0. 이전 글 요약
on-prem + GCP 하이브리드 클러스터 구축기-2 에서의 Hybrid-Cluster 노드 오토스케일링 도입은 다음 질문에서 출발했습니다.
"On-prem GPU가 부족해지는 순간, Cloud GPU 노드를 자동으로 끌어쓸 수 있을까?"
이를 검증하기 위해 우리는 "온프레미스 k8s 클러스터"와 "GCP Cloud 노드"를 하나의 "하이브리드 클러스터"로 묶고, Cluster Autoscaler 기반 자동 확장 기능이 실제로 운영 가능한 수준인지 테스트 했어요.
다음 내용은 그 과정에서 실제로 부딪힌 문제들과 이를 해결해 운영 수준으로 끌어올린 방식을 정리한 것입니다.
1. 테스트 과정에서 마주친 문제들
하이브리드 환경에서 Autoscaling을 구현하는 일은 생각보다 손쉽게 흘러가지 않았어요.
실제 운영에서 사용되려면 아래와 같은 문제들이 반드시 해결되어야 했습니다.
이 섹션에서는 그중 핵심이었던 3가지 난제를 소개합니다.
| 문제 | 원인 | 해결 |
|---|---|---|
| Cluster Autoscaler 전용 노드 필요 | GCP metadata 접근 필요 / CA 중단 시 스케일 로직 마비 | 전용 CPU 노드에 CA 고정 배치 |
| GPU 노드 중복 스케일업 | 드라이버 초기화 중 Pod 스케줄 불가 → CA가 추가 스케일업 | startup taint + GPU validator 기반 taint remover |
| MIG kube-env와 실제 노드 mismatch | CA는 kube-env 기반으로 시뮬레이션 수행 | kube-env와 init-script 동기화 |
1.1 Cluster Autoscaler는 결국 '전용 노드'가 필요하다
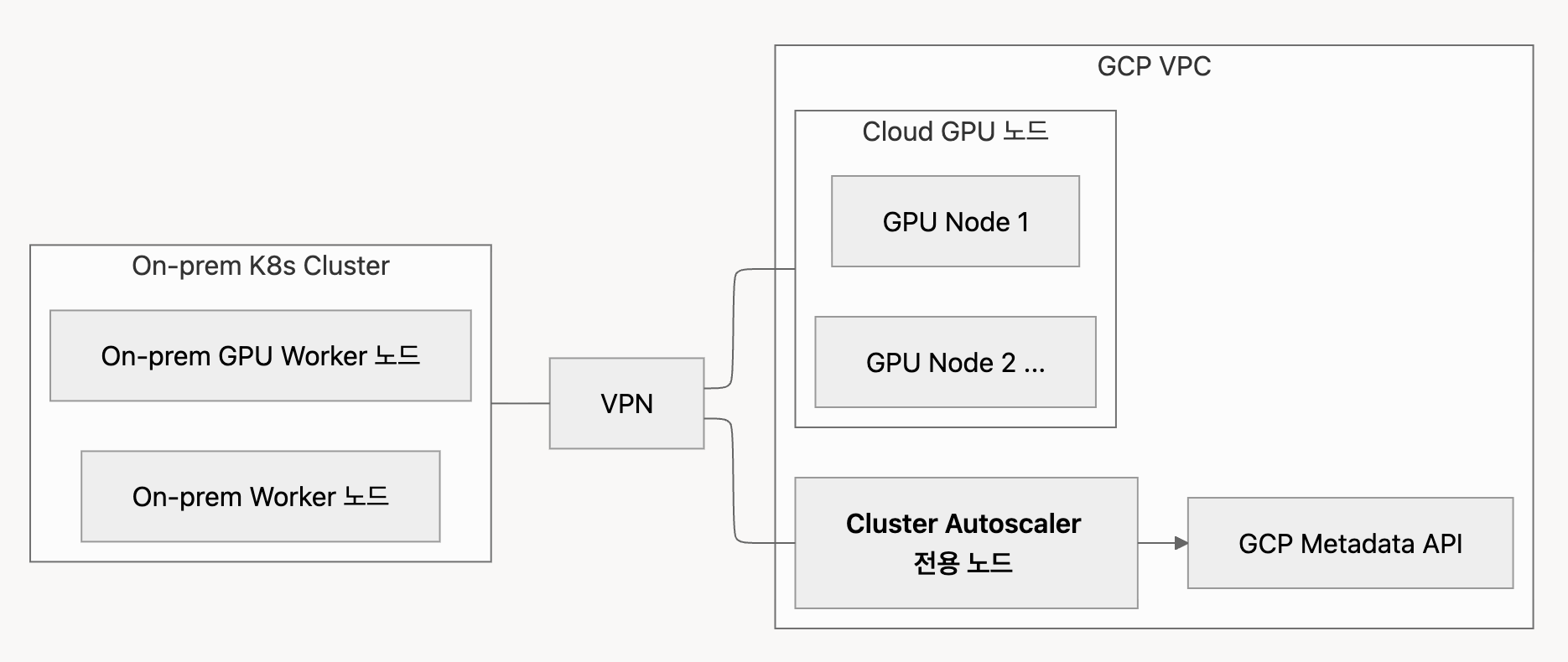
초기 설계에서는 On-prem 노드에 Cluster Autoscaler(CA)를 띄우면 되겠다고 판단했어요.
