Production 클러스터에서 p99 지연 4초 반복 발생으로 2주간 총력 대응한 사례입니다. DevOps 팀 3명이 모든 업무를 멈추고 집중한 "지옥의 트러블슈팅" 기록입니다.
문제 발생: Production 성능 이슈
24년 7월 10일 경에 production 클러스터 앱의 성능 이슈가 발생한다는 문의가 들어왔습니다. 이날부터 2주동안, 저를 포함한 DevOps Engineer 3명은 모든 업무를 멈추고 네트워크 이슈 원인 찾기에 돌입하였습니다.
1. 문제 재현을 위한 부하테스트
문제 재현을 위해 k6, Grafana를 이용해 부하테스트를 진행하였습니다.
Grafana로 확인해보니 정말로 특정 노드로 통하는 외부망에서 request duration이 1분 간격으로 4초간 지연이 발생하였습니다.
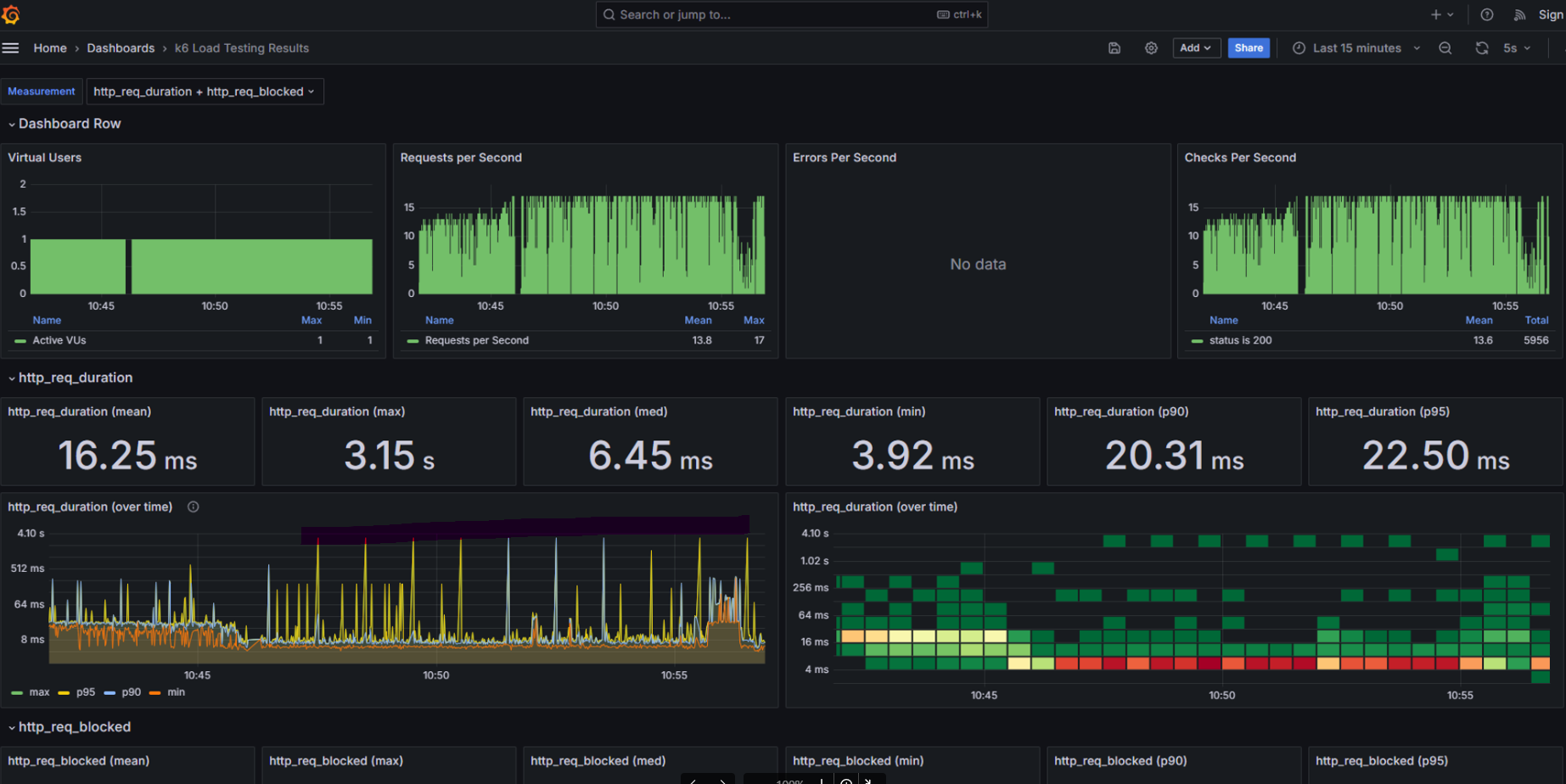
조사 결과: 외부 → 클러스터 특정 노드 경로에서만 발생

2. 원인 분석: MetalLB Layer2 Leader Election 문제
현재 클러스터는 MetalLB Layer2 모드 운영 중:
- Leader Pod가 있는 노드(Leader Node)가 모든 LB 트래픽 수신
- Leader 선출/전환 시 네트워크 불안정 발생MetalLB Leader Node 확인 과정에서 충격적인 현상을 발견했습니다.
leader node를 확인하기 위해 LB의 ip로 arping을 날리면 하나의 MAC address가 아닌 다수의 MAC address가 응답을 하였습니다.
