0. 이전 글 요약
운영 환경에서 VPN 게이트웨이가 단일 장애 지점(SPOF)이 되면 어떻게 될까?
이전 글에선 PoC 과정에서의 세 가지 어려웠던 점을 어떻게 풀어나갔는지에 대해 설명했습니다.
- Cluster Autoscaler 전용 노드 필요성: GCP Metadata API 접근을 위해 클라우드 내 전용 CPU 노드 배치
- GPU 노드 중복 스케일업 방지: Startup Taint + 커스텀 Taint Remover DaemonSet으로 드라이버 초기화 시간 동안의 중복 생성 차단
- MIG kube-env 동기화: 템플릿 노드 시뮬레이션의 기준이 되는 kube-env를 실제 노드 설정과 100% 일치시켜 스케일링 안정성 확보
이 글에선 "실제 운영에 필요한 HA 구성을 어떻게 했는가"에 대해 다룰게요.
1. VPN HA, 왜 필요한가?
하이브리드 클러스터 [2]에서 구축한 strongSwan 기반 Site-to-Site VPN은 하나의 게이트웨이 노드로 운영되고 있었어요.
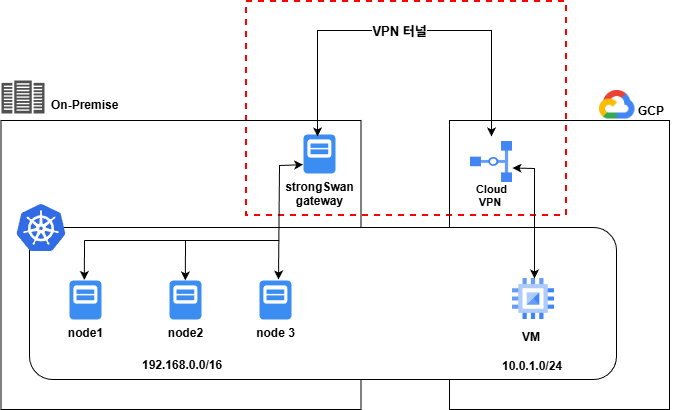
이 구조에는 치명적인 문제가 있었습니다.
| 장애 시나리오 | 영향 |
|---|---|
| 게이트웨이 노드 다운 | 전체 하이브리드 통신 중단 |
| VPN 프로세스 장애 | Cloud GPU 노드 접근 불가 |
| 네트워크 인터페이스 장애 | 서비스 연속성 상실 |
특히 Cloud GPU가 실제 워크로드를 처리하는 중이라면, VPN 게이트웨이 장애는 곧 서비스 장애를 의미해요. GPU 노드에서 학습이나 추론이 진행되고 있는데 VPN이 끊기면, 그 작업은 그대로 중단되는 거예요.
1.1 운영 환경에서 요구되는 안정성 수준
이를 해결하기 위해 아래와 같은 요구사항을 정의했습니다.
| 요구사항 | 목표 |
|---|---|
| 자동 장애 복구 | 수동 개입 없이 자동 Failover |
| 복구 시간 | 10초 이내 통신 재개 |
| 투명한 복구 | 애플리케이션 레벨에서 인지 불가 |
| 운영 단순성 | 복잡한 관리 컴포넌트 최소화 |
핵심은 "장애가 발생해도 사람이 개입하지 않아도 되는 구조"를 만드는 것이었어요.
2. HA 구성 방안: 두 가지 후보
VPN HA를 구성하는 방법은 여러 가지가 있지만, 우리 환경에 적용 가능한 두 가지 방안을 후보로 선정했습니다.
