문제 상황
사내 플랫폼의 API Server를 모니터링하던 도중에 이상한 점을 발견하였습니다.
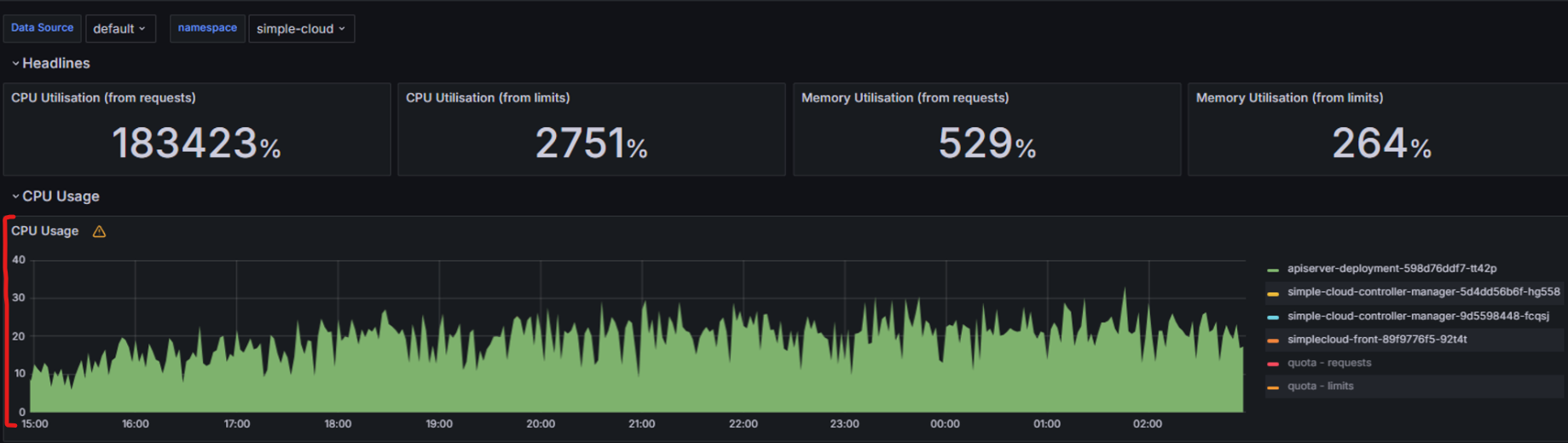
API Server의 CPU가 25코어 남짓을 잡아먹고 있던 것이었습니다.
실제로 확인해보니 API Server 기능 중 로그 모니터링을 사용하면 CPU 사용률이 비정상적으로 높아지는 것을 찾을 수 있었고, 로그 모니터링 기능 중 websocket을 사용한 부분에 문제가 있다고 판단했습니다.
특이점은 실행중인 pod의 로그를 가져올 때는 문제가 없는데 completed나 failed된 파드의 로그를 가져올 때 cpu가 올라간다는 점이었습니다.
현재 로직
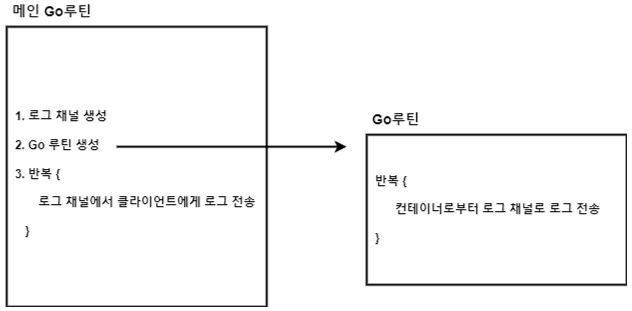
두 개의 반복문이 있는데 아래와 같습니다.
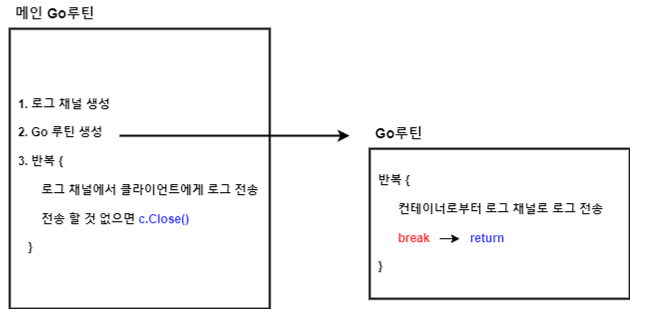
- 메인 go루틴 : 로그 채널 생성 후 로그 채널에 들어온 로그를 클라이언트로 보내도록 반복
- go루틴 : 컨테이너로 부터 로그 채널로 로그 전송하도록 반복
원인 파악
문제가 발생하는 원인에 대해 가장 높은 가능성순으로 나열한 뒤 소거법으로 문제를 해결했습니다.
