열을 출력하기 보다 최종값만을 구하는 형태임)
즉, while문을 이용하여 fibonacci_print 함수를 만들고 호출시 argument로 수열을 출력해줄지 최종 값만 반환할지를 선택케 하는 형태로 만들면 효과적이다.
Interrupt and Polling
Interrupt와 Polling은 CPU에게 어떤 event들이 발생했음을 알리고 이들을 처리하기 위해 제안된 두가지 방법이다.
event가 발생했을 때 CPU는 대개의 경우 어떤 process를 처리하고 있을 경우가 많다. 즉, CPU는 어떤 process를 처리하고 있는 도중이라도 특정 event들이 발생했는지 여부를 알 수 있어야 하고 이를 처리할 수 있어야 한다.
예를 들어, 키보드에서 입력이 된 event가 발생했으나 CPU가 특정 process를 처리하느라 이를 인식하지 못할 경우 사용자는 해당 process가 종료되기 전까지는 키보드를 통한 어떤 입력도 수행되지 못하는 것을 보게될 것이고 이는 컴퓨터가 죽은 게 아닌가 생각하게 될 것이다. 때문에 interrupt나 polling을 통해 event를 확인하고 처리할 수 있어야 한다.
Polling
Polling 방식의 경우 CPU는 일정시간 간격으로 현재 수행 중인 process를 잠시 멈추고 event들이 발생했는지를 점검 하게 된다.
점검해야할 모든 event들을 주기적으로 체크하는 방식 이기 때문에 점검해야 하는 event의 수가 많아질수록 CPU에 걸리는 부하가 커진다.
때문에 현재는 interrupt 방식이 polling 보다 많이 사용되며 실제로 HW적으로 구현된 interrupt system이 사용 된다. 오늘날 Polling은 일종의 protocol이며 SW적으로 구현하여 특정 처리 등을 할 때 사용된다.
Interrupt
Interrupt는 CPU가 주도적으로 체크하는 polling과 달리 event가 발생된 경우 해당 event와 관련된 device등이 CPU에게 event가 발생 되었다고 알려준다.
주변기기에서 발생한 interrupt의 처리과정을 예를 들어 살펴보면 다음과 같다.
- 주변기기에서 CPU가 attention해야만 하는 event가 발생시 interrupt request (IRQ)을 생성하여 CPU(or processor)에게 보내게 된다.
- 이를 받은 processor는 현재 작업 수행(execution)의 상태를 저장하고 수행을 멈춘다.
- 그리고 해당
interrupt의interrupt vector를 참고하여 처리를 수행할interrupt handler(or interrupt service routine)를 호출하게 된다. interrupt handler는 해당 interrupt를 처리하는 작업을 수행하게 된다. interrupt handler는 특정 interrupt에 해당하는 event시 처리되어야할 작업을 구현한 function 이라고 생각하면 된다.interrupt handler가 처리를 끝내면 processor는 중단시킨 작업(process)를 다시 재개한다.
Stack 과 interrupt
현재 실행 중이었던 process의 상태를 저장하고 interrupt handler가 종료되고 나면 돌아올 주소 등이 저장하기 위해 사용되는 자료구조가 stack으로 오늘날 processor들은 이를 위한 stack을 hardware로 구현하고 있다.
이같은 상태 저장 등은 interrupt handler가 책임지고 수행한다.
Interrupt vector
Interrupt handler가 위치하고 있는 memory address등을 가지고 있다.
발생한 interrupt의 종류와 이를 처리할 interrupt handler의 memory address등을 가지고 있다.
(Interrupt) Mask, Priority and Timer
특정 interrupt를 켜고 끌 수 있으며 이에 대한 정보를 가지고 있는 mask 가 존재한다.
또한 interrupt들은 priority(우선순위)를 가지며 높은 우선순위의 interrupt 가 우선적으로 처리된다.
지나치게 interrupt처리에 많은 시간을 줄 수 없으며 이같은 시간제한을 위한 timer interrupt도 존재한다.
OS와 signal (or event) handler system
SW적 관점에서 OS는 마치 hardware interrupt를 모방한 virtual or software interrupt system을 가지고 있다.
User application에서 system call을 통해 Kernel mode로 동작을 요청할 때 software interrupt가 발생하며 이후로 kernel mode가 되어 해당 처리가 완료된 이후 원래의 User application의 user mode로 돌아와 작업이 재개된다.