하지만 아래와 같은 문제가 드러났습니다.
문제 1. Cluster Autoscaler는 GCP Metadata 서버와 통신해야 합니다
Cluster Autoscaler(GCE Provider)는 아래 API들을 계속 호출합니다.
- MIG 상태 조회 (인스턴스 개수 / 준비 상태)
- 인스턴스 그룹 resize 요청
- health check API
- node template 추출을 위한 metadata 조회
하지만 GCP Metadata 서버는 VPC 내부에서만 접근 가능하며, On-prem에서는 접근할 수 없습니다.
즉, Cluster Autoscaler가 On-prem에 있으면 Cloud Provider 기능이 정상 동작할 수 없어요.
해결: Cluster Autoscaler는 반드시 '전용 클라우드 노드'가 필요합니다
아래 기준으로 ClusterAutoscaler를 배치했습니다.
✔ 클라우드에 생성된 하나의 노드
✔ GPU 노드가 아닌 순수 CPU 노드
✔ eviction 방지를 위한 taint/toleration 구성
✔ 안정적 네트워크 환경(Cloud Metadata 접근 가능한 환경)
Cluster Autoscaler는 안정성을 최우선으로 하는 핵심 시스템이므로 반드시 전용 노드에서 운영해야 합니다.
1.2 GPU 노드의 중복 스케일업 문제 → Startup Taint + Taint Remover 도입
테스트 과정 중 가장 골칫거리는 다음 문제였어요.
문제: GPU 노드는 1개만 필요하지만, 2개 이상 생성되는 현상
원인: GPU Driver 초기화가 오래 걸립니다
Cloud GPU 노드가 생성되면 GPU Operator의 init 과정이 다음 순서로 진행됩니다.
- GPU 드라이버 설치
- gpu-operator-validator 컨테이너 실행
- GPU 장치 인식 확인
- GPU를 kubernetes에서 사용할 수 있게 됨
이 과정은 수십 초 ~ 수 분까지 걸릴 수 있으며, 초기화 중에는 Pod가 이 노드에 할당될 수 없어요.
그런데 Cluster Autoscaler는 이 상태를 보고 이렇게 판단합니다:
"아직 스케줄 가능한 GPU 노드가 없구나 → 하나 더 늘리자"
그 결과 중복 스케일업이 발생합니다.
해결책: Cluster Autoscaler의 Startup Taint 기능 활용
ClusterAutoscaler는 다음 prefix의 taint가 붙은 노드를 "아직 준비 중이지만 존재하는 노드"로 인식합니다.
startup-taint.cluster-autoscaler.kubernetes.io/*따라서 다음 전략을 사용했어요.
- 노드가 join되는 시점에 startup taint를 자동 부여
- GPU 드라이버 설치 완료 후 → taint 제거
- CA는 이 taint가 붙은 노드를 "이미 스케일업된 노드"로 인식
- 결과적으로 중복 스케일업 방지
문제: taint 제거를 누가, 언제, 어떻게 수행할 것인가?
포인트는 GPU가 정상 인식되기 전에는 절대 taint를 제거하면 안 된다는 점입니다.
이 로직을 어디에 넣을지 결정하는 데 많은 시간이 걸렸어요.
최종 해결: Taint Remover DaemonSet 생성
gpu-operator-validator는 원래 init containers의 결과를 판정하고 성공하면 무한 sleep 상태에 들어갑니다.