2.1 방안 A: BIRD + BGP 기반 (Active-Active)
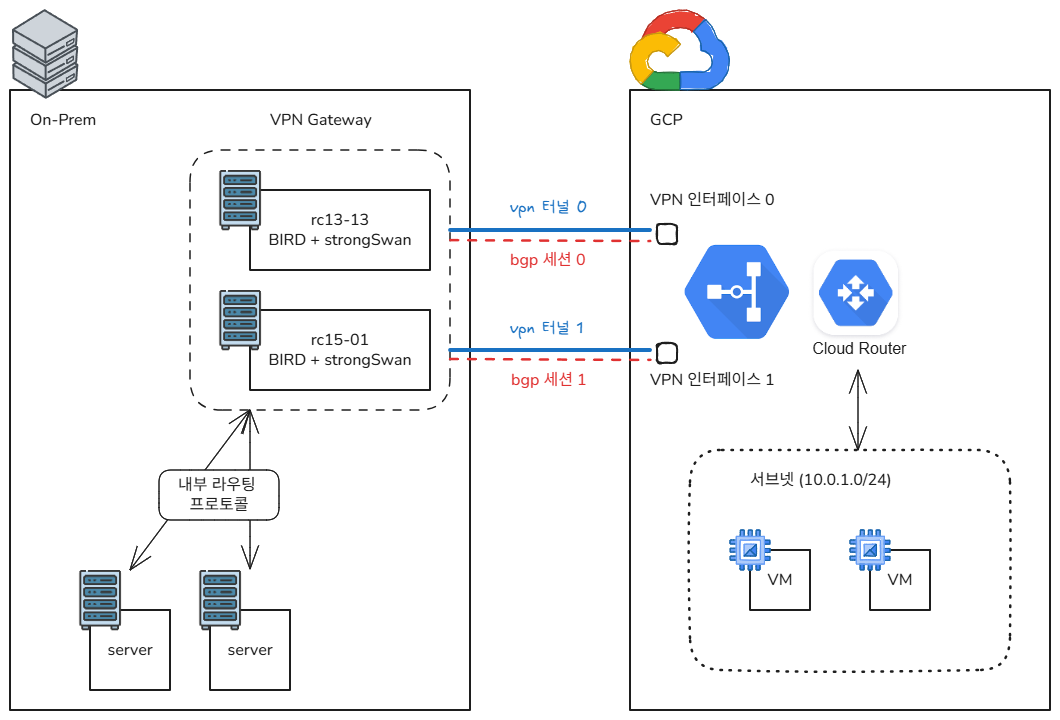
첫 번째 방안은 GCP HA VPN + Cloud Router + BIRD를 조합하는 거예요.
핵심 구성 요소:
- GCP HA VPN: 이중 터널을 자동으로 제공하며 99.99% SLA를 보장합니다
- Cloud Router: BGP 기반 동적 라우팅을 처리합니다
- BIRD: On-prem 측에서 BGP 세션을 관리하는 데몬입니다 (ASN: 65001)
- xfrm 인터페이스: 라우트 기반 VPN을 위한 가상 인터페이스예요
두 개의 게이트웨이가 동시에 트래픽을 처리하는 Active-Active 구조로, BGP를 통해 동적으로 라우팅 경로를 관리해요.