UNIX에서는 이같은 software interrupt를 주로 signal이라고 부르며 해당 처리 방식을 signal mechanism이라고 부른다. (CTRL+C도 대표적인 signal)
하지만 최근에는 signal이라는 용어보다 event라는 용어가 더 많이 사용된다.
interrupt
오늘날 OS는 interrupt를 기반으로 동작 (Interrupt Based System)한다
- interrupt가 발생하면 CPU는 현재 하는 일을 멈추고 해당 interrupt를 해결하려고 동작한다.
processor가 특정 동작을 하고 있는 중 (OS가 특정 process를 수행)에 다른 device들에게서 interrupt가 오는 경우 (경우에 따라 다르지만) 현재 실행되고 있는 일을 멈추고 해당 interrupt에 대응하는 Interrupt Service Routine (ISR)이 수행하는 것을 가르킨다.
- routine이란 어떤 동작을 수행하는 프로그램 코드를 의미한다.
Interrupt 작동단계 : Keyboard 예
Keyboard에서 키를 누를 경우 다음의 단계를 거치게 된다.
- Keyboard의 controller에서 key up, key down 등의 interrupt를 일으키는 event를 감지한다.
- Keyboard에서 전기적 신호가 processor로 전달된다. (interrupt 발생)
- 바로 연결된 것은 아니다. (작은 임베디드 시스템의 특정 센서라면 직접 연결될 수도 있음)
- 하지만 결국은 interrupt signal이 들어오는 processor의 pin에 전기신호가 들어오게 된다.
- processor는 매번 execute 명령이 끝날 때마다 interrupt를 확인하고 interrupt 요청 이 있을 경우 현재 하던 일을 중지한다. (현재 실행 중인 process 중지)
- 현재 하던일을 stack에 저장하는 context switching이 발생한다. (실행 중이었던 process의 상태 저장)
- 이후 해당 ISR에 제어권이 넘어가며 수행됨 (키보드의 경우 keyboard ISR이 수행됨.) : ISR (또는 handler) 실행한다.
- 키보드 인터럽트의 경우 scan code의 값을 ASCII code로 변환하여 buffer에 저장한다.
- ISR수행 이후, 원래 수행하던 process가 수행된다.(context switching) : 저장된 상태로 복구하고 다시 process 실행 재개한다.
- 키보드 값이 필요한 process라면 buffer에서 읽어들이게 됨.
Interrupt 종류
다양한 Interrupt가 있지만 크게 다음과 같은 3가지 종류로 나뉜다.
Hardware Interrupt
- processor에 연결된 hardware에서 발생시키는 interrupt이다.
- 키보드, 마우스를 조작할 때 발생되는 게 가장 흔한 예이다. (입출력장치 interrupt)
- Timer interrupt, 전원공급 이상 interrupt 등이 있다.
- Timer interrupt 를 통해 무한루프인 프로그램도 종료되며 특정 프로그램이 CPU를 독점하는 것이 방지된다.
- 전원공급 이상 interrupt를 통해 작업 중이던 process를 dump한다던지의 처리가 가능하다.
Software Interrupt
- User application의 process가 system call을 할 때 발생되는 interrupt이다.
- User application은 User Mode에서 수행되기 때문에 직접 접근할 수 없는 resource들이 존재한다. 이같은 resource에 접근이 필요한 코드가 User appliation에 있다면 해당 코드를 수행할 때 SVC(SuperVisor Call)를 통해 Kernel Mode 로 변경이 되고(물론 OS가 허락을 해야함) 해당 코드의 수행이 종료된 이후 다시 User Mode로 변경이 된다.
- system call은 OS가 제공하는 서비스들에 User application이 접근하게 해주는 interface이고 이들 System call을 수행케 해주는 instruction (CPU가 가지고 있는 instruction set에 속함)이 SVC이다.
- Trap: Register와 스택 포인터가 저장되고 Context Switching이 일어나고 실행이 재개될 수 있게 해주는 특별한 명령어이다. CPU 내부 interrupt 라고도 불리며 system call도 Trap을 통해 구현된다.
- SVC는 Software interrupt의 대표적 예이다.
Internal Interrupt
- processor 내부에서 발생되는 interrupt: Processor가 프로그램의 코드를 실행하는 도중 발생한 interrupt
- 잘못된 instruction이나 data를 사용한 경우 발생한다.
- Overflow나 Divded by Zero, 기타 Exception 등이 발생한 경우 발생한다. Trap은 특정 조건을 걸어둔 경우 적절할 ISR이 수행되는 경우라면 Exception은 예기치 못한 예외상황에 해당한다. SW 내부에서 exception처리를 통해 프로그래밍에서 특정 exception들이 발생시 처리할 수도 있다.
