
사이킷런(sklearn)이란?
scikit-learn(사이킷런)은 파이썬을 대표하는 머신러닝 분석을 할 때 유용하게 사용할 수 있는 라이브러리입니다. 여러가지 머신러닝 모듈로 구성되어 있습니다. scikit-learn은 오픈 소스로 공개되어 있습니다. 초심자가 기계학습을 배우기 시작할 때 적합한 라이브러리라고 합니다.
사이킷런 설치
pip install scikit-learn 명령어를 실행하여 설치할 수 있습니다.
사이킷런 사용 방법
사이킷런은 알고리즘이 많이 포함되어 있기 때문에, 필요한 알고리즘을 호출하여 사용합니다.
사이킷런을 사용한 프로그램은 기본적으로 아래의 구성을 따릅니다.
- 라이브러리 import
- 학습 데이터나 테스트 데이터 준비
- 알고리즘 지정과 학습 실행
- 테스트 데이터로 테스트
- 필요에 따라 정밀도 등을 시각화
사이킷런을 사용한 기계학습 예제
1. 데이터 세트 읽기
# scikit-learn 라이브러리 가져오기
from sklearn import datasets
# 데이터 세트 읽어오기
digits = datasets.load_digits()
# 무슨 데이터인지 확인하기
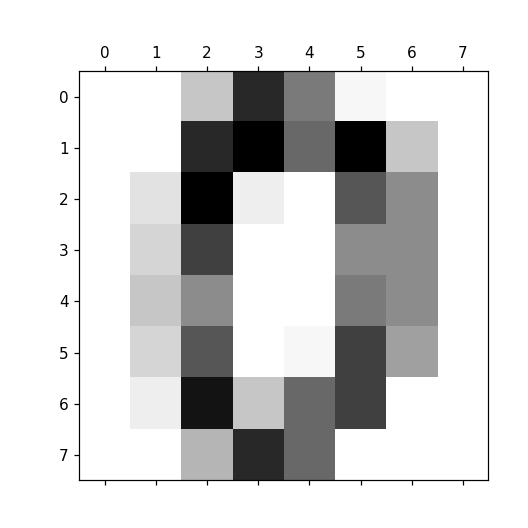
import matplotlib.pyplot as plt
plt.matshow(digits.images[0], cmap="Greys")
plt.show()위 코드를 입력하면 아래와 같은 화면이 나옵니다.
당연하게, sklearn과 matplotlib를 설치해야합니다.
pip install scikit-learn
pip install matplotlib
필자의 경우
pip install scikit-learn과 pip install matplotlib를 하였음에도 오류가 발생하여 파이썬 버전을 3.10.9로 바꾸었더니 실행되었습니다.
2. 훈련 데이터와 테스트 데이터 준비
훈련 데이터(train data)를 통하여 학습하고 테스트 데이터(test data)를 통하여 학습의 결과를 검증합니다.
# 화상 데이터를 배열로 한 것(numpy.ndarray형)
X = digits.data
# 이미지 데이터에 대한 숫자(numpy.ndarray형) (라벨)
y = digits.target
# 훈련 데이터와 테스트 데이터로 나누다
# 훈련 데이터 : 짝수 행
X_train, y_train = X[0::2], y[0::2]
# 테스트 데이터: 홀수 행
X_test, y_test = X[1::2], y[1::2]3. 학습
이제 모델을 통하여 학습을 해보겠습니다.
# 학습기 작성. SVM이라는 알고리즘을 선택
from sklearn import svm
clf = svm.SVC(gamma=0.001)
# 훈련 데이터와 라벨로 학습
clf.fit(X_train, y_train)SVM이라는 알고리즘을 사용하였습니다.
4. 모델 평가
최종적으로 모델의 학습 결과를 테스트 데이터를 사용하여 평가해보겠습니다.
# 테스트 데이터로 시험한 정답률을 반환하다
accuracy = clf.score(X_test, y_test)
print(f"정답률: {accuracy}")
# 학습된 모델을 사용하여 테스트 데이터를 분류한 결과를 반환한다.
predicted = clf.predict(X_test)
import sklearn.metrics as metrics
# 자세한 리포트
# precision(적합율): 선택한 정답/선택한 집합
# recall(재현율) : 선택한 정답 / 전체 정답
# F-score(F값) : 적합률과 재현율은 트레이드오프의 관계에 있기 때문에
print("classification report")
print(metrics.classification_report(y_test, predicted))학습의 결과는 콘솔창에 나오며 아래와 같습니다.