$ arping -I eth0 <LB_VIP>
예상: 단일 Leader Node MAC
실제: 5개 노드의 MAC 주소 동시 응답 😱tcpdump로 패킷 캡처 결과:
GARP 스톰 + Leader 전환 중 ARP 테이블 혼란
src MAC이 LB_VIP에 대해 계속 바뀜Reddit에서 동일 증상 확인
https://www.reddit.com/r/vmware/comments/y68emx/metallb_vmware_multiple_mac_address_associated/
3. 근본 원인: Bitnami MetalLB Helm Chart 버그
이것은 저희가 클러스터에 배포한 bitnami의 metalLB 차트 이상으로 확인되었습니다.
참고: MetalLB Layer2 mode 동작 원리
1. Leader Speaker가 VIP를 ARP로 광고 (단일 MAC) 2. Memberlist Gossip(TCP/UDP 7946)으로 Speaker들끼리 Leader 선출 조율 3. 비-Leader Speaker는 VIP 광고 중단
Bitnami 차트에서 발견된 문제: 여러 Speaker가 동시에 VIP를 광고 → Split-Brain
근본 원인: NetworkPolicy가 Memberlist 차단
문제점은 Speaker 간 Gossip 포트(7946) 미허용하고 있었습니다.
# Bitnami 차트 기존 networkpolicy.yaml
spec:
networkPolicy:
enabled: true
egress:
- ports: # DNS, API Server만 허용
- port: 53 # ❌ 7946/TCP+UDP 누락!Memberlist Gossip 차단으로 인한 결과:
- 각 Speaker가 "내가 Leader"로 오인
- 모든 노드에서 VIP ARP 광고 지속
- arping → 다중 MAC 응답 4. 문제 해결
metallb 공식차트는 7946 포트에서 memberlist를 잘 쓰도록 설계되어 있습니다.
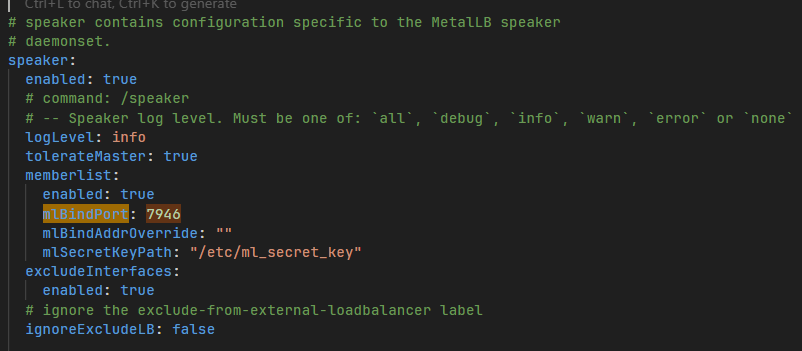
metallb의 차트를 bitnami 에서 배포한 차트에서 공식 차트로 수정하였고 정상적으로 하나의 MAC address가 찍히는 것을 확인할 수 있습니다.