저는 gpu-operator-validator의 이미지를 이용하여 startup taint를 제거하도록 직접 개발했습니다.
- 원래 gpu-validator 동작을 그대로 수행합니다
- GPU 장치 목록을 조회합니다
- 정상 인식 시 startup taint 제거합니다
- 클라우드 GPU 노드에만 스케줄링됩니다
장점
✔ GPU driver 설치 라이프사이클과 완벽하게 동기화됩니다
✔ 노드 초기화 → 드라이버 설치 → gpu-operator-validator → taint 제거 이 전체 흐름이 하나로 연결돼요
최종적으로 GPU 노드 스케일링부터 Taint 제거는 다음과 같은 시나리오로 동작합니다.
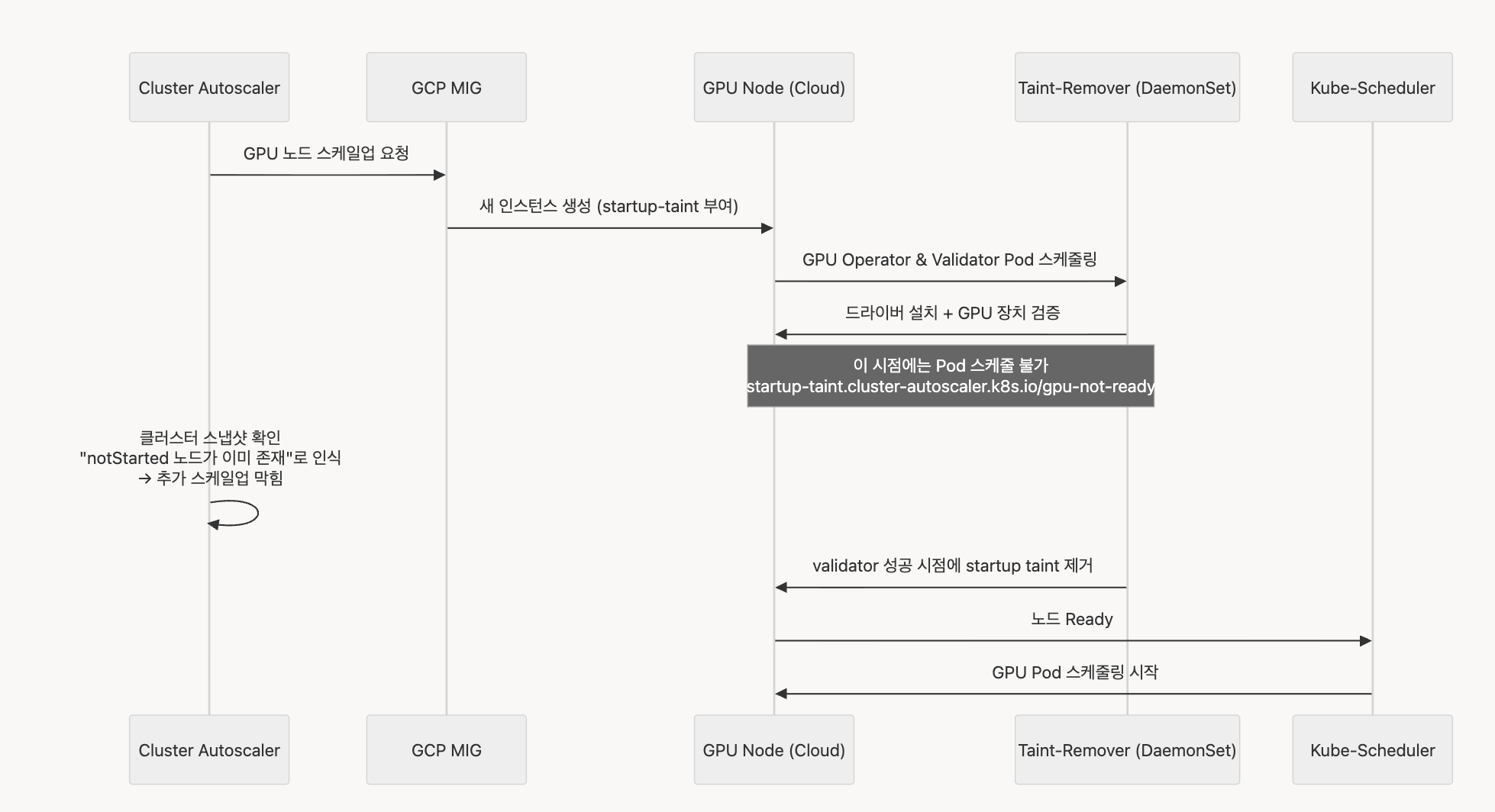
- GPU 노드 스케일업 요청: Cluster Autoscaler가 GCP MIG에 GPU 노드 생성을 요청합니다.
