1. Hybrid-Cluster 노드 오토스케일링: Cloud GPU를 자동으로 끌어쓰는 방법
on-prem + GCP 하이브리드 클러스터 구축기-1 에서 왜 Hybrid Cloud가 필요한지, 어떻게 On-prem ↔ Cloud 네트워크를 연결할지, 어떤 VPN 기술을 선택했는지 정리했어요.
이제 다음 과제로 넘어갑니다.
▶ Cloud GPU를 언제, 어떻게 자동으로 끌어 쓸 것인가?
▶ On-prem 기반 K8s에서 Cloud 쪽 Worker Node를 자동 확장할 수 있는가?
즉, Hybrid-Cluster의 핵심 능력인 Node Autoscaling에 대한 테스트를 시작해요.
1.1 GPU 노드 오토스케일링의 필요성
AI workload는 대부분 다음과 같은 패턴을 갖습니다.
- 순간적으로 폭증하는 RPS(Requests Per Second)
- 모델 특성 상 높은 GPU 자원 요구량
- 특정 고객사 업무 시간대 부하 쏠림
- 긴급 분석/파일 처리로 인한 단기적 GPU 필요
실제 운영에서 발생한 주요 문제예요.
| 문제 | 설명 |
|---|---|
| On-prem GPU 부족 | HPA가 스케일아웃하려 해도 GPU 노드가 없어 Pending Pod 발생 |
| 복구 지연 | 장애/업데이트 시 GPU 노드가 가용해질 때까지 시간 소요 |
| 고객 요구사항 미충족 | "갑자기 RPS 2배 이상 증가" 같은 요구 대응 곤란 |
| 비용 이슈 | 온프렘 GPU 증설은 수개월 리드타임 + 초기 투자 ↑ |
결국, 다음 조건을 모두 만족하는 오토스케일링 전략이 필요했습니다.
✔ GPU 부족 시 Cloud에서 자동으로 노드 추가
✔ Pod 생성 요청(HPA 등)에 따라 적시에 동작
✔ 안전한 스케일 인
✔ On-prem 노드에 영향 없어야 함
✔ 네트워크는 이미 구성된 VPN 경로를 그대로 사용
✔ Pod-to-Pod 통신/서비스 Mesh 구조 유지1.2 노드 오토스케일링 연구: 어떤 방식이 있는가?
Hybrid 환경에서 가능한 노드 오토스케일링 기법을 모두 조사했어요.
총 5가지 접근 방식이 검토되었습니다.
📌 오토스케일링 방법 5가지 요약
| 방법 | 장점 | 단점 | 결론 |
|---|---|---|---|
| 1. Virtual Kubelet + Kip | 빠른 확장 / 가상노드 기반 | Kip 유지보수 중단, 안정성 ↓ | ❌ 탈락 |
| 2. Cluster Autoscaler + Cluster API | 완전한 K8s native infra-as-code | 관리 클러스터 필요, 오버엔지니어링 | ❌ 탈락 |
| 3. Cluster Autoscaler + 초기화 Script | 안정적 / Cloud-agnostic / K8s 공식 | 구현 복잡도는 있지만 현실적인 대안 | ✅ 후보 채택 |
| 4. GCP Instance Group Metric Autoscaler | 구성 쉽다 | Cloud 측 metric만 사용 / 제로스케일 불가 | ❌ 탈락 |
| 5. Event-based Scaling (Grafana alert → Pub/Sub → instance scale) | 최대 커스터마이즈 | 관리 복잡, 운영 난이도 ↑ | △ 테스트 가능 |
1.3 각 방법에 대한 정리
1) Virtual Kubelet & Kip
결론: ❌ Kip 유지보수 종료로 채택 불가
가상 노드에 Pod 스케줄 → Kip가 Cloud에서 인스턴스를 생성하는 방식입니다. 하지만 Kip가 더 이상 활성 유지되지 않아 안정성 확보가 불가해 배제했어요.
2) Cluster API (CAPI)
결론: ❌ 운영 난이도 & 새 클러스터 생성 필수 → 오버엔지니어링
Cluster API는 K8s를 K8s로 관리하는 확장된 방식이지만, 이번 프로젝트 규모에는 과하다고 판단되었습니다.