2.2 방안 B: Keepalived + VRRP 기반 (Active-Standby)
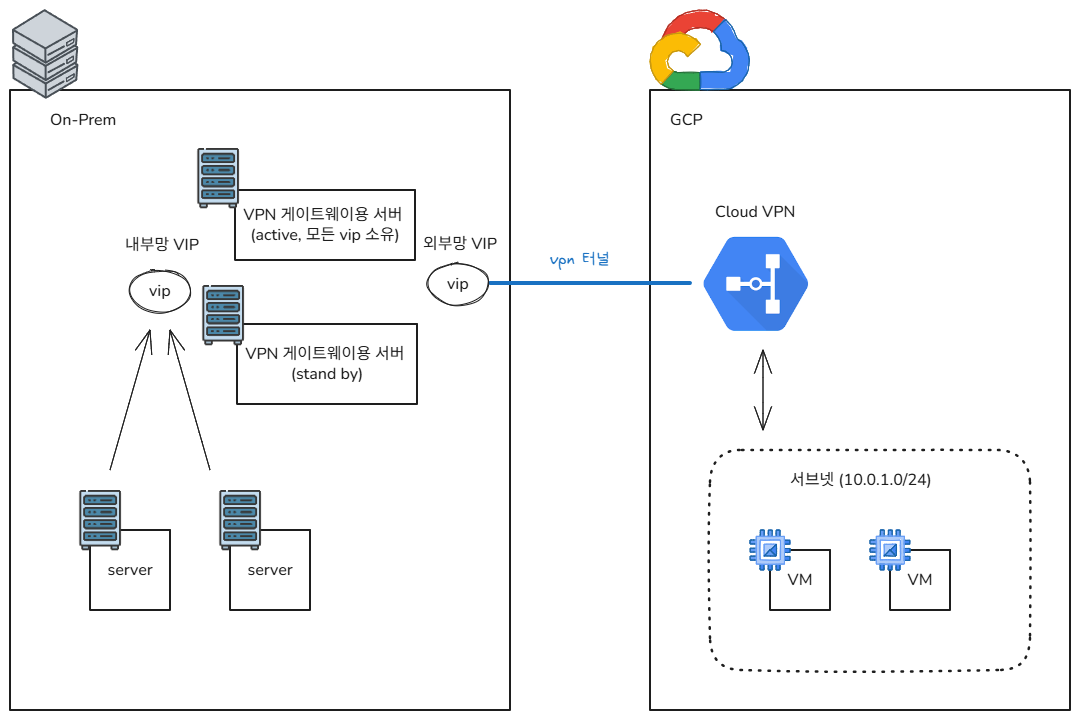
두 번째 방안은 GCP Classic VPN + Keepalived + strongSwan HA Plugin을 조합하는 거예요.
핵심 구성 요소:
- GCP Classic VPN: 정적 라우팅 기반으로 99.9% SLA를 보장해요
- Keepalived: VRRP 프로토콜로 VIP(Virtual IP)를 관리해요
- strongSwan HA Plugin: IKE/CHILD SA를 실시간으로 복제해요
- 내부망 VIP:
192.168.1.47(워커 노드 게이트웨이) - 외부망 VIP:
203.251.205.87(GCP VPN 피어 주소)
하나의 게이트웨이가 트래픽을 처리하고, 장애 시 대기 노드가 즉시 승격하는 Active-Standby 구조예요.
3. 두 방안의 상세 비교
3.1 기술적 비교
| 항목 | 방안 A: BIRD + BGP | 방안 B: Keepalived + VRRP |
|---|---|---|
| 프로토콜 | BGP (Border Gateway Protocol) | VRRP (Virtual Router Redundancy Protocol) |
| GCP VPN | HA VPN (이중 터널) | Classic VPN (단일 터널) |
| HA 컴포넌트 | Cloud Router + BIRD | Keepalived + strongSwan HA Plugin |
| 구조 | Active-Active | Active-Standby |
| 라우팅 방식 | 동적 (BGP Advertisement) | 정적 (수동 설정) |
| VIP 필요 | ❌ 불필요 | ✅ 필요 (내부망 1개 + 외부망 1개) |
| 위치 제약 | ❌ 없음 | ✅ 같은 랙/L2 세그먼트 필요 |
언뜻 보면 방안 A가 모든 면에서 우월해 보입니다. 하지만 "기술적으로 우월한 것"과 "운영에 적합한 것"은 다른 문제예요.
3.2 운영 복잡도 비교
방안 A (BIRD)의 복잡도
방안 A는 관리해야 할 컴포넌트가 많아요.
- GCP Cloud Router: BGP 세션 관리, prefix advertisement
- GCP HA VPN: 이중 터널 상태 모니터링
- BIRD 데몬: BGP 설정, 라우팅 정책
- xfrm 인터페이스: 재부팅 시 자동 복구 스크립트
- 워커 노드 라우팅: ECMP 기반 경로 관리
장애가 발생하면 디버깅도 쉽지 않아요.
Cloud Router 장애 → BGP 세션 단절 → 라우팅 재수렴
BIRD 프로세스 다운 → 로컬 BGP 세션 끊김
xfrm 인터페이스 누락 → 터널 통신 불가무엇보다 BGP 프로토콜에 대한 이해, BIRD 설정 문법, 라우팅 테이블 디버깅 능력이 모두 필요해요. 러닝 커브가 상당했어요.
