
큐(Queue), 우선순위 큐(Priority Queue), 스택(Stack)
1. 큐(Queue)란?
- 선입선출 FIFO(First In First Out)의 자료구조이다.
- 시간 순서상 먼저 집어 넣은 데이터가 먼저 나오는 구조이다.
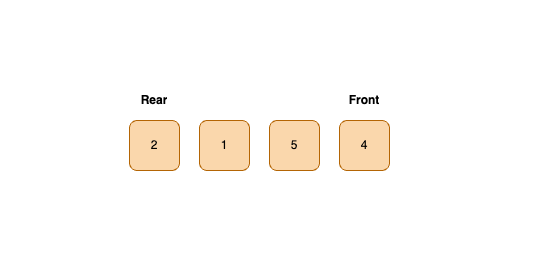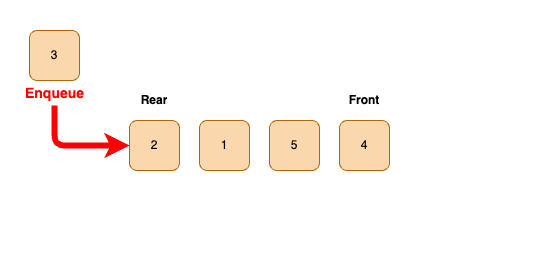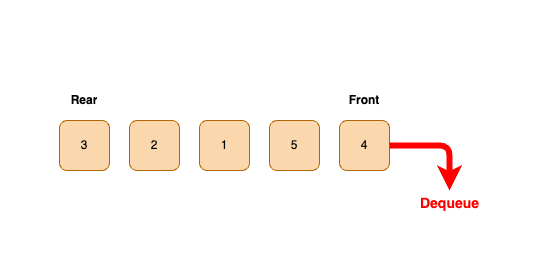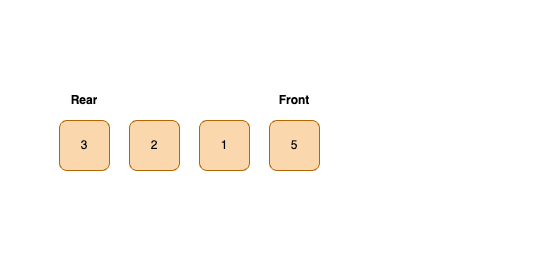
- 큐에 요소를 넣는 작업을 Enqueue, 제거하는 작업을 Dequeue라고 한다.
- Rear : Enqueue 연산이 이루어지는 큐의 맨 뒤에 있는 공간을 가리키는 포인터
- Front : Dequeue 연산이 이루어지는 큐의 맨 앞에 있는 요소를 가리키는 포인터
- 가장 기본 형태가 선형 큐(Linear Queue)이다.
2. 큐의 동작 조건
- 크기 제한
- 큐는 메모리 또는 시스템 자원의 한계를 가지기 때문에 크기 제한이 필요하다.
- 제한이 없을 경우 메모리 부족 문제가 발생할 수 있다.
- 고정 크기의 배열을 사용하여 큐를 구현하는 경우 배열의 크기가 큐의 최대 크기를 결정한다.
- 만약 큐가 가득 차 있는 상태에서 새로운 데이터를 삽일하려 한다면 → 큐 오버플로우(overflow) 발생
- 빈 큐 상태
- 큐가 비어 있는 상태에서 데이터를 제거하려고 할 경우 언더플로우(underflow) 문제가 발생할 수 있다.
- 이때, 큐가 제거할 데이터가 없기 때문에 예외 처리가 필요하다
- 데이터 순서 유지
- 큐는 선입 선출 방식으로 동작하기 때문에 삽입된 데이터가 순서대로 처리되어야 한다.
- 순서가 뒤바뀌는 상황을 방지해야 한다.
3. 큐(Queue)의 대표적인 함수
-
Enqueue(삽입) 연산
- 큐에 새로운 데이터를 추가하는 과정이다.
- 삽입되는 데이터는 큐의 rear(뒤)에 위치하게 된다.
-
Dequeue(제거) 연산
- 큐의 맨 앞에 있는 데이터를 제거하고 반환하는 과정이다.
4. 큐의 장단점
- 장점
- 간단한 구조와 구현
- 매우 직관적이고 간단한 구조를 가지고 있어 구현이 용이하다.
- 배열이나 연결 리스트 같은 기본적인 구조를 이용해 쉽게 만들 수 있다
- FIFO 방식으로 데이터 처리
- 데이터가 삽입된 순서대로 처리되므로, 일관된 처리 순서를 유지할 수 있습니다.
- 간단한 구조와 구현
- 단점
- 비효율적인 메모리 사용
- 선형 큐에서 삽입과 삭제를 반복하다 보면, front와 rear 포인터가 큐의 끝으로 이동하게 된다.
- 이때 큐의 앞부분에 공간이 남아 있더라도, 더 이상 새로운 데이터를 삽입할 수 없게 된다.