- 새 인스턴스 생성: GCP MIG가 startup-taint가 부여된 상태로 새 인스턴스를 생성합니다.
- GPU Operator & Validator Pod 스케줄링: 새 노드에 GPU Operator와 Validator Pod이 스케줄됩니다.
- 드라이버 설치 및 GPU 장치 검증: Taint-Remover가 드라이버 설치 및 GPU 장치 검증을 수행합니다.
- 초기화 진행 중: 이 시점에는 Pod 스케줄이 불가능합니다(
startup-taint.cluster-autoscaler.k8s.io/gpu-not-ready). - 클러스터 스냅샷 확인: Cluster Autoscaler가 클러스터 상태를 확인하고 "notStarted 노드가 이미 존재"한다고 인식하여 추가 스케일업을 막습니다.
- Startup Taint 제거: validator 성공 시점에 Taint-Remover가 startup taint를 제거합니다.
- 노드 Ready: 노드가 Ready 상태가 됩니다.
- GPU Pod 스케줄링 시작: Kube-Scheduler가 GPU Pod 스케줄링을 시작합니다.
1.3 GCP MIG의 kube-env와 실제 노드 설정이 일치해야 한다
이 이슈의 구조를 정리하면 다음과 같습니다.
설정 관리 흐름: Instance 초기화 script가 "taint, label 적용해서 join"을 통해 Cloud GPU Node에 설정을 적용합니다.
ClusterAutoscaler가 보는 세계:
- MIG Instance Template (kube-env)는 "scale-from-zero 시 템플릿 노드 생성"합니다.
- Cloud GPU Node는 "이미 존재하는 노드 기준 템플릿 노드 생성"합니다.
- 이 둘이 Cluster Autoscaler와 상호작용합니다.
ClusterAutoscaler가 MIG를 스케일아웃할지 말지 판단할 때는 "템플릿 노드"를 생성해 시뮬레이션을 합니다.
이때 template node는 다음 우선 순위로부터 생성됩니다.
- 이미 존재하는 healthy cloud node 기반
- ClusterAutoscaler 내부 캐시 기반
- MIG instance template의 kube-env 기반 ← scale-from-zero 상황에서 필수
문제: MIG kube-env와 실제 노드 설정이 다를 수 있습니다
예시 상황: taint mismatch
- MIG template의 kube-env에는
newen.ai/gcp=true - 실제 노드에는 label 적용 안함
- → ClusterAutoscaler는 "이 nodegroup은 taint 때문에 unschedulable"로 판단
- → scale-out 실패
해결 전략: kube-env 싱크 관리
아래 조치를 적용했습니다.
✔ MIG kube-env를 init-script와 100% 동일하게 유지
✔ label/taint/env 설정을 하나의 source에서만 관리
즉, MIG template의 kube-env는 CA 입장에서 절대적 진실(single source of truth)이므로 이를 맞추는 것이 스케일 업/다운의 핵심 안정성 기준이었습니다.
2. VPN Gateway 고가용성(HA) 구성
Cluster Autoscaler를 통한 노드 자동 확장 기능이 안정적으로 동작하게 되면서 새로운 과제가 대두되었어요.
바로 On-prem과 Cloud 간의 네트워크 연결을 담당하는 VPN Gateway의 장애 대비입니다.
테스트 단계에서는 strongSwan 기반 S2S VPN으로 단일 VPN 게이트웨이를 운영했지만, 실제 프로덕션 환경에서는 VPN Gateway 자체가 단일 장애점(Single Point of Failure)이 될 수 밖에 없습니다.
온프렘에 있는 Control-plane과 통신을 못하면 node가 NotReady 상태가 되기때문이죠.
다음 게시물에서는 VPN Gateway의 고가용성을 확보하기 위해 검토한 여러 HA 기법과, 최종적으로 선택하게 된 솔루션, 그리고 이를 통해 하이브리드 클러스터의 안정성을 한 단계 끌어올린 방식을 다뤄볼 예정입니다.