3) Cluster Autoscaler (CA) + 초기화 스크립트
결론: 현실적 + 안정적 + 클라우드 친화적 → 1순위 후보
Cluster Autoscaler는 K8s SIG에서 개발하는 공식 Autoscaler입니다.
Pod Pending 상태를 감지 → Cloud Provider API 호출하며, MIG / ASG / VM 생성이 가능해요.
GCP에서는 MIG(Instance Group)와 자연스럽게 연동되며, 초기화 스크립트로 자동 kubeadm join + label 등록 + providerID 설정까지 처리 가능합니다.
이 방식은 하이브리드 클러스터에서도 완전한 운영이 가능했으며 가장 좋은 결과를 보여 최종 검증 대상이 되었습니다.
4) GCP 인스턴스 그룹 메트릭 기반 Autoscaler
결론: ❌ 간단하지만 Cloud 측 metric에 종속 → 하이브리드 부적합
온프렘 기준 metric(HPA, Prometheus)을 사용할 수 없어서 제외했습니다.
5) 이벤트 기반 스케일링
결론: 매우 유연하지만 관리 난이도 매우 높음 → 부가적 전략으로 활용 가능
Grafana alert → webhook → GCP pub/sub → MIG scale-out 흐름으로 조건 조합이 가능하지만, 운영 복잡도가 높아 보조적 활용이 적합해요.
1.4 Cluster Autoscaler로 승부 보기
이번 프로젝트는 다음 목표를 기준으로 테스트를 설계하였습니다.
✔ 검증 목표
| 검증 항목 | 설명 |
|---|---|