정답률: 0.9866369710467706
classification report
precision recall f1-score support
0 1.00 0.99 0.99 88
1 0.98 1.00 0.99 89
2 1.00 1.00 1.00 91
3 1.00 0.98 0.99 93
4 0.99 1.00 0.99 88
5 0.98 0.97 0.97 91
6 0.99 1.00 0.99 90
7 0.99 1.00 0.99 91
8 0.97 0.97 0.97 86
9 0.98 0.97 0.97 91
accuracy 0.99 898
macro avg 0.99 0.99 0.99 898
weighted avg 0.99 0.99 0.99 898전체 코드
# scikit-learn 라이브러리 가져오기
from sklearn import datasets
# 데이터 세트 읽어오기
digits = datasets.load_digits()
# 무슨 데이터인지 확인하기
import matplotlib.pyplot as plt
plt.matshow(digits.images[0], cmap="Greys")
plt.show()
# 화상 데이터를 배열로 한 것(numpy.ndarray형)
X = digits.data
# 이미지 데이터에 대한 숫자(numpy.ndarray형) (라벨)
y = digits.target
# 훈련 데이터와 테스트 데이터로 나누다
# 훈련 데이터 : 짝수 행
X_train, y_train = X[0::2], y[0::2]
# 테스트 데이터: 홀수 행
X_test, y_test = X[1::2], y[1::2]
# 학습기 작성. SVM이라는 알고리즘을 선택
from sklearn import svm
clf = svm.SVC(gamma=0.001)
# 훈련 데이터와 라벨로 학습
clf.fit(X_train, y_train)
# 테스트 데이터로 시험한 정답률을 반환하다
accuracy = clf.score(X_test, y_test)
print(f"정답률: {accuracy}")
# 학습된 모델을 사용하여 테스트 데이터를 분류한 결과를 반환한다.
predicted = clf.predict(X_test)
import sklearn.metrics as metrics
# 자세한 리포트
# precision(적합율): 선택한 정답/선택한 집합
# recall(재현율) : 선택한 정답 / 전체 정답
# F-score(F값) : 적합률과 재현율은 트레이드오프의 관계에 있기 때문에
print("classification report")
print(metrics.classification_report(y_test, predicted))로지스틱 회귀로 변환
학습기 작성의 2행을 아래와 같이 변경하면 기계학습 알고리즘을 로지스틱 회귀로 변환할 수 있습니다.
# 학습기 작성. 로지스틱 회귀라는 알고리즘을 선택
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()학습의 결과는 콘솔창에 나오며 아래와 같습니다.
정답률: 0.9532293986636972
classification report
precision recall f1-score support
0 1.00 0.98 0.99 88
1 0.87 0.96 0.91 89
2 0.97 0.99 0.98 91
3 0.98 0.95 0.96 93
4 0.94 0.99 0.96 88
5 0.97 0.96 0.96 91
6 0.97 0.99 0.98 90
7 0.97 0.97 0.97 91
8 0.94 0.88 0.91 86
9 0.95 0.88 0.91 91
accuracy 0.95 898
macro avg 0.95 0.95 0.95 898
weighted avg 0.95 0.95 0.95 898전체 코드
# scikit-learn 라이브러리 가져오기
from sklearn import datasets
# 데이터 세트 읽어오기
digits = datasets.load_digits()
# 무슨 데이터인지 확인하기
import matplotlib.pyplot as plt
plt.matshow(digits.images[0], cmap="Greys")
plt.show()
# 화상 데이터를 배열로 한 것(numpy.ndarray형)
X = digits.data
# 이미지 데이터에 대한 숫자(numpy.ndarray형) (라벨)
y = digits.target
# 훈련 데이터와 테스트 데이터로 나누다
# 훈련 데이터 : 짝수 행
X_train, y_train = X[0::2], y[0::2]
# 테스트 데이터: 홀수 행
X_test, y_test = X[1::2], y[1::2]
# 학습기 작성. 로지스틱 회귀라는 알고리즘을 선택
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
# 훈련 데이터와 라벨로 학습
clf.fit(X_train, y_train)
# 테스트 데이터로 시험한 정답률을 반환하다
accuracy = clf.score(X_test, y_test)
print(f"정답률: {accuracy}")
# 학습된 모델을 사용하여 테스트 데이터를 분류한 결과를 반환한다.
predicted = clf.predict(X_test)
import sklearn.metrics as metrics
# 자세한 리포트
# precision(적합율): 선택한 정답/선택한 집합
# recall(재현율) : 선택한 정답 / 전체 정답
# F-score(F값) : 적합률과 재현율은 트레이드오프의 관계에 있기 때문에
print("classification report")
print(metrics.classification_report(y_test, predicted))자료 출처
https://scikit-learn.org/stable/tutorial/basic/tutorial.html