방안 B (Keepalived)의 단순성
반면 방안 B는 관리 포인트가 세 가지로 줄어듭니다.
- Keepalived: VRRP hello 패킷 (1초 간격)
- strongSwan + HA Plugin: SA 복제
- Health Check 스크립트: VPN 상태 감지
장애 시 동작 흐름도 단순해요.
MASTER 노드 다운 → VRRP 감지 → VIP 이동 → Failover 완료가장 큰 장점은 우리 팀이 이미 프록시 서버에서 Keepalived를 운영 중이라는 거예요. Health Check 스크립트만 커스터마이징하면 됐어요.
3.3 성능 및 안정성 비교
| 측정 항목 | BIRD + BGP | Keepalived + VRRP |
|---|---|---|
| Failover 시간 | 15초 | 5초 |
| 평균 대역폭 | 800 Mbps | 790 Mbps |
| 장애 감지 방법 | BGP keepalive + VPN DPD | VRRP hello (1초) + Health Check |
| 무중단 Failover | ✅ 가능 (BGP 재수렴) | ⚠️ VIP 이동 중 순간 단절 |
| 대역폭 확장 | ❌ 불가 (인프라 제약) | ❌ 불가 (Active-Standby) |
Active-Active 구조인 방안 A가 무중단 Failover에서는 유리하지만, Failover 시간 자체는 오히려 방안 B가 3배 빠른 5초를 기록했어요. BGP 재수렴에 시간이 걸리기 때문이에요.
대역폭은 두 방안 모두 약 800Mbps로 거의 동일했어요. Active-Active의 대역폭 이점은 우리 인프라 환경에서는 제한적이었어요.
3.4 비용 비교
| 항목 | HA VPN (방안 A) | Classic VPN (방안 B) |
|---|---|---|
| VPN 게이트웨이 | $0.075/시간 × 2터널 = $108/월 | $0.075/시간 = $54/월 |
| Cloud Router | 필요 (약 $10/월) | ❌ 불필요 |
| 데이터 전송 | $0.19/GB | $0.19/GB |
| SLA | 99.99% (연간 52분 down) | 99.9% (연간 9시간 down) |
방안 B는 방안 A 대비 월 $64, 연간 $768을 절감할 수 있었습니다.
3.5 Cloud Bursting 환경 특성 고려
여기서 한 가지 더 고려한 점이 있습니다. 우리의 하이브리드 클러스터는 "필요할 때만 Cloud GPU를 사용"하는 Cloud Bursting 구조라는 점이에요.
| 특성 | 영향 |
|---|---|
| 간헐적 트래픽 | 24시간 고트래픽 환경이 아님 |
| 워크로드 패턴 | GPU 부족 시에만 Cloud 확장 |
| 네트워크 요구 | 복잡한 멀티패스 라우팅 불필요 |
| 운영 우선순위 | 고가용성 > 대역폭 확장성 |
Active-Active의 핵심 장점인 병렬 트래픽 처리와 대역폭 확장은 우리 환경에서는 실효성이 낮았어요. 상시 대량 트래픽이 흐르는 환경이 아니기 때문이에요. 오히려 라우팅 복잡도만 증가시키는 결과가 될 수 있었어요.
4. 최종 선택: Keepalived + VRRP
4.1 선택 근거
종합적으로 판단했을 때, 방안 B(Keepalived + VRRP)가 우리 환경에 더 적합했습니다. 선택 근거를 정리하면 다음과 같습니다.
✅ 단순성과 신뢰성
복잡도 감소 → 장애 지점 감소 → 운영 안정성 향상
| 요소 | 개선 효과 |
|---|---|
| 관리 컴포넌트 수 | 5개 → 3개 |
| 설정 복잡도 | 높음 → 낮음 |
| 디버깅 난이도 | BGP 라우팅 분석 → VIP 상태 확인 |
| 운영 경험 | 신규 학습 필요 → 기존 활용 중 |
운영에서 가장 위험한 것은 "복잡해서 아무도 손댈 수 없는 시스템"입니다. 단순할수록 장애 지점이 줄고, 장애가 발생해도 빠르게 원인을 파악할 수 있습니다.