- go루틴 내 반복문 무한루프
- 메인 go루틴 내 반복문 무한루프
- websocket 로직의 문제
테스트 및 문제 해결 과정
1. go루틴 내 반복문의 무한루프
먼저 go루틴 반복문에 log를 찍어봤습니다.
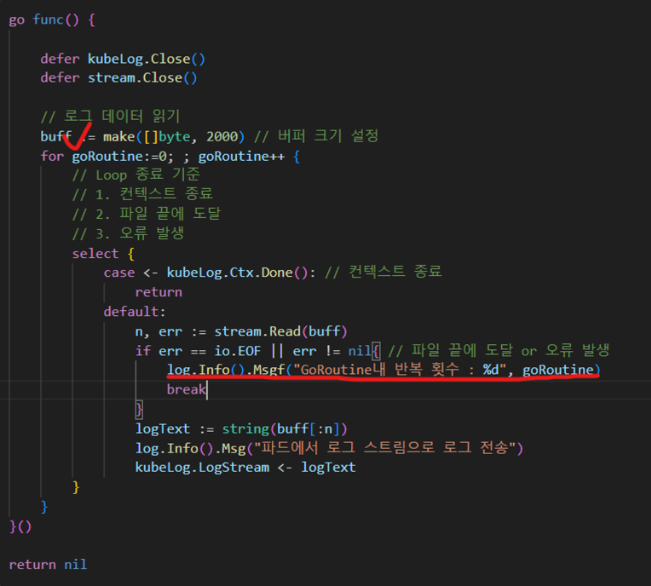
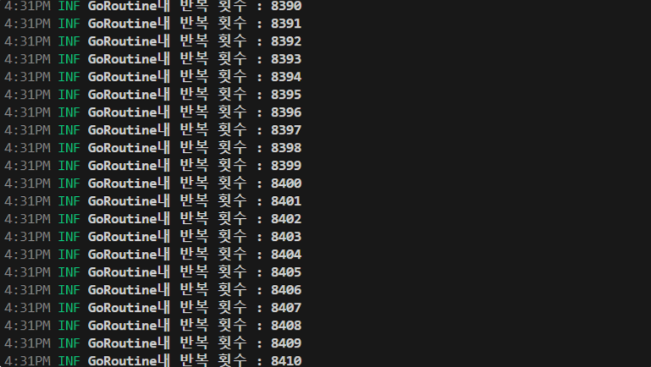
예상대로 무한루프가 돌고 있었습니다.
그 원인은 "break" 에 있었습니다.
completed 되었거나 failed된 pod의 로그는 EOF를 만나게 됩니다.
따라서 EOF를 만나면 반복문을 탈출해야하고 break가 그 역할을 수행할 줄 알았습니다.
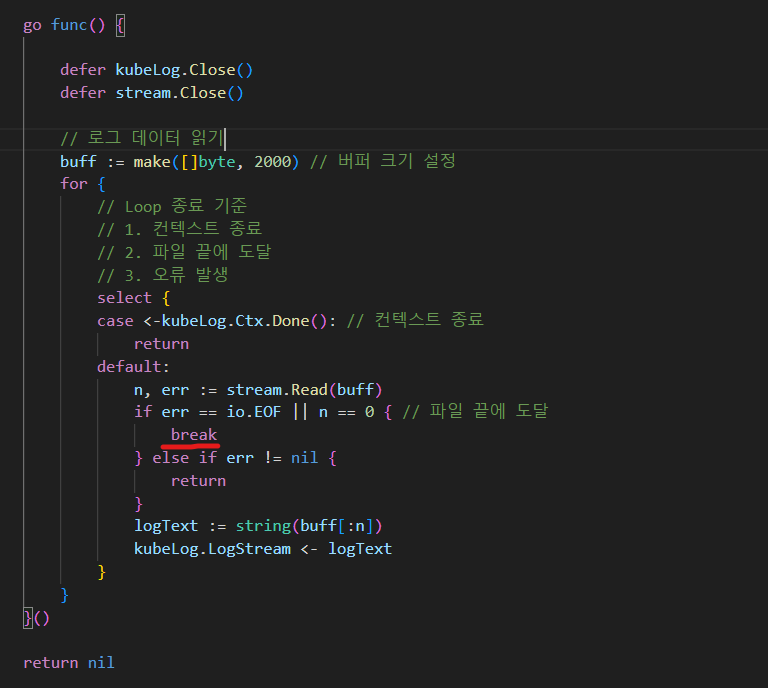
하지만 원하는대로 동작하지 않았고 반복문이 아닌 select문의 default 블록을 탈출하였습니다
그래서 break가 아닌 return을 적용하여 해결하였습니다.