이후 네트워크 이슈가 해결된 것을 부하테스트 결과로 확인할 수 있었습니다. (req_duration이 1s 미만)
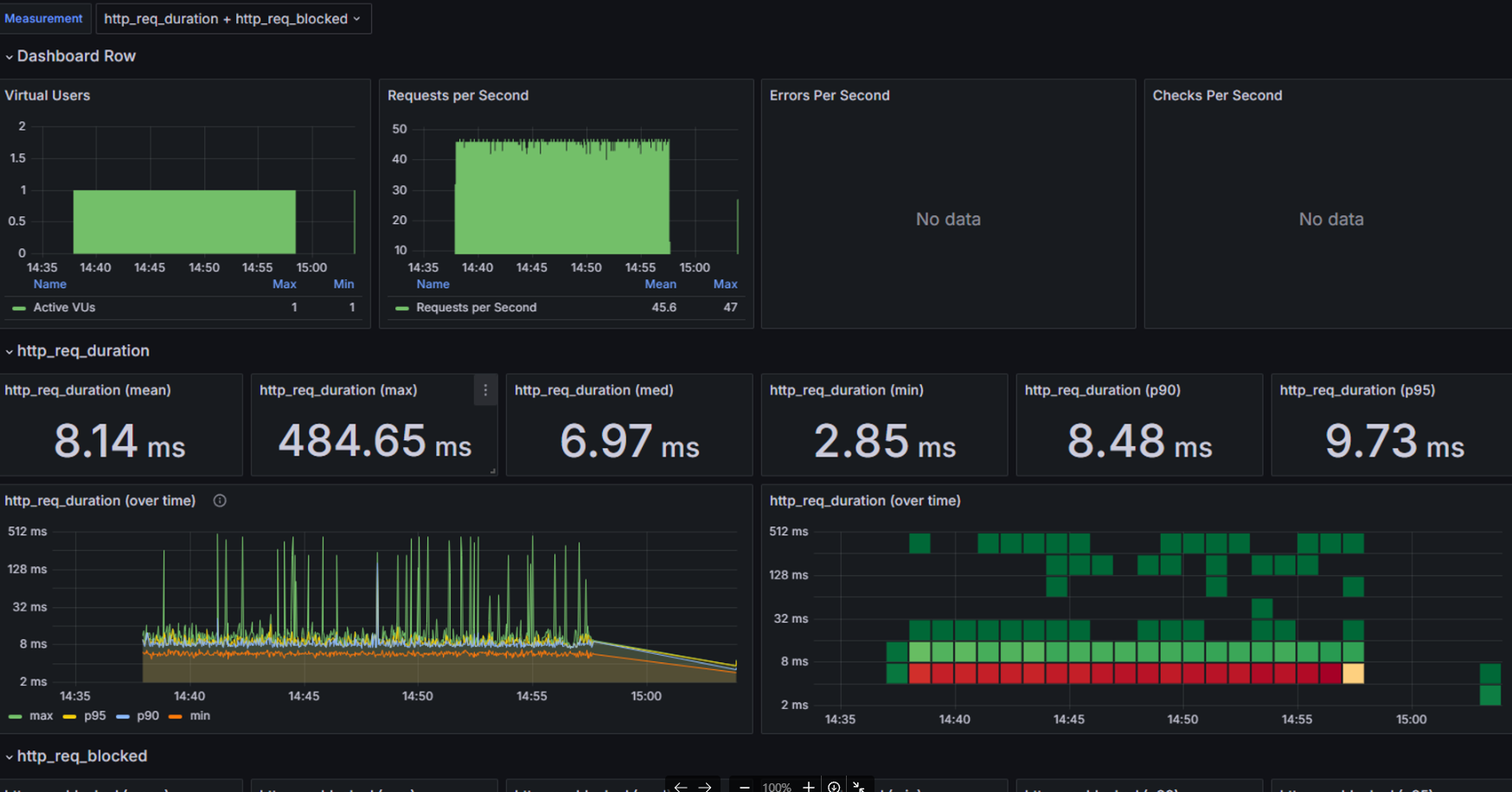
5. 추가 최적화: 모델 다운로드 대역폭 제한
추가로 ai 개발자분들이 모델을 다운로드 받는 시간동안 네트워크 성능이 많이 떨어지는 현상을 확인해 해당 deployment(object storage)에 calico 대역폭 제한을 설정하였습니다.
metadata:
annotations:
kubernetes.io/ingress-bandwidth: 512M
kubernetes.io/egress-bandwidth: 512M이후 네트워크 대역폭이 안정적으로 유지되었고 성능 이슈가 발생하지 않았습니다.
배운점
1. 리눅스의 네트워크 툴과 명령어
$ arping
- arping을 날려 해당 ip가 가진 MAC address 확인
$ tcp_dump
- 네트워크 인터페이스로 들어오는 패킷들을 캡쳐
$ mtr (my traceroute)
- ping + traceroute
- ip로 통신하기 위해 어떤 경로를 사용하는 지 확인할 수 있었음
$ ip neigh show
- 해당 노드가 주변 노드들에 대해 가지는 neighbor ip + MAC address 확인
$ ip route show
- 해당 노드가 가진 라우팅 테이블을 확인, 목적지 ip가 어떤 인터페이스를 통해 전달되는지
2. grafana k6 사용법 숙지
테스트는 grafana + influxdb 로 모니터링을 진행하였고
grafana k6 공식 문서를 살펴보면서 여러가지 테스트 가이드가 있는 걸 확인하였습니다.
그 중에서 최소한의 부하에서도 적절하게 작동하는지 확인하기 위해 smoke test를 진행하였습니다.
3. "bitnami helm 차트는 웬만해선 쓰지 말고 공식 helm 차트를 사용하는 것이 좋다"
처음엔 bitnami의 helm chart가 공식 helm chart를 가져온 것인줄로만 알았는데 이번 기회를 통해 전혀 아님을 확인했습니다.
다행히 현재 클러스터엔 metallb만 bitnami를 사용하는 중이었습니다.
4. calico의 대역폭 제한
쿠버네티스 트래픽 셰이핑 지원을 통해 CNI 플러그인에서 파드 수신 및 송신 트래픽 셰이핑을 지원하는 것을 알게 되었고 이를 클러스터에 적용하였습니다.