✅ 기존 인프라 활용
우리는 이미 프록시 서버에서 Keepalived를 운영 중이었어요. 이 점이 결정적이었어요.
현재 프록시 구조:
- proxy-active: VIP 소유
- proxy-standby: VIP 대기
VPN 게이트웨이 통합:
- proxy-standby → VPN MASTER (rc13-13)
- proxy-active → VPN BACKUP (rc15-01)두 노드가 이미 같은 랙에 위치하고 있어 VIP 공유가 가능했고, Keepalived 운영 경험이 있으니 러닝 커브가 사실상 제로였어요. 기존 모니터링/알림 체계도 그대로 재사용할 수 있었어요.
✅ 충분히 빠른 Failover
| 요구사항 | 목표 | 실제 성능 | 판정 |
|---|---|---|---|
| 자동 복구 | 수동 개입 없음 | ✅ VRRP 자동 전환 | 충족 |
| 복구 시간 | 10초 이내 | ✅ 4~5초 | 초과 달성 |
| 투명성 | 애플리케이션 인지 불가 | ✅ TCP Keep-Alive 재시도 내 | 충족 |
여기서 strongSwan HA Plugin의 역할이 컸어요. VPN 세션(SA)을 실시간으로 복제하기 때문에, Failover 시 IKE/IPsec 세션을 처음부터 재수립할 필요가 없어요. 이 덕분에 4~5초라는 빠른 복구 시간을 달성할 수 있었습니다.
✅ 비용 효율성
| 항목 | 연간 절감 |
|---|---|
| VPN 게이트웨이 | $648 |
| Cloud Router | $120 |
| 총 절감 | $768/년 |
99.9% SLA도 우리 환경에 충분했어요. 연간 최대 다운타임이 9시간이지만, Cloud GPU는 간헐적으로만 사용하고, 온프레미스 우선 정책이기 때문에 실질적인 영향은 미미했어요.
5. HA Failover 테스트 결과
마지막으로 실제 Failover 테스트를 수행한 결과를 공유할게요. 세 가지 장애 시나리오를 시뮬레이션했습니다.
| 시나리오 | 패킷 손실 기간 | 복구 방식 |
|---|---|---|
| MASTER 노드 완전 다운 | 약 5초 | VRRP가 VIP 이동 → BACKUP이 MASTER로 승격 |
| strongSwan 프로세스 장애 | 약 5초 | Health Check 실패 → Keepalived가 VIP 반납 |
| 네트워크 인터페이스 다운 | 약 3초 | VRRP hello 패킷 미수신 → 즉시 Failover |
세 가지 시나리오 모두 10초 이내에 자동 복구가 이루어졌으며, 특히 네트워크 인터페이스 다운의 경우 VRRP가 hello 패킷을 즉시 감지하지 못하기 때문에 3초 만에 Failover가 완료되었습니다.
모든 시나리오에서 수동 개입 없이 자동 복구가 이루어졌고, 목표했던 10초 이내 복구 시간을 달성했습니다.
6. 마무리
이번 글에서는 하이브리드 클러스터 운영을 위한 VPN HA 구성을 다뤘습니다. 두 가지 방안을 비교 검토한 끝에, 우리 환경에 맞는 Keepalived + VRRP 기반 Active-Standby 구조를 선택했어요.
결국 HA 구성에서 가장 중요한 것은 "가장 좋은 기술"이 아니라 "우리 환경에 가장 적합한 기술"을 선택하는 것이라고 생각합니다. BGP + Active-Active가 기술적으로는 우월할 수 있지만, 운영 복잡도와 비용, 그리고 팀의 기존 역량까지 고려하면 Keepalived가 더 합리적인 선택이었습니다.