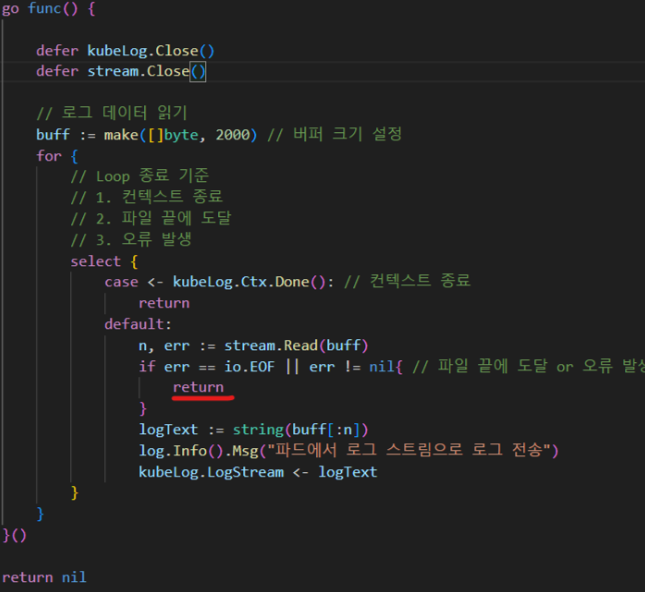
이대로 문제가 해결된줄 알았지만 CPU 사용률은 여전히 높았습니다.
2. main go루틴 내 반복문 무한루프
테스트 결과 main go루틴의 반복문에도 무한루프가 돌고 있었습니다.
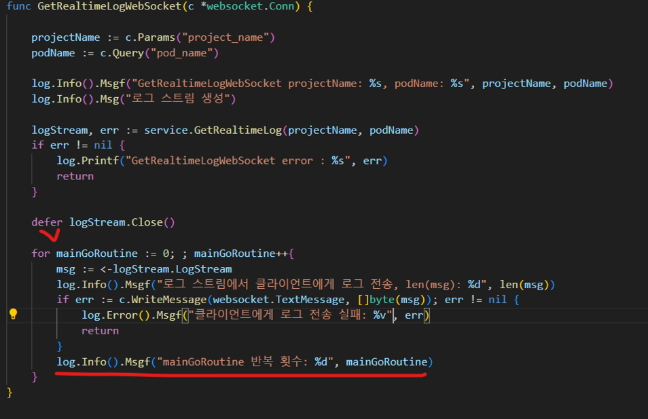
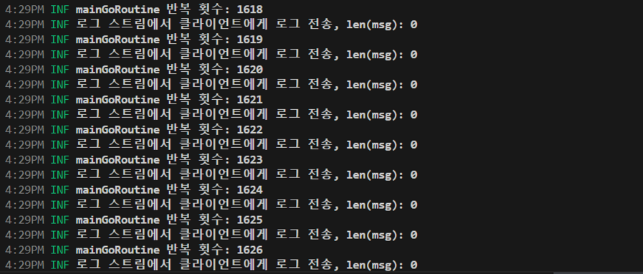
그 결과 go루틴이 무한대로 생성되었고 CPU 점유율이 기하급수적으로 상승하였습니다.
그 원인은 websocket의 connection을 제때 끊어주지 않음에 있었습니다.
EOF를 만나 go루틴이 끝나면 채널에는 빈 msg가 들어오게 됩니다.
빈 msg가 들어오면 websocket connection을 종료하도록 로직을 수정하였습니다.
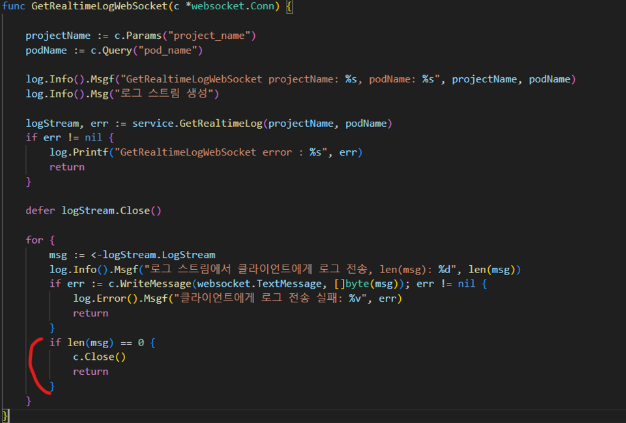
최종 로직과 결과
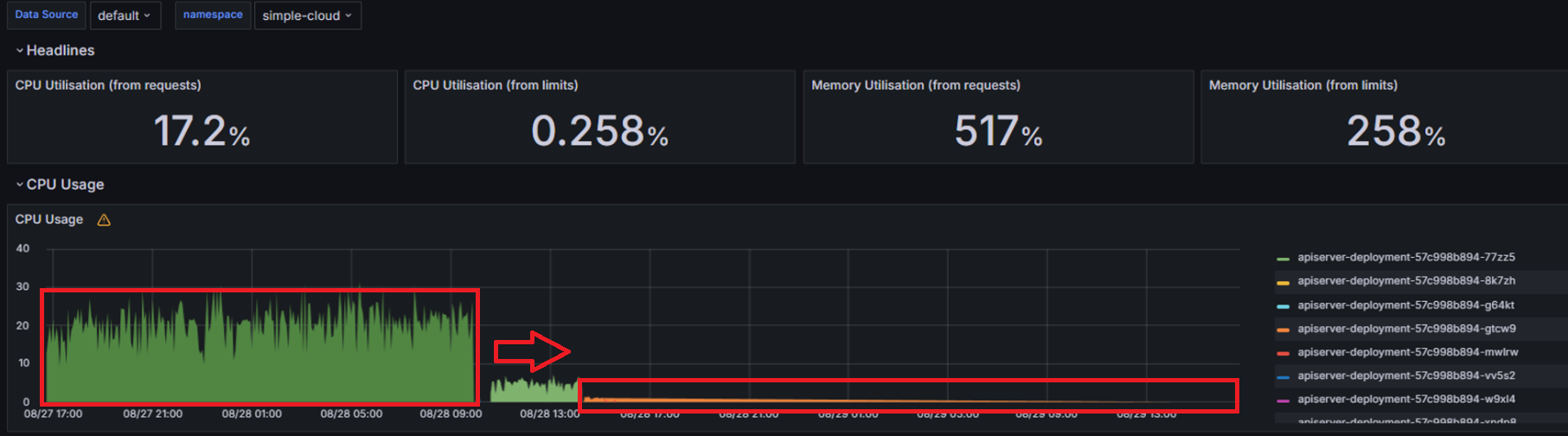
최종 로직은 아래와 같이 수정되었고 그 결과 CPU 사용률이 1코어 내로 줄어들었습니다.
방지 대책
테스트를 통해 해결은 했지만 다음에 이런상황이 오는 것을 방지하기 위한 대책을 세워야 겠다고 판단했습니다.
Uber에 goleak이라는 leak을 detect해주는 패키지가 있습니다.
해당 패키지로 테스트 케이스를 짜면 leak을 사전에 테스트 해볼 수 있습니다.
느낀점
이번 문제를 해결하면서 몇 가지 중요한 교훈을 얻을 수 있었습니다.
1. 비동기 처리의 복잡성
go루틴이 경량 스레드라 가볍다고 생각해서 별다른 관리 없이 그냥 방치했는데, 특히 WebSocket처럼 지속적인 연결이 있는 상황에서는 애플리케이션 전체 성능을 저하시킬 수 있다는 사실을 깨달았습니다.