| 노드 스케일 아웃 | Pod pending 시 MIG가 정상적으로 VM 생성하는가 |
| 노드 스케일 인 | VM 제거 시 Pod 안전 이동이 가능한가 |
| GPU Pod 운용 | GPU workload에도 Autoscaling 동작하는가 |
| On-prem 영향 | 온프레미스 노드를 절대 변경하지 않는가 |
| HPA 연동 | HPA / KEDA 등 상위 autoscaler와 함께 동작하는가 |
| 네트워크 | Cloud Pod ↔ On-prem Pod ↔ 외부 통신 정상 여부 |
| 비용 | 스케일인/아웃 기준 최적화 가능성 |
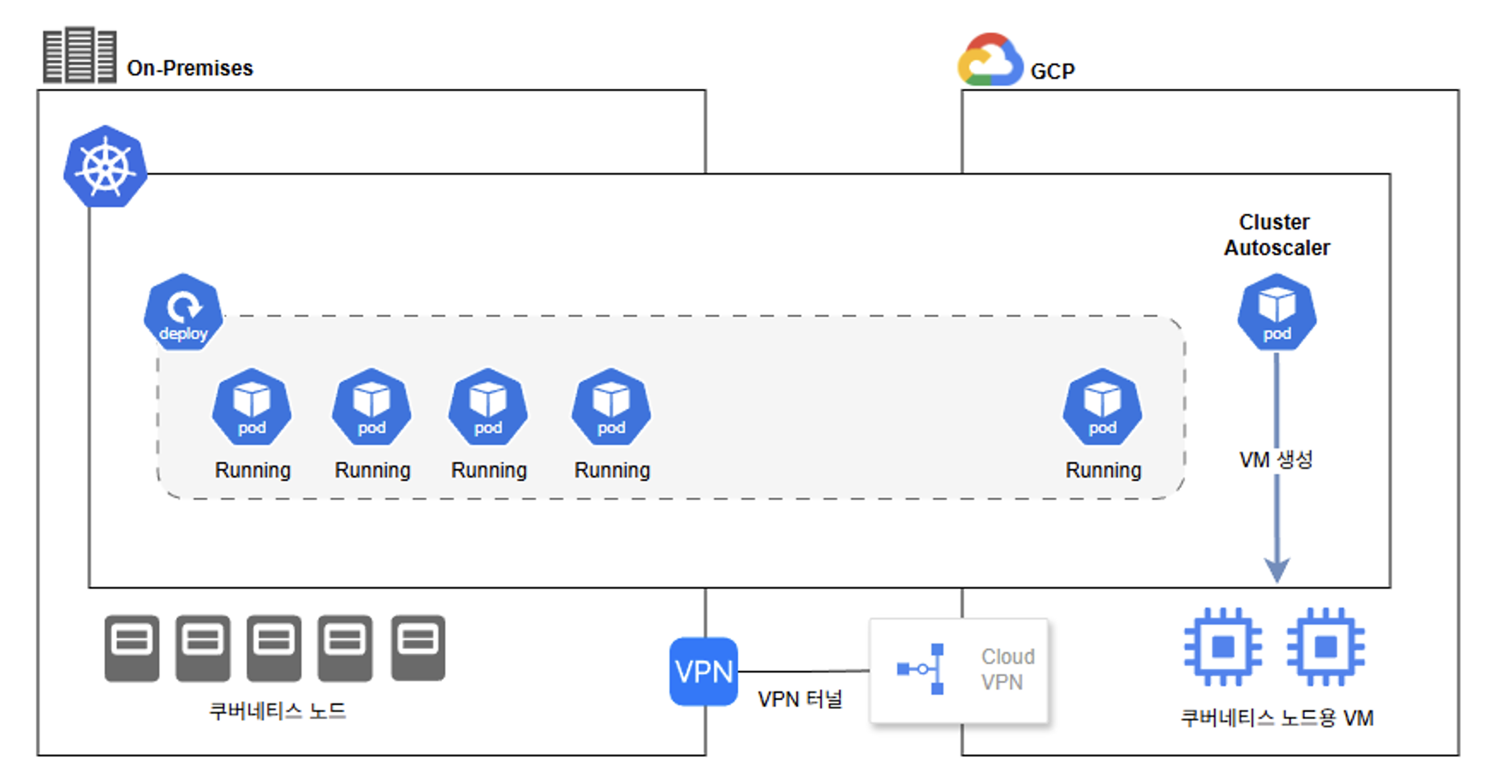
1.5 환경 구성
구성 요소
- On-prem K8s Cluster (Control Plane + worker)
- Cloud MIG + GPU 인스턴스 or CPU 인스턴스
- S2S VPN (strongSwan ↔ Cloud VPN)
- Calico CNI / Istio Service Mesh
- Cluster Autoscaler (v1.33)
- Prometheus / Grafana / HPA / KEDA
구성도
노드 확장 시나리오
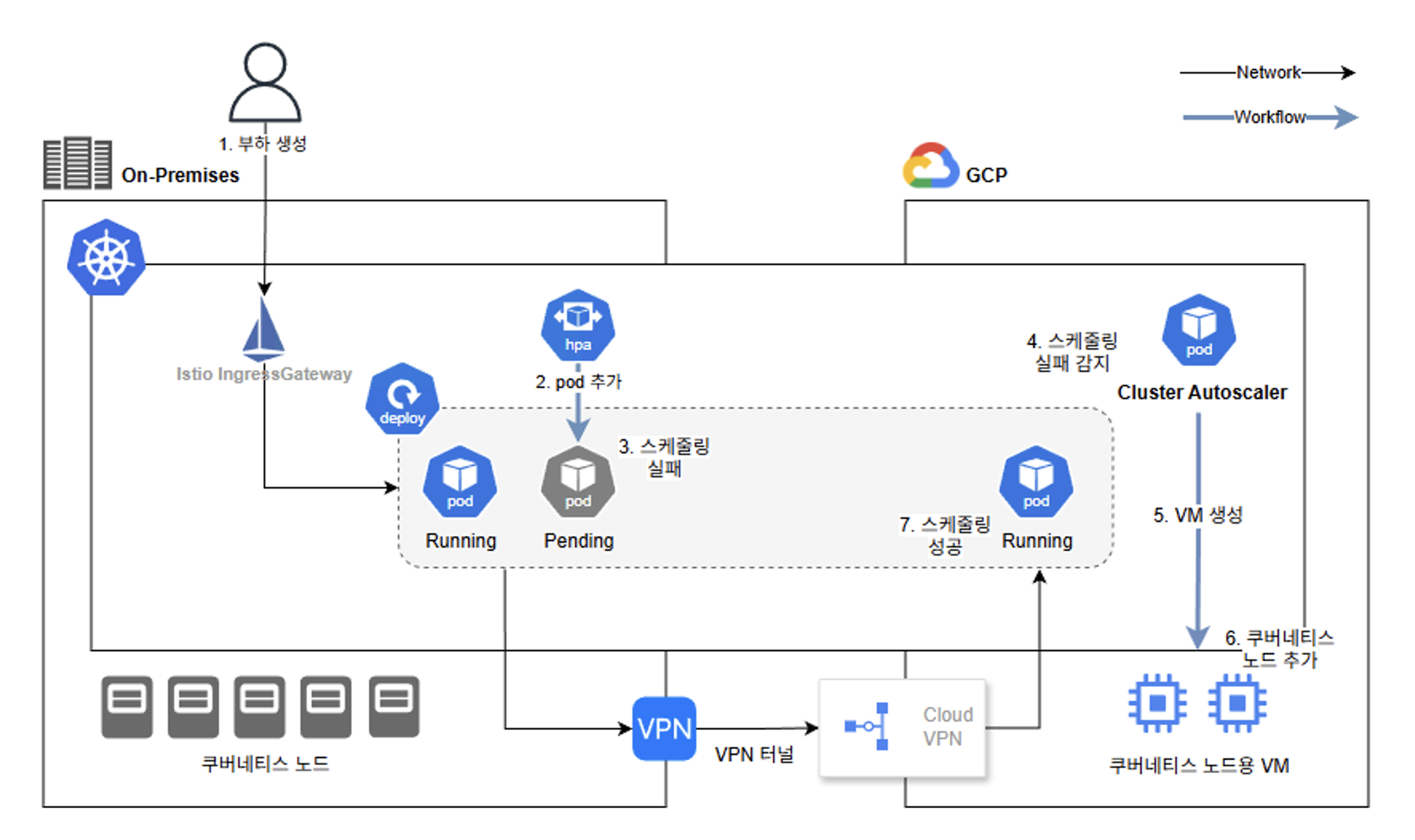
1.6 주요 테스트 결과 요약
✔ 1) 노드 스케일 아웃: 성공
Pending Pod 발생 시 MIG가 자동으로 VM 생성 + kubeadm join 성공했습니다.
✔ 2) 노드 스케일 인: 성공
PDB(pod disruption budget) 설정 시 다운타임 없이 안전하게 스케일 인 성공했어요.