- 이 문제로 인해 실제로는 충분한 공간이 남아있어도 큐를 다 사용한 것 처럼 보여 큐 오버플로우가 발생할 수 있다.
- 고정된 크기 제한
- 선형 큐가 배열 기반으로 구현된 경우, 큐의 크리가 고정됩니다.
- 고정된 크기 때문에 큐가 가득 찼을 때 더 이상 데이털르 삽입할 수 없으며, 동적 크기 조정이 어려울 수 있다.
- 비효율적인 메모리 사용
5. 우선순위 큐(Priority Queue)란?

- 큐에 삽입된 데이터가 단순히 선입선출(FIFO)방식으로 처리되는 것이 아니라, 각 데이터에 부여된 우선순위에 따라 처리순서가 결정되는 자료구조이다.
- 우선순위가 높은 데이터가 먼저 처리되며, 동일한 우선순위를 가진 데이터는 선입선출 방식으로 처리된다.
- 우선순위 큐는 다양한 방식으로 구현될 수 있으며, 가장 효율적인 방식은 힙(Heap) 자료 구조를 사용하는 것이다.
- 최소 힙 또는 최대 힙을 이용해 우선 순위 큐를 구현하면, 데이터 삽입과 삭제가 효율적으로 이루어진다.
6. 우선순위 큐 장단점
- 장점
- 유연한 데이터 처리
- 데이터의 우선순위에 따라 처리 순서를 동적으로 결정할 수 있기 때문에, 중요한 작업을 먼저 처리해야 하는 상황에서 매우 유용하다.
- 효율적인 구현
- 힙 자료 구조를 사용하면 우선순위 큐의 삽입 및 삭제 연산이 의 시간 복잡도로 처리된다.
- 유연한 데이터 처리
- 단점
- 복잡한 구현
- 정렬된 삽입이나 힙 구조 유지 등의 과정 때문에, 코드가 복잡해지고 유지 보수가 어려워 질 수 있다.
- 우선순위 결정의 어려움
- 모든 데이터에 우선순위를 부여해야 하는데, 이 우선순위를 결정하는 과정이 어려울 수 있다.
- 잘못된 우선순위 설정은 비효율적인 데이터 처리로 이어질 수 있으며, 시스템 성능에 영향을 줄 수 있다.
- 우선순위 설정 규칙이 명확하지 않거나 애매한 경우, 시스템의 동작이 예기치 않은 방향으로 흘러갈 수 있다
- 복잡한 구현
7. 스택(Stack)이란?
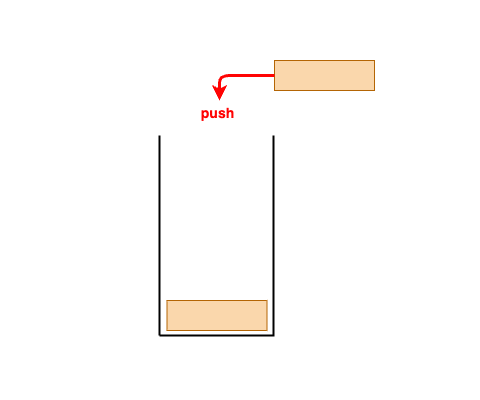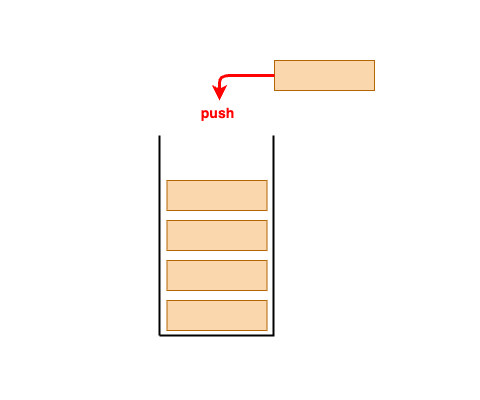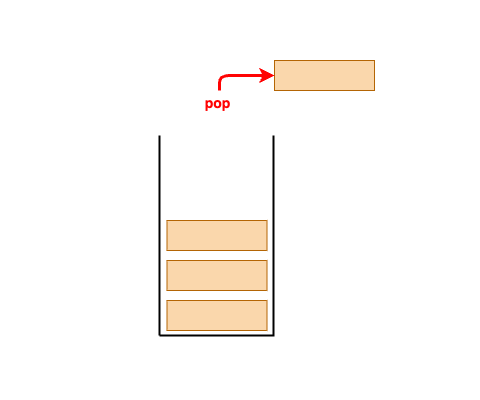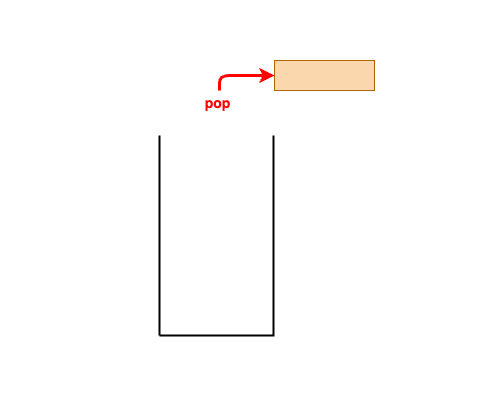
- 후입선출(LIFO, Last in, First Out)방식으로 동작하는 자료구조이다.