2. select문에서 잘 탈출하기!
break가 반복문만 탈출하는 게 아니라 select문에서도 탈출할 수 있기 때문에 주의가 필요합니다. 이 작은 차이가 이번에 애플리케이션 전체에 영향을 주는 결과를 초래했기 때문에 중요한 포인트였습니다.
3. WebSocket과 채널 관리
WebSocket과 채널이 결합된 비동기 로직에서는 연결 상태를 지속적으로 확인하고, 로그 스트림이 종료된 후 WebSocket 연결을 어떻게 종료할지도 관리가 필요합니다. 그렇지 않으면 자원 누수가 발생하기 쉽고, 이는 성능 저하로 이어질 수 있기 때문에 설계와 구현에 신중해야겠다고 느꼈습니다.
4. 지속적인 모니터링의 중요성
마지막으로, 시스템 모니터링의 중요성도 크게 느꼈습니다. 이번 문제가 발생한 배경도 그라파나를 통해 CPU 사용량이 비정상적으로 높은 것을 발견하면서 시작되었거든요. 만약 모니터링이 없었다면 문제를 인지하지 못했을 수도 있고, 성능 이슈로 사내 개발자들의 관심을 끌지 못했을 수도 있었을 겁니다! 결국 시스템을 안정적으로 운영하려면 실시간으로 시스템 상태를 모니터링하고, 이상 증상을 빠르게 파악하는 것이 필수적이라는 교훈을 얻었습니다.
결론
이번 이슈가 종료된 pod의 로그에서만 발생했기 때문에, 해당 pod의 로그만 WebSocket을 사용하지 않는 방법도 고려할 수 있었습니다. 그러나 이런 회피책은 실력 향상에 도움이 되지 않을 뿐만 아니라 좋은 해결책이라고 생각하지 않습니다. 시간적 여유가 없는 상황에서 최후의 수단으로 삼아야 할 방법입니다.
문제의 근본 원인을 해결하는 과정에서 보람을 느꼈으며, 앞으로도 이러한 도전을 통해 제 개발 역량을 발전시킬 것입니다.
긴 글 읽어주셔서 감사합니다