✔ 3) GPU Pod Autoscaling: 성공
CA의 scale-down-gpu-utilization-threshold로 GPU 기준 스케일 인이 정상 작동합니다.
✔ 4) On-prem 영향 없음
Cluster Autoscaler가 MIG에 속하지 않은 온프레미스 노드는 절대 제거하지 않습니다.
✔ 5) HPA / KEDA 연동: 정상
HPA로 Pod 확장 → Pod pending → CA 노드 확장 → 부하 감소 → HPA 축소 → CA 지연 후 노드 스케일 인 순서로 동작해요.
✔ 6) 네트워크: 정상
Cloud Pod ↔ On-prem Pod ↔ 사무실 클라이언트 통신 성공하며, Istio mTLS, proxy-init 정상 작동합니다.
1.7 테스트 결론
Hybrid-Cluster 환경에서도 K8s Cluster Autoscaler를 기반으로 Cloud Node 자동 확장이 충분히 실현 가능합니다.
장점
- K8s native 방식 → 기존 운영이 크게 변하지 않습니다
- HPA/KEDA와 자연스럽게 연동돼요
- GPU workload에도 정상 작동합니다
- 온프레미스 노드 영향 없음
- 안정적이고 예측 가능한 스케일링
단점 / 개선 포인트
- 신규 노드 초기화 시간 최적화 필요
- Cloud 모니터링 체계 필요
2. 추후..
다음 게시글 on-prem + GCP 하이브리드 클러스터 구축기 - 3 에서는 이번 검증을 거치면서 실제로 겪었던 이슈와 해결 방법 그리고 실제 Hybrid-Cluster 운영 전략을 정리합니다.