- 나중에 삽입된 데이터가 먼저 제거되는 구조이다.
- 스택에서는 데이터 삽입과 제거가 한쪽 끝에서만 이루어지며, 이 끝을 탑(top)이라고 부릅니다.
- 주요 연산
- push: 데이터를 스택의 top에 삽입하는 연산.
- pop: 스택의 top에 있는 데이터를 제거하고 반환하는 연산.
- peek: 스택에서 현재 top에 있는 데이터를 확인하는 연산.
8. 스택의 동작 조건
- 후입선출(LIFO) 원칙 준수
- 스택의 가장 중요한 동작 조건은 후입선출(LIFO)원칙 이다.
- 따라서 마지막에 삽입된 데이터가 가장 먼저 제거되고 이 규칙이 어겨지면 스택의 기본 개념이 무너져 데이터 처리의 예측 가능성이 없어진다.
- 고정된 크기 또는 동적 크기
- 스택은 고정된 크기로 구현되거나 필요에 따라 동적으로 크기를 변경할 수 있다.
- 스택이 고정된 크기를 가지는 경우, 새로ㅗ운 데이터를 삽입할 때 스택이 가득차면 Stack Overflow가 발생한다.
- 반대로, 동적 크기를 가진 스택은 필요에 따라 크기를 확장 할 수 있지만, 크기 확장은 성능에 영향을 줄 수 있다.
- 비어 있는 스택에 대한 접근 금지
- 스택이 비어 있는 상태에서 pop 또는 Peak연산을 시도하면 오류가 발생한다
- 이를 Stack Underflow라고 하며, 이 경우 스택이 비어 있음을 미리 확인하여 오류를 방지해야 한다.
- 보통 isEmpty() 함수로 스택이 비어있는지 확인한 후, Pop 또는 Peek 연산을 수행하는 것이 안전하다
9. 스택의 대표적인 함수
- Push(item)
- 스택의 맨 위에 새로운 데이터를 삽입한다.
- 스택이 비어 있으면 이 데이터가 첫 번째 요소가 된다
- Pop()
- 스택의 맨 위에 있는 데이터를 제거하고 반환한다.
- 이 함수는 Push로 삽입된 데이터가 가장 나중에 제거된다는 점에서 후입선출 원칙을 따른다.
- Peek()
- 스택의 맨 위에 있는 데이터를 제거하지 않고 반환한다.
- 이 함수는 현재 스택의 상태를 확인할 때 유용하다.
- isEmpty()
- 스택이 비어 있는지 여부를 확인한다.
- 이 함수는 Pop이나 Peek 연산을 수행하기 전에 스택의 상채를 확인하는 데 유용하다.
10. 스택의 장단점
- 장점
- 간단한 구현과 관리
- 스택은 배열 또는 연결 리스트를 이용해 수비게 구현할 수 있고 직관적이다.
- 재귀적 알고리즘의 지원
- 재귀 함수의 호출 기록을 저장하고, 나중에 복원하여 함수가 정상적으로 동작할 수 있게 돕습니다.
- 빠른 데이터 접근
- 마지막에 삽입된 데이터를 빠르게 접근할 수 있다.
- 간단한 구현과 관리
- 단점
- 제한된 데이터 접근
- 스택은 오직 Top 위치의 데이터만 접근할 수 있으며, 중간에 있는 데이터를 직접 접근하거나 수정할 수 없다.
- 데이터 삽입/제거의 순서 강제
- 데이터가 삽입된 순서와 반대로만 제거할 수 있기 때문에, 스택에 데이터를 잘못 삽입하면 나중에 이를 다시 꺼내는 것이 불가능하거나 어렵다.
- 제한된 데이터 접근
11. 결론
| 큐 | 선입선출(FIFO, First in First Out) | 먼저 삽입된 데이터가 가장 먼저 제거 |
|---|---|---|
| 우선순위 큐 | 우선순위 기반 | 우선순위가 높은 데이터가 먼저 처리 |
| 스택 | 후입선출(LIFO, Last In First Out) | 마지막에 삽입된 데이터가 가장 먼저 제거 |
- 스택은 재귀적 문제 해결과 같은 루입선출 구조가 필요한 상황에 적합하다.
- 큐는 데이터가 들어온 순서대로 처리해야 하는 대기열 관리에 유리하다.
- 우선순위 큐는 우선순위에 따라 중요한 작업을 먼저 처리해야 하는 경우에 탁월하다.
